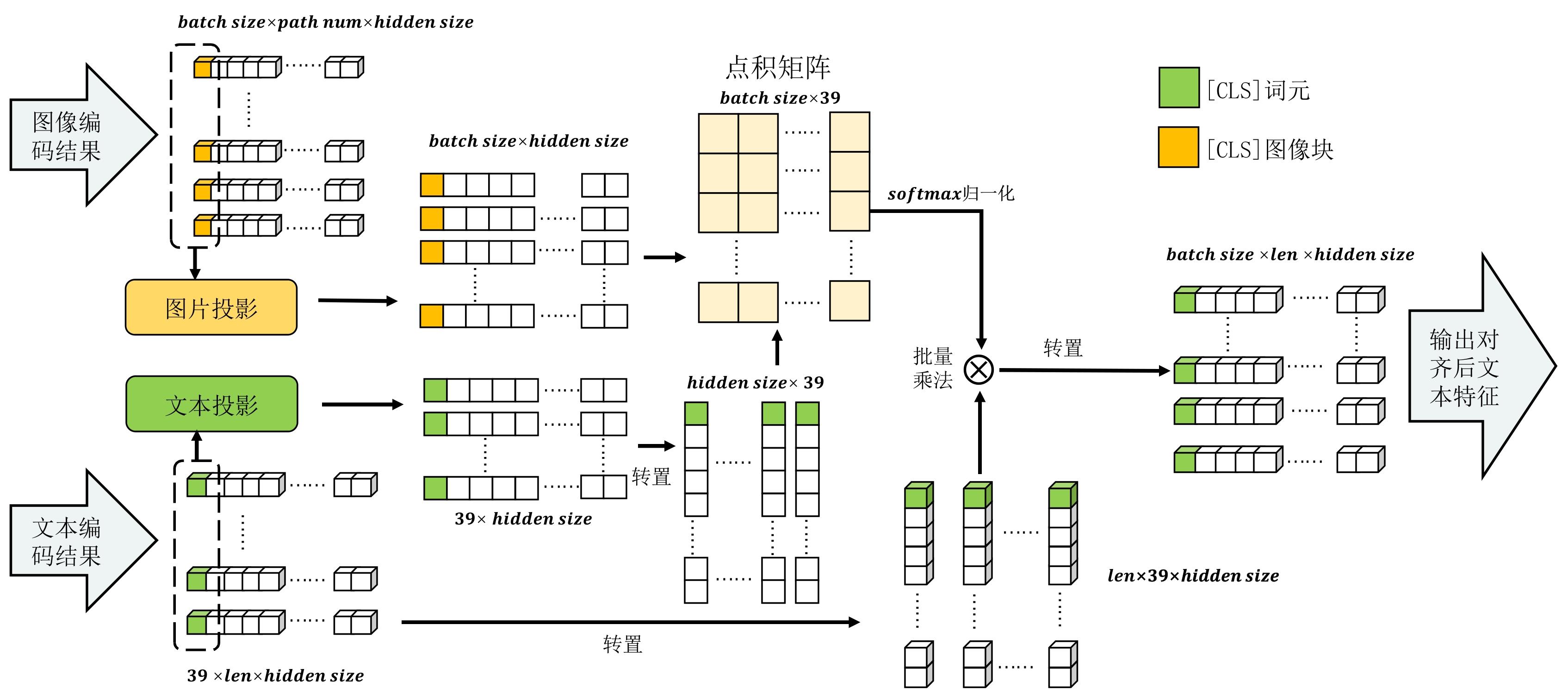
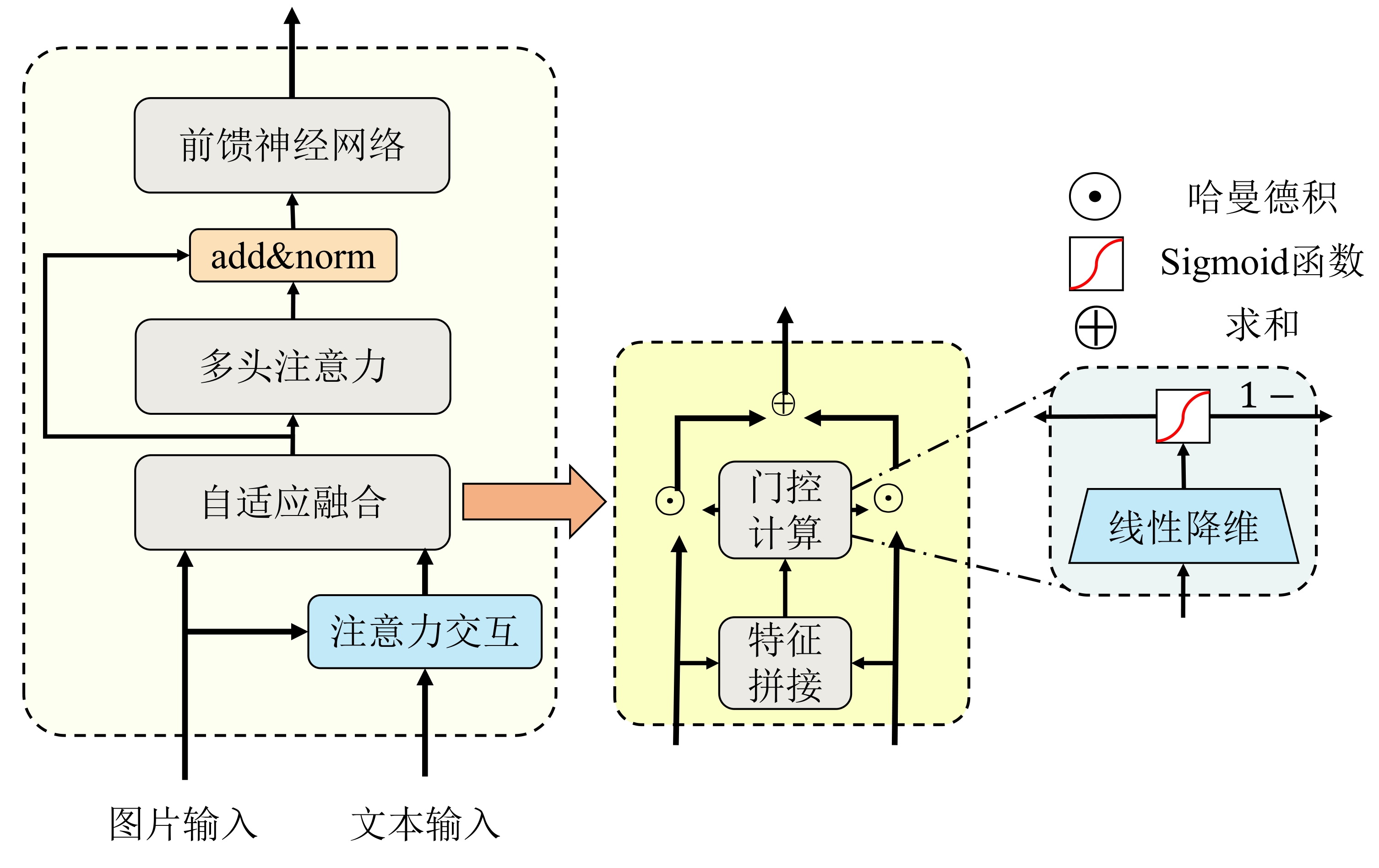
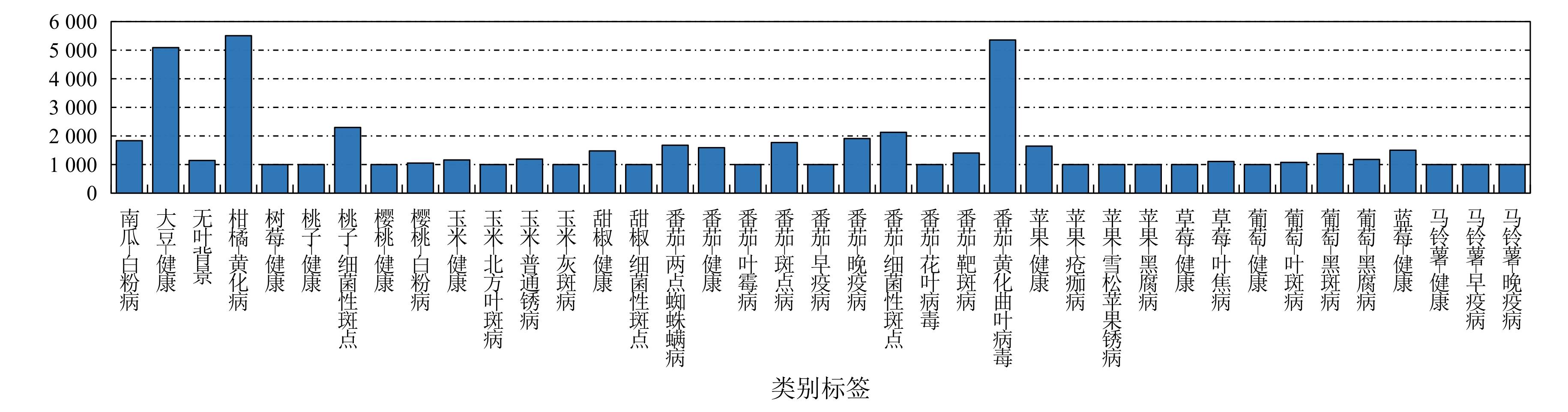
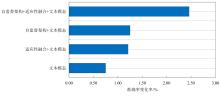
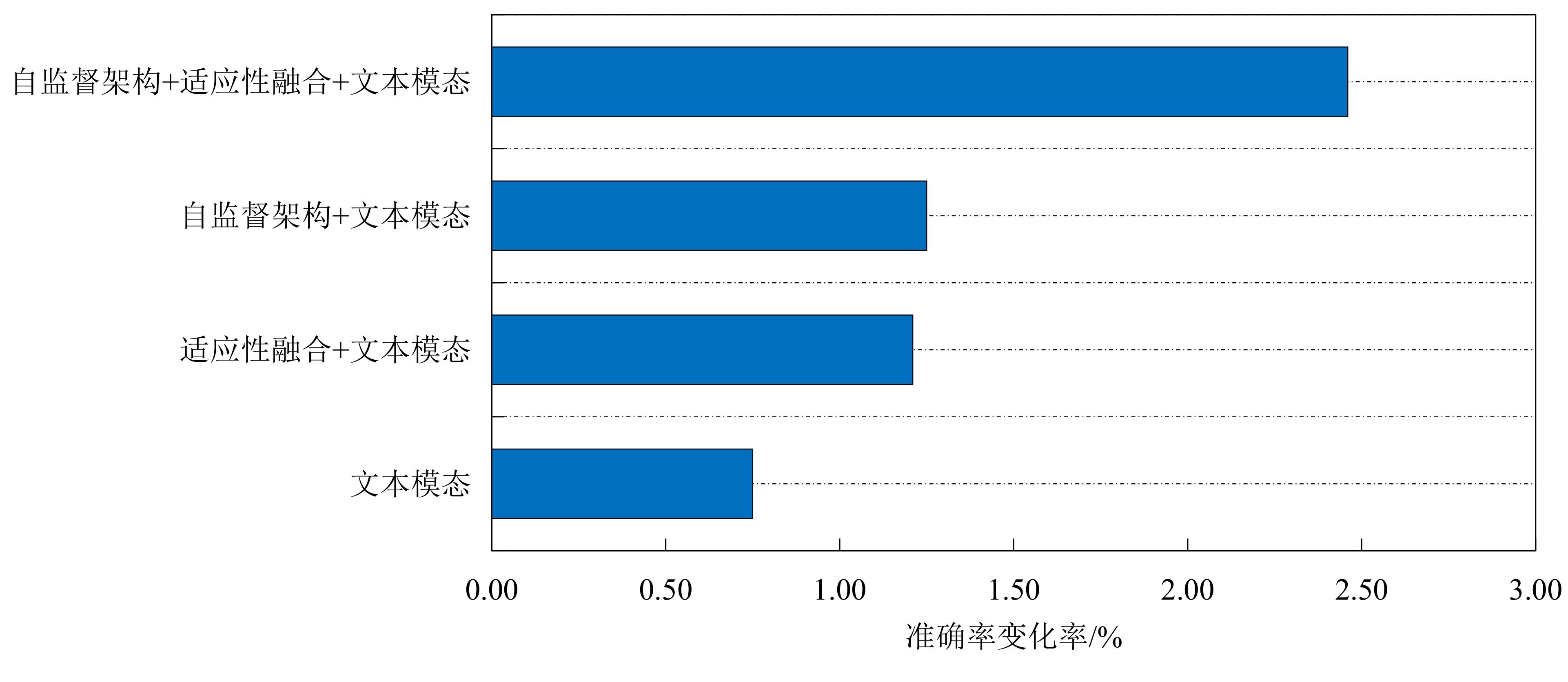
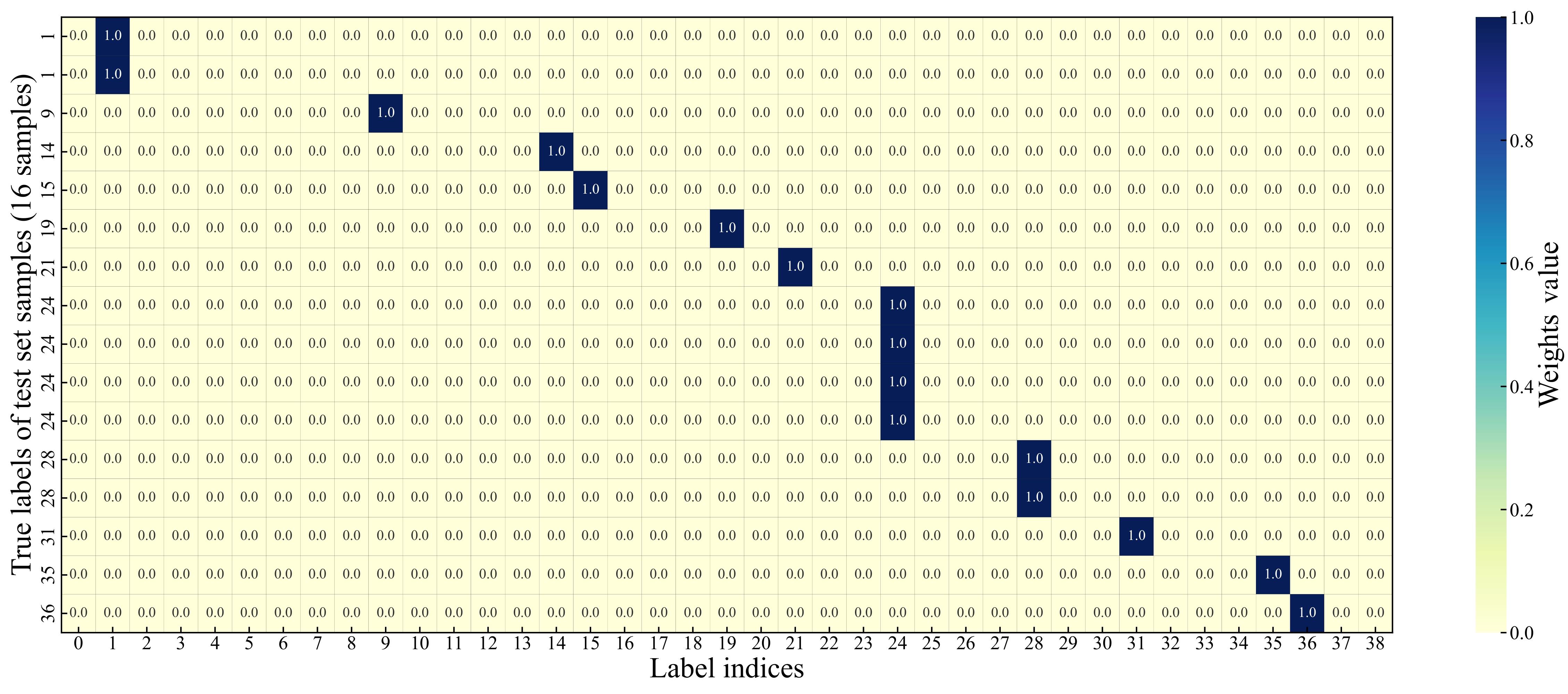
| [1] |
FAO. Global crop losses due to pests and diseases: Annual impact on food security and economy[R]. Food and Agriculture Organization of the United Nation. [2025-09-02]. https://www.fao.org/plant-production-protection/about/zh.
|
| [2] |
王聃, 柴秀娟. 机器学习在植物病害识别研究中的应用[J]. 中国农机化学报, 2019, 40(9): 171-180.
|
|
WANG D, CHAI X J. Application of machine learning in plant diseases recognition[J]. Journal of Chinese Agricultural Mechanization, 2019, 40(9): 171-180.
|
| [3] |
邵明月, 张建华, 冯全, 等. 深度学习在植物叶部病害检测与识别的研究进展[J]. 智慧农业(中英文), 2022(1): 29-46.
|
|
SHAO M Y, ZHANG J H, FENG Q, et al. Research progress of deep learning in detection and recognition of plant leaf diseases[J]. Smart agriculture, 2022(1): 29-46.
|
| [4] |
慕君林, 马博, 王云飞, 等. 基于深度学习的农作物病虫害检测算法综述[J]. 农业机械学报, 2023, 54(S2): 301-313.
|
|
MU J L, MA B, WANG Y F, et al. A review of deep-learning-based algorithms for crop pest and disease detection[J]. Transactions of the Chinese Society for Agricultural Machinery, 2023, 54(S2): 301-313.
|
| [5] |
杨锋, 姚晓通. 基于改进YOLOv8的小麦叶片病虫害检测轻量化模型[J]. 智慧农业(中英文), 2024(1): 147-157.
|
|
YANG F, YAO X T. Lightweighted wheat leaf diseases and pests detection model based on improved YOLOv8[J]. Smart Agriculture, 2024(1): 147-157.
|
| [6] |
彭红星, 何慧君, 高宗梅, 等. 基于改进ShuffleNetV2模型的荔枝病虫害识别方法[J]. 农业机械学报, 2022, 53(12): 290-300.
|
|
PENG H X, HE H J, GAO Z M, et al. Litchi diseases and insect pests identification method based on improved ShuffleNetV2[J]. Transactions of the Chinese Society for Agricultural Machinery, 2022, 53(12): 290-300.
|
| [7] |
冯峰, 周鑫, 陈诗瑶, 等. 一种基于改进神经网络算法ResNet50的玉米病虫害识别模型[J]. 江苏农业科学, 2024, 52(16): 239-244.
|
|
FENG F, ZHOU X, CHEN S Y, et al. A maize pest and disease identification model based on improved neural network algorithm ResNet50[J]. Jiangsu Agricultural Sciences, 2024, 52(16): 239-244.
|
| [8] |
孙杨俊, 陈滔, 刘志梁, 等. 基于双线性卷积宽度网络的水稻病虫害识别[J]. 计算机应用, 2024, 44(S1): 314-318.
|
|
SUN Y J, CHEN T, LIU Z L, et al. Rice pests and diseases recognition based on bilinear convolutional broad network[J]. Journal of Computer Applications, 2024, 44(S1): 314-318.
|
| [9] |
王杨, 李迎春, 许佳炜, 等. 基于改进Vision Transformer网络的农作物病害识别方法[J]. 小型微型计算机系统, 2024, 45(4): 887-893.
|
|
WANG Y, LI Y C, XU J W, et al. Crop disease recognition method based on improved vision transformer network[J]. Journal of Chinese Computer Systems, 2024, 45(4): 887-893.
|
| [10] |
刘拥民, 刘翰林, 石婷婷, 等. 一种优化的Swin Transformer番茄叶片病害识别方法[J]. 中国农业大学学报, 2023, 28(4): 80-90.
|
|
LIU Y M, LIU H L, SHI T T, et al. Tomato leaf disease recognition based on an optimized Swin Transformer[J]. Journal of China Agricultural University, 2023, 28(4): 80-90.
|
| [11] |
RADFORD A, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[EB/OL]. arXiv: 2103.00020, 2021.
|
| [12] |
陈燕, 赖宇斌, 肖澳, 等. 基于CLIP和交叉注意力的多模态情感分析模型[J]. 郑州大学学报(工学版), 2024, 45(2): 42-50.
|
|
CHEN Y, LAI Y B, XIAO A, et al. Multimodal sentiment analysis model based on clip and cross-attention [J]. Journal of Zhengzhou University (Engineering Science), 2024, 45(2): 42-50.
|
| [13] |
FU J M, XU S Y, LIU H D, et al. CMA-CLIP: Cross-modality attention clip for text-image classification[C]// 2022 IEEE International Conference on Image Processing (ICIP). Piscataway, New Jersey, USA: IEEE, 2022: 2846-2850.
|
| [14] |
许睿, 邵帅, 曹维佳, 等. 基于重构对比的广义零样本图像分类[J]. 模式识别与人工智能, 2022, 35(12): 1078-1088.
|
|
XU R, SHAO S, CAO W J, et al. Generalized zero-shot image classification based on reconstruction contrast [J]. Pattern Recognition and Artificial Intelligence, 2022, 35(12): 1078-1088.
|
| [15] |
LI J N, SELVARAJU R R, GOTMARE A D, et al. Align before fuse: vision and language representation learning with momentum distillation[EB/OL]. arXiv: 2107.07651, 2021.
|
| [16] |
LI J N, LI D X, XIONG C M, et al. BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation[EB/OL]. arXiv: 2201.12086, 2022.
|
| [17] |
谢润锋, 张博超, 杜永萍, 等. 基于视觉语言模型的跨模态多级融合情感分析方法[J]. 模式识别与人工智能, 2024, 37(5): 459-468.
|
|
XIE R F, ZHANG B C, DU Y P, et al. Cross-modal multi-level fusion sentiment analysis method based on visual language model [J]. Pattern Recognition and Artificial Intelligence, 2024, 37(5): 459-468.
|
| [18] |
FENG X G, ZHAO C J, WANG C S, et al. A vegetable leaf disease identification model based on image-text cross-modal feature fusion[J]. Frontiers in Plant Science, 2022, 13: 918940.
|
| [19] |
CAO Y Y, CHEN L, YUAN Y, et al. Cucumber disease recognition with small samples using image-text-label-based multi-modal language model[J]. Computers and Electronics in Agriculture, 2023, 211: 107993.
|
| [20] |
LIU W J, WU G Q, WANG H, et al. Cross-modal data fusion via vision-language model for crop disease recognition[J]. Sensors, 2025, 25(13): 4096.
|
| [21] |
DENG S M, ZHU J L, HU Y, et al. Tomato leaf disease identification framework FCMNet based on multimodal fusion[J]. Plants, 2025, 14(15): 2329.
|
| [22] |
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[EB/OL]. arXiv:1706.03762, 2017.
|
| [23] |
ERICSSON L, GOUK H, LOY C C, et al. Self-supervised representation learning: Introduction, advances, and challenges[J]. IEEE Signal Processing Magazine, 2022, 39(3): 42-62.
|
| [24] |
BERAHMAND K, DANESHFAR F, SALEHI E S, et al. Autoencoders and their applications in machine learning: A survey[J]. Artificial Intelligence Review, 2024, 57(2): 28.
|
| [25] |
HUGHES D P, SALATHE M. An open access repository of images on plant health to enable the development of mobile disease diagnostics[EB/OL]. arXiv: 1511.08060, 2015.
|
| [26] |
PENN STATE EXTENSION. Pests and diseases[EB/OL]. [2025-12-16].
|
| [27] |
THE AMERICAN PHYTOPATHOLOGICAL SOCIETY. Common names of plant diseases[EB/OL]. [2025-12-16].
|
| [28] |
ZHANG T Y, KISHORE V, WU F, et al. BERTScore: Evaluating text generation with BERT[EB/OL]. arXiv: 1904.09675, 2019.
|
| [29] |
SAI A B, MOHANKUMAR A K, KHAPRA M M. A survey of evaluation metrics used for NLG systems[J]. ACM Computing Surveys, 2023, 55(2):1-39.
|
| [30] |
LOSHCHILOV I, HUTTER F. Decoupled weight decay regularization[EB/OL]// arXiv:1711.05101, 2017.
|
| [31] |
LOSHCHILOV I, HUTTER F. SGDR: Stochastic gradient descent with restarts[EB/OL]. arXiv: 1608.03983, 2016.
|
| [32] |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2016: 770-778.
|
| [33] |
LIU Z, LIN Y T, CAO Y, et al. Swin transformer: Hierarchical vision transformer using shifted windows[C]// 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway, New Jersey, USA: IEEE, 2022: 9992-10002.
|
| [34] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[J]. International Journal of Computer Vision, 2020, 128(2): 336-359.
|
| [35] |
王科平, 左鑫浩, 杨艺, 等. 基于伪全局Swin Transformer的遥感图像识别算法[J]. 模式识别与人工智能, 2023, 36(9): 818-831.
|
|
WANG K P, ZUO X H, YANG Y, et al. Remote sensing image recognition algorithm based on pseudo global swin transformer[J]. Pattern Recognition and Artificial Intelligence, 2023, 36(9): 818-831.
|
| [36] |
朱杰, 陈黎飞. 核密度估计的聚类算法[J]. 模式识别与人工智能, 2017, 30(5): 439-447.
|
|
ZHU J, CHEN L F. Clustering algorithm with kernel density estimation[J]. Pattern Recognition and Artificial Intelligence, 2017, 30(5): 439-447.
|
 ), 闵超1,2,3(
), 闵超1,2,3(