



1 引 言
2 材料与方法
2.1 数据集采集

2.2 数据集处理
2.3 试验条件
2.4 T-M-VGG网络构建
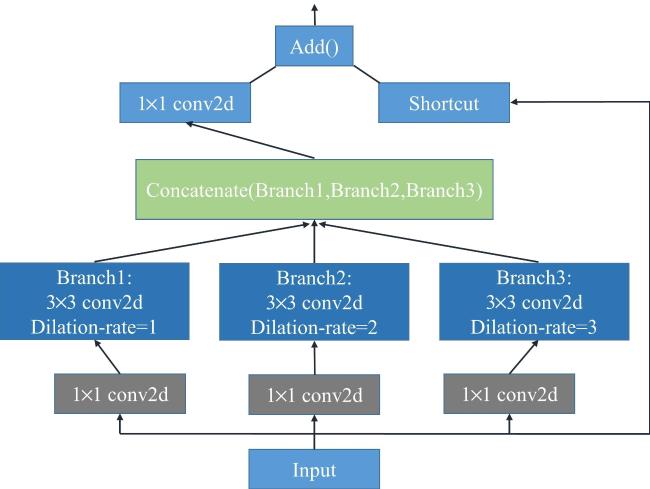
2.4.1 并行的空洞卷积
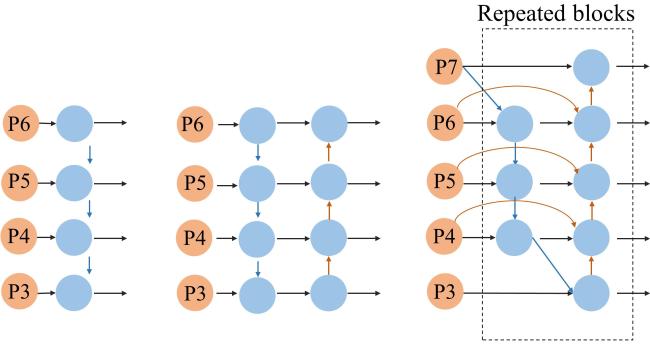
2.4.2 特征金字塔
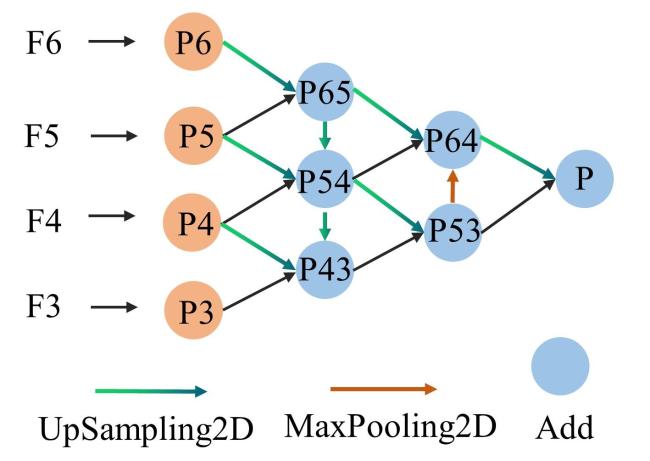
| Algorithm 特征金字塔算法实现 |
|---|
| Input: F3、F4、F5、F6 |
| Output: P 1 def OurFPN(Input): |
| 2 P3 = F3, P4 = F4, P5 = F5, P6 = F6, Features = P3, P4, P5, P6 |
| 3 for j in range(len(Features)): 4 C_Feature[j] = Conv2D(channels_num, kernel_size = 1)Feature[j] #调整通道数 5 P3_in = C_Feature[0], P4_in = C_Feature[1], P5_in = C_Feature[2], P6_in = C_Feature[3] # P3_in、P4_in、P5_in、P6_in分别为通道数调整后的特征输入 6 P6_UP = UpSampling2D()(P6_in), P65 = Add([P6_UP,P5_in]), P65 = SeparableConv()(P65) # P6_in经过上采样与P5_in进行Add操作生成P65。P54、P43、P53生成操作相似 |
| 7 P65_UP= UpSampling2D()(P65), P5_UP = UpSampling2D()(P5_in),P54=Add([P65_UP,P5_UP,P4_in]), P54= SeparableConv()(P54) |
| # P65_UP和P5_UP经过上采样后与P4_in进行Add操作生成P54 |
| 8 P54_UP= UpSampling2D()(P54), P4_UP = UpSampling2D()(P4_in),P43=Add([P54_UP,P4_UP,P3_in]), P43= SeparableConv()(P43) |
| # P54_UP和P4_UP经过上采样后与P3_in进行Add操作生成P43 |
| 9 P53 = Add([P54_UP,P43]), P53= SeparableConv()(P53) |
| 10 P53_MaP = MaxPooling2D()(P53),P64 = Add([P53_MaP,P54,P65_UP]), P64= SeparableConv()(P64) # P53进行最大池化生成P53_MaP;P65经过上采样与P54、P53_MaP进行Add操作生成P64 |
| 11 P64_UP = UpSampling2D()(P64), P = Add([P64_UP,P53]), P= SeparableConv()(P) 12 return P #返回特征P,送入分类部分 |

2.5 试验参数设置
表1 试验方案参数设置Table 1 Parameters setting of experimental schemes |
| 试验方案 | 图像训练形式 | 优化函数 | 学习率 | 批量 | 迁移学习-全连接层 |
|---|---|---|---|---|---|
| 文献[9]结构 | 256 256 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| 文献[10]结构 | 128 128 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| 文献[11]结构 | 256 256 1 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| 文献[25]结构 | 256 256 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| VGG16 | 128 128 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| Mb-Net-L | 128 128 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| Mb-Net-S | 256 256 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| InceptionV3 | 128 128 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| FaceNet结构 | 128 128 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | —— |
| Tr-L-VGG16 | 256 256 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | x=Activation('relu')(output) x=GlobalAveragePooling2D(x) x=Dense(194,activation='softmax')(x) |
| T-M-VGG | 256 256 3 | SGD(momentum=0.9,decay=0.00001) | 0.001 | 128 | x=Activation('relu')(output) x=GlobalAveragePooling2D(x) x=Dense(194,activation='softmax')(x) |
|
2.6 试验评价指标
3 结果与分析
3.1 VGG系列算法结果与分析
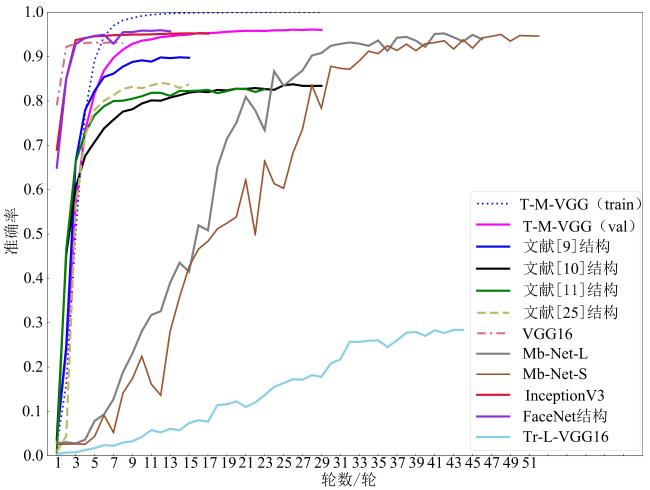
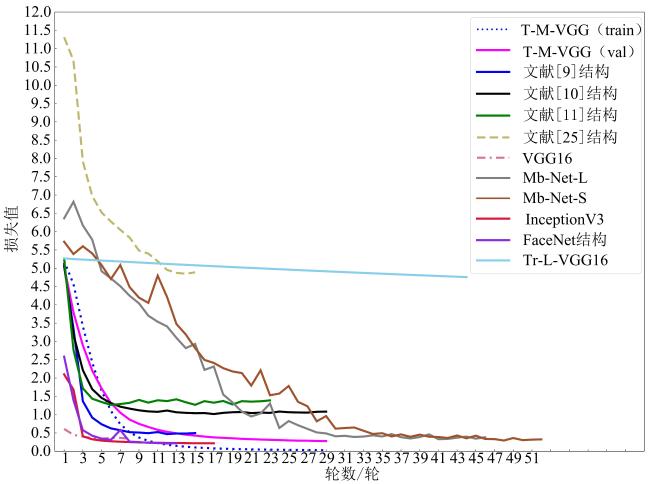
表2 不同试验方案的性能指标对照Table 2 Comparison of performance indicators of different experiments |
| 试验方案 | F1值/% | 模型大小/MB | 准确率/% | 可训练参 数量/M |
|---|---|---|---|---|
| T-M-VGG | 95.43 | 70.75 | 96.01 | 3.73 |
| 文献[9]结构 | 88.03 | 166.33 | 88.03 | 7.07 |
| 文献[10]结构 | 82.07 | 263.02 | 82.89 | 34.47 |
| 文献[11]结构 | 81.92 | 263.16 | 82.63 | 34.48 |
| 文献[25]结构 | 83.57 | 74.85 | 84.24 | 9.80 |
| VGG16 | 92.85 | 502.48 | 93.02 | 65.85 |
| Mb-Net-L | 93.29 | 34.74 | 93.91 | 4.46 |
| Mb-Net-S | 94.60 | 13.65 | 94.62 | 1.72 |
| InceptionV3 | 95.01 | 170.13 | 95.16 | 22.17 |
| FaceNet结构 | 95.60 | 418.71 | 95.68 | 54.57 |
| Tr-L-VGG16 | 20.64 | 56.96 | 28.38 | 0.10 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}