



1 引 言
植物在遭遇低温胁迫时,会因脂质过氧化反应导致蛋白质裂解和细胞膜系统的破坏,从而损害其光合作用与呼吸作用,重则导致植物死亡[10]。丙二醛(Malondialdehyde,MDA)是多不饱和脂肪酸过氧化物的降解产物。植物遭遇低温逆境的损伤越严重,其MDA含量就越高[11, 12]。因此,MDA含量可作为研究植物生长动态的有力诊断指标。准确预测植物体内MDA含量可实时反映植物的健康状况。硫代巴比妥酸(Thiobarbituric Acid Method,TBA)法是测定植物中MDA最常用的方法之一[13],但其耗时耗力,且具有破坏性,难以对大尺度的田间作物进行实时有效的检测[14]。因此建立一种快速、无损、有效的MDA测定方法对植物胁迫监测具有重要意义。
近年来,随着各类光学传感器及机器学习技术的发展,可见/近红外光谱技术由于其快速、无损等众多优势已被广泛地应用在农业[15, 16]、食品[17]、医药[18]等领域。在以往生化指标测定的研究中,大多采用光谱预处理以及优化建模的方式来提高模型的准确性。Phuphaphud等[19]以甘蔗为研究对象,利用可见/近红外光谱结合预处理方法对其不同部位进行纤维含量预测,基于偏最小二乘回归(Partial Least Squares Regression,PLSR)模型,其最佳的模型检测性能Rp 2为0.81。Chanda等[20]以茶叶为研究对象,利用近红外光谱对咖啡因含量进行检测,根据咖啡因中不同化学键的响应特征获取有效波长,结合预处理技术与两种回归模型,包括支持向量机(Support Vector Regression,SVR)和PLSR,其中最佳的Rp 2为0.637。张亚坤等[21]基于近红外光谱测定大豆叶片可溶性蛋白含量,表明Savitzky-Golay平滑结合连续投影算法(Successive Projections Algorithm,SPA)可获得最佳的检测效果,其中预测集R 2为0.746。上述研究虽都取得了较好的效果,然而在实际样本采集中,获取大量数据的难度较大,而数据量较小的情况往往又会影响建模精度,因此扩充高质量的样本数据集很有必要[22, 23]。
Radford等[24]于2015年提出了深度卷积生成式对抗网络(Deep Convolutional Generative Adversarial Networks,DCGAN)用于生成高质量图像,在数据增强、图像修复、超分辨率重构等领域均取得了很好的效果[25, 26]。基于此,为探究利用DCGAN网络联合可见/近红外光谱反演低温胁迫下菌草MDA含量的可行性,本研究以6种菌草为研究对象,测定菌草叶片的可见/近红外反射率与MDA含量,采用一维DCGAN进行数据集扩充,并建立3种定量检测模型,包括一维卷积神经网络(Convolutional Neural Networks,CNN)、随机森林(Random Forest,RF)以及偏最小二乘回归(Partial Least Squares Regression,PLSR),实现菌草MDA含量快速无损检测。
2 材料与方法
2.1 实验材料
本研究于2022年10‒11月与2023年3—4月在福建农林大学菌草温室大棚(26°5'21"N,119°14'49"E)进行。本研究对象包含6种典型的菌草品种,分别是绿洲二号(Arundo donax cv. Lv zhou. No.2,A. donax. No.2)、绿洲七号(Arundo donax cv. Lv zhou. No.7,A. donax. No.7)、巨菌草(Cenchrus fungigraminus)、象草(Pennisetum purpureum Schum)、紫象草(Pennisetum purpureum Schumab)以及皇竹草(Pennisetum sinese Roxb),均由福建农林大学国家菌草工程技术研究中心提供。样本植株种植采用土培方式,将菌草种节种植在穴盘中(穴盘上口径58 mm,下口径20 mm,深度110 mm),并放置于恒温培养箱中,温度设定为28℃,定期浇水。当植株高度为25 cm左右时,将每个品种的植株均匀分为两组,其中对照组继续放置于28℃恒温培养箱中,胁迫组放置于4℃培养箱中进行胁迫处理[27]。经过5 d后,一次性采集对照组与胁迫组植株叶片作为实验样本,并测定叶片光谱反射率和MDA含量。样本总计144株,不同菌草品种的植株如图1所示。
2.2 测定项目及方法
2.2.1 叶片光谱反射率获取
使用手持式地物光谱仪(ASD HandHeld 2, Malvern Panalytical America,波长范围为325~1075 nm,光谱分辨率为1 nm)与近红外光谱仪(SW2520-050-NIRA,台湾超微光学,波长范围为900~1700 nm,光谱分辨率为9 nm)采集远离主脉的菌草叶片在325~1700 nm范围内的光谱信息,每个样本重复采集3个不同位置,取其平均值作为该样本的光谱反射率。数据采集前先开启装置预热约30 min并进行黑白板校准。由于采集的光谱数据在首尾两端会产生明显噪声,为消除该影响,截取手持式地物光谱仪采集的400~999 nm范围内光谱(共600个波长参数),以及截取近红外光谱仪采集的1000~1650 nm范围内的光谱(共99个波长参数),经光谱拼接后(共699个波长参数)用于后续实验分析。
2.2.2 丙二醛含量测定
菌草叶片MDA含量的测定方法采用硫代巴比妥酸法。在样本完成光谱数据采集后,剪下叶片,在剪叶时注意避开叶脉。将每株剪下的叶片混合后称取0.1 g放置于离心管中,并立刻将其用液氮速冻后放入-80℃冰箱中以便后续实验测定。MDA含量具体测定方法如下:将叶片加入1 mL提取液后进行冰浴匀浆,之后在4℃下以8000 r/min离心10 min,提取0.l mL上清液并加入0.4 mL TBA溶液后于100℃水浴60 min,然后在25℃下以10,000 r/min离心10 min,最后取0.2 mL上清液分别测定其在532与600 nm处的吸光度用于确定该样本的MDA浓度。
2.3 建模方法与模型评价标准
2.3.1 深度卷积生成式对抗网络
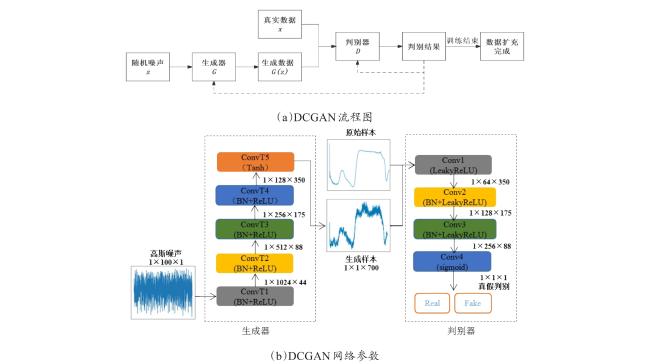
本研究中DCGAN模型使用Python3.8编程实现。实验平台为Pycharm社区版与Pytorch2.0.0。该模型主要由生成器与判别器构成,执行流程如图2(a)所示。生成器以一个高斯分布的随机噪声z作为输入,通过生成器生成伪数据G(z);判别器则以真实数据与伪数据共同作为输入,判别结果作为输出。当训练完成时,保存生成样本完成数据扩充。
由于该对抗网络模型主要用于图像领域,为此本研究在此网络的基础上进行了改进,使其适用于一维光谱数据,同时在实际训练中,为避免判别器过强导致其出现梯度消失的现象,从而难以学习到原始样本中信息的问题,本实验在原始网络模型基础上减少了判别器的网络深度,模型的结构与参数如图2(b)所示。生成器由5个转置卷积、5个激活函数以及4个批规范化层组成,其中第5层是tanh激活函数,其余为ReLU激活函数,最终生成长度为700的一维向量,其中第1列向量为拟合的MDA含量信息,后699列为光谱参数;判别器包含4个卷积层、2个批规范化层以及3个LeakyReLU激活函数,最后通过sigmoid激活函数判别数据的真伪。该模型采用Adam优化器,生成器与判别器的学习率都设定为0.0002,批次大小设定为1,训练次数设定为300。由于模型训练前期不够稳定,因此仅保存模型训练100次后生成器最低损失函数值的样本。
2.3.2 模型建立
首先利用Kennard-stone(KS)算法按照2∶1比例将原始样本划分为建模集和预测集,其中建模集96个,预测集48个。其次将96个建模集样本通过DCGAN模型生成4倍于建模集的伪样本,共384个。最后将伪样本随机打乱并依次加入到建模集中,构成增强建模集,利用不同回归建模方法以及添加的生成样本数量进行模型评价。
本研究构建PLSR、RF以及CNN模型用于菌草低温胁迫MDA定量检测,其中CNN模型具体网络参数如表1所示。模型超参数设定:优化器选择随机梯度下降(Stochastic Gradient Descent,SGD);批大小为48;迭代次数设定为500次,为防止过拟合,会提前停止训练;学习率为0.001。
表1 CNN网络参数Table 1 CNN network parameter |
| 网络层 | 卷积核大小 | 卷积核数量 | Padding | 激活函数 |
|---|---|---|---|---|
| Conv1 | 3 | 16 | same | ReLU |
| Conv2 | 3 | 32 | same | ReLU |
2.3.3 评价指标
选用决定系数(Coefficient of Determination, R 2),均方根误差(Root Mean Square Error, RMSE)与残差预测偏差(Residual Predictive Deviation,RPD)对模型的预测性能进行评估。一般情况下,R 2与RPD越大,RMSE越小,表明该模型预测值与实测值相关性好,且预测性能也越好。具体计算方法如公式(1 )~(3 )所示。
其中, 、 分别为第i个样本的实际测量MDA含量值和模型预测的MDA含量值,nmol/g; 、 分别为样本实际测量平均值和模型预测平均值,nmol/g; 、 分别为预测集的实际含量标准偏差和预测标准偏差,nmol/g; 为样本的数量,个。
3 结果与讨论
3.1 低温胁迫对菌草叶片光谱反射率与MDA含量的影响
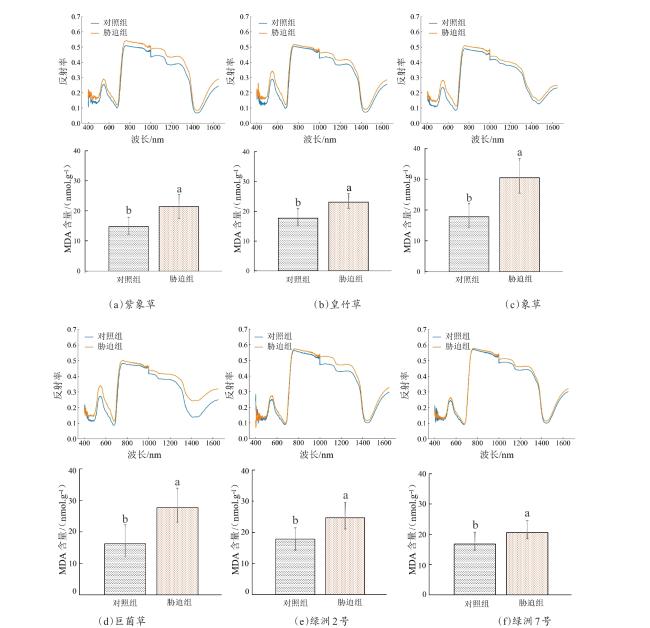
在遭遇低温胁迫后,各品种菌草的MDA含量相较于对照组都具有一定的提高,表现出脂质过氧化现象,说明植株受到损伤。同时,本研究利用不同菌草品种得到了不同浓度梯度的MDA含量,数据分布均匀合理,并且各品种菌草的MDA含量在对照组与胁迫组当中均表现出显著性差异(P<0.05),有利于后续建立稳定的定量模型。
3.2 利用深度卷积生成式对抗网络扩充菌草原始光谱及MDA含量信息
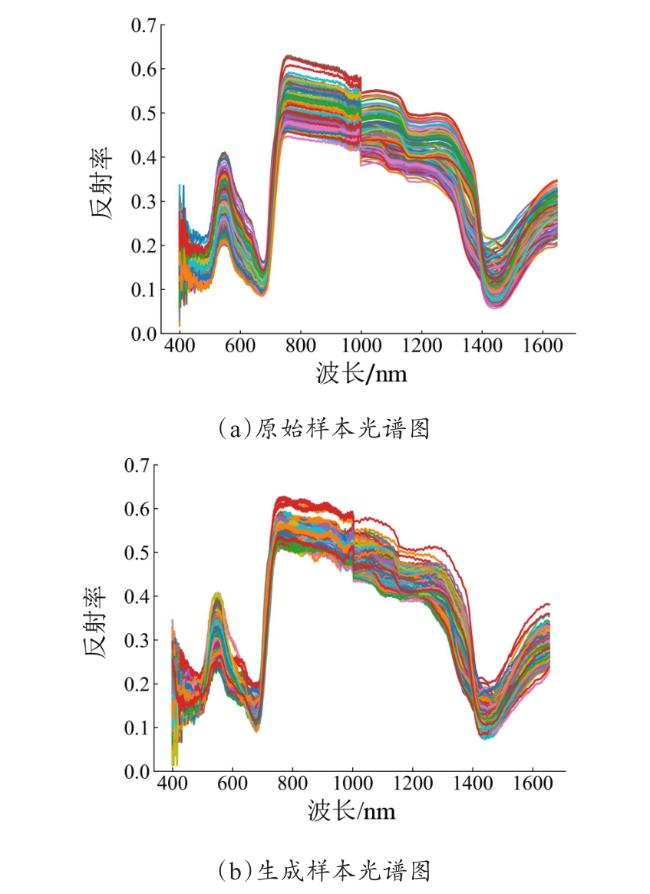
对比原始样本与生成样本的MDA含量统计特征,如表2所示。生成样本中MDA含量的最小值与最大值均在原始样本的范围内,分别为13.2523与34.5608 nmol/g,并且平均值与标准差分别只下降0.6650与0.9743 nmol/g。结果表明生成的MDA含量值能很好地符合原始样本的分布。
表2 MDA含量统计特征Table 2 Statistical characteristics of MDA content |
| 样本类型 | 数量 | 最小值/(nmol·g-1) | 最大值/(nmol·g-1) | 平均值/(nmol·g-1) | 标准差/(nmol·g-1) |
|---|---|---|---|---|---|
| 原始样本 | 144 | 12.1988 | 36.7918 | 21.5571 | 5.8438 |
| 生成样本 | 384 | 13.2523 | 34.5608 | 20.8921 | 4.8695 |
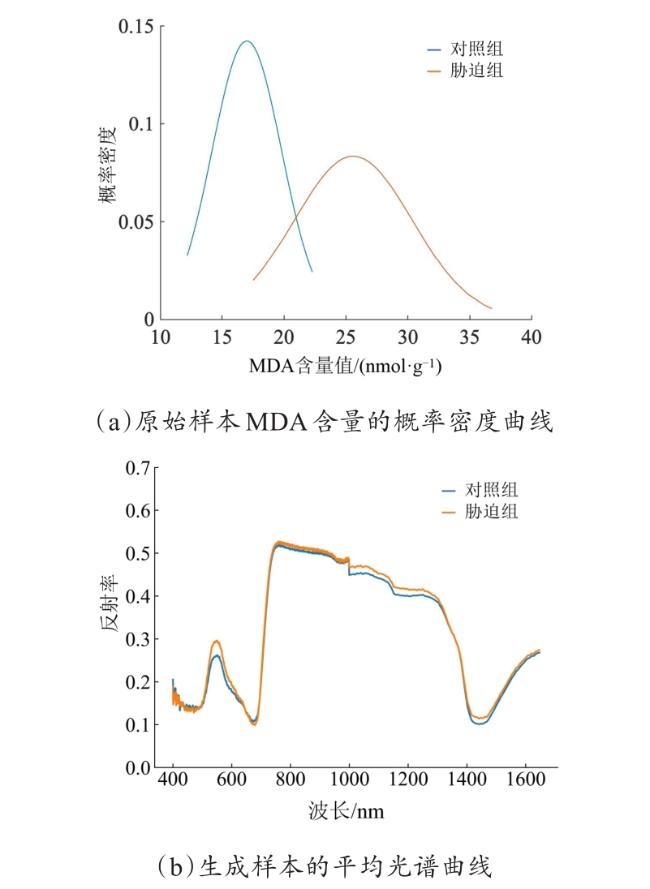
由于在原始样本中,各品种菌草叶片的MDA含量在对照组与胁迫组当中均存在显著差异性(P<0.05),胁迫组的叶片MDA含量往往高于对照组。将原始样本中对照组与胁迫组的MDA含量分别建立概率密度曲线,如图5(a)所示。可以看出对照组在MDA含量为17.0014 nmol/g时,其概率密度取得最高值,胁迫组在MDA含量为25.5955 nmol/g时,其概率密度取得最高值,并且在MDA含量为20.9407 nmol/g时,两者概率密度值相同。因此,将临界值20.9407 nmol/g作为生成样本中对照组与胁迫组的划分依据,将MDA含量小于该值的样本作为对照组,MDA含量大于该值的样本作为胁迫组,比较生成样本在可见/近红外光谱的差异性。图5(b)为生成样本中对照组与胁迫组的平均光谱曲线,可以看出,胁迫组的平均光谱在大部分波长范围内都高于对照组,虽然仅在550、1000~1300以及1450 nm处较为显著,但仍较好地满足了原始样本的光谱特征。
上述结果说明,经DCGAN模型生成的样本在自身具有多样性的同时,与原始样本也具有较高的相似性。因此,生成样本符合原始样本的分布规律,可对原始样本进行数据扩充。
3.3 基于原始样本与生成样本构建菌草MDA含量检测模型
在构建检测模型之前,先将生成样本随机打乱,并依次添加到原始建模集中。分别采用PLSR、RF以及CNN构建定量检测模型来对DCGAN生成的数据在同一预测集上进行评估。由于CNN模型训练时间较长,无法将生成样本依次加入到建模集中,因此本研究在构建CNN回归模型中按比例在建模集中加入48、96、192、288、384个生成样本。
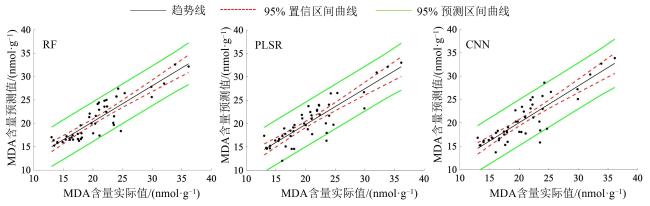
三种模型的检测结果如图6所示。在未添加生成样本时,不同模型在预测集上的R 2差异显著,其中RF模型的R 2为0.6967,RMSEP为2.7591;CNN模型的R 2为0.6729,RMSEP为3.1353;而PLSR模型的R 2仅为0.5298,RMSEP为3.6646。随后在建模集中逐步添加生成样本,可以看出,在加入生成样本后,3种模型的R 2在预测集上皆表现出先增大后减小的趋势,RMSEP则先减小后增大。表3为3种模型的最优训练结果,相较于未添加生成样本的预测精度Rp 2,CNN模型最高提升11.2%;RF模型最高提升13.7%;PLSR最高提升42.8%,且RF模型可以得到最佳的检测效果。Zhang等[31]利用近红外光谱对松树叶片的MDA含量进行估测,通过将光谱预处理与重要特征选择算法应用于PLSR,其最佳的R 2为0.66,但原始R 2为0.64,二者差距不大。本研究将原始样本进行数据扩增后建立3种回归模型,其检测精度均得到较好的提高。为了更加直观地表示模型的预测能力,图7为3种模型在最优样本数量下的菌草MDA含量预测值与实测值相关图。结果表明,利用DCGAN模型对原始建模集进行数据扩充可以获得更好的精度与稳定性。同时,充足的数据集有助于得到最优的检测结果。
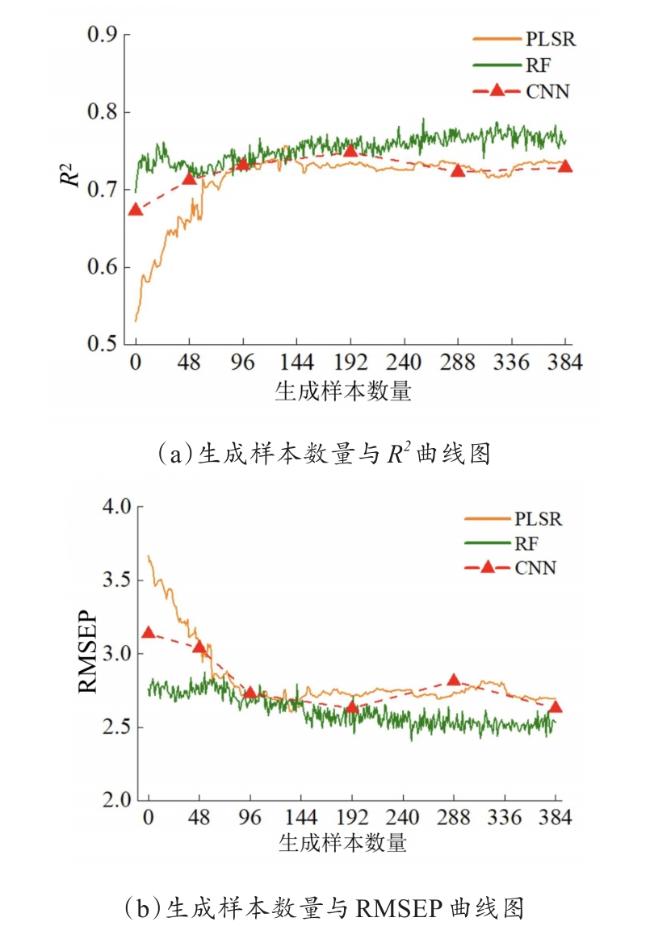
图6 添加不同生成样本数量的3种检测模型的R 2与RMSEP曲线图Fig. 6 R 2 and RMSEP curves of three detection models with different generated sample sizes added |
表3 建立不同模型的菌草MDA含量最优检测效果Table 3 Establishing different models for the optimal detection of MDA content in JUNCAO |
| 模型 选择 | 添加样本数量 | 训练集 | 预测集 | |||
|---|---|---|---|---|---|---|
| Rc 2 | RMSEC | RP 2 | RMSEP | RPD | ||
| PLSR | 134 | 0.8376 | 1.8781 | 0.7566 | 2.5263 | 2.0269 |
| RF | 248 | 0.8716 | 1.9817 | 0.7922 | 2.4063 | 2.1937 |
| CNN | 192 | 0.7512 | 2.7107 | 0.7484 | 2.6298 | 1.9936 |
4 结 论
本研究以低温胁迫下的6种菌草植株为研究对象,提出了一维DCGAN模型用于拓展样本数量,并结合PLSR、RF以及CNN模型对菌草MDA含量进行定量检测。研究表明:(1)低温胁迫后,菌草叶片的MDA含量相较于对照组会显著升高,其可见/近红外光谱反射率较于对照组也呈现增大趋势;(2)DCGAN模型能用于扩充样本数量,并且随着添加样本数量的增多,模型精度会呈现先升高后减小的趋势;(3)三种模型在数据扩充后的评价指标皆优于原始数据集,采用DCGAN联合RF模型可以获得最佳的MDA含量检测效果。
本研究可用于低温胁迫下小样本量菌草MDA含量的快速检测,可为菌草育种及低温胁迫诊断提供一定的理论依据和技术支持。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}