



1 引 言
2 材料与方法
2.1 干旱胁迫玉米叶片样本制备
2.2 高光谱图像采集

图1 用于采集玉米叶片光谱的高光谱成像系统(a)光谱相机与光源 (b)推扫控制器与样本放置处 Fig. 1 The hyperspectral imaging system used to collect maize leaf spectrum |
表1 高光谱相机主要技术参数Table 1 Specs of hyperspectral cameras |
| 技术参数 | 相机型号 | |
|---|---|---|
| FX10 | FX17 | |
| 光谱范围/nm | 400~1000 | 900~1700 |
| 光谱分辨率/nm | 5.5 | 8 |
| 狭缝宽度/µm | 30 | 30 |
| 空间像素数 | 1024 | 640 |
| 像素大小/µm | 8×8 | 15×15 |
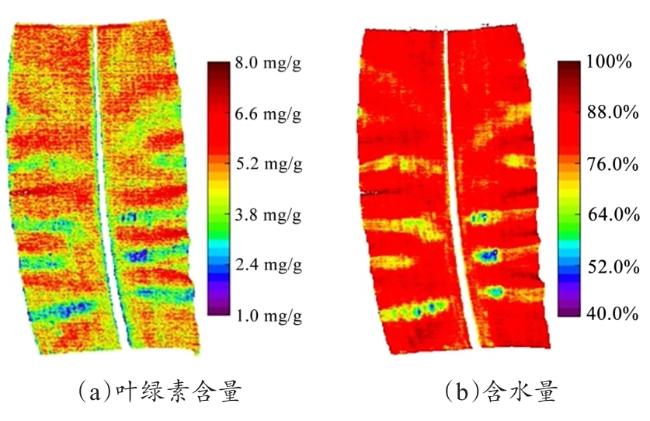
2.3 玉米叶片叶绿素含量与含水量测定
| (1) | ||
| (2) | ||
| C= 20.29 + 8.05 | (3) |
2.4 数据处理方法
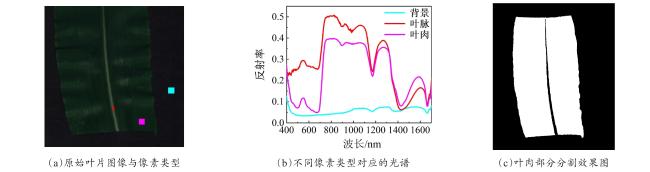
表2 常用传统植被系数Table 2 Traditional vegetation indices |
| 植被名称及计算公式 | 描述 | 参考 文献 | |
|---|---|---|---|
| GI= | (6) | 叶绿素 含量相关的植被系数 | [13] |
| CI_730 = | (7) | [14] | |
| CI_709 = | (8) | [14] | |
| Chl_green = | (9) | [15] | |
| NDRE = | (10) | [16] | |
| RGVI = | (11) | [17] | |
| MTCI = | (12) | [18] | |
| NDWI = | (13) | 含水量 相关的植被系数 | [19] |
| MSI = | (14) | [20] | |
| hNDVI = | (15) | [21] | |
| WI = | (16) | [22] | |
| SRWI = | (17) | [23] | |
| NDII = | (18) | [21] | |
|
3 结果与讨论
3.1 不同程度干旱胁迫下的玉米叶片光谱特征与变化趋势分析
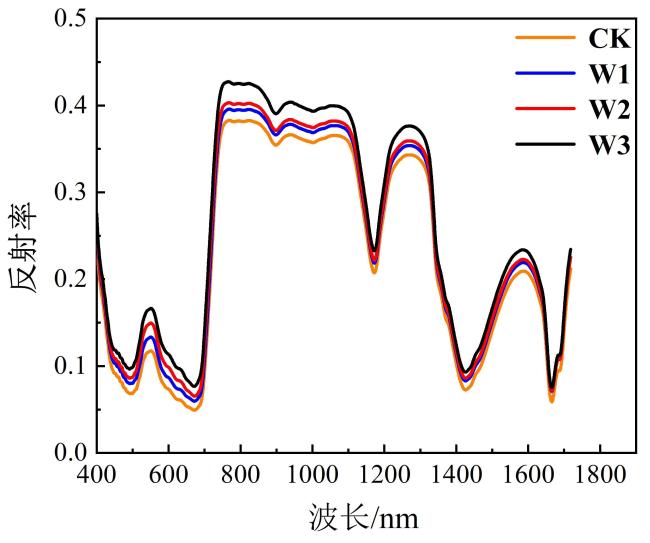
3.2 不同光谱预处理方法的性能比较
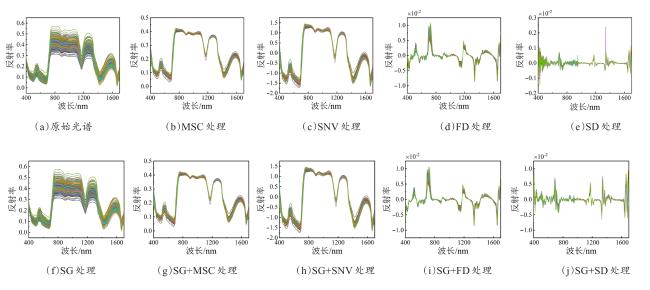
表4 不同预处理后光谱与原始光谱对叶绿素含量和含水量预测性能Table 4 Inversion performance of different pre-treated and original spectra for chlorophyll content and water content |
| 反演目标 | 预处理 方法 | 主成 分数 | 训练集 | 验证集 | ||
|---|---|---|---|---|---|---|
| 叶绿素含 量/(mg·g-1) | 无 | 10 | 0.857 | 0.307 | 0.839 | 0.312 |
| SG | 10 | 0.866 | 0.298 | 0.832 | 0.318 | |
| MSC | 11 | 0.867 | 0.297 | 0.831 | 0.312 | |
| SNV | 12 | 0.873 | 0.289 | 0.823 | 0.326 | |
| FD | 6 | 0.908 | 0.247 | 0.838 | 0.312 | |
| SD | 4 | 0.908 | 0.246 | 0.809 | 0.339 | |
| SG+MSC | 11 | 0.857 | 0.307 | 0.839 | 0.311 | |
| SG+SNV | 12 | 0.872 | 0.291 | 0.825 | 0.324 | |
| SG+FD | 6 | 0.884 | 0.277 | 0.830 | 0.320 | |
| SG+SD | 4 | 0.898 | 0.260 | 0.807 | 0.341 | |
| 含水量/% | 无 | 11 | 0.877 | 3.05 | 0.843 | 3.57 |
| SG | 11 | 0.877 | 3.09 | 0.843 | 3.58 | |
| MSC | 13 | 0.856 | 3.34 | 0.796 | 4.07 | |
| SNV | 14 | 0.863 | 3.26 | 0.702 | 4.92 | |
| FD | 5 | 0.849 | 3.42 | 0.624 | 5.53 | |
| SD | 4 | 0.868 | 3.20 | 0.710 | 4.85 | |
| SG+MSC | 13 | 0.855 | 3.35 | 0.796 | 4.07 | |
| SG+SNV | 14 | 0.861 | 3.28 | 0.706 | 4.89 | |
| SG+FD | 5 | 0.839 | 3.53 | 0.632 | 5.47 | |
| SG+SD | 4 | 0.862 | 3.27 | 0.734 | 4.65 | |
3.3 基于特征波长的玉米叶片叶绿素含量和含水量反演模型构建
3.3.1 特征波长提取结果分析
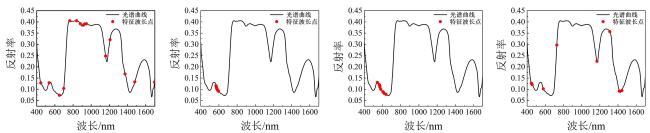
图6 各算法提取用于叶绿素含量反演的特征波长分布(a)SPA算法 (b)相关系数法 (c)RF算法 (d)SR算法 Fig. 6 Distributions of the characteristic wavebands extracted for chlorophyll content inversion by algorithms |

3.3.2 基于特征波长的反演模型性能分析
表5 不同模型对玉米叶片叶绿素含量的预测性能Table 5 Inversion results of different models for chlorophyll content of maize leaves |
| 特征波长提取方法 | 回归 方法 | 训练集 | 测试集 | ||
|---|---|---|---|---|---|
| /(mg·g-1) | /(mg·g-1) | ||||
| 无 | ANN | 0.849 | 0.292 | 0.812 | 0.394 |
| SVR | 0.854 | 0.288 | 0.865 | 0.334 | |
| KNN | 0.831 | 0.309 | 0.766 | 0.439 | |
| Stacking | 0.870 | 0.272 | 0.849 | 0.353 | |
| SPA | ANN | 0.898 | 0.241 | 0.816 | 0.390 |
| SVR | 0.845 | 0.297 | 0.806 | 0.400 | |
| KNN | 0.844 | 0.298 | 0.750 | 0.455 | |
| Stacking | 0.869 | 0.273 | 0.840 | 0.364 | |
| 相关系数 | ANN | 0.833 | 0.308 | 0.773 | 0.433 |
| SVR | 0.752 | 0.375 | 0.741 | 0.462 | |
| KNN | 0.596 | 0.479 | 0.587 | 0.584 | |
| Stacking | 0.761 | 0.368 | 0.775 | 0.431 | |
| RF | ANN | 0.807 | 0.331 | 0.774 | 0.432 |
| SVR | 0.764 | 0.366 | 0.735 | 0.468 | |
| KNN | 0.615 | 0.467 | 0.594 | 0.579 | |
| Stacking | 0.791 | 0.343 | 0.778 | 0.428 | |
| SR | ANN | 0.847 | 0.295 | 0.867 | 0.331 |
| SVR | 0.828 | 0.312 | 0.849 | 0.353 | |
| KNN | 0.810 | 0.328 | 0.796 | 0.410 | |
| Stacking | 0.855 | 0.287 | 0.878 | 0.317 | |

表6 不同模型对玉米叶片含水量的预测性能Table 6 Inversion performance of different models for the water content of maize leaves |
| 特征波长 提取方法 | 回归方法 | 训练集 | 测试集 | ||
|---|---|---|---|---|---|
| /% | /% | ||||
| 无 | ANN | 0.767 | 3.99 | 0.835 | 4.06 |
| SVR | 0.709 | 4.47 | 0.799 | 4.47 | |
| KNN | 0.777 | 3.92 | 0.804 | 4.41 | |
| Stacking | 0.792 | 3.78 | 0.857 | 3.78 | |
| SPA | ANN | 0.746 | 4.19 | 0.809 | 4.37 |
| SVR | 0.710 | 4.47 | 0.784 | 4.64 | |
| KNN | 0.812 | 3.60 | 0.827 | 4.16 | |
| Stacking | 0.815 | 3.58 | 0.859 | 3.75 | |
| 相关系数 | ANN | 0.597 | 5.28 | 0.711 | 5.37 |
| SVR | 0.508 | 5.83 | 0.595 | 6.36 | |
| KNN | 0.643 | 4.96 | 0.699 | 5.48 | |
| Stacking | 0.639 | 4.99 | 0.724 | 5.24 | |
| RF | ANN | 0.604 | 5.23 | 0.699 | 5.47 |
| SVR | 0.536 | 5.66 | 0.539 | 6.77 | |
| KNN | 0.639 | 4.99 | 0.695 | 5.51 | |
| Stacking | 0.633 | 5.04 | 0.762 | 4.87 | |
| SR | ANN | 0.753 | 4.13 | 0.821 | 4.22 |
| SVR | 0.719 | 4.40 | 0.805 | 4.41 | |
| KNN | 0.764 | 4.03 | 0.781 | 4.67 | |
| Stacking | 0.785 | 3.85 | 0.848 | 3.90 | |

3.4 基于植被系数的玉米叶片含水量和叶绿素含量反演模型构建
表7 不同植被系数对叶绿素含量和含水量的预测性能Table 7 Performance of different vegetation indices in the inversion of chlorophyll content and water content |
| 反演目标 | 植被系数 | 训练集 | 测试集 | ||
|---|---|---|---|---|---|
| 叶绿素含量/(mg·g-1) | GI | 0.130 | 0.704 | 0.015 | 0.902 |
| CI_730 | 0.281 | 0.640 | 0.150 | 0.838 | |
| CI_709 | 0.367 | 0.601 | 0.292 | 0.765 | |
| Chl_green | 0.523 | 0.522 | 0.438 | 0.687 | |
| NDRE | 0.300 | 0.632 | 0.187 | 0.819 | |
| RGVI | 0.126 | 0.706 | 0.012 | 0.903 | |
| MTCI | 0.271 | 0.645 | 0.208 | 0.809 | |
| 含水量/% | NDWI | 0.034 | 8.25 | 0.015 | 10.74 |
| MSI | 0.324 | 6.14 | 0.150 | 9.51 | |
| hNDVI | 0.204 | 7.01 | 0.293 | 8.20 | |
| WI | 0.400 | 5.68 | 0.338 | 7.80 | |
| SRWI | 0.300 | 6.31 | 0.187 | 9.13 | |
| NDII | 0.126 | 7.55 | 0.012 | 10.77 | |

图10 新构建植被系数与叶绿素含量和含水量相关系数热力图Fig. 10 Heat maps of correlation coefficients between the newly constructed vegetation coefficients and chlorophyll content and water content, respectively |
表8 新构建的植被系数对应的相关系数最大值及波长位置Table 8 The maximum correlation coefficient and wavelength position corresponding to the newly constructed vegetation coefficient |
| 植被系数 | 叶绿素含量 | 含水量 | ||
|---|---|---|---|---|
| 波长位置(i,j)/nm | 波长位置(i,j)/nm | |||
| DI | 0.882 | (420,558) | 0.783 | (742,1681) |
| RI | 0.892 | (420,559) | 0.898 | (400,1171) |
| NDVI | 0.889 | (410,559) | 0.890 | (410,1348) |
表9 新构建植被系数对叶绿素含量和含水量预测性能Table 9 The inversion performance of the newly constructed vegetation coefficients for chlorophyll content and water content |
| 反演目标 | 植被系数 | 回归方程 | 训练集 | 测试集 | ||
|---|---|---|---|---|---|---|
| 叶绿素含量/(mg·g-1) | DI(420,558) | y=28.96x+1.959 (22) | 0.769 | 0.363 | 0.785 | 0.421 |
| RI(420,559) | y= ‒8.691x+10.914 (23) | 0.774 | 0.358 | 0.791 | 0.415 | |
| NDVI(410,559) | y=15.13x+2.268 (24) | 0.784 | 0.351 | 0.803 | 0.403 | |
| 含水量/% | DI(742,1681) | y=2.014x+1.340 (25) | 0.731 | 3.42 | 0.799 | 3.53 |
| RI(400,1171) | y= ‒0.9413x+1.5327 (26) | 0.788 | 3.04 | 0.827 | 3.28 | |
| NDVI(410,1348) | y= ‒1.526x+0.5752 (27) | 0.775 | 3.12 | 0.807 | 3.46 | |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}