



0 引 言
深度学习是一种数据驱动型方法,该类方法在训练时需要大量已标注的训练样本。而世界目前现存昆虫种类高达百万种[6],构建包含所有种类的害虫数据集是不可能的任务,因此,在实际应用过程中遇见训练集(可见类害虫)中没有出现过的害虫类别(不可见类害虫)是在所难免的,这里的不可见仅指缺少该类图片,但其特征描述信息是可获取的。当面临这种不可见害虫的识别问题,传统的识别模型就无能为力。零样本学习(Zero-shot Learning, ZSL)为解决这一问题带来了契机。ZSL是指在训练期间只需要来自可见类别的图像,但在测试过程中具有识别不可见类别的能力。ZSL的概念是在2008年由Larochelle等[7]首次提出,旨在解决没有足够带标签的训练数据来覆盖所有类别的分类问题。不同于以往的深度学习,ZSL旨在训练一个模型,在语义信息的帮助下,通过迁移从可见类别获得的知识,对不可见类别物体进行识别。语义信息的获取方式可以是手工定义的属性向量、自动提取的词向量、基于上下文的嵌入,或者它们之间的组合[8]。ZSL就是使用语义信息来弥合可见类和不可见类之间的差距,构建从可见类到不可见类的桥梁,进而实现对不可见类的识别。
关于ZSL,近年来已经得到了极大的发展。Mishra等[9]训练一个条件变分自编码器[10](Conditional Variational Autoencoders, CVAE)来学习以语义向量为条件的图像特征潜在概率分布,然后通过生成不可见类的视觉特征来训练一个支持向量机[11]作为最终的分类器;Xian等[12]提出的f-CLSWGAN通过以不可见类的语义属性和随机噪声为条件来合成不可见类的视觉特征,该模型基于Wasserstein距离的生成对抗网络[13](Wasserstein Generative Adversarial Network, WGAN),通过补偿因不可见类训练样本不足而导致的可见类和不可见类样本数量不平衡问题,将伪视觉特征作为训练数据的组成部分,把ZSL问题转换为传统的监督学习问题;Han等[14]提出,在将真实视觉特征嵌入到新空间时,使用无冗余特征形成类关系并消除冗余信息,它使特征在这个新空间中更具区分性;Han等[15]构建了一个对比学习框架CE-GZSL,通过基于实例对比和类级对比,鼓励生成器产生更具区分性的视觉特征。有关ZSL在农业领域的研究才刚刚起步,Zhong等[16]提出了一种新的基于条件对抗自编码器(Conditional Adversarial Autoencoders, CAAE)的柑橘病害零样本识别生成模型,通过综合视觉特征,将零样本和少样本识别转化为常规的监督分类问题。然而,相关研究在农业害虫推理识别领域还鲜有报道。
针对当前害虫识别中由于缺少图片而无法识别的问题,本研究尝试将ZSL这一概念引入害虫识别领域,首先构建一个害虫图像及其语义数据集,通过人工定义的属性特征来进行语义编码,更好地表征害虫语义信息,然后在上述CE-GZSL方法的基础上进一步改进,引入视觉-语义对齐模块,通过约束生成器,使得生成的视觉特征更符合原始语义信息,最终构建一个可以对不可见类别进行推理的零样本害虫识别模型并进行评估。
1 数据与方法
1.1 数据采集与处理
为了获取多样性的害虫数据,提高语义描述的准确性与全面性,本研究数据采集方式包括相机田间拍摄和网络爬取。相机拍摄采用的相机型号为尼康D200,图像采集区域为北京周边郊区不同位置,时间跨度为多年。网络爬取的图片主要采用搜索引擎从网络上获取。最终数据集中包含20种害虫的样本图像,均为昆虫纲鳞翅目成虫。害虫样例如图1所示。通过对采集照片中重复的数据及网络爬取图片中的噪声数据进行剔除。最终构建的数据集包含图片数量为2 000张,类别为20类,每一类100张,其中相机拍摄的照片数量总占比为5%。

1.2 语义标注与编码
ZSL需要目标语义信息的辅助来实现从可见类到不可见类的知识迁移,在模型构建过程中,本研究在参考了CUB(Caltech-UCSD Birds-200-2011)[17]数据集的标注方式基础上,对害虫属性进行描述定义。具体如图2所示,从昆虫的触角、背部、尾部、足部、翅膀以及整体等6个部分出发,在颜色、图案、大小、形状等4个方面进行了属性定义,然后对数据集中每一张图片进行了标注,为每一类害虫形成一个65维的属性向量,最后将所有类别的属性向量放在一起构成一个20×65维语义属性矩阵,如图3所示。该矩阵每一行对应一个类别,每列包含一个数值,对应着一个属性。该数值代表该属性存在于给定类中的比例,即该类中存在该属性的图片数量占该类图片总数的比例。图3为该语义矩阵正则化后的可视化热图,可以看到,以绿尾大蚕蛾、榆绿天蛾、褐边绿刺蛾等几种昆虫为例,由于它们的翅膀大多都是呈现绿色,因此热图中翅膀绿色位置的颜色就更深,说明该属性占比更大,通过这种方式来实现对害虫的语义编码。


1.3 识别模型构建
生成对抗网络(Generative Adversarial Network, GAN)是Goodfellow等[18]在2014年提出的框架。GAN旨在生成与给定数据集相似的数据样本,其背后的基本思想是两个神经网络:生成器(Generator)和判别器(Discriminator),在训练中相互竞争,相互提升。GAN的提出为ZSL问题提供了一种解决方案。该方法可以通过生成不可见类的视觉特征来缓解可见类和不可见类数量不平衡问题。生成器G通过生成不可见类别的伪视觉特征,将伪视觉特征作为最终分类器训练数据的组成部分,从而将ZSL问题转换为传统的监督学习问题。
图4为本研究提出的VSA-WGAN模型框架图,主要包括WGAN、对比学习模块和视觉-语义对齐模块三部分。各个部分主要功能如下: WGAN为模型的主体框架,由生成器G和判别器D组成;对比学习模块通过使一个批次中的正样本尽可能相互靠近,而负样本尽可能远离的方式来捕捉类与类之间极强的判别信息,使得生成的视觉特征更具判别性;语义-视觉对齐模块通过将视觉和语义嵌入到一个共同空间中,通过交叉熵损失函数优化两者的余弦相似度来使两者尽可能对齐,从而进一步约束生成器G,优化其生成质量。
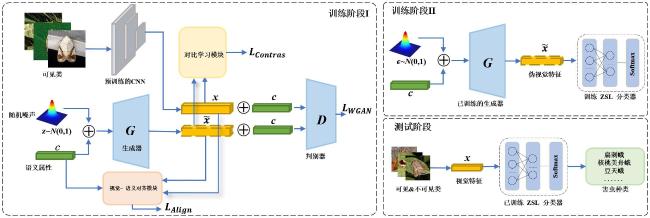
整个模型的训练及测试流程如下:在训练阶段,使用可见类图片以及可见类的语义信息训练生成对抗网络。具体包括三大部分:生成器G以语义信息和随机噪声为输入生成伪视觉特征 ,随后 会和真实样本 一起与对应语义拼接后输入判别器D,产生判别损失;其次,使用原始 和语义 训练好视觉-语义对齐模块后,生成的 会和其对应语义信息 一起被输入到该模块来评估生成质量好坏,产生的对齐损失会反馈给生成器G,实现语义指导生成;对比学习模块则使用自监督方式,分别以生成的特征 和原始的特征 为输入产生对比损失。当网络训练完成后,得到训练好的生成器G。随后,将语义和随机噪声拼接在一起,输入到训练好的G中来生成一定数量的伪视觉特征,由于这些伪视觉特征都是由对应语义生成的,所以都是带标签的。因此采用监督学习,使用这些特征及其对应标签训练一个ZSL分类器,它只包含一层线性全连接层和一层softmax输出层。对于ZSL,生成伪视觉特征使用的语义都是不可见类的,而对于广义零样本学习(Generalized Zero-Shot Learning, GZSL)来说,使用的语义包括可见类和不可见类。在测试阶段,将测试的害虫图像输入到网络中,经过前面已经训练好的ZSL分类器判定,可推断图像所属种类。
1.3.1 对抗网络(WGAN)
对于给定数据集,模型旨在学习一个条件生成器G: ,它将高斯随机噪声 与类别属性向量 拼接在一起作为输入,最终输出伪视觉特征 。而判别器D: ,它是一个多层感知器(Multilayer Perceptron, MLP),将视觉特征 和属性向量 拼接起来作为输入,最后一层为sigmoid函数,从而来判断输入的视觉特征 是真实的还是合成的。损失函数如公式(1) 所示。
式中: 为WGAN的损失函数; 为惩罚系数; 和 分别如公式(2) 和公式(3) 所示。
生成器G尽可能通过生成真实的视觉特征来欺骗判别器D,而D则试图准确区分真实视觉特征和生成的伪视觉特征,两者通过这种方式不断对抗优化。
1.3.2 对比学习模块
对比学习作为一种非监督学习方法,在计算机视觉领域得到了广泛的应用。CE-GZSL通过构建一个对比学习框架,从基于实例的对比和基于类级的对比两个方面,鼓励生成器G生成更具判别性的视觉特征。由于害虫体积较小,不同害虫之间有的尺寸、颜色、形状以及语义描述相近,但有的相差甚远。而对比学习的核心思想正是将两个相似的正样本尽可能靠近,而让不相似的两个负样本尽可能分离,因此将对比学习引入害虫零样本识别能使生成网络G生成更具判别力的视觉特征,从而分类效果更好。其结构如图5所示。
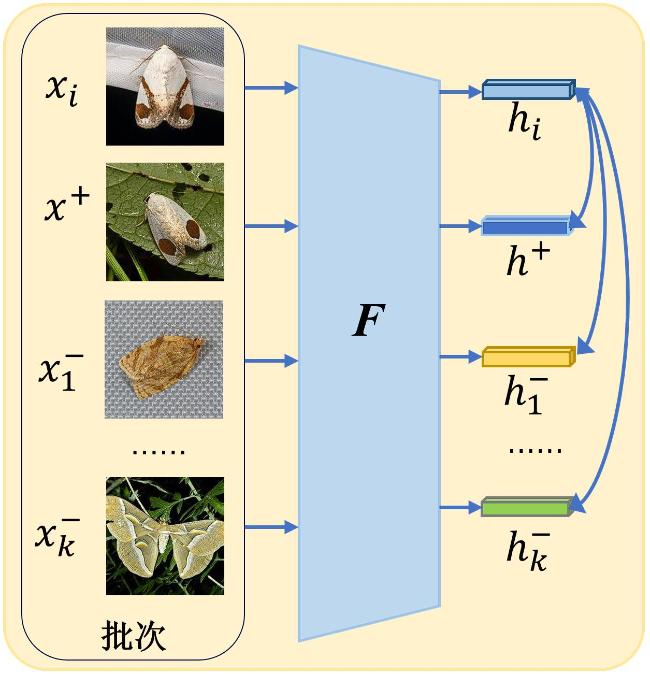
对应的损失函数如公式(4) 所示。
式中: 为对比学习模块的损失函数;k是负样例的总数;τ是温度超参数,τ>0。通过对比学习这种方式,大量的负样本能使生成器G捕捉到不同类别中极强的判别信息,从而使得生成效果更好[15]。
1.3.3 视觉-语义对齐模块
本研究使用的方法属于生成式方法,通过生成伪视觉特征将ZSL问题转换为传统的监督学习问题。因此模型识别的效果与合成的伪视觉特征直接相关,也就是与生成器G的生成质量相关。生成器G生成的视觉特征越符合原始语义,说明生成质量越好[8]。实际上,生成的视觉特征和对应的语义是以不同的模态表示相同的东西,一个是语义模态,一个是视觉模态。因此,生成的视觉特征与原始语义特征越一致,最终训练的分类器的分类效果越好。为了使得生成的视觉特征更符合其原始语义,确保视觉、语义更好地一一对应,受CLIP(Contrastive Language-Image Pretraining)[19]启发,本研究设计了“视觉-语义对齐”模块,来进一步约束生成器G,优化视觉合成质量。
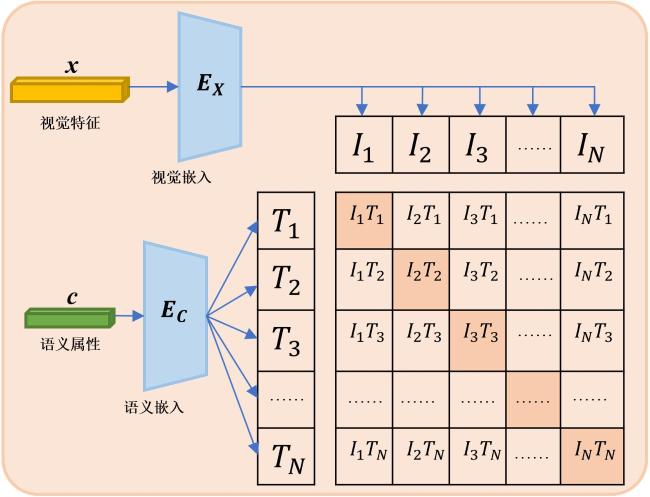
其中视觉嵌入和语义嵌入都只含一层线性的映射层,将视觉特征向量和语义向量映射成同样的维度。在训练时,对于每一个样本对 ,将其分别通过线性映射层,输出后为 , 和 具有相同的维度。训练过程包含两部分损失,一部分是视觉到语义的对齐损失,另一部分是语义到视觉的对齐损失,因此对于第i对样本对,其损失函数如公式(5) 所示。
式中: 为第i对样本对的损失; 表示余弦相似度; 为温度超参数;k为样本量。对于一个Batch中N个样本,总的对齐损失函数 则为公式(6) 。
在训练阶段,先将训练集可见类的样本对 通过线性映射层,计算其对齐损失,并更新映射层的权重,训练好一个视觉-语义对齐的嵌入空间。随后,冻结映射层权重,将生成器G生成的样本对 通过映射层,再计算此时的对齐损失,若对齐损失过大,说明生成的 质量较差,不符合其对应的语义信息,将该损失反馈给生成器G,这样能保证生成的 受到语义的约束,实现语义指导视觉生成。
最终模型总的损失函数 为公式(7) 。
1.4 试验设置
试验环境基于Ubuntu 20.04.5 LTS操作系统,硬件为NVIDIA RTX 3090 GPU,内存为64 G,CUDA版本为11.7,使用Python 3.8编程语言和Pytorch 2.0.1深度学习框架。
1.4.1 害虫图像特征
1.4.2 评价指标
在测试时,由于ZSL范式中的测试集只包含不可见类别样本,常用的评价指标是所有类别的平均Top-1指标。该指标是指所有预测正确的样本数占测试集样本总数的比例,如公式(8) 所示。
式中: 为Top-1精度;n为测试集样本总数;I为指示函数,测试时对图片类别预测正确为1,预测错误为0; 为样本真实类别; 为预测类别。
在GZSL,测试集不仅包含可见类,还有不可见类,因此为了综合评估模型性能,分别计算模型在可见类和不可见类上的Top-1精度,综合性能则由它们的调和平均值H来衡量,如公式(9) 所示。
式中:S为在可见类上的Top-1准确率;U为不可见类上的Top-1准确率。
1.4.3 参数细节
生成器G和判别器D都包含一个4 096单元的隐藏层,具有LeakyReLU激活,优化器使用Adam[22],学习率为0.000 01,迭代次数为1 000次。对比学习模块中,非线性投影F的输出 的维度设置为512,视觉-语义对齐模块中视觉嵌入和语义嵌入的输出维度均为512,ZSL分类器只由输入层、输出层和Softmax层组成,学习率为0.001,迭代次数100次。随机噪声 维度和语义向量维度保持一致,均为65维。
2 结果与分析
2.1 公共数据集
表1 零样本公共数据集详细信息Table 1 Statistics for ZSL public datasets |
| 数据集 | 可见类数量/类 | 不可见类数量/类 | 属性维度/维 | 样本数/个 |
|---|---|---|---|---|
| CUB | 150 | 50 | 312 | 11 788 |
| AWA1 | 40 | 10 | 85 | 30 475 |
| AWA2 | 40 | 10 | 85 | 37 322 |
| SUN | 645 | 72 | 102 | 14 340 |
| FLO | 82 | 20 | 1 024 | 8 189 |
使用在ImageNet-1K上预训练的ResNet101提取了上述5个公开数据集的2 048维卷积神经网络(Convolutional Neural Network, CNN)特征,没有进行微调。并且采用Xian等[24]所提出的数据集划分方式将所有类划分为可见类和不可见类。AWA1和AWA2的批处理大小均为4 096,CUB为2 048,FLO为3 072,SUN为1 024。
2.1.1 公共数据集结果
将所提方法与近期的GZSL方法进行对比,结果如表2和表3所示,表中所有方法都属于归纳式(Inductive)方法,也就是在训练期间不允许使用不可见类图像。从表2可以看到,在ZSL设置下,本研究方法在CUB数据集上取得了最优的结果,在AWA1、FLO上取得了次优的结果。其中CUB提升较大,比次优方法CE-GZSL提升了1.8%;从表3能看到,在GZSL设置下,本研究在CUB数据集的U、S和H指标上取得了最优结果,相比次优方法分别提升了5.2%、0.4%和2.8%,在AWA2的U和H指标上取得了最优结果,较之前方法分别提升了0.3%和0.1%,这说明本方法能较好地将语义特征泛化到不可见类,从而生成更具判别性的特征,提高了不可见类的分类性能,并且同时在U和S之间保持了较好的平衡。除此之外,在AWA1数据集中的U、S和H指标,SUN中的U指标和FLO的H指标取得了次优结果。总的来说,本方法在CUB和AWA2数据集上取得了不错的提升,同时在AWA1、SUN和FLO数据集上也有不错的表现。值得一提的是,本方法在CUB上的所有指标均取得了目前最优结果,并且是所有数据集中提升最大的,考虑到CUB数据集和本研究的害虫数据集最为接近,都是同一物种的数据集,这说明本研究方法在这类数据集上具有优势。
表2 VSA-WGAN在5个公共数据集零样本实验结果Table 2 ZSL results of VSA-WGAN on five public datasets |
| 方法 | 零样本 | ||||
|---|---|---|---|---|---|
| CUB | AWA1 | AWA2 | SUN | FLO | |
| SE-GZSL[27] | 59.6 | 69.5 | 69.2 | 63.4 | — |
| f-CLSWGAN[12] | 57.3 | 68.2 | — | 60.8 | 67.2 |
| cycle-CLSWGAN[28] | 58.4 | 66.3 | — | 60.0 | 70.1 |
| f-VAEGAN[29] | 61.0 | — | 71.1 | 64.7 | 67.7 |
| LisGAN[30] | 58.8 | 70.6 | — | 61.7 | 69.6 |
| OCD-CVAE[31] | 60.3 | — | 71.3 | 63.5 | — |
| TF-VAEGAN[32] | 64.9 | — | 72.2 | 66.0 | 70.8 |
| CE-GZSL[15] | 77.5 | 71.0 | 70.4 | 63.3 | 70.6 |
| VSA-WGAN | 79.3 | 70.9 | 70.2 | 62.6 | 70.7 |
|
表3 VSA-WGAN在5个公共数据集广义零样本试验结果Table 3 GZSL results of VSA-WGAN on five public datasets |
| 方法 | CUB | AWA1 | AWA2 | SUN | FLO | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| U | S | H | U | S | H | U | S | H | U | S | H | U | S | H | |
| SE-GZSL | 41.5 | 53.3 | 46.7 | 56.3 | 67.8 | 61.5 | 58.3 | 68.1 | 62.8 | 40.9 | 30.5 | 34.9 | — | — | — |
| f-CLSWGAN | 43.7 | 57.7 | 49.7 | 57.9 | 61.4 | 59.6 | — | — | — | 42.6 | 36.6 | 39.4 | 59.0 | 73.8 | 65.6 |
| DAZLE[33] | 56.7 | 59.6 | 58.1 | — | — | — | 60.3 | 75.7 | 67.1 | 52.3 | 24.3 | 33.2 | — | — | — |
| cycle-CLSWGAN | 45.7 | 61.0 | 52.3 | 56.9 | 64.0 | 60.2 | — | — | — | 49.4 | 33.6 | 40.0 | 59.2 | 72.5 | 65.1 |
| f-VAEGAN | 48.4 | 60.1 | 53.6 | — | — | — | 57.6 | 70.6 | 63.5 | 45.1 | 38.0 | 41.3 | 56.8 | 74.9 | 64.6 |
| CADA-VAE[34] | 51.6 | 53.5 | 52.4 | 57.3 | 72.8 | 64.1 | 55.8 | 75.0 | 63.9 | 47.2 | 35.7 | 40.6 | — | — | — |
| LisGAN | 46.5 | 57.9 | 51.6 | 52.6 | 76.3 | 62.3 | — | — | — | 42.9 | 37.8 | 40.2 | 57.7 | 83.8 | 68.3 |
| OCD-CVAE | 44.8 | 59.9 | 51.3 | — | — | — | 59.5 | 73.4 | 65.7 | 44.8 | 42.9 | 43.8 | — | — | — |
| TF-VAEGAN | 52.8 | 64.7 | 58.1 | — | — | — | 59.8 | 75.1 | 66.6 | 45.6 | 40.7 | 43.0 | 62.5 | 84.1 | 71.7 |
| FREE[35] | 55.7 | 59.9 | 57.7 | 62.9 | 69.4 | 66.0 | 60.4 | 75.4 | 67.1 | 47.4 | 37.2 | 41.7 | 67.4 | 84.5 | 75.0 |
| CE-GZSL | 63.9 | 66.8 | 65.3 | 65.3 | 73.4 | 69.1 | 63.1 | 78.6 | 70.0 | 48.8 | 38.6 | 43.1 | 69.0 | 78.7 | 73.5 |
| VSA-WGAN | 69.1 | 67.2 | 68.1 | 63.8 | 74.8 | 68.9 | 63.4 | 78.3 | 70.1 | 51.0 | 35.2 | 41.7 | 66.7 | 83.6 | 74.2 |
|
2.1.2 T-SNE可视化
图7是使用T-SNE将CUB、AWA1、AWA2和FLO数据集进行可视化的结果。其中原始特征是直接使用预训练的ResNet101从不可见类图片中提取的视觉特征,而合成视觉特征是将不可见类语义与随机噪声拼接输入生成器G生成的伪视觉特征,不同的颜色代表不同的种类,而CUB由于不可见类种类过多,为了区分不同类别在图中将对应种类的标签进行了标注。通过对比能看出,在合成的可视化图中属于同一类的样本距离较近,基本都聚在一起,而不属于同一类的样本相距较远,并且类与类之间的分布情况基本符合真实数据的分布,这说明本研究模型的生成器G的生成质量很高,生成的样本符合真实数据的分布,具有很好的泛化能力,能很好的将语义信息从可见类迁移至不可见类。即使在图7h合成FLO图中某些类别出现了比较严重的边界混淆,也是因为其原始类分布的对应类别有一定的分布混淆。

2.2 自建害虫数据集
2.2.1 试验结果
为了评估本研究方法在害虫零样本识别上的效果,在自建20类害虫数据集上进行了试验。同时为了消除不同划分方式对试验结果的影响,试验采用五折交叉验证,随机划分可见类和不可见类,每次试验划分数据集16类为可见类,4类为不可见类,最终试验结果取5次结果的平均值。
由于零样本和广义零样本的试验是相互独立的,为了充分利用害虫数据集,在零样本设置下,划分训练集为16类可见类,测试集为4类不可见类,每一类均为100张图片;在广义零样本设置下,将训练集16类可见类每一类随机划分20张图片为测试集的可见类,最终数据集为:训练集16类可见类,每一类80张,测试集包括4类不可见类,每一类100张,以及16类可见类,每一类20张,如表4所示。
表4 自建20类害虫数据集的划分方式Table 4 The split of the proposed dataset of 20 pest classes |
| 设置 | 训练集 | 测试集 |
|---|---|---|
| 零样本 | 16类 100张 | |
| 广义零样本 |
将ZSL领域有代表性的几种方法:CVAE、f-CLSWGAN和CE-GZSL在自建害虫数据集上进行了试验,结果如表5所示,相比基于变分自编码器的CVAE,VSA-WGAN在ZSL设置下精度提升了17.8%,在GZSL设置下的U、S和H分别提高了44.7%、20.5%和40.2%;相比f-CLSWGAN,本研究方法在ZSL设置下精度提升了3.8%,在GZSL设置下的三个指标分别提升了15.3%、14.8%和15.1%;而相比基准方法CE-GZSL,本研究方法也取得了较大的提升,分别在ZSL设置下精度提高了2.1%,在GZSL设置下U、S和H分别提高了2.0%、0.1%和1.2%,这说明本研究提出的视觉-语义对齐模块很好地约束了生成器G,使得生成的视觉特征更具有判别性、更符合该类别的原始语义。
由于ImageNet 1K中包含的害虫类别较少,直接使用预训练模型用于害虫特征提取有可能存在不能充分提取图像特征、领域不适应等问题。为此,将预训练的ResNet101在害虫数据集上进行了微调,然后用于特征提取,结果见表5。通过结果能看到,微调后的模型相比微调前的取得了一定的提升,在零样本设置下提升了0.8%,广义零样本设置下的H提升了0.9%,这说明微调后的ResNet101能更好提取害虫特征,表征能力更强。
2.2.2 消融试验
为了直观展现各个模块的作用和性能,在自建害虫数据集上进行了消融试验,结果如表6所示。
表6 VSA-WGAN在自建害虫数据集上的消融试验结果Table 6 Ablation results of VSA-WGAN on the proposed pest dataset |
| 方法 | 零样本 | 广义零样本 | ||
|---|---|---|---|---|
| U | S | H | ||
| 66.6 | 59.3 | 80.4 | 67.9 | |
| 68.2 | 59.1 | 82.6 | 68.7 | |
| 69.6 | 64.9 | 86.4 | 73.8 | |
| 77.4 | 72.0 | 86.4 | 78.3 | |
通过表6能看到,通过在基准模型WGAN上添加视觉-语义对齐模块,分别在零样本的精度T 1和广义零样本的调和精度H下取得了1.6%和0.8%的提升;将对比模块添加到WGAN中,取得了3.0%和5.9%的提升;而在对比模块基础上再添加视觉-语义模块则取得了10.8%和10.4%的提升,这说明本研究提出的视觉-对齐模块能较大幅度提升模型性能,优化生成器的生成质量。
2.2.3 超参数分析
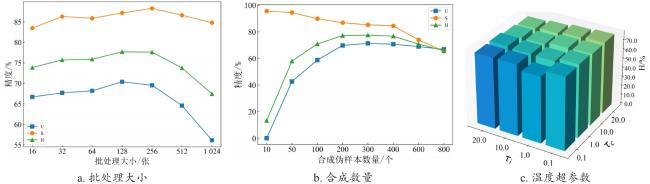
由于本研究在很多地方大量应用到了对比学习的思想,而对比学习的效果直接与批处理的大小(Batch size)直接相关。当批处理的大小足够大,能确保同一批次中有大量的负样本,大量的负样本能使得生成器G捕捉到极强的判别性信息,这样训练出来的模型效果更好。从图8a中能看出,当批处理大小增加时,U、S和H指标都随之增加;但当批处理大小过大,三个指标出现了急剧下降,说明生成器G出现了模式崩溃问题,导致生成质量下降。本研究在批大小为256时取得了最好的H。
不可见类样本的合成数量也会极大影响最后分类器的精度,如果合成数量过少,最终的分类器拟合效果不佳,不可见类识别精度较低;若合成数量过多,模型会过拟合,识别偏向不可见类。本研究评估了不可见类的不同合成样本数量对试验结果的影响,如图8b所示。随着合成数量增加,模型性能会随着合成样本数量的增加而提高,可见类精度会有轻微下降,但是不可见类识别精度极大地提高了,这说明模型缓解了可见类与不可见类的偏见问题;但当不可见类合成数量过多时,模型会偏向不可见类,导致H值下降。本研究在不可见类合成数量为200时取得了最好的H值。图8c是温度超参数对结果的影响,其中 和 分别为实例级温度超参数和类级温度超参数。本研究在 和 分别为0.1和1时取得了最好结果。
2.2.4 不同语义向量的影响分析
获取语义信息的方法可以是手工定义的属性向量或者自动提取的词向量。本研究选择了手工定义的属性向量作为语义信息的表示方式。为了比较不同语义向量对模型性能的影响,设计了词向量语义编码进行对比研究。
首先,从最新的开源维基百科中文文章中获取大量的训练语料,该训练语料囊括了政治、经济、生物等各个领域的中文语料,语料库一共包含452 966条文本。但这些中文语料中包含的害虫百科信息较少,自建害虫数据集中有些类别在语料库中甚至没有出现,为此,人工收集了数据集所有20类害虫的百科文本,将这些文本加入到维基语料库中。随后,对语料库进行了去标点符号、分词等一系列操作,并将其放入模型进行训练。
采用Word2Vec[36]模型,词向量的维度设置为100维,并使用Skip-gram模式进行训练,这样能更好联系上下文,例如害虫的特征上下文和习性上下文。训练迭代次数为100次。当模型训练完成后,就可以根据害虫名称获取其对应的词向量,最终得到一个 的语义向量矩阵。图9a展示了20类害虫词向量语义特征通过T-SNE映射到二维空间中的可视化图,两个类别之间的距离越接近,它们的相似度就越高。例如,花椒凤蝶和碧凤蝶这两个类别都属于碟类昆虫,它们的体态特征和习性相似,所以它们的语义特征也相近,在图中相距很近。而绿尾大蚕蛾和苹小卷叶蛾这两个类别不仅在体态上有明显的差距,习性也截然不同,所以它们之间的距离较远。
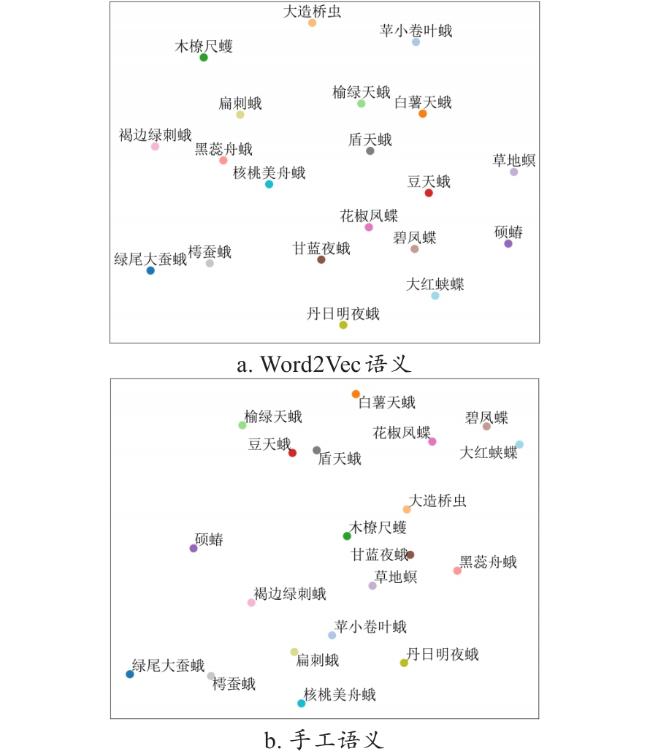
此外,将手工定义的65维语义向量也进行了T-SNE可视化,如图9b。通过与词向量语义的对比,可以观察到手工定义的语义向量能更准确地表征害虫的特征。具体表现在具有相同特征的害虫在空间中更加接近,而具有不同特征的害虫则相距较远,类与类之间的关系更符合实际情况。比如豆天蛾和榆绿天蛾,两者在体态特征上十分接近,相比于词向量语义,手工语义更为接近真实情况;又比如硕蝽和碧凤蝶,两者在视觉特征上相差较大,习性也各不相同,在T-SNE可视化图中应该相隔较远,但词向量语义并没有将两者很好地区分出来,手工语义却很好地做到了这一点。因此通过手工定义语义向量,能进一步增强语义特征的判别性,使得模型更好地理解和区分不同害虫,从而识别性能更好。
表7为两种语义编码方式在最终试验中的表现,无论是ZSL设置下还是GZSL设置下,手工定义的语义向量比Word2Vec提取的词向量效果好很多:其中ZSL设置下高了13.6%,GZSL设置下的U、S、H分别高了20.1%、15.3%、19.3%。这说明手工定义的语义特征比词向量更具判别性。
表7 VSA-WGAN在害虫数据集上不同语义编码试验结果Table 7 Results of VSA-WGAN on the proposed pest dataset under different semantic features |
| 语义编码 | 属性维度/维 | ZSL | GZSL | ||
|---|---|---|---|---|---|
| U | S | H | |||
| Word2Vec | 100 | 63.8 | 51.9 | 71.1 | 59.0 |
| 手工定义(本研究) | 65 | 77.4 | 72.0 | 86.4 | 78.3 |
|
2.2.5 小样本试验分析
小样本学习(Few-Shot Learning)是指在只有非常少量样本用于训练的情况下进行机器学习任务。为了评估本模型在小样本情况下的表现,从4类不可见类中随机抽取少量图片加入训练集中,其余参数设置和前文保持一致,结果如图10所示。
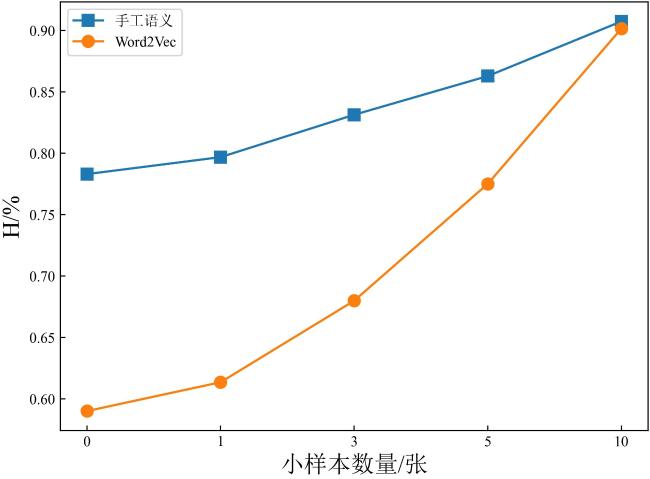
横坐标是从每一类不可见类中随机抽取加入到训练集的图片数量,纵坐标为调和平均数。从图10可以观察到,通过添加少量的不可见类图片,H值得到了极大提高。具体来说,通过添加1张不可见类图片,在手工语义和Word2Vec语义两种设置下,调和精度平均上升了2%;添加3张图片,调和精度平均上升了6%;而添加5张,这个提升平均达到了14%左右,这表明本研究的模型通过只添加少量不可见类样本,可以显著提高识别性能。值得注意的是,相较于手工语义,Word2Vec语义的曲线增长尤其快,这说明通过添加不可见类图片,本方法极大地弥补了不同语义之间带来的性能差距。
3 结 论
本研究将ZSL理论引入害虫识别领域,旨在克服传统基于深度学习的害虫识别方法只能对训练集中存在的类别进行识别方面的不足,使模型在面对训练集中没有出现过的害虫类别仍能进行推理辨识,提升模型的泛化能力。具体结论如下。
1)构建了一个包含20类鳞翅目害虫图像-语义数据集,共包含2 000张图像和一个20×65维的语义矩阵。
2)通过添加视觉-语义对齐模块,更好地约束了GAN中的生成器G,优化了生成质量,提升了模型性能。试验表明,本研究所提方法能很好地将可见类特征泛化到不可见类从而实现对不可见类的识别。在CUB、AWA2数据集上取得了最优结果,在AWA1、SUN、FLO也取得了极有竞争力的结果;在自建数据集上分别实现了ZSL设置下的77.4%识别精度和GZSL设置下的78.3%调和精度。
3)对比了使用Word2Vec和人工定义两种语义编码方式对模型精度的影响,其中人工定义的精度远远高于Word2Vec,说明人工定义的语义信息更能准确描述害虫特征。
4)测试了本模型在小样本设置下的性能表现,通过只添加5张不可见类图片能取得14%的精度提升。
本模型仍存在一些问题,比如对数据集样本数量较为敏感,如果数据集中图片数量过少,得会导致训练出的生成器G随机性很大,导致最终生成质量不高;其次,有些类别在现实中比较相近,比如斑马和马,但这两类在对比模块中会互相远离,这不符合实际情况。这些问题将在后续进行研究。
目前,ZSL在害虫识别领域仍然有许多需要解决的问题:①需要探索更高效的语义编码方式。语义信息的编码是ZSL识别模型是否有效的关键。本研究采用的人工编码方式,和Word2Vec等词向量方式相比,人工编码虽然描述更精确,但相对需要更长的时间。如何从害虫的百科文本等自然语言描述中提取判别性强的语义特征是下一步需要研究的工作。②需要更多的类目。本研究数据集的害虫均属于鳞翅目,如何将其扩展到其他目害虫并且能统一进行语义信息编码需要进一步研究。总之,害虫零样本识别是一项复杂而具有挑战性的工作,对农业、生态学和环境保护等领域具有重要意义,可以帮助人们及早发现和应对害虫威胁。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}