



0 引 言
苹果是世界上最广泛栽培的水果之一,中国苹果产量在2023年为4 960.2万吨,已成为全球最大的苹果生产国和消费国[1]。随着消费者对苹果品质要求的不断提升,如何提高苹果的产量和质量成为农业生产中的关键问题之一。传统的苹果检测方法依赖人工检查,虽然直观易懂,但效率低、耗时长,且容易受到人为因素的影响,难以满足现代农业生产的大规模需求。因此,推动苹果品质检测的自动化和智能化是提高苹果产业竞争力的重要途径。当前,高光谱成像(Hyperspectral Imaging, HSI)、近红外光谱和机器视觉等先进技术在苹果无损检测中的应用取得了显著的研究成果[2, 3],广泛用于成分预测、真伪鉴别和产地识别等[4-6]。近红外光谱可穿透果皮分析苹果内部糖度与酸度,电子鼻通过挥发性气体检测评估新鲜度,机器视觉能精准识别表面缺陷与色泽分级。然而,单一无损检测技术存在一定的局限性,仅依赖单一光谱或图像数据的苹果品质模型预测误差波动范围较大,严重制约产业化应用[7]。
多源数据融合技术通过整合光谱、图像、电化学信号等多模态数据,从同一样品中提供不同的化学或物理信息,利用化学计量学与机器学习(深度学习)算法构建多层次融合模型,从而提高预测模型的稳健性,可显著提升检测系统的综合性能[8]。多源数据融合技术的出现对于获取不同光谱学的互补信息,以及克服单一传感技术的不足具有重要意义。光谱-光谱融合(如近红外光谱与高光谱联合)可增强分子结构解析能力,光谱-电子鼻融合能同时捕捉挥发性气体与化学成分的动态关联,而光谱-机器视觉融合可实现外观与成分的协同分析[9-11]。这种智能整合摒弃了“数据量决定一切”的传统观念,强调通过战略性地选取多样化、可相互增益的数据类型实现价值最大化。
本文聚焦多源数据融合技术在苹果品质检测中的前沿进展,介绍了数据级、特征级与决策级融合技术在苹果产业中的应用进展,系统综述光谱检测、电子鼻和机器视觉等无损检测技术,数据融合技术、融合方式、特点及其在苹果检测领域中应用,以期为苹果无损检测技术发展提供技术参考。
1 苹果常见无损检测方法
苹果无损检测是通过不破坏果实结构的方式,对其外观、内部质量、成熟度、糖度与酸度等多项品质指标进行精准评估。近红外光谱方法凭借非破坏性、高效率、快速检测及高灵敏度等显著优势,已成为苹果品质检测领域常用手段之一。该技术所涵盖光谱范围包括可见光区(350~700 nm)、短波近红外区(700~1 100 nm)与长波近红外区(1 100~2 500 nm)[12]。其中,可见光区主要用于反映物质对可见光的吸收、散射及透射特性,在物体颜色信息的获取中发挥关键作用;而短波近红外区与长波近红外区则能快速捕捉物质中含氢基团的合频及倍频吸收信号,为物质成分分析提供重要依据。如表1所示,当前苹果无损检测常用的方法还包括HSI、电子鼻、机器视觉、X-射线技术和核磁共振技术。尽管上述技术在不同维度上为苹果品质检测提供了有效手段,然而,单一技术往往因信息局限或环境干扰而难以全面覆盖复杂场景,例如近红外光谱可解析分子振动或原子组成等信息,却对外观缺陷和气味特征的敏感度不足;电子鼻接触挥发性物质产生电信号,却对非挥发性成分的反应不敏捷;机器视觉可精准捕捉食品表面颜色与纹理,却无法穿透果皮识别内部成分变化及内部病变等[13-15]。为解决这个问题,数据融合技术成为苹果无损检测关键升级方向。通过数据融合整合多源异构数据(如光谱、图像、气味、核磁信号等),实现了1+1>2的协同效应,提升结果准确性,为苹果品质的全方位、高精度评估提供新的技术范式。
表1 苹果无损检测常用方法及优缺点Table 1 Advantages and disadvantages of common used apple non-destructive testing methods |
| 方法 | 应用 | 优势 | 局限 |
|---|---|---|---|
| 可见-近红外光谱 | 贮藏时间确定[16]、品种鉴别[17, 18]和可溶性固形物含量[19]等 | 检测速度快、适合实时分析、多成分同时分析、设备成本相对较低等[20] | 依赖大量标准样品建模与容易受到外界环境干扰[21] |
| 短波-近红外光谱 | 褐变识别[22]、表面缺陷检测[23] | 比长波近红外的穿透能力强、适用于透射分析[24]、设备成本相对较低 | 短波近红外谱区多为基团高倍频与合频,重叠严重[25] |
| 长波-近红外光谱 | 可溶性固形物含量检测[26] | 比短波近红外吸收能力强[27] | 长波-近红外光谱仪器价格明显高于短波-近红外光谱,对样品透入深度一般[28] |
| HSI | 缺陷检测[29, 30]、表面蜡质检测[31]、可溶性固形物检测[32]和病害检测[33] | 硬件级融合获取空间图像与光谱信息、精度高、无损检测和多参数同步分析[34]等 | 数据量大、硬件成本高和信号可能会受到外界环境的影响[35] |
| 电子鼻 | 苹果病害检测[36]、香气检测[37]和早期腐烂和发霉检测[3, 38] | 操作简便、快速、成本低和实时检测[39] | 传感器稳定性较差、灵敏度和特异性低[40] |
| 机器视觉 | 果实数量识别[41]、品质分级[42]、缺陷检测[2]和表面光泽检测[43] | 自动化、智能化、检测效率高、准确和使用成本低[44] | 图像收集和标注耗时长,数据质量和数量会影响模型性能[45] |
| X-射线技术 | 苹果褐变与病害检测、缺陷检测[46, 47] | 可检测内部缺陷,突破外观限制、避免破坏水果完整性、穿透性强[48] | 对于设备要求较高,检测设备成本较高,且存在辐射性,需规范设置检验场所和防护装置[49] |
| 核磁共振 | 果汁发酵质量监控[50]、加工过程水分检测[51, 52]和多酚含量检测[53] | 无损快速,穿透力强不会受到果皮厚度的限制[54] | 技术复杂,检测时间长,对专业操作人员要求高且设备昂贵[55] |
2 数据融合方式及研究进展
2.1 数据融合方式
数据融合技术在苹果无损检测领域至关重要,它通过结合来自多个传感器针对同一批苹果采集的数据,有效提升了检测的广度和精度[56]。数据融合核心在于发挥不同数据源互补特性,而非简单地聚合冗余数据。在苹果品质综合评估中,单一检测技术往往存在局限性,例如,近红外光谱技术擅长分析糖度、酸度等内部化学成分,但可能无法有效识别表皮的微小划痕或内部的局部霉变,机器视觉技术能精准捕捉外部瑕疵,却对内部成分不敏感。数据融合将不同技术来源的数据集(如图像、光谱数据)有机结合,充分利用它们之间的互补性和协同性,从而构建出一个关于苹果品质更具体、更全面、更科学综合的数据集。获得新数据集可作为机器学习模型输入变量,显著提升模型预测性能。使用多源数据还能够获得统计优势,融合来自多个光谱探头的数据,可以减少单个探头因苹果表面曲率或轻微污染造成的测量噪声,从而得到更稳健的化学成分预测值。
数据融合过程通常根据其在处理流程中阶段,分为数据级融合、特征级融合和决策级融合[59]。数据级融合直接将不同传感器采集的苹果原始数据(如光谱仪吸光度值和相机像素值)拼接成一个更大数据矩阵,然后输入到模型中进行训练。这种方法保留了最原始信息,对数据配准要求高。特征级融合是苹果检测中最常用策略,首先从各类数据中提取关键特征,如从光谱中提取与糖度、硬度相关有效波长,从图像中提取颜色、纹理和形状特征来表征瑕疵,然后将这些特征向量融合,共同用于训练分类或回归模型。决策级融合为每种数据源单独建立一个预测模型,例如一个基于光谱糖度预测模型和一个基于图像缺陷分类模型。最后,通过加权、投票或模糊逻辑等规则将各个模型输出结果进行融合,得出最终的综合评级(如特等果、一等果或二等果)。如图1所示,这三种融合策略各有侧重,共同构成了苹果无损检测中实现高精度、多维度品质评估的核心技术体系。

2.1.1 数据级融合
数据级融合,又称低级数据融合(Low-level Data Fusion, LLDF),是一种在原始数据层面对多源传感器信息进行整合的策略。该方法直接融合原始数据,旨在最大程度保留有效信息,并借助多模态协同分析抑制噪声、增强目标与背景的对比度,进而提升检测与分析精度[60]。以提高苹果霉心病识别准确率为例,有研究融合声振动信号与近红外光谱数据,实现了对正常、轻度、中度和重度病害样本的高精度分类,准确率分别达到100%、97.56%、100%和100%[60]。尽管数据级融合能够保留数据完整信息,但其对数据处理技术要求较高。由于不同传感器产生的数据在格式、维度和物理意义上差异显著,必须进行复杂的数据预处理,以确保数据一致性和后续分析有效性。标准的数据级融合流程一般首先对各个独立数据集进行预处理,然后将其连接成一个包含所有变量的综合矩阵。随后,可利用主成分分析(Principal Component Analysis, PCA)或各类聚类分析等非监督方法探究样本间相似性,或应用监督学习方法构建分类或回归模型。在回归任务中,常用方法是偏最小二乘回归(Partial Least Squares Regression, PLS)及其变体,在分类任务中,偏最小二乘判别分析(Partial Least Squares-Discriminant Analysis, PLS-DA)、线性判别分析(Linear Discriminant Analysis, LDA)、k近邻算法(K-Nearest Neighbor, KNN)、支持向量机(Support Vector Machine, SVM)、人工神经网络(Artificial Neural Network, ANN),以及随机森林(Random Forest, RF)等方法被广泛应用[61]。然而,传统处理方法将所有变量置于同一矩阵中分析,忽略了数据来源的异质性,即未能有效考虑不同数据集之间的内在关联。为解决这一局限性,有研究开发了多块分析算法(Multi-Block Algorithms),如共同主成分分析(Common Principal Component Analysis, CPCA)、共同维度分析(Common Dimension Analysis, ComDim)和多块全局正交投影(Multiblock Global Orthogonal Projections to Latent Structures, MBGOPLS),以及由此衍生的集成方法如区块森林(Block Forest, BF),这些算法能够明确处理数据的块结构[62]。多块算法的核心优势在于,通过对变量进行区块划分,不仅能够量化每个数据块对模型的相对贡献度,还能深入分析块间相互关系,有效解决了不同数据集因变量数量、噪声水平和信息密度不均衡所带来的建模难题。
2.1.2 特征级融合
特征级融合又称为中级数据融合(Mid-level Data Fusion, MLDF),一般流程是首先从不同类型的数据源中提取特征,然后对筛选出的特征变量进行耦合,以提升融合模型的分类或预测性能[63]。相较于数据级融合易形成高维小样本数据集进而显著影响多元分析模型稳健性的局限,特征级融合通过特征提取步骤优化了数据结构,有效减少了数据量,降低了处理复杂度,同时保留了对检测任务至关重要的特征信息。如图2所示,果园采摘机器人需要良好的水果识别和空间感知性能。Tao和Zhou[64]融合苹果的颜色特征与几何特征,训练基于遗传算法(Genetic Algorithm, GA)优化SVM的自动识别分类器。结果表明,所提出的方法具有较高的识别准确率和性能,苹果、树枝和叶片的准确率分别为92.30%、88.03%和80.34%,研究结果可为农业机器人的水果识别和信息提取提供参考。

特征级融合的关键在于针对异构数据源进行有效的特征筛选与结构优化。在数据合并前,通常采用降维方法提取潜在变量,或通过变量选择筛选关键特征。传统降维方法与特征筛选主要依赖统计分析和计算智能算法,包括相关分析、方差分析、组合分析、自相关分析等。近年来,更先进的算法如竞争性自适应重加权抽样、连续投影算法、GA以和PCA得到了广泛应用[65]。为提升特征提取的鲁棒性,研究者提出了集成多方法的创新思路,如包装法、嵌入法和三步混合法。这些监督式机器学习方法以其简洁高效的特点,在化学计量学领域成效显著。与此同时,深度学习技术为特征提取开辟了新途径。基于神经网络的无监督自动编码器和卷积神经网络提取更具判别性的特征,能够显著提升模型性能。同时在数据融合处理中多模块偏最小二乘法结合正交化方法近期得到关注,该算法是一种有监督多模块建模的分类方法,包括序贯正交偏最小二乘(Sequential and Orthogonalized PLS, SO-PLS)和并行正交偏最小二乘回归(Parallel and Orthogonalized Parallel and Orthogonalized Partial Least Squares, PO-PLS)。SO-PLS有助于研究多个数据集之间的关系,以提高模型性能。PO-PLS的研究目标是评估和获得多个数据集中具有共同或唯一子空间的新数据矩阵,并对多个数据集进行降维,以获得每块数据阵中的独特信息。此外,典型相关分析(Canonical Cor-relation Analysis, CCA)作为一种线性降维技术,用于融合上层匹配特征与下层匹配特征,进一步提升匹配精度,通过最大化数据集间的相关性来实现特征融合。这些方法共同构成了MLDF技术多元化的方法体系,为复杂数据分析提供了有力工具。
2.1.3 决策级融合
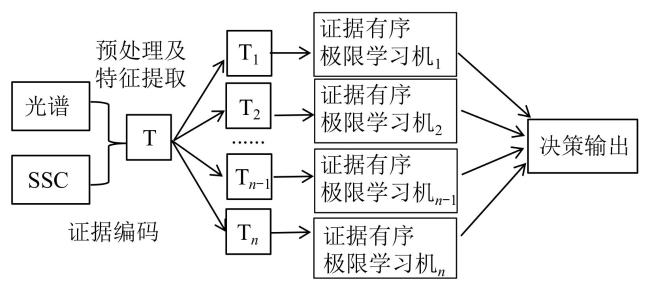
决策级融合又称为高级融合(High-Level Data Fusion, HLDF),其核心在于融合基于单个传感器数据所做出的高级决策结果(如分类标签或置信度),而非在数据级融合原始传感器数据或在特征级融合从原始数据中提取的特征[66]。相较于其他融合方式,HLDF旨在通过整合由单一信息源校准的单一模型的预测输出,提升最终组合决策结果的准确性。例如,Fathizadeh等[67]应用Dempster-Shafer证据理论进行决策级融合,将苹果品质分类的准确率较融合前提升了12.5%~19.8%。影响HLDF模型构建的关键因素在于融合决策方法的选择与建立。常用的方法主要包括投票法、贝叶斯方法、Dempster-Shafer(D-S)证据理论等。投票法是最为简单直观的方法,多数投票法遵循“少数服从多数”原则确定最终决策;加权投票法则依据各决策源(如传感器或模型)的可靠性或历史表现分配不同权重(可靠性高的权重更大),再进行加权投票;贝叶斯方法基于概率论框架,利用各决策源提供的先验知识(基于历史数据)和当前观测证据,通过贝叶斯定理计算各种可能决策的后验概率,并选取后验概率最高的决策作为最终结果;D-S证据理论相较于传统概率论在处理不确定性方面更具优势。它通过为每个可能的决策分配一个信任度区间,并基于特定的证据合成规则融合来自多个源的证据,形成最终决策。例如,在传统苹果分级方法中,等级(如特等、一等、二等)之间的有序关系常被忽略,且等级边界采用硬划分,导致类别标签包含认知不确定性,影响模型稳定性和准确率。为克服这些局限,卫鹏[68]构建了证据有序极限学习机作为基分类器。如图3所示,在D-S证据理论框架下,他们设计了特定的质量函数和证据编码方案,有效处理了由硬划分引起的数据不确定性,并融入了等级的有序性。在保持与传统神经网络模型相当或更优准确率的前提下,其可溶性固形物含量(Soluble Solids Content, SSC)预测时间显著缩减了至少三个数量级。尽管决策层融合因各传感器独立决策可能导致部分有用信息的丢失[69],但其在信息处理方面展现出高度的灵活性和良好的兼容性。
2.2 融合方式选择
在数据融合系统设计中,融合层次的选择本质上是信息保留度、系统鲁棒性与计算效率的动态平衡过程。数据级融合虽能最大限度留存原始数据细节,却可能因数据冗余度高而增加计算负载;特征级融合通过降维处理有效缓解数据冗余问题,但特征选择的合理性直接决定关键信息是否流失;决策级融合系统的稳定性与数据质量容错性相比之下最好,但是却面临原始特征信息损耗的风险。从数据级到决策级的融合过程呈现出层级递增特性,融合层级越高,系统对原始数据缺陷的容错能力与计算效率越强,但信息损耗风险同步提升,对细微差异的捕捉能力也随之弱化。这一特性决定了融合层次的最优解不具备普适性。以苹果病害检测场景为例,当任务需求为精准区分轻度与重度霉心病时,数据级融合对声振动信号与近红外光谱等原始数据的完整保留,可满足高精度细节分析需求。若仅需快速判别病害是否存在,决策级融合对多源分类结果的鲁棒性整合则更为高效。
因此,融合层次的抉择需系统性评估应用场景的多维约束,在信息完整性、系统可靠性与计算可行性中寻求动态平衡点。这一过程并非追求单一指标的最大化,而是基于具体应用目标的定制化适配。
2.3 数据融合技术
数据融合技术通过整合来自不同传感器或分析手段的互补信息,克服单一技术的局限性,显著提升检测的准确性、鲁棒性和信息维度。在苹果无损检测领域,数据融合技术主要集中在光谱与光谱、光谱与电子鼻,以及机器视觉与光谱的结合等[70]。其他无损检测技术,例如核磁共振同样能提供独特维度信息。但是这些技术数据未能广泛融合,主要可能是成本与效率制约。光谱和视觉技术已经相对成熟、快速且成本较低,适合在线检测。而核磁共振等设备通常价格相对更昂贵[71],检测速度也可能较慢,这阻碍了它们在工业化大规模应用中组合。并且融合的目的是用最低成本获得最大信息增益,如果两种技术测量是高度相关特性,或者新增信息对最终品质判断贡献很小,那么复杂融合就失去了意义。
2.3.1 光谱与光谱数据融合
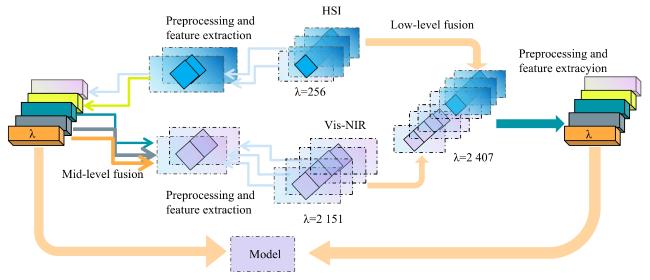
近年来,光谱技术因其具有无损、环保和便捷的优势,在食品分析领域受到了极大的关注,应用潜力巨大[72]。在众多光谱技术中,近红外光谱和高光谱等技术已在食品行业中得到广泛应用,并被认为是实现光谱数据融合的理想技术[73]。光谱数据融合方法是一种融合许多光谱信号的创新技术,通过整合差异波段(如可见光、近红外、短波红外)的互补信息显著提升检测能力。其核心优势在于信息互补性,不同波段光谱对样品特性(水分、糖度、内部缺陷及表面色素)的敏感度差异显著,融合后可构建更全面的分析维度。尤其当HSI与其他光谱技术融合时,可形成空间-光谱协同分析能力,利用三维数据结构实现成分定位与定量分析的协同优化。Keresztes等[74]利用近红外光谱技术结合高光谱数据中光谱维度信息,可实现苹果瘀伤的高精度检测(准确率达98%),并且每个苹果的识别时间低于200 ms。Lin等[75]探究了近红外光谱技术和高光谱技术结合不同数据融合方式在苹果可溶性固形物检测上的效果,融合方式过程如图4所示。研究表明,数据级融合在预测苹果可溶性固形物方面展现出最佳性能,预测决定系数 为0.927,RMSEP为0.529 ºBrix。化春键等[76]结合可见光和近红外图像的优点,融合多源信息,使用多光谱图像对苹果的表层缺陷进行检测,建立了一个可见光-近红外苹果表层缺陷数据集,所提改进模型在增加较少参数量和运算量的前提下将检测精度提升了1.2个百分点,能有效识别4种缺陷以及果梗和花萼,同时保持较高检测速度。
虽然该技术能有效提升精度与鲁棒性,克服单一技术的局限性(如近红外光谱对表面信息不敏感、HSI空间分辨率不足),从而增强模型预测准确性与稳定性[77]。然而,光谱与光谱数据融合存在以下几个问题亟待解决:融合后数据可能导致维度激增,导致存储、传输及计算负担加重,模型训练复杂度显著提高;多源光谱间存在信息冗余与噪声叠加风险,若未采用有效的特征选择与降维策略,可能引发模型性能退化;此外,高设备成本与系统集成难度(特别是HSI设备价格)限制了技术普及;最后,校准与标准化难题突出,因不同原理设备数据格式、量纲及噪声水平差异显著,需复杂的数据对齐预处理以确保融合有效性。未来研究应注重于高效特征提取与创新技术,以提高光谱与光谱数据融合技术在产业中应用规模。
2.3.2 光谱与电子鼻数据融合
电子鼻是一种重要的无损检测技术,通过传感器检测食物中的挥发性成分生成电信号,随后发送到一个能够有效区分这些成分的识别设备,进而监测品质的变化[78]。传统风味检测通常采用光谱技术,如气相色谱-质谱联用技术等,虽然能实现定性分析的准确性,但实时性能较差。而电子鼻技术能快速检测物质风味变化,但在提供精确的定性分析方面仍存在不足[79]。因此,将光谱技术与电子鼻技术融合,能够同时整合气体和光谱数据,从而提高食品检测的准确性和实时性。光谱技术可精确解析苹果样品分子结构和主要化学成分,而电子鼻技术则能灵敏捕捉挥发性有机化合物整体气味特征。这种化学指纹与气味指纹有机结合,为苹果质量评估提供了更全面分析维度。该技术可显著提升食品的鉴别与溯源能力,同时,由于苹果风味特性与其挥发性成分密切相关,该融合技术还能更准确地评估食品的新鲜度、成熟度和腐败程度等品质指标。曹有芳[80]使用电子鼻和近红外光谱技术检测了不同产地、不同品种苹果鲜汁和苹果酒的理化指标和风味物质,实现了电子鼻与光谱技术融合在苹果鲜汁和苹果酒分类鉴别及定性定量分析方面的应用。乔琦[81]通过将遗传算法与偏最小二乘法结合(Genetic Algorithm-PLS, GA-PLS)对高光谱和电子鼻特征数据进行融合,实现了对苹果的农残进行检测。经过GA-PLS的筛选得到最终的融合特征,通过对比可以发现不论是直接融合还是GA-PLS筛选特征之后,都有较好的检测性能,检测精度更是达到了98.33%。
然而,该技术在实际应用中仍面临信息冗余与模型复杂度问题。由于气体传感器阵列普遍存在的交叉敏感性,加之光谱数据本身的高维特性,融合后的数据集往往包含大量冗余甚至冲突信息。若不能进行有效的特征提取和降维处理,不仅会增加模型过拟合风险,还可能降低整体预测性能[82]。其次,电子鼻传感器易受环境温湿度变化和器件老化的影响,导致信号漂移现象,这要求系统必须配备复杂的漂移校正算法或进行频繁校准。此外,建立化学成分与整体气味特征之间的精确关联模型本身就是一个复杂问题,现有的融合模型往往缺乏良好的可解释性。最后,电子鼻检测对样品顶空状态(包括温度、顶空体积和平衡时间等)的高度敏感性,也在一定程度上限制了该技术在快速在线检测场景中的应用。未来研究应着重建立更完善的化学-气味关联模型以提高预测准确性,以及优化检测流程以适应在线检测需求。随着这些技术难题的逐步攻克,光谱与电子鼻融合技术有望在食品质量安全检测领域发挥更大的作用。
2.3.3 机器视觉与光谱融合数据融合
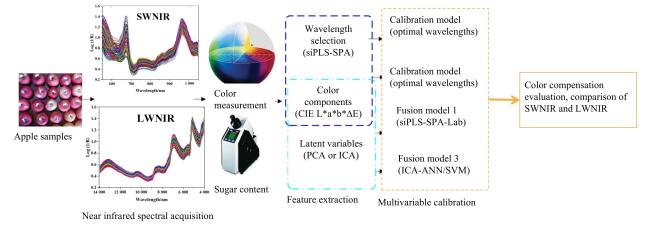
虽然光谱技术因为其无损、快速及便携的优点在众多领域得以应用,但其检测精度与稳定性常受到外界因素的制约。具体而言,环境或样品自身的温度波动可导致光谱信号漂移,从而降低检测结果的可靠性。更为重要的是,样品表面颜色的异质性会引起光吸收与散射特性的显著差异,这直接影响了光谱信号的强度和信噪比,最终影响了定量分析的精度。为了消减上述因素带来的不利影响,研究者们提出了基于多源信息融合的补偿策略。例如,Guo等[83]针对富士苹果的品质检测,提出了一种颜色补偿方法(图5)。该方法首先获取苹果的颜色数据,并将其与近红外光谱信息进行融合,用以训练一个SVM预测模型,从而评估苹果SSC含量。实验结果表明,与未使用颜色补偿的模型相比,基于独立分量分析-支持向量机(Imperialistic Competitive Algorithm-SVM, ICA-SVM)的融合模型表现出优越的性能,其预测相关系数Rp为0.939 8,RMSEP仅为0.387 0%,证明了颜色补偿对提升模型预测能力的显著作用。此外,Sun等[84]构建了一种基于深度学习的多源数据融合模型,并集成了色彩校正功能。研究证实,该优化模型的RMSEP相较于传统PLS模型和一维卷积神经网络(Convolutional Neural Network, CNN)模型分别显著下降了36.4%和16.1%。与此同时,Liu等[85]将光谱技术与机器视觉技术相结合,以实现对富士苹果脆度的无损评估。通过融合光谱数据与苹果外观的图像特征,并采用偏最小二乘法建立校准模型,其预测结果的平均相对误差由8.52%降至6.44%,标准差也从6.22%降至5.30%。
机器视觉与光谱数据融合技术最突出优势在于其能够有效补偿表面干扰因素对光谱信号的影响。通过机器视觉系统对苹果样品表面特征(如颜色分布、纹理特征、几何形状和缺陷区域)精确量化,可以显著校正由表面异质性导致的光谱失真现象(包括光散射效应和信号衰减),从而大幅提升对苹果内部品质参数(如可溶性固形物含量、酸度和内部缺陷)检测精度和模型稳定性。该技术还实现了多维度品质信息同步获取。机器视觉系统不仅能够提供样品的尺寸、形状、颜色分布等外观特征,还能准确识别表面缺陷(如碰伤、腐烂和瘢痕)和污染物,这些信息与光谱数据融合后,可在单次检测中同时完成外观品质评价和内部品质分析,显著提升检测效率。值得注意的是,这种多源信息融合的方式还增强了模型的泛化能力,使其对样品个体差异(如果皮颜色深浅、表面光泽度)和环境波动具有更好的适应性,有效降低了过拟合风险。然而,该技术在工程应用中仍存在若干技术难题。数据配准问题是关键技术难点,特别是在检测非均匀样品或运动中的样品时,确保空间位置对应的光谱数据与图像特征的精确匹配具有较大难度。此外,融合效果在很大程度上依赖于机器视觉系统对表面特征捕捉能力,当表面特征与内部品质关联性较弱或被遮挡时,补偿效果会明显下降[86]。未来研究应重点开发更高效的异构数据配准算法,研究自适应特征选择机制以降低对表面信息的依赖,探索可解释性更强的融合模型架构,以及优化系统集成方案以降低成本。随着这些技术难题的逐步解决,机器视觉与光谱融合技术有望在苹果品质与安全检测领域实现更广泛应用。
2.3.4 其他数据融合技术
随着机器学习(尤其是深度学习)发展,数据融合技术在苹果无损检测中的应用展现出显著优势。通过整合多源信息,不仅能够有效提升检测精度与稳定性,也拓展了多种融合技术。例如计算机视觉技术可高效获取苹果外观特征,如颜色、形状及表面缺陷,但对挥发性物质等内部信息的感知能力有限。因此,将其与电子鼻技术融合,有望实现对苹果品质的更全面评估。此外,声学检测可反映苹果的物理结构与硬度特性,而光谱分析则能够提供糖度、酸度、色素等化学成分的信息,二者的融合有助于更精准地评估苹果的内部品质。这类跨模态信息的深度融合不仅在技术上具有可行性,也在产业中展现出广阔应用前景。
3 多源数据融合技术在苹果无损检测中的应用
多源数据融合技术作为一种很有前途的分析方法,在解决苹果无损检测领域的问题和挑战方面赢得了研究人员广泛关注。目前研究大多将光谱与光谱、光谱与电子鼻、光谱与机器视觉数据融合技术,用于苹果分析的各个方面,包括品质评估、缺陷、病害检测、产地鉴别,以及微生物污染检测。
3.1 苹果品质评估
苹果的品质关键指标涵盖了质地(如硬度和脆度)、形状、糖度与含水量等多个维度。在当前苹果产业面临出口规模有限及产品附加值偏低等问题的背景下,精准高效的采后分级成为提升产业竞争力的核心。然而,依赖大小、形状或颜色等单一特征的传统分级方法,其结果往往不够准确,导致产品品质参差不齐。
为了解决这一难题,研究者们已转向采用多源数据融合技术,以实现对苹果品质更全面、精准的评估。如表2所示,近年来涌现了多种基于数据融合的苹果品质评估应用。通过融合光谱与机器视觉信息,可在不损伤果体的前提下,精准预测作为核心口感指标的苹果脆度[87],其预测误差标准差从8.29%下降到5.55%,实现了对口感的量化评估。通过图像融合技术,将苹果大小、几何形状、颜色及纹理等多维特征数据相结合,能够显著提升自动分级系统的准确率。研究表明,融合多特征后的分级准确率可由单一特征时的70%大幅提升至87.50%[88],甚至高达98.48%[89],为苹果的标准化和商品化提供了有力技术支撑。质地是决定消费者体验的关键。苹果的糖度(可溶性固形物)、硬度及含水量是其风味和营养价值的直接体现。采用光谱与光谱融合技术,可以有效增强对这些内部化学成分检测模型的稳定性和精度,并可同时对糖度、硬度、含水量等多种内部指标进行综合检测[90]。
表2 数据融合在苹果品质检测中的应用Table 2 Application of data fusion in apple quality inspection |
| 融合技术 | 研究目标 | 关键结果 | 参考文献 |
|---|---|---|---|
| 光谱与光谱融合 | 苹果可溶性固形物检测 | 与特征级融合相比,数据级融合最优:R 2p=0.927,RMSEP=0.529°Brix | [75] |
| 光谱与机器视觉融合 | 苹果脆度检测 | 融合后预测误差标准差从6.22%降至5.30% | [85] |
| 光谱与机器视觉融合 | 苹果脆性无损检测 | 预测准确率89.21%,RMSEP=0.122 6 N | [87] |
| 图像融合 | 苹果分级 | 准确率由单一特征时的70%提高到87.50% | [88] |
| 图像融合 | 苹果分级检测 | 分级准确率达98.48% | [89] |
| 光谱与光谱融合 | 苹果内部品质检测 | 构建模型检测糖度R 2=0.887,硬度R 2=0.814,含水量R 2=0.891 | [90] |
| 图像融合 | 苹果分级检测 | 分级正确率93.75%,优于单特征模型 | [91] |
综上所述,多源数据融合技术是突破传统苹果品质检测瓶颈关键。通过整合不同传感器(如光谱、视觉)或不同维度(如图像的颜色、纹理、形状)的信息,实现了“1+1>2”的协同效应,无论是用于外观的自动分级,还是内部品质的无损检测,都表现出远超单一检测方法的准确性与可靠性。
3.2 苹果缺陷及病害检测
目前,虽然基于计算机视觉的苹果尺寸、形状、颜色等外观特征的自动检测技术已相对成熟,但在更精细的缺陷与病害检测领域仍面临挑战。主要难点在于果梗、花萼等自然部位在特征上与真实缺陷相似,易造成混淆;常规无损检测方法对划伤、瘀伤等机械损伤的识别准确率偏低;霉心病等内部病害的检测方法或成本高昂、流程复杂,或精度不足。为了克服这些瓶颈,研究者们将多源数据融合技术应用于苹果的缺陷及病害检测中,并取得了显著成果。如表3所示,通过融合不同信息源,可以大幅提升检测的准确性和可靠性。针对果梗、花萼与缺陷难以区分的问题,通过融合红外与可见光图像,能够有效增强缺陷特征的显著性,将完好果、缺陷果、花萼和果梗的平均识别准确度提升至99.0%[92]。同样,该技术在识别采运过程中产生的瘀伤方面也表现出色,融合数据集的检测准确率可达96%[93],显著优于单一光谱。苹果霉心病是影响果品价值和安全的重大病害。为解决传统检测方法结果容易受环境影响问题[94],数据融合提供了创新方案。通过融合密度特征与漫反射光谱,可将霉心病的判别准确率提升至95.56%,为便携式设备开发提供了理论支持[95]。更有研究将声振信号与近红外光谱相结合,使检测准确率达到98.31%[96],展现了跨模态信息融合的巨大潜力。
表3 数据融合在苹果缺陷及病害检测中的应用Table 3 Application of data fusion in apple defect and disease detection |
| 融合技术 | 研究目标 | 关键结果 | 参考文献 |
|---|---|---|---|
| 近红外光谱与图像融合 | 苹果表面缺陷检测 | 平均准确度99.0%,缺陷识别率100% | [92] |
| 光谱与光谱融合 | 苹果表面缺陷识别 | 准确率为96% | [93] |
| 密度与光谱融合 | 苹果霉心病检测 | 融合模型准确率95.56% | [95] |
| 声振信号与近红外光谱融合 | 苹果霉心病检测 | 准确率98.31%,召回率97.06%,F 1值97.90% | [96] |
| 光谱与光谱融合 | 苹果缺陷检测 | 方法在划碰伤、果梗/花萼、完好果的苹果果实检测方面平均识别率可达96% | [97] |
| 直径信息与近红外光谱技术融合 | 苹果霉心病检测 | 校正后准确率89.09%,较未校正模型提升5.45% | [98] |
| 光谱与光谱融合 | 苹果霉心病识别 | 整体准确率99.31%(轻度霉心病97.56%) | [99] |
| 光谱与光谱融合 | 苹果叶部病害识别 | 多特征融合识别率84%,优于单特征(颜色75%、纹理57%、形状45%) | [100] |
| 光谱与光谱融合 | 苹果霉心病检测 | 方法训练集准确率为98.6%,测试集为96.3% | [101] |
因此多源数据融合技术已为苹果缺陷及病害无损检测技术向前发展提供了有力方式。结合不同技术(如光谱、视觉、声学)或不同维度数据(如密度、直径)的优势,有效弥补了单一检测方法的局限性。无论是应对复杂的表面缺陷识别,还是挑战隐蔽的内部病害探查,数据融合都展现出强大的能力,持续将检测准确率推向新高(超过95%甚至99%)。
3.3 苹果识别以及产地鉴别
在果园自动化与目标识别中自主采摘等自动化任务的实现,高度依赖于在复杂果园环境中对苹果进行快速而精准地识别。针对高密度果园中光照不均、枝叶遮挡等因素导致的图像信息质量低的问题,研究者通过融合颜色、形状等多模态图像数据,开发出高效的识别模型。如表4所示,这些方法能够有效区分苹果果实、树枝和树叶[64],并且在实际应用中,其实时检测精度可高达0.964[102],为采摘机器人的精准作业奠定了坚实基础。同时确保苹果品种与产地的真实性,对于品牌保护和消费者权益至关重要。通过融合近红外光谱与HSI等不同光谱技术,可以获取苹果内外部更丰富的“指纹”信息。研究表明,融合后的决策模型在苹果品种鉴别上,准确率可达100%[103];在产地判别上,准确率能达到99.89%,远超单一传感器的表现[104]。更有研究表明,该技术在鉴别产地的同时,还能精准预测糖度等内部品质指标[105],实现了一次检测、多种收获。
表4 数据融合在苹果识别以及产地鉴别中的应用Table 4 Application of data fusion in apple identification and origin identification |
数据融合技术在苹果识别与鉴别领域展现了其强大的适应性和精准性。无论是应用于田间地头的物理识别,还是应用于实验室与检测线的属性鉴别,该技术都通过整合多源信息,显著提升了模型的鲁棒性和准确率。它不仅解决了自动化生产中的关键技术瓶颈,也为建立透明、可靠的农产品溯源体系提供了强有力的无损检测手段。
3.4 其他应用
数据融合技术的应用正向苹果产业的更多元、更纵深的领域拓展,以解决货架期管理、食品安全等关键性难题,甚至延伸至苹果衍生品的品质分析中。如表5所示,这些前沿应用展现了该技术的巨大潜力。苹果在长期冷藏过程中质地会下降,准确预测其最佳食用期对于减少浪费至关重要。如图6所示,通过融合声学、振动信号及质量数据,并结合ANN,可以有效预测苹果的货架期。该方法通过特征级融合可稳定提升约10%的准确率,而通过决策级融合(如D-S理论)最高可将判别准确率提升19.8%[67],为动态仓储管理和销售策略提供了科学依据。为应对化学农药残留带来的食品安全风险,快速无损检测方法应运而生。通过融合HSI与电子鼻技术,可以协同分析苹果表面的化学光谱信息与挥发性气体信息,实现对农残的高精度检测,准确率达98.33%[81]。此外,将高光谱图像与CNN相结合,也能建立起强大的检测系统,测试集准确率高达99.09%[106],为保障消费者健康提供了有力屏障。数据融合的价值链已延伸至苹果的加工产品。例如,在苹果酒的品质控制中,通过融合光谱与电子鼻数据,能够对复杂的风味进行精细化分析,成功检测出多达90种挥发性物质[80],为产品风味的标准化与优化提供了新思路。
表5 数据融合在苹果检测中的其他应用Table 5 Other applications of data fusion in apple detection |

综上所述,数据融合技术在苹果检测领域正深入到货架期动态预测、食品安全风险监控以及高附加值衍生品分析等多个前沿阵地。解决了传统方法难以应对的复杂问题,也证明了数据融合作为一种平台型技术,具备极强的可塑性和拓展性。
4 多源数据融合技术在苹果无损检测应用的挑战与展望
4.1 挑战
苹果作为全球性大宗水果,其品质直接关联到产业链经济效益与消费者满意度。传统依赖人工品质检测方法,因其主观性强、效率低下且无法评估内部品质等局限性,已难以满足现代农业需求。无损检测技术,特别是结合了光谱、图像等多种信息源的多源数据融合技术,为实现苹果品质客观、精准、高效评估提供了革命性解决方案。该技术通过信息互补,能够克服单一传感器局限性,在糖度、酸度、硬度、内部缺陷及病害综合判定上展现出巨大潜力。多源数据融合本质是“1+1>2”信息增益过程,然而在实际应用中,这项技术从理论研究走向产业化应用仍面临着数据、算法、硬件等多个维度严峻挑战。
(1)数据是融合分析基石,其质量和特性直接决定了模型性能上限。在苹果无损检测场景中,数据层面挑战尤为突出和复杂,主要体现在异构性、不完整性与噪声干扰。数据异构性是多源数据融合首要且根本挑战,不同传感器捕获物理或化学属性各异。例如,近红外或高光谱技术提供与化学成分相关高维光谱数据,而机器视觉技术则获取评估外部性状图像数据,振动技术则反映力学特性一维时序信号。这些模态间数据结构与维度迥异,直接拼接易导致过拟合;此外,在高速分选流水线上,苹果运动状态使得时空对齐与配准极为困难,任何微小偏差都将导致数据错位。不同数据源数值尺度和分布差异巨大,简单归一化方法难以消除模态间固有偏差和不同噪声分布影响,需要更复杂预处理与自适应归一化策略;工业现场环境与理想实验室环境存在巨大差异,数据缺失和噪声是常态[107]。数据缺失可源于传感器故障、苹果未被有效捕捉、环境光干扰或设备振动。工业环境中的电磁噪声、机械噪声、光学噪声及传感器自身热噪声会严重污染原始数据,降低信噪比。在融合过程中,一个模态噪声可能“污染”其他模态,并在非线性模型中被放大,最终导致错误决策。传统融合模型常假定数据完整且对齐,面对部分数据缺失时,其鲁棒性面临严峻考验。
(2)算法是连接数据和决策的桥梁。苹果品质这一复杂目标非线性特性,以及工业应用对效率严苛要求,使得算法设计成为核心难点,主要表现为模型复杂性与实时性。苹果各项品质指标间存在复杂非线性关联。内部碰伤可能在图像上不显现,但在高光谱数据特征上却有明显变化。这些特征间关联复杂性,使得传统线性方法如加权平均或PCA难以有效捕捉,易丢失关键交互信息,导致融合效果不佳。尽管深度神经网络具备强大非线性拟合能力,但其结构设计面临挑战,包括如何有效处理异构数据、选择数据级、特征级与决策级融合策略,且无普适最优解,需大量实验调优;工业分选线速度极快,每个苹果检测时间窗口仅为60~200 ms,需包含数据采集、预处理、模型推理及控制信号输出的全过程。多源数据,特别是高光谱图像和高清图像,处理计算量巨大。复杂多模态深度学习模型可能具有数十亿次浮点运算,虽在高性能设备上运行迅速,但部署到成本和功耗受限的工业嵌入式设备上,推理速度会急剧下降,远不能满足实时性要求。为满足实时性而堆砌高性能硬件将大幅推高设备总成本,影响市场接受度,故算法的轻量化和高效率是关键经济因素;并且当前模型泛化能力较弱,传统检测模型通常针对单一品类开发,迁移至其他水果或农产品时需重新训练,导致数据与算力成本高昂,开发周期长。
(3)硬件是技术的物理载体,其制约直接限制了技术应用场景和普及范围,主要体现在集成、成本与易用性方面。在紧凑流水线空间内,合理布置相机、光源、光谱仪等多个部件,并避免信号干扰和物理遮挡,是一个复杂系统工程。实现纳秒或微秒级硬件同步触发需专用控制系统。传感器标定过程繁琐且需定期维护,设备位移或部件更换需重新复杂标定,导致高维护成本。此外,苹果车间潮湿、粉尘、温度变化等恶劣环境严重影响光学镜头、电子元件性能和寿命,要求硬件系统具备高工业防护等级和长期稳定运行能力;高性能工业相机和科研级近红外光谱仪等核心部件本身价格不菲,集成为稳定可靠系统还需大量研发、软件开发、集成和调试成本,导致设备总价居高不下。目前系统大多需要专业技术人员操作和维护,缺乏简单易用操作界面,极大阻碍了技术在普通农业生产者中普及。
此外,当前多源数据采集与分析系统存在数据格式、通信协议、接口标准多样问题,缺乏行业标准,不利于技术推广、模块替换升级及数据共享与比较。
4.2 展望
针对上述挑战,未来研究应聚焦于数据、算法,以及硬件协同创新,通过引入注意力机制、迁移学习与模型压缩等前沿技术,逐一击破障碍。
(1)为应对异构与缺失数据,可引入基于注意力机制的自适应融合,使模型能够学习各数据源和特征的重要性并动态分配权重;针对数据缺失,可利用生成式模型构建跨模态推断能力,在数据缺失时生成最可能数据,最大限度保留信息。此外,应设计面向不完整数据的鲁棒模型架构,如采用多分支独立处理、后期融合策略,并结合“模态丢弃”等训练技巧,增强模型在真实数据缺失场景下泛化能力;在模型训练阶段引入噪声注入策略,通过随机添加模拟工业噪声加强模型泛化能力,采用对抗训练机制,训练判别器区分真实数据与噪声污染数据,迫使融合模型学习抗干扰特征表示,提升复杂环境下的决策可靠性
(2)对于目前算法存在的挑战,可以采用跨模态强化特征交互,通过多头注意力机制自动捕捉高光谱数据与振动信号的隐性关联。如针对苹果内部碰伤检测,可增强近红外波段与特定频率振动信号的耦合权重;构建自适应融合决策树,根据数据信噪比动态选择融合策略,高信噪比数据采用数据级像素对齐,中等信噪比启用特征级提取,低信噪比则通过决策级集成学习投票输出,避免传统方法信息丢失[108];运用模型压缩组合技术,通过知识蒸馏将复杂网络压缩为轻量级架构,并结合混合精度量化减少计算量;实现实时检测核心在于高效轻量化网络架构设计。这包括深度可分离卷积、分组卷积、倒置残差结构等模型结构优化,构建高效骨干网络。同时,通过模型压缩与加速技术(如知识蒸馏、模型剪枝、模型量化)在保证精度前提下提升推理速度并降低内存占用[109]。利用网络架构搜索技术,针对特定硬件平台自动搜索最优网络结构,实现定制化高效模型;迁移学习技术能够将在苹果检测上训练好基础模型,仅用少量新数据微调,即可快速适应其他水果(如梨、桃、柑橘)或农产品(如马铃薯、番茄)无损检测任务,大幅降低新应用开发成本和周期[110]。
(3)硬件方面进行突破从而走向集成化、智能化与标准化。应借助微机电系统技术,将光谱仪、相机等核心传感部件微型化,并与光源、控制电路高度集成,设计出一体化检测头或手持式设备,从而缩小体积、降低功耗和成本,并解决多传感器物理布局和同步采集难题。通过将预处理算法和轻量化AI融合模型固化实现边缘计算与片上系统,数据在前端完成采集和分析,极大降低延迟;此外,开发具备自我调节和校准能力自适应与自校准硬件,可自动调整参数,定期自我校准,降低人工维护频率和技术门槛。应由行业协会、龙头企业和科研机构牵头,共同制定多源农产品检测数据格式、元数据、通信协议和硬件接口行业标准,打破厂商壁垒,促进互联互通和数据共享[111];同时,开发面向最终用户、图形化、一键式易用操作平台和云平台,降低操作门槛,推动技术大规模普及。
多源数据融合技术无疑是开启苹果产业乃至整个农业智能化时代的金钥匙。当前所面临的数据、算法、硬件层面挑战,也同样清晰指明了未来技术突破方向。通过在数据和算法层面追求智能、轻量,在硬件层面实现高度集成与标准化,并最终将应用场景从单产线检测扩展至覆盖全产业链生命周期管理。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}