



0 引 言
梨是一种常见的水果,富含维生素和矿物质。它能够维持人体细胞的健康状态,具有丰富的营养价值[1]。中国作为梨生产与出口大国,其产量与出口量长期位居世界首位[2]。传统的梨分级检测主要依靠人工经验,通过视觉和触觉等感官手段进行判断,不仅效率较低,而且会受限于主观因素影响,导致检测结果的准确性有限。此外,人工操作处理梨的过程中可能会造成不同程度的物理损伤,从而影响梨的外观质量和市场价值。因此,开发自动、高效且可靠的梨分级技术已成为行业迫切的需求。基于计算机视觉与机器学习技术的自动分类方法[3],虽然能够提供比人工判断更为客观的检测结果,但其效率依旧难以满足工业化流水线日益增长的实时性需求。在此背景下,开展可靠的梨分级检测研究,保障产品质量并增强市场竞争力,成了重要的研究方向。
随着神经网络和深度学习技术的快速发展,当前相关的分级研究已经从传统算法转向基于深度学习的目标检测算法[4-6],如YOLO系列模型[7-9]。KARKI等[10]利用迁移学习在ImageNet数据集上对VGG19(Visual Geometry Group 19)、Inception V3、ResNet50(Residual Network with 50 layers)和DenseNet121(Densely Connected Convolutional Network with 121 layers)等架构进行预训练,并采用微调和特征提取技术来检测草莓病害,在ResNet50架构上取得了高达94.4%的准确率。然而,ResNet50作为特征提取网络所构成的双阶段检测模型不仅需要更多计算资源,而且训练时间过长,不适合实际部署。
YOLO系列模型由于网络结构简单、推理速度快,非常适合实时监控和轻量级部署,在农业领域得到了广泛的应用。例如,周宏平等[11]提出了一种基于迁移学习和YOLOv8n算法的油茶果分类识别方法,有效降低了视觉引导式油茶果采摘机器人采摘被遮挡油茶果时造成的果树和抓取装置损伤。陈俊霖等[12]提出了一种基于轻量化YOLOv8s的草莓穴盘苗分级识别和定位方法,有效克服了穴盘苗越界生长带来的识别和定位干扰。黎祖胜等[13]针对自然环境中荔枝虫害识别效率低的问题,提出一种基于改进YOLOv10n的轻量化目标检测模型YOLO-LP(YOLO-Litchi Pests),实现对小目标的高效聚焦,增强目标与背景的区分能力,同时减少参数和计算量,为荔枝虫害检测的实际应用提供了有效的参考。针对采后芦笋在销售前人工分级成本高、效率低的问题,杨启良等[14]提出了一种基于改进YOLOv11模型的采后芦笋分级方法,并引入了ECAM(Efficient Channel Attention Module)[15]以提高网络的特征提取能力。HU等[16]通过集成注意力机制优化了YOLOv5[17]模型来提高柑橘表面缺陷的检测准确性,改进算法的平均精度均值相较于基准模型提高了5.8个百分点。谭厚森等[18]针对非结构化环境下香梨识别准确率低、检测速度慢的问题,在YOLOv8模型的基础上,通过使用PConv(Partial Convolution)[19]模块替换部分冗余的C2f(CSPDarknet53 to 2-Stage FPN)[20]模块以减少模型的参数量,同时引入simSPPF(Simplified Spatial Pooling Fast)和Inner IOU(Intersection Over Union)[21]来进一步提高模型的推理速度与性能。
综上所述,深度学习在农作物缺陷检测领域已经取得了显著的成果[22]。但是,目前关于梨缺陷检测的研究仍有较大的改进空间。例如双阶段模型参数量庞大和推理速度缓慢,YOLO模型对梨的小目标缺陷检测精度不足,这些严重影响了实际生产线的性能和效率[22]。因此,本研究基于Mamba[23]与YOLO相结合的Mamba-YOLO[24]模型,引入了卷积门控线性单元(Convolutional Gated Linear Unit, CGLU)[25]模块、动态上采样(Dynamic Upsampling, Dysample)[26]模块和频率自适应空洞卷积(Frequency-Adaptive Dilated Convolution, FADC)[27]模块,提出了一种新的梨表面缺陷检测方法,提升综合检测性能的同时降低了计算复杂度与参数量。
1 数据获取与预处理
1.1 图像采集设备
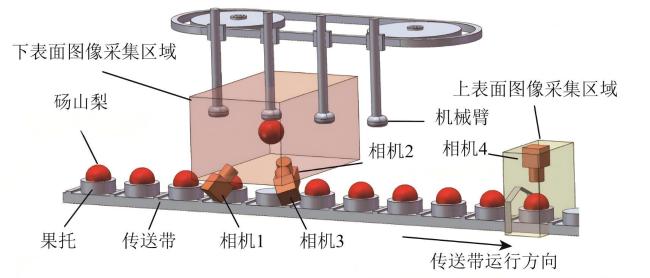
试验平台为北京市农林科学院智能装备技术研究中心自主研发的果托式多表面品质检测分级生产线。该生产线由输送果托、可编程逻辑控制器(Programmable Logic Controller, PLC)控制单元、分辨率为1 920×1 080的彩色工业相机(acA1920-40gc,Basler,德国)、带状LED 光源、漫反射光箱,以及包含分选软件的工业计算机等部分。梨由输送果托输送至光箱检测区域,通过机器视觉系统采集梨图像,经过工业计算机中的分选软件检测梨是否含有缺陷,并将检测结果发送至PLC控制单元,最后在卸料区完成梨的分选。采集系统示意图如图1所示。
1.2 数据采集
本研究采用的品种为安徽砀山梨,每张图像为同一个梨的四个不同角度。利用Labelimg标记图像中的缺陷区域框来构建训练数据集,花萼的标签为“calyx”,紫盖缺陷的标签为“cap”,锈斑缺陷的标签为“rust spot”,霉斑的标签为“mold”。其中紫盖缺陷为果梗及其周围因日灼导致的褐色放射状纹路;锈斑缺陷多为果柄附近的不规则斑块;霉斑为区域性黑色斑点,表面带有些许绒毛。花萼虽不是表面缺陷,但标注并让模型学习后可以避免干扰其他缺陷的识别,从而降低模型的误检率。图2为砀山梨的缺陷图像。

为了提升模型训练的精度与泛化能力,人工剔除质量差的数据集图像。本数据集共有1 000张图像,按8∶1∶1划分为训练集、验证集与测试集。此外,为了增强模型的训练效果,对数据集进行了数据增强,包括旋转、裁剪、镜像、改变亮度等操作。图3为部分梨数据集图像。

2 研究方法
2.1 Mamba-YOLO模型结构
Mamba-YOLO模型是一种以YOLOv8为基础模型并采用SSM的创新架构。得益于Mamba的计算复杂度随输入大小线性增长的优势,Mamba-YOLO模型可有效解决YOLO模型因引入自注意力机制而导致计算开销过大的问题,因此更加适用于目标检测任务。
与YOLO模型结构相似,Mamba-YOLO模型由骨干网络、颈部层、头部检测层三部分组成。首先输入层对需要检测的图像进行预处理,然后输入骨干网络层进行特征提取,将其分为三个不同尺寸的特征图。随后把特征图输入颈部层处理,将得到的三个不同大小的特征图进行预测,最后输出目标检测的结果。
2.2 Mamba-YOLO模型改进
为了提高Mamba-YOLO模型的检测精度,本研究提出了一种有效的改进算法,记为Mamba-YOLO-FC。将Mamba-YOLO模型中的ODSS模块替换为FCSS(Feature Convolutional Structured)模块,改进了ODSS模块中的LS(Local Spatial)模块与RG(Res Gated)模块,旨在能够更好地捕捉局部特征,进而提升模型小目标检测的性能,同时提高模型的鲁棒性,减少噪声和扰动的影响。将颈部层的Upsample模块替换为Dysample模块,不仅减少了模型的参数量和浮点运算次数,同时提升了模型的检测精度。本研究提出的梨表面缺陷检测模型Mamba-YOLO-FC的结构如图4所示。
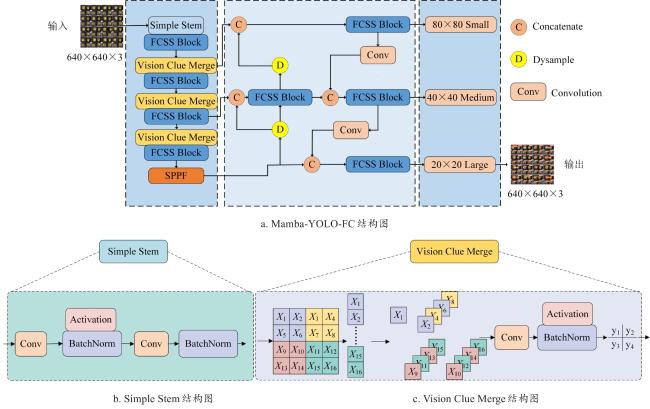
2.2.1 Dysample上采样器
上采样器是目标检测领域中的关键技术之一。它能够通过恢复特征图的分辨率,帮助模型在复杂场景中实现精确定位与多尺度目标检测。具体而言,上采样器通过多尺度特征融合机制,如FPN(Feature Pyramid Network)中的“自上而下”结构,使高层语义信息与底层细节特征互补,以此提升模型的检测精度与鲁棒性。但是在砀山梨的表面缺陷检测实验中发现,许多小目标缺陷信息并没有被捕捉,特征没有得到充分的提取,这对砀山梨缺陷检测产生了一定的影响。
于是,本研究引入了一种轻量级且高效的动态上采样器,即Dysample。尽管内容感知特征重组(Content-Aware ReAssembly of FEatures, CARAFE)[30]、特征对齐与蒸馏增强(Feature Alignment and Distillation Enhancement, FADE)[31]和尺度感知金字塔注意力(Scale-Aware Pyramid Attention, SAPA)[32]等基于内核的动态上采样器显著提升了检测精度,但因为耗时的动态内核中额外子网络导致检测效率大幅降低。针对梨表面缺陷实时检测所需精度与效率兼顾问题,在本研究提出的Mamba-YOLO-FC模型中,Dysample模块通过动态因子自适应调整偏移量的幅度,进而增强网络的灵活性,如公式(1) 所示。
式中: 是输入的特征图; 表示线性投影; 为函数。将输入特征图以通道维度分为多组,每组独立生成偏移量,单独计算后合并再用于重采样。将偏移量 加到原始网格 上,生成动态采样点 ,如公式(2) 所示。
随后使用PyTorch的 函数进行双线性插值采样, 为输出的特征图,如公式(3) 所示。
Dysample通过动态生成采样点的偏移量,结合双线性插值的重采样机制,实现了高效且轻量的上采样。其设计摒弃了复杂的动态卷积核,仅需少量线性层和分组操作,即可兼顾高精度和低计算开销。
2.2.2 频率自适应空洞卷积
Mamba-YOLO模型为了增强特征的提取能力,提出了使用ODSS模块来代替C2f模块。在此基础上,本研究改进ODSS模块为FCSS模块,如图5a所示。
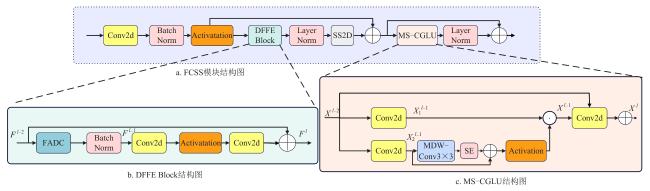
在梨表面缺陷检测中,缺陷往往表现为高频局部特征,而传统卷积神经网络存在特征捕捉不足与频率响应失衡的问题。随着扩张率增大,卷积核频率响应降低,带宽变窄,进而限制了对高频信息的处理能力。为此,改进FADC模块,通过动态调整卷积核的大小,使其在高频区域采用小的卷积核,在低频区域采用大的卷积核,实现多频段特征的协同优化,如图5b所示。
具体来说,首先将给定的输入特征 进行频率自适应空洞卷积,有效提取输入特征图的局部空间信息。然后进行批处理的归一化,减少过拟合的同时还有一定程度的正则化效果,得到中间状态 ,如公式(4) 所示。
式中: 为批归一化。中间状态 进行 卷积,混合了通道信息,可以从输入的特征图中获得更多的信息。然后通过激活函数GeLU(Gaussian Error Linear Unit)增强特征的信息,如公式(5) 所示。
式中: 为非线性函数GeLU; 表示残差拼接的元素加法; 为 卷积层。最后将处理后的信息与残差网络的信息融合,以此使模型具有更好的鲁棒性。
2.2.3 卷积门控线性单元
最初的MLP(Multi-Layer Perceptron)结构仍是目前最广泛采用的全连接层,它在各种视觉任务中表现突出,但面临信息混合不足的问题。针对这一问题,引入了结合卷积和门控线性单元(Gated Linear Unit, GLU)的通道混合器CGLU模块。
在CGLU的基础上,考虑仅通过单尺度的3×3深度卷积捕获局部特征,可能对输入特征的信息感知不足。为此,引入了多尺度机制,这样不同尺度的深度卷积可以实现更强的特征表达能力。同时,传统门控机制存在全局上下文信息建模不足的问题。针对这一局限性,提出了一种改进方案:采用融合通道注意力机制的CGLU模块,并将其扩展为多尺度版本的MS-CGLU(Multi-Scale Convolutional Gated Linear Unit),替代原始ODSS模块中的RG模块。通过添加不同尺寸的卷积核获取多尺度特征,再经过加权融合实现更强的特征表达。这一改进策略提升了网络捕获全局上下文信息和局部特征细节的能力,从而提升了模型的表征能力和鲁棒性。改进后的模块结构如图5c所示。该模块从输入创建两个分支,记为 与 ,并分别对其进行 卷积,如公式(6) 和公式(7) 所示。
将 进行多重深度卷积增强特征表达能力处理后,将残差拼接得到的 与 进行门控机制的元素乘法,如公式(8) 所示。
式中: 为门控机制的元素乘法; 为多尺度深度卷积。通过 的卷积与全局特征进行细化,混合通道信息。最后通过残差拼接得到的原始输入 的进行求和,如公式(9) 所示。
该模块可以获得更丰富的全局特征信息,且不会带来过多的计算量。
3 结果与分析
3.1 训练方法与环境
实验环境的硬件和软件配置如下:GPU为NVIDIA GeForce RTX 4090,CPU为AMD EPYC 9354,CUDA 11.8.89,Python 3.10,PyTorch 2.0.1。输入图像像素尺寸为640×640,初始学习率为0.01,优化器选择为Adam,Batchsize为16,Epoch为300。所有模型均在相同的硬件环境和初始化条件下进行,旨在消除因配置差异引入的偏差,从而确保实验结论的有效性。
3.2 评价指标
模型性能的评估体系通常包含检测效率与检测精度。在检测效率方面,模型参数量反映了可训练参数的总数,直接影响内存占用;GFLOPs(十亿次浮点运算)量化了前向推理的计算复杂度,数值越高,表示模型对硬件要求越高。在检测精度方面,F 1值(F 1-Score)是一个综合评估模型分类性能的重要指标,它结合了精确率(Precision, )和召回率(Recall, ),如公式(10)~公式(12) 所示。
式中: 为检测正确的正样本数量; 为检测错误的正样本数量; 为检测错误的负样本数量。平均精度均值(Mean Average Precision, mAP)是AP(Average Precision)的平均值。通常来说,mAP值越高,模型检测效果越好。计算AP与mAP如公式(13) 和公式(14) 所示。
式中:C为检测类别数,实验中为花萼、霉斑、紫盖和锈斑,因此共有C= 4类。
3.3 消融实验分析
根据表1的消融实验结果可以看出,B+Dysample(Baseline+Dysample)模型在引入Dysample模块后帧率(Frames Per Second, FPS)提高53.8%,F 1显著上升,mAP0.5提高1.2个百分点。虽然精确率略微下降,但是召回率上升,说明模型的泛化能力在增强。由于F 1是精确率和召回率的调和平均值,其上升说明召回率的提升幅度显著高于精确率的下降幅度。这表明,Dysample模块在精度不低于其他高精度动态上采样器的情况下,推理速度提升,实现了模型检测效率的优化。
表1 梨表面缺陷检测研究消融实验的结果Table 1 Results of ablation experiments for pear surface defect detection research |
| 模型 | FADC | CGLU | Dysample | 精确率/% | 召回率/% | mAP0.5/% | mAP0.5:0.95/% | F 1值/% | FPS/(帧/s) |
|---|---|---|---|---|---|---|---|---|---|
| B | × | × | × | 95.7 | 83.9 | 91.7 | 53.2 | 89.4 | 65 |
| B+Dysample | × | × | √ | 92.6 | 92.9 | 92.9 | 53.5 | 92.7 | 100 |
| B+FADC | √ | × | × | 93.1 | 90.4 | 93.1 | 54.7 | 91.7 | 56 |
| B+CGLU | × | √ | × | 97.1 | 88.4 | 92.2 | 53.7 | 92.5 | 38 |
| B+CGLU+Dysample | × | √ | √ | 95.5 | 87.4 | 93.8 | 53.9 | 91.3 | 51 |
| B+FADC+Dysample | √ | × | √ | 88.4 | 92.0 | 92.3 | 54.0 | 90.2 | 57 |
| B+FADC+CGLU | √ | √ | × | 93.7 | 89.2 | 93.0 | 55.2 | 91.4 | 41 |
| B+FADC+CGLU+Dysample | √ | √ | √ | 95.1 | 91.1 | 95.1 | 56.6 | 93.1 | 72 |
|
B+FADC模型相较于B模型,mAP0.5提高1.4个百分点,mAP0.5∶0.95提高1.2个百分点,FPS下降13.8%,F 1提高2.3个百分点。B+CGLU模型单独引入CGLU模块,mAP值有少量增长,FPS大幅下降41.5%,但精确率和召回率都有显著提升,F 1值提高3.1个百分点。B+CGLU+Dysample和B+FADC+Dysample模型情况相似,mAP0.5和mAP0.5∶0.95分别提高2.1、0.6和0.7、0.8个百分点,FPS下降27%和12.3%。
B+FADC+CGLU模型同时引入CGLU模块与FADC模块,mAP0.5提高1.3个百分点,mAP0.5∶0.95提高2个百分点,F 1提高2个百分点,FPS下降37%。可以看出,CGLU与FADC对于精度和模型的泛化性与鲁棒性有明显的提升,但由于引入更加复杂的卷积层,模型的计算量大幅增加,FPS下降。面对需要实时性的梨表面缺陷检测任务,推理速度也是不能忽略的一环。
B+FADC+CGLU+Dysample模型通过引入CGLU、FADC和Dysample三个模块,实现了检测性能的全面提升。在检测精度方面,mAP0.5达到95.1%,mAP0.5∶0.95达到56.6%,较B模型提高3.4个百分点;在推理效率方面,达到72帧/s,比B模型提高10.8%。
从上述实验中可以看出,在梨表面缺陷检测任务中,单独引入某一模块并不能提高模型的性能,甚至会导致性能的降低。这意味着在模型改进时需要进行多方面的考量,不同的模块是否兼容,这样才能根据需求提升模型的效果。本研究提出的Mamba-YOLO-FC模型在工业化流水线的梨缺陷检测与分级分拣任务中,各项指标均满足实际应用需求。
3.4 与其他模型对比
表2 梨表面缺陷检测研究YOLO系列模型对比的实验结果Table 2 Experimental results of YOLO-series models for pear surface defect detection research |
| 模型 | mAP0.5/% | mAP0.5:0.95/% | 参数量/M | 计算量/GFLOPs |
|---|---|---|---|---|
| YOLOv5n | 86.8 | 49.1 | 1.9 | 4.5 |
| YOLOv6n | 90.3 | 48.4 | 4.7 | 4.7 |
| YOLOv7-tiny | 90.7 | 49.3 | 6.2 | 13.7 |
| YOLOv8n | 90.4 | 50.5 | 3.2 | 34.1 |
| Gold-YOLO-N | 89.8 | 51.0 | 5.6 | 12.1 |
| YOLOv12n | 88.8 | 51.9 | 2.6 | 6.5 |
| Mamba-YOLO-FC | 95.1 | 56.6 | 9.1 | 28.4 |
表3 不同规模的Mamba-YOLO模型对比的实验结果Table 3 Experimental results of Mamba-YOLO models at various scales |
| 模型 | mAP0.5/% | mAP0.5:0.95/% | 参数量/M | 计算量/GFLOPs |
|---|---|---|---|---|
| Mamba-YOLO-T | 91.7 | 53.2 | 6.1 | 14.3 |
| Mamba-YOLO-B | 91.9 | 53.5 | 21.8 | 49.7 |
| Mamba-YOLO-L | 94.2 | 54.0 | 57.6 | 156.2 |
| Mamba-YOLO-FC | 95.1 | 56.6 | 9.1 | 28.4 |
实验结果表明,本研究提出的Mamba-YOLO-FC在模型性能方面表现良好,以少量参数量与计算量的增加,获得了mAP的大幅提升。与YOLOv5n、YOLOv6n、YOLOv7-tiny和YOLOv8n模型相比,mAP0.5分别有8.3、4.8、4.4和4.7个百分点的提高,与当前目标检测领域表现优异的Gold-YOLO-N模型相比,展现出更优的性能,其mAP0.5和mAP0.5∶0.95分别提高5.3个和5.6个百分点。即使与YOLO系列目前最新版本的YOLOv12n相比,mAP0.5和mAP0.5∶0.95仍分别提高6.3个和4.7个百分点。
进一步,与基准模型Mamba-YOLO-T相比,本方法仅增加3 M参数量,却使mAP0.5和mAP0.5∶0.95均提高3.4个百分点,实现了精度与效率的良好平衡。此外,在与Mamba-YOLO同系列更大规模的模型对比实验中,Mamba-YOLO-FC仍然表现出显著的优势:在参数量仅为Mamba-YOLO-B的41.7%和Mamba-YOLO-L的15.7%的情况下,计算量分别仅为二者的57.1%和18.1%,而mAP0.5却分别提高3.2和1.4个百分点,mAP0.5∶0.95分别提高3.1和2.6个百分点。
综合以上实验结果,Mamba-YOLO-FC模型在保持轻量级架构的同时实现了检测精度的显著提升。该模型在参数量、计算复杂度和检测精度三者之间得到了平衡,同步优化了效率和性能,满足梨表面缺陷检测任务对模型性能和实时性的双重需求,具有重要的实际应用价值。
3.5 不同的特征提取模块对比
为了验证本研究提出的FCSS模块在梨表面缺陷检测任务中的性能,将FCSS模块和传统YOLO模型主要使用的C2f模块、C3模块和基准模型使用的ODSS模块分别作为模型的特征提取模块,在同一数据集上进行训练,再将各项指标进行对比,结果如表4所示。
表4 梨表面缺陷检测研究改进特征提取模块的实验结果Table 4 Performance of the enhanced feature extraction module for pear surface defect detection research |
| 特征提取模块 | 精确率/% | 召回率/% | mAP0.5/% | mAP0.5:0.95/% | F 1值/% | 计算量/GFLOPs |
|---|---|---|---|---|---|---|
| C2f | 90.9 | 93.6 | 93.4 | 54.5 | 92.2 | 33.1 |
| C3 | 94.0 | 85.8 | 92.8 | 54.3 | 89.7 | 23.6 |
| ODSS | 95.7 | 83.9 | 91.7 | 53.2 | 89.4 | 14.3 |
| FCSS | 95.1 | 91.1 | 95.1 | 55.6 | 93.1 | 28.4 |
实验结果表明,提出的FCSS模块在检测性能上展现出显著的优势。FCSS模块相较于传统YOLO模型常用的C2f和C3模块,mAP0.5分别提高1.7和2.3个百分点,mAP0.5∶0.95分别提高1.1和1.3个百分点。FCSS模块与基准模型中的ODSS模块相比,mAP0.5和mAP0.5∶0.95分别提高3.4和2.4个百分点。
在模型分类性能方面,FCSS模块同样表现出色。实验数据显示,F 1相较于C2f、C3和ODSS模块分别提高0.9、3.4和3.7个百分点,这一结果充分验证了FCSS模块在保持高检测精度的同时,能够有效降低漏检率和误检率,以少量计算量的增加,显著提升了模型的整体性能。
3.6 模型训练损失图
损失曲线如图6所示,其中Bounding box loss表示边界框损失,Classification loss表示分类损失。可以看出Mamba-YOLO-FC模型相较于基准模型Mamba-YOLO-T的损失曲线呈现出更加优秀的收敛趋势。
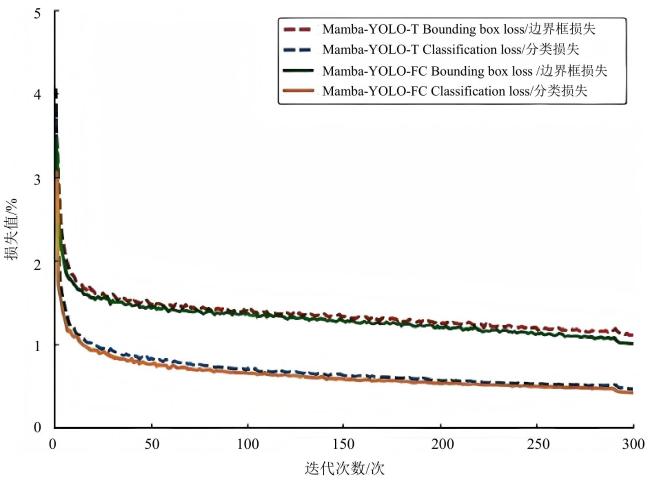
具体而言,在前50个训练周期内,损失值呈现快速下降态势,表明模型在此阶段迅速学习到有效的特征表示;随后损失值逐渐稳定,模型得到了收敛。这种收敛特性表明,本研究提出的Mamba-YOLO-FC模型具有良好的学习效率和训练稳定性。损失曲线的平滑过渡和稳定在较低水平,充分验证了模型超参数设置的合理性,以及模型架构优秀的鲁棒性。实验结果表明,Mamba-YOLO-FC模型成功完成了训练过程,为后续对模型性能的评估奠定了基础。
3.7 模型检测效果可视化分析
为了验证模型Mamba-YOLO-FC的在线检测效果,在实际砀山梨数据集上进行了实验,缺陷检测效果图如图7所示。
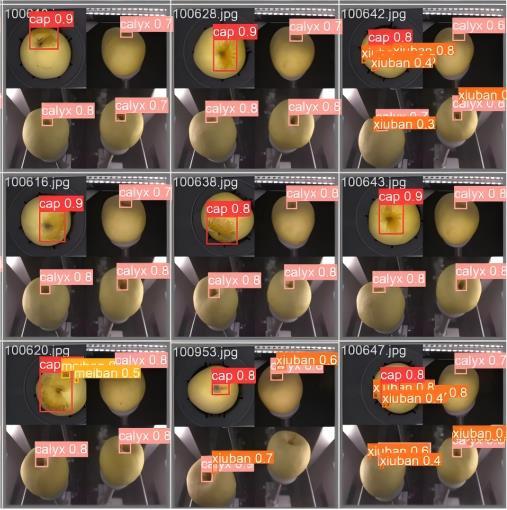
如图7所示,在不同视角的情况下,模型对锈斑这种易于混淆的缺陷能够有效地检测出来,这反映了模型良好的检测性能。同时在图中也能发现,由于图像采集角度问题,会导致漏检的发生。
3.8 模型检测错误情况分析
在果实缺陷检测中,正常梨样本的误判现象主要源于其花萼结构与缺陷区域在形态特征上的相似性。针对该问题,可通过扩充训练数据集的多样性促进模型对不同区域特征的辨识能力,从而增强分类鲁棒性。而对于缺陷梨样本的识别误差问题,研究发现与小尺寸样本的特征表征不足密切相关。由于梨缺陷尺寸较小,当果实整体尺寸较小时,其表面缺陷区域过小,使模型特征检测不足,进而产生漏检的风险。此外,尺寸较小的梨在摩擦传输带翻滚过程中速度较快,易造成图像采集系统未能有效捕捉到缺陷区域的图像,导致缺陷未能被检测。需要说明的是,在实际生产场景中,尺寸较小的梨会依据尺寸标准作为外果,该类梨果不参与正常等级的分选。同时还应注意,果实的摆放可能会导致图像采集角度问题,如图7中第三行第二列的图所示,这同样会导致漏检的发生。
4 结 论
本研究针对梨表面缺陷目标小、易与花萼区域混淆的问题进行了探讨,提出了一种兼顾检测精度与推理速度的Mamba-YOLO-FC模型,主要结论如下。
1)首先,设计了新的FCSS特征提取模块来替代基础模型的ODSS模块,将FADC模块和CGLU模块加以改进并引入到FCSS模块中,为模型提供了更好的特征提取能力和更强的鲁棒性。其次,引入了新的上采样模块,使用Dysample模块取代原颈部网络中的Upsample模块,不仅使参数量与浮点运算次数得到了一定程度的下降,而且模型检测效率得到了提升。
2)所提出的Mamba-YOLO-FC模型与YOLOv5n、YOLOv6n、YOLOv7-tiny、YOLOv8n、Gold-YOLO-N和YOLOv12n模型相比,mAP0.5分别有8.3、4.8、4.4、4.7、5.3和6.3个百分点的提高。与Mamba-YOLO同系列更大规模的模型相比,Mamba-YOLO-FC模型在梨表面缺陷检测任务中依旧能够展现出更高的精度与效率,具备良好的综合性能。
3)提出的Mamba-YOLO-FC算法精确率达到了95.1%,召回率达到了91.1%,mAP0.5达到了95.1%,mAP0.5∶0.95达到了56.6%,帧率达到了72帧/s。因此能够快速精准地检测出缺陷梨,具有良好的稳定性与泛化能力,对梨表面缺陷检测具有积极的意义。
需要指出的是,在砀山梨表面缺陷检测的任务中仍存在以下局限性:1)数据集规模相对有限,可能影响模型在训练过程中的特征学习充分性,未来需进一步扩充数据以提升模型性能。2)构建小目标缺陷数据集,以深入验证模型在小目标检测能力方面的提升效果。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}