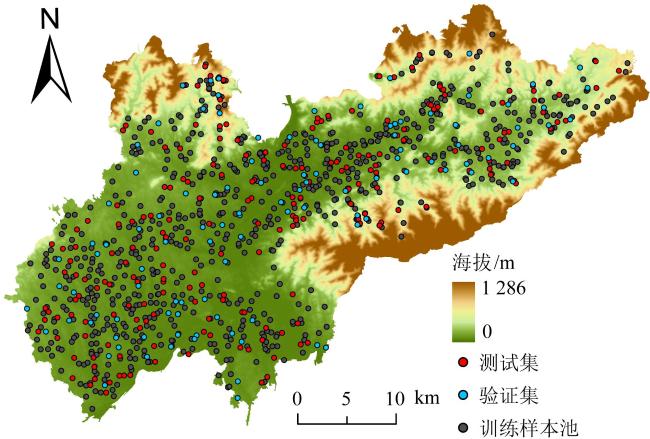
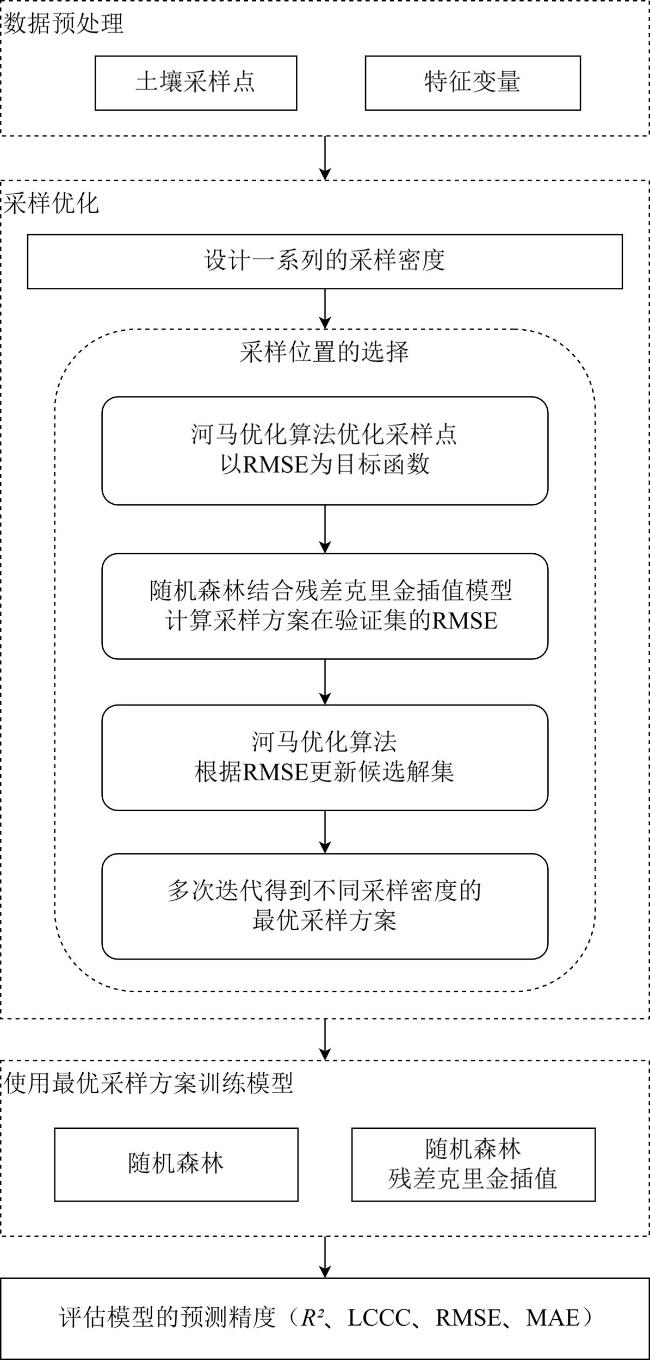
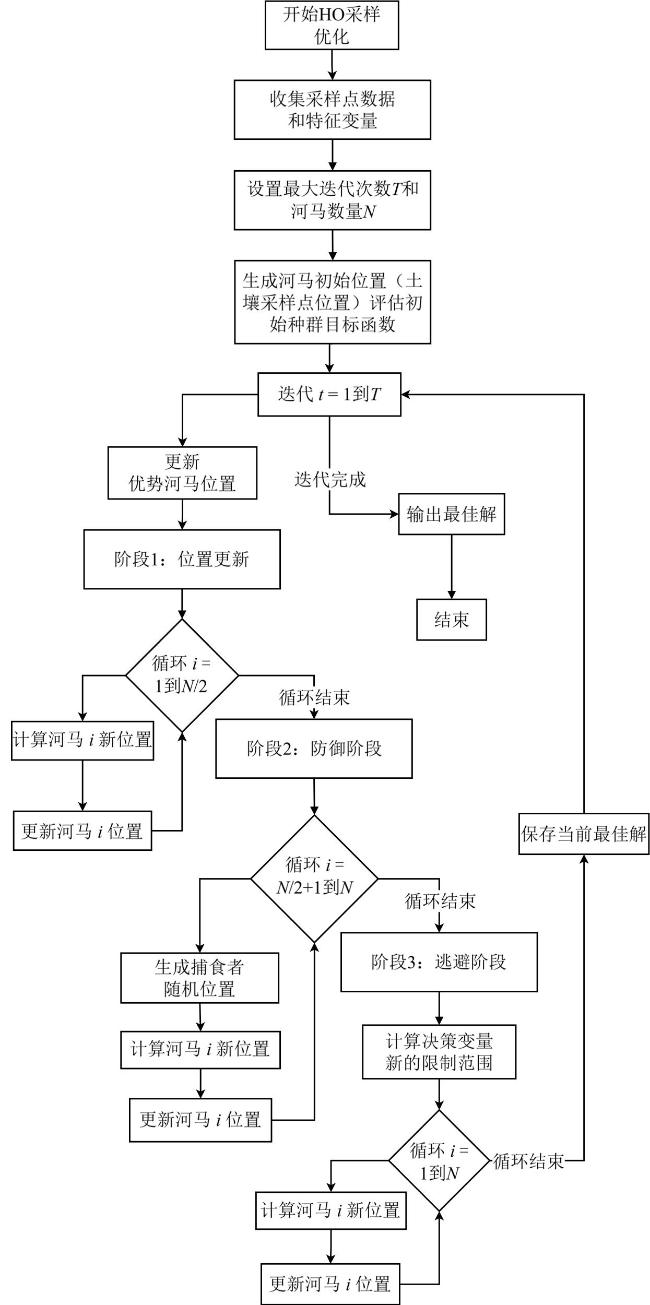
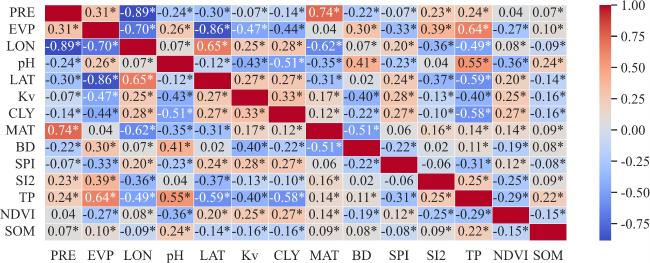
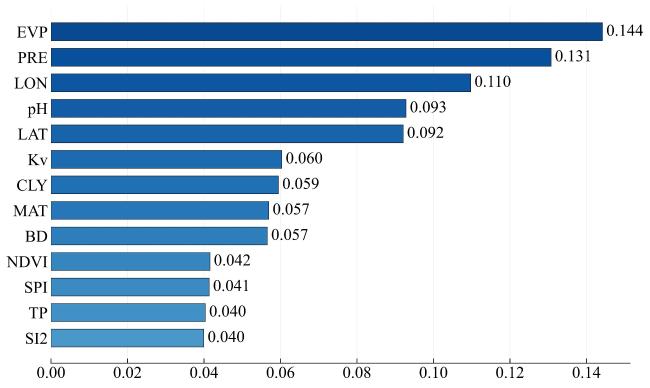
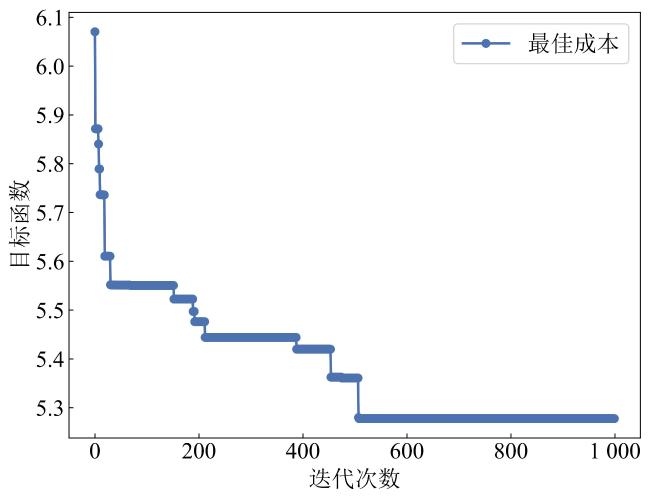
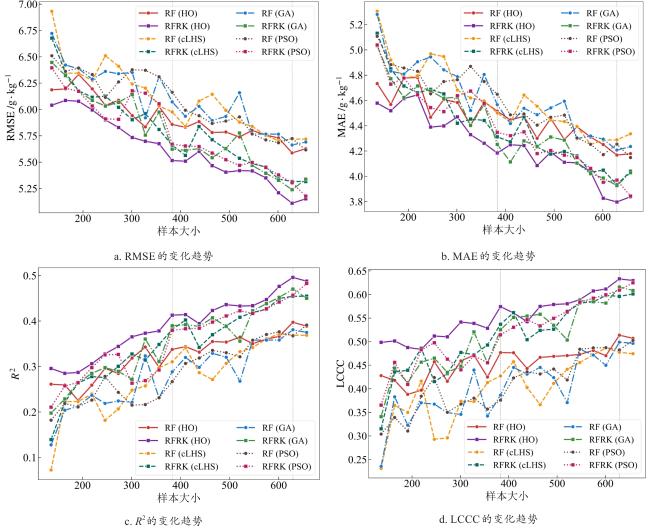
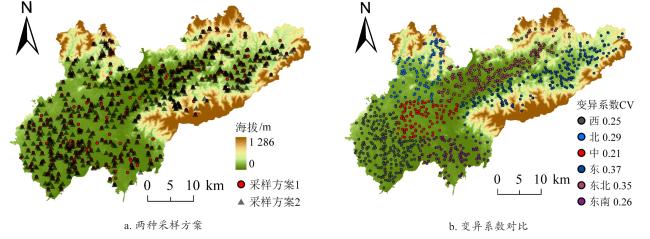
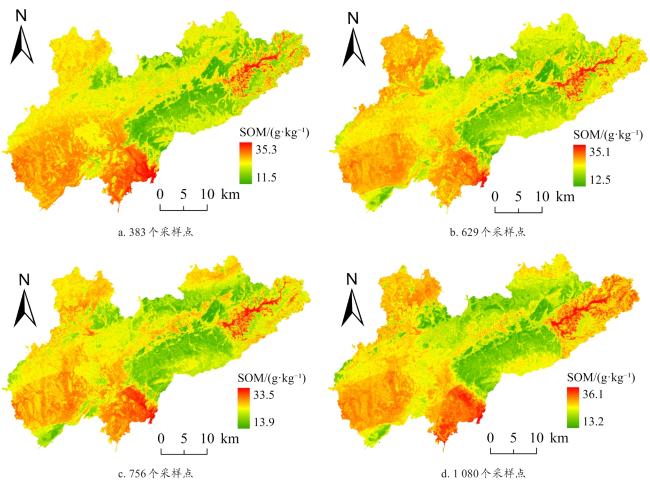
[Objective] Soil quality is crucial for food security, ecosystem health, and sustainable development, but faces degradation due to intensive land use. Accurate soil quality assessment is therefore essential for informed land management and ecological protection. Machine learning has enhanced digital soil mapping (DSM) by improving modeling accuracy through multi-source data integration. Within DSM, soil sampling design is a foundational step that directly influences prediction accuracy, cost, and efficiency. An ideal scheme must balance mapping precision with economic and operational feasibility. This study focuses on soil organic matter (SOM), a core indicator of soil quality affecting fertility, carbon sequestration, and environmental regulation. Precisely mapping its spatial variability is vital for sustainable soil management. To address the need for efficient sampling, the aim is to develop an optimal sampling design method for regional-scale SOM mapping. The objective is to reduce sampling redundancy and cost while improving spatial prediction accuracy. [Methods] A sampling optimization framework was proposed that integrated intelligent optimization algorithms with a hybrid spatial interpolation model. The framework was built upon the hippopotamus optimization algorithm (HO) and incorporated the random forest residual kriging (RFRK) method to construct an optimal sampling strategy for the spatial prediction of SOM. At the initialization stage, a population of candidate solutions—referred to as 'hippopotamuses'—was randomly generated, with each individual representing a potential sampling layout. In this study, the HO was employed to select subsets of sampling points from the training sample pool, with each subset forming a candidate solution. Collectively, these solutions constituted the initial hippopotamus population. The study area was located in Lanxi city, Zhejiang province, where a total of 1 080 field-measured soil samples were collected. These samples were partitioned into a training set (n=756), a validation set (n=108), and a test set (n=216) at a ratio of 7:1:2. Environmental covariates—including terrain attributes, vegetation indices, and climate factors—were extracted from multi-source remote sensing datasets. Using these covariates, the HO optimized sampling schemes across varying densities and spatial configurations. The resulting designs were then evaluated using the RFRK model to assess their SOM prediction performance. This process enabled the identification of the optimal sampling density and spatial layout that balanced accuracy and cost-efficiency. [Results and Discussions] When the HO-RFRK framework was applied, the prediction accuracy of SOM improved significantly as sampling density increased from 0.5 to 2.3 points/km2 (136-629 points). The root mean square error (RMSE) on the test set decreased from 6.04 to 5.11 g/kg, representing a reduction of approximately 15.4%. The lowest prediction errors were observed at a sampling density of 2.3 points/km2, with the RMSE and mean absolute error (MAE) reaching their minimum values of 5.11 and 3.79 g/kg, respectively, beyond which further increases yielded only marginal gains, indicating diminishing returns. To assess the effectiveness of HO, its performance was compared with three established methods: conditioned Latin hypercube sampling (cLHS), genetic algorithm (GA), and particle swarm optimization (PSO). At lower densities (0.5-1.3 points/km2), all methods showed limited predictive power. However, at 1.4 points/km2 (383 points), the HO method was the first to exceed predefined accuracy thresholds (coefficient of determination, R2>0.40; Lin's concordance correlation coefficient, LCCC>0.55), achieving R2=0.41 and LCCC=0.57, outperforming cLHS (R²=0.38, LCCC=0.53), GA (R2=0.39, LCCC=0.52), and PSO (R2=0.38, LCCC=0.51). Across the range of 1.4-2.3 points/km2, HO consistently delivered superior results. At 2.3 points/km², the HO-RFRK combination achieved R2=0.49 and LCCC=0.63, surpassing cLHS, GA, and PSO in both metrics. [Conclusions] Based on the cultivated land of Lanxi city as a test case, a novel sampling optimization strategy is proposed based on the HO. First, the strategy successfully identified an optimal sampling density that maximizes prediction accuracy, as well as a lower, cost-effective density that maintains robust predictive performance with substantially reduced survey costs, defining a practical density range that balances precision and economic feasibility. Second, the RFRK model consistently demonstrated superior prediction accuracy compared to the standard random forest (RF) model across all tested sampling schemes, validating the effectiveness of the integrated HO-RFRK approach. In summary, this optimized strategy achieves high mapping accuracy with greater sampling efficiency, offering a scientifically grounded and practical methodology for reducing long-term soil monitoring costs. It provides a valuable reference for optimizing soil surveys in Lanxi city and other regions with similar environmental settings.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}