



0 引 言
近年来,全球气候变化导致春季低温事件呈现出频率增加、强度增强且时空分布更不确定的趋势[3]。苹果树在春季的生长发育正处于嫩芽—开花的关键窗口,若在此阶段发生低温冻害事件,极易导致授粉受阻和坐果率骤降,影响苹果正常生产[4]。因此,准确预测始花期能够为防范和减轻春季低温冻害提供科学决策依据。在这一背景下,开展苹果始花期预测研究受到广泛关注。现有始花期的预测方法主要分为两类[5]:基于果树生长发育的机理模型和基于观测调查数据的统计经验模型。果树在进入冬季时保持休眠状态,在春季温度升高时适当条件下解除休眠恢复生长[6],故机理模型以作物生理机制为基础,模拟苹果树从休眠解除到盛花期的全过程[7],如果在一定时期内满足苹果树冷量要求,就进入热累积阶段,在满足热量需求之后果树进入萌芽阶段[8-10]。机理模型主要有序列模型和冷重叠模型[5]。序列模型认为果树在冬季进行冷量积累(寒冷期),在春季进行热量积累(强迫期),并且这两段积累是先后独立进行的。但随后的研究认为序列模型忽视了果树所具备的生物学特性,比如果树已积累的冷量对后续热量积累的动态影响,因此相关学者认为序列模型可能不具有普遍适用性[9]。LUEDELING等[11]基于冷量累积模型和热量累积模型,提出了一个可动态响应温度的温带果树春季物候预测模型PhenoFlex,该模型能够更好反映果树的生物学特性。机理模型能揭示物候与温度间的生理联系,但其参数通常需针对不同区域分别进行校准。与机理模型相比,统计模型通常通过分析物候期与气象因子间的定量关系来建立回归模型[12],在预测时灵活且计算简单。柏秦凤等[13]基于有效积温因子与观测花期的相关性,构建了多元线性回归的始花期预测模型,用于模拟中国富士系苹果主产区的苹果花期分布,但此类模型易受到气象变量多重共线性的影响。为解决这一问题,张艳艳等[14]在预测苹果始花期时采用偏最小二乘回归法,结果显示其方法优于传统回归模型。郭连云和赵年武[15]通过敏感性分析筛选关键变量,并结合逐步回归建立了梨树始花期预测模型,所建立的预测模型能准确预测贵德县梨树始花期。刘淼等[16]提出了一种半机理半统计模型,该方法以机理模型为基础,通过网格化方式为苹果主产区匹配冷量和热量需求参数,再结合每日温度构建随机森林(Random Forest, RF)模型对冷/热积温进行分区估算,并通过热量累加判定物候节点,但仍需分区域标定阈值。通过上述方法建立的始花期预测模型,预测精度仍有待提升。
随着人工智能的发展,深度学习已逐渐成为物候预测的重要方法,特别是在处理物候时序数据方面展现出独特优势。相较于传统统计模型,深度学习方法能够在无需显式假设物候变化函数形式的情况下,自动学习气象因子与物候响应之间的非线性关系,从而为复杂物候过程的建模提供新的技术路径。现有研究中,长短期记忆(Long Short-term Memory, LSTM)网络因其在捕捉时间序列长期依赖特征方面的优势,被广泛应用于物候过程建模。REDDY和PRASAD [17]利用中分辨率成像光谱仪(Moderate Resolution Imaging Spectroradiometer, MODIS)得到的归一化植被指数(Normalized Difference Vegetation Index, NDVI)时间序列数据与LSTM,成功构建了植被动态预测模型,用以模拟NDVI的季节性变化过程。LIU等[18]将LSTM网络与多变量气象记忆效应机制相结合,开发了一个深度学习框架,实现了对冠层绿度全季节动态轨迹的高精度模拟。这类研究表明,基于递归神经网络的模型能够有效表征物候演变过程中蕴含的时间依赖特性。在此基础上,部分研究开始引入更复杂的时序建模结构以提升对物候事件的刻画能力。TRAN等[19]将基于自注意力机制的神经网络(Transformer)架构应用于物候学研究,通过注意力机制处理时间序列数据,实现了多个关键物候事件发生时间的预测。ALHNAITY等[20]将LSTM与注意力机制相结合来构建模型,用于植物茎直径变化的多步预测,结果表明,注意力机制有助于模型在复杂时序中聚焦关键信息,从而提升预测精度。
尽管上述研究在物候预测中取得了一定进展,但总体来看,现有深度学习方法多侧重于整体时间序列建模,对气温变化过程中不同时间尺度信息的区分与利用仍较为有限。尤其是在花前关键阶段,气温的短期波动、长期趋势及累积效应可能对始花期产生不同影响,而现有模型往往难以对这些时变规律进行有针对性的表征。此外,多数模型对空间差异的处理仍依赖分区建模或经验参数设定,区域适应性有待进一步提升。
针对上述问题,本研究从气温时变规律挖掘与区域自适应建模两个层面提出改进思路:在时间维度上,引入多头注意力机制以增强模型对气温序列中关键时段信息的关注能力,从而更精细地刻画局部波动、整体趋势及累积变化等时变特征;在空间维度上,将地理因子与递归神经网络结构相结合,构建区域自适应的预测框架,以表征不同地理位置下苹果始花期的响应差异。在此基础上,本研究构建了苹果始花期预测模型,并利用实地观测数据对其预测性能进行验证。
1 材料与方法
1.1 研究区概况
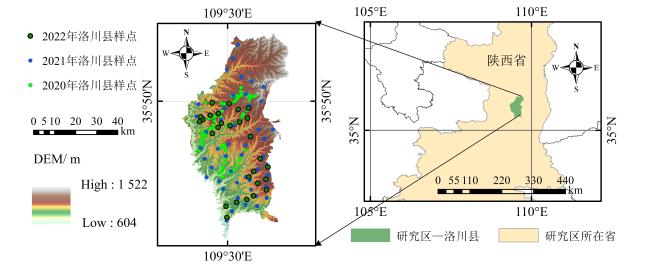
1.2 数据获取及预处理
1.2.1 气象数据
本研究使用的近地表气温(Near-Surface Air Temperature, NSAT)来源于GAO等[21]生成的近地表气温产品。该产品主要采用RF机器学习模型,利用多个数据源,包括ERA5-Land、全球陆地数据同化(Global Land Data Assimilation)、遥感数据,以及若干辅助因素在Google Earth Engine云平台上实现。经年/月分层抽样训练后,生成了1981—2020年黄河流域1 km日尺度最大、平均、最小近地面气温(NSAT)栅格。文章中通过十折交叉验证表明各类日温的均方根误差(Root Mean Square Error, RMSE)均低于1.93 K、R 2不低于0.968。本研究中使用该产品方法生成的1 km尺度日最高/平均/最低NSAT用于后续分析,并且参考果树生理物候和区域花期调查信息,所使用近地表气温时间范围为10月1日—次年3月30日(苹果采收后至次年始花期前)。表1展示了样点1在2019年10月1日—10月5日的逐日近地表气温数据。
表1 洛川县逐日时序NSAT数据示例Table 1 Example of daily time-series NSAT data in Luochuan county |
| 日期 | 日最高气温/℃ | 日平均气温/℃ | 日最低气温/℃ |
|---|---|---|---|
| 2019-10-01 | 17.6 | 15.3 | 13.3 |
| 2019-10-02 | 21.9 | 15.5 | 13.5 |
| 2019-10-03 | 17.0 | 14.1 | 13.9 |
| 2019-10-04 | 14.8 | 12.5 | 11.9 |
| 2019-10-05 | 9.2 | 7.9 | 7.1 |
1.2.2 花期调查数据
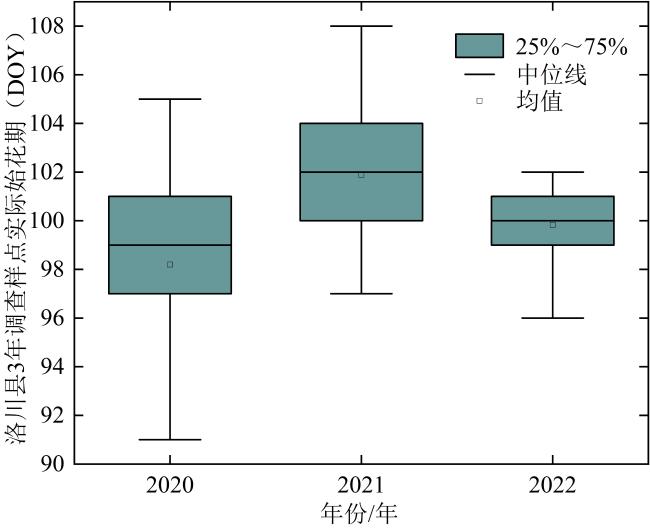
在2020、2021、2022年的3—4月,在洛川县进行了苹果始花期调查,记录了各调查样点实际的始花期数据。花期物候的判定依据是各调查样点苹果园的平均开花比例,始花期限定为每个样本点单株苹果树开花量不能超过25%。同时,通过千寻差分定位系统获取调查样点的经纬度等地理位置信息。3年共采集145个调查样点始花期数据,具体调查样点分布如图1所示。为更全面展示始花期数据的分布情况,图2通过箱线图展示了3年洛川县始花期数据的4分位数。本研究中的日期采用年积日表示,即一年中的第几天(Day of Year, DOY)。图2显示,洛川县3年始花期出现在3月30日—4月14日。其中,2020年始花期时间相对较早,2021年和2022年相对较晚。
1.2.3 数据预处理
在模型的构建过程中,超参数选择对预测性能有一定影响。本研究通过贝叶斯优化方法,针对隐含层数、隐含层神经元数、学习率、L2正则化参数和优化器等超参数进行了调优。经优化后得到最优超参数配置如下:学习率稳定在0.01,网络结构收敛为两层隐藏层、每层约230个神经元,优化器选用Adam。在此配置下,验证集目标损失降至-0.01。
在模型训练过程中,需要将完整数据集划分为训练集、验证集与测试集3部分。训练集和验证集作为建模集,主要用于模型训练和超参数优化,测试集作为未知数据不参与模型训练,仅用于检验模型泛化能力。本研究根据已有调查样点数量,将2020年和2021年花期数据、2019年10月1日—2020年2月29日及2020年10月1日—2021年3月30日的逐日最高/平均/最低NSAT数据、各样点高程和经纬度数据按照9∶1的比例划分并做十折交叉验证(表2),用作模型训练,并用RMSE、平均绝对误差(Mean Absolute Error, MAE)和相关系数( , R)来表征训练结果,以避免训练集样本或验证集样本出现不平衡问题,影响模型的训练效果。最后利用2022年花期数据、2021年10月1日—2022年3月30日逐日最高/平均/最低NSAT数据及高程和经纬度数据作为模型独立测试集。由于模型输入变量在量纲和物理意义上存在差异,其数值存在数量级不一致的情况,为避免量纲差异带来的影响,对数据进行了归一化处理。
表2 十折交叉验证模型训练结果Table 2 Results of 10-fold cross-validation for model training |
| 折数 | MAE/d | RMSE/d | R |
|---|---|---|---|
| 1 | 1.13 | 1.46 | 0.95 |
| 2 | 1.80 | 2.12 | 0.87 |
| 3 | 1.71 | 2.14 | 0.87 |
| 4 | 1.79 | 2.58 | 0.83 |
| 5 | 1.58 | 2.32 | 0.82 |
| 6 | 1.37 | 1.67 | 0.79 |
| 7 | 1.60 | 2.30 | 0.84 |
| 8 | 0.87 | 1.10 | 0.95 |
| 9 | 1.88 | 2.24 | 0.78 |
| 10 | 1.13 | 1.29 | 0.96 |
1.3 研究方法
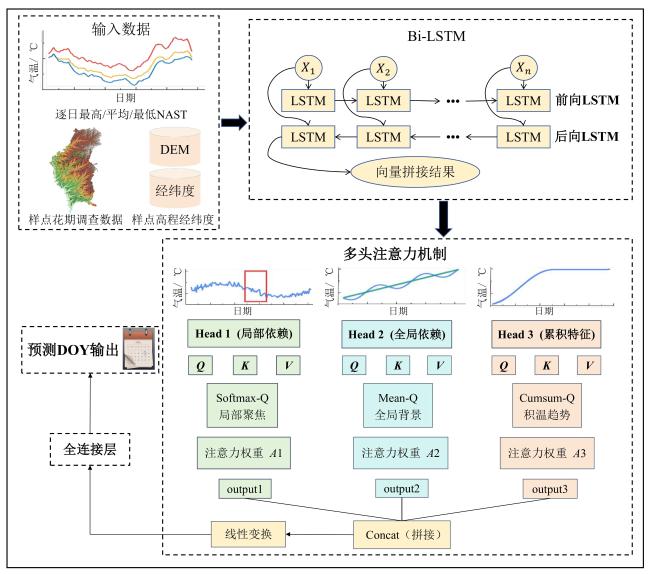
本研究以双向长短期记忆网络(Bidirectional Long Short-Term Memory, Bi-LSTM)为核心时序建模框架,在时间特征方面,引入局部依赖头、全局依赖头和累积特征头3种多头注意力机制(Multi-Head Attention, MhA),用于对多维近地表气温序列中的关键时序信息进行加权建模,从而提升模型对不同时间尺度气温变化特征的识别能力;在空间特征方面,将地理因子(经纬度与高程)作为静态特征与递归神经网络结构相融合,以增强模型对不同地理位置下物候响应差异的适应能力。为便于表述,本研究将在Bi-LSTM框架中引入多头注意力机制后的预测模型简称为基于多头注意力机制的双向长短期记忆网络(BiLSTM-MhA)。模型的整体技术流程与预测框架如图3所示。首先,基于NSAT估算产品,计算得到研究区各样点2019—2022年逐日的最大、平均和最小NSAT数据。其次,基于获取的各样点最大/平均/最小NSAT逐日数据、经纬度高程数据和实测始花期数据,分别构建LSTM、Bi-LSTM和BiLSTM-MhA 3类预测模型。为保证模型性能的可比性,对LSTM和Bi-LSTM模型均采用贝叶斯优化算法进行超参数寻优,从而获得较优的网络结构与训练参数;并在Bi-LSTM的基础上引入多头注意力机制得到BiLSTM-MhA模型,用于进一步增强模型对气温时变特征的建模能力。接着,将研究区2021年10月1日—2022年3月30日逐日的最大、平均和最小NSAT栅格数据与DEM、经纬度叠置,对每个有效像元直接调用已训练且固定的BiLSTM-MhA模型进行逐像元预测,得到研究区苹果始花期预测空间分布图。最后,对比已有苹果花期预测模型,分析讨论本方法在苹果始花期预测精度上的优势。
1.3.1 双向长短时记忆网络(Bi-LSTM)
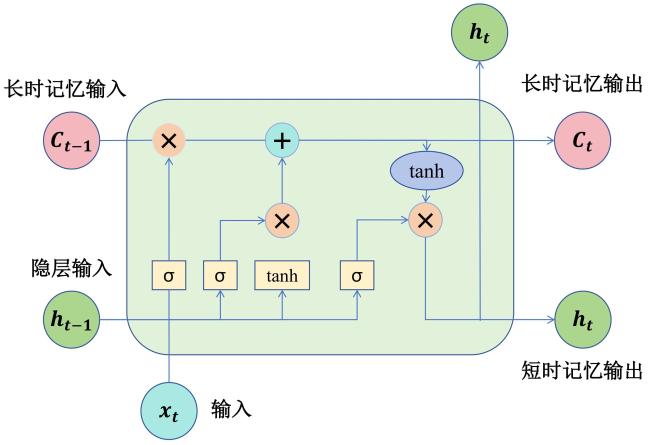
LSTM是在循环神经网络(Recurrent Neural Network, RNN)的基础上,引入记忆单元和门控机制实现序列信息的有效传递的一种改进模型。LSTM共有3个门:遗忘门、输入门(更新门)和输出门[22]。这些门通过控制信息的流动,决定哪些信息被遗忘、哪些信息被更新,并在每个时间步生成新的输出。这种机制使得LSTM能够保留长期依赖信息,并有效地处理较长的时间序列。故该模型在处理较长的时间序列信息时,可以有效解决普通的循环神经网络存在的记忆丢失和梯度消失问题[23]。LSTM包含1个隐藏向量 h 和1个记忆向量 C,二者在复杂的门控机制作用下协同工作,在每个时间步动态更新状态,如图4所示。
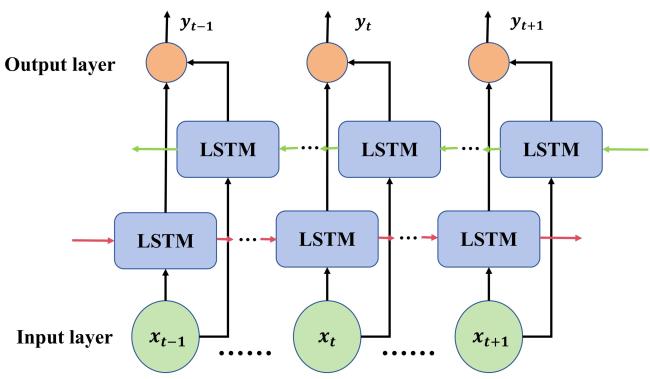
为了使模型能够更好地学习各调查样点逐日最高/平均/最低NSAT和经纬度高程与其始花期之间的关系,本研究使用了Bi-LSTM模型,该模型由两个LSTM单元组成,1个前向LSTM和1个后向LSTM,前向LSTM单元处理正向输入,即从时间序列起始到当前时间步的输入数据;另1个单元处理反向输入,即从当前时间步到序列结束的输入数据[24]。通过这种双向的设计,Bi-LSTM能够同时捕捉过去和未来的依赖关系,从而为每个时间步提供更丰富的上下文信息。具体地,图5为该模型原理图,输入数据分别被送入两个LSTM单元进行处理,在每个时间步生成对应的双向特征。最终,模型将双向特征进行拼接,并且经由激活函数处理映射到输出层特征,得到预测结果[25]。
1.3.2 多头注意力机制
注意力机制最早用来模拟人脑在信息处理中的选择性关注特征。早期大部分实现均依赖于RNN架构,但是这种序列依赖结构限制了计算的并行化。Transformer框架在此基础上发展出多头注意力机制,通过运行多个自注意力层并融合其结果,增强了对输入序列在不同子空间中的信息捕捉能力,从而提升了模型的表达能力[26]。尽管Bi-LSTM能够有效捕捉时序数据中的长期依赖性,但对于短期波动和多尺度特征的提取存在一定的局限性。因此,本研究在Bi-LSTM基础上引入了多头注意力机制,以增强模型的表达能力,并且设计了3种自定义注意力头:局部依赖头、全局依赖头和累积特征头。局部依赖头关注局部时间步的短期气候波动,如突如其来的气温升高或下降,这类短期波动对苹果的始花期有着直接的影响。该头通过对输入的最高/平均/最低气温序列的查询矩阵进行softmax操作,强化了对局部时间步变化的关注,使得模型能够在气候突变时及时调整对始花期的预测。全局依赖头则平均化捕捉全局的信息,聚焦于全局最高/平均/最低气温变化的长期变化。全局依赖头通过对输入的最高/平均/最低气温序列的查询矩阵做均值化处理,帮助模型识别局温的长期效应,避免短期波动的干扰,同时高程经纬度信息在该头中也被重点关注。累积特征头则关注气温变化的累积效应,特别是气温积累对始花期的影响。始花期通常受到气温长期变化的影响,比如低温的积累(冷量积累)和高温的积累(热量积累),这对于预测花期具有关键意义。该头通过对输入的最高/平均/最低温度序列查询矩阵进行累加(Cumsum)操作,学习了气温的逐步变化和积累,从而更好地捕捉到气温变化趋势对始花期的影响。图6为多头注意力机制的原理构图。
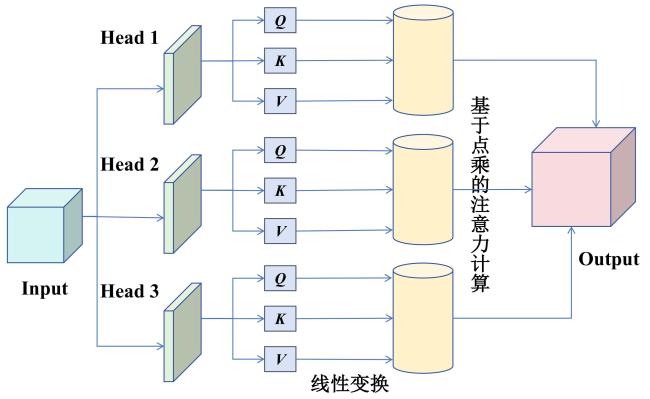
多头注意力机制的本质就是学习3个权重矩阵,它们用于构造分别用查询(Query)、键(Key)和值(Value)矩阵表示。通常随机定义3个权重矩阵,将输入分别映射为 Q 、 K 、 V,如公式(1)~公式(3) 所示。
接着,将 Q 、 K 、 V 分为3个子矩阵;每个头独立计算注意力权重,对应图3的 A1、 A2、 A3,如公式(4) 所示。
式中: 为每个头的维度。
最后,再将多个头的输出拼接并映射回原始的隐藏空间,如公式(5) 所示。
式中: 为第i个头的输出; 为输出层的权重矩阵。
1.3.3 精度评价指标
RMSE用于衡量预测值 与真实值 之间的偏差,是评估模型预测精度的常用指标。较小的RMSE值表明模型在整体上更贴近真实观测值,如公式(6) 所示。
式中:N表示样点总数; 表示第i个样本的预测值; 表示第i个样本的真实值。
MAE是预测值与真实值之差的绝对值的平均值,能够更直观地刻画预测偏差的平均水平。MAE值越低,说明模型在绝大多数样本上的预测更为精准,如公式(7) 所示。
用于衡量预测值与真实值之间的线性相关程度,R越接近1,表示模型预测与真实观测高度正相关,如公式(8) 所示。
式中:SSR为回归平方和;SST为总平方和。
2 结果与讨论
2.1 模型跨年度建模验证结果
在本研究中,针对苹果始花期的预测任务,基于贝叶斯优化选定的超参数,分别构建了LSTM、Bi-LSTM,以及在Bi-LSTM框架中引入多头注意力机制的BiLSTM-MhA模型。采用前两年数据(2020年和2021年花期数据、2019年10月1日—2020年2月29日及2020年10月1日—2021年3月30日的逐日最高/平均/最低NSAT数据、各样点高程和经纬度数据)进行模型训练,并利用第3年的数据(2022年花期数据、2021年10月1日—2022年3月30日的逐日最高/平均/最低NSAT数据、各样点高程和经纬度数据)开展独立验证,旨在评估模型在不同年份数据上的预测性能和泛化能力。
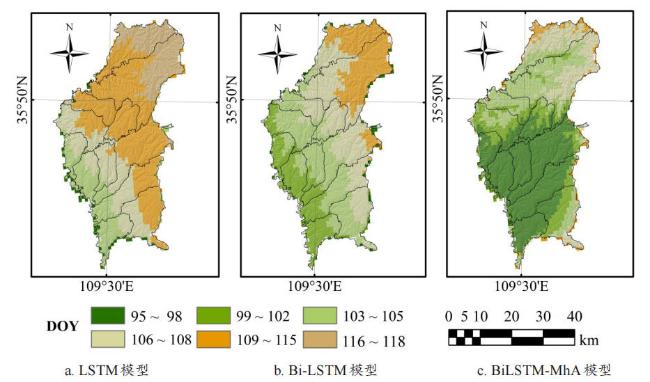
图7给出了LSTM模型、Bi-LSTM模型和BiLSTM-MhA模型的预测结果与真实值的回归分析及误差分布情况。图7a和图7b表明LSTM模型在预测过程中存在低估,无法有效地捕捉数据的变化趋势,R为0.39,表明LSTM预测值与真实值之间的相关性较弱,说明该模型在时间序列数据建模过程中对数据变异性的解释能力较低,拟合效果较差。结合置信区间来看,LSTM预测值的离散程度较高,尤其是在数据较大或较小时,其偏差更大,导致整体预测精度受限。由于LSTM在建模过程中对不同时段的气温信息赋予了相同权重,难以有效区分开花前关键阶段与非关键阶段的影响,部分站点的RMSE误差超过3 d。相较之下,Bi-LSTM模型通过引入双向结构,在一定程度上增强了对气温序列前后依赖关系的利用。由图7c可见,其预测相关性提高至R=0.45。然而,如图7d所示,由于Bi-LSTM仍主要依赖隐状态传递进行时间特征建模,缺乏对不同时序信息重要性的显式刻画,在部分样点上仍存在预测不稳定的情况。在Bi-LSTM框架中进一步引入多头注意力机制后,模型在始花期预测精度与稳定性方面均得到改善。如图7e和图7f所示,BiLSTM-MhA 模型能够较好地拟合始花期的整体变化趋势,相较于传统LSTM和Bi-LSTM模型,其预测值与实测值之间的相关系数提升至R=0.84。通过多头注意力机制对气温序列中不同时段信息进行加权建模,模型能够分别关注气温变化过程中的局部波动、长期趋势及累积效应,提高模型预测能力。结果表明,预测误差主要集中在0~2 d,其RMSE为1.34 d,MAE为1.13 d(表3),较LSTM和Bi-LSTM模型,预测精度分别提升了39.37%和20.71%。表明模型在整体预测精度上具备综合优势。这说明在进行苹果始花期预测时,BiLSTM-MhA模型能够更好地捕捉数据的非线性特征,在进行跨年度验证时,也具有较好的可迁移预测能力。此外,图8c展示了BiLSTM-MhA模型得到的2022年洛川县尺度苹果始花期预测值的空间分布图。可以看到,始花期在90~120 d呈现海拔梯度特征,从空间维度印证了将高程、经纬度纳入模型的必要性。
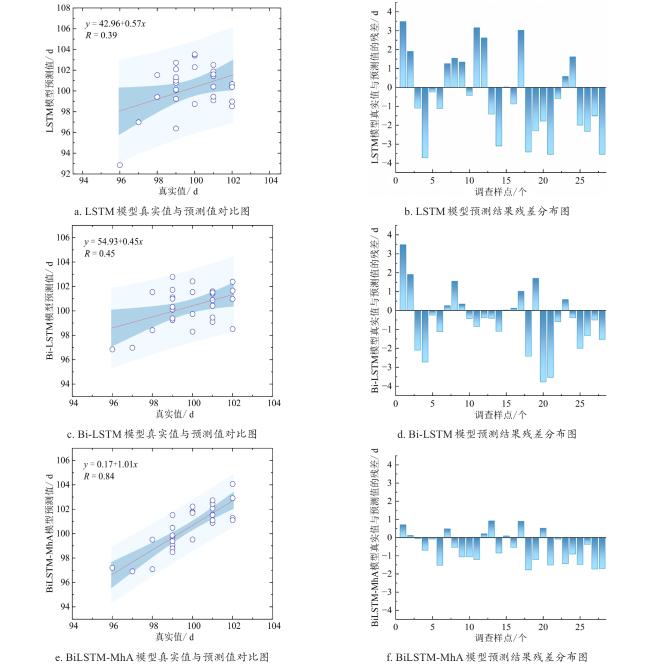
图7 LSTM、Bi-LSTM与BiLSTM-MhA模型验证结果图Fig.7 Verification result charts of LSTM, Bi-LSTM and BiLSTM-MhA |
表3 LSTM、Bi-LSTM与BiLSTM-MhA模型验证结果Table 3 Verification results of LSTM, Bi-LSTM and BiLSTM-MhA |
| 模型 | RMSE/ d | MAE/ d | R |
|---|---|---|---|
| LSTM | 2.21 | 1.91 | 0.39 |
| Bi-LSTM | 1.69 | 1.30 | 0.45 |
| BiLSTM-MhA | 1.34 | 1.13 | 0.84 |
2.2 不同输入时间窗口下的模型性能分析
为进一步验证模型的可提前预测能力,本研究以不同数据截止日期(3月5日—3月30日)为分界,对模型进行提取预测能力测试(表4)。结果显示,随着数据截断日期的提前,模型预测误差呈轻微上升趋势,但整体波动幅度较小。截至3月15日—3月20日的模型仍维持RMSE为1.3~1.5 d、MAE为1.1~1.2 d、相关系数R≈0.83的水平,与3月30日全信息输入时的结果几乎一致;即便将输入数据提前至3月10日(提前约20 d),RMSE仅为1.41 d、MAE为1.18 d,R仍保持0.82,说明模型在气象观测不完全的条件下仍具稳健性。
表4 输入数据不同截止日对苹果始花期预测模型精度的影响Table 4 Impact of different input data cutoff dates on the prediction accuracy of the first flowering date of apples |
| 截止日 | RMSE/ d | MAE/ d | R |
|---|---|---|---|
| 3月30日 | 1.34 | 1.13 | 0.84 |
| 3月25日 | 1.30 | 1.07 | 0.83 |
| 3月20日 | 1.32 | 1.10 | 084 |
| 3月15日 | 1.46 | 1.20 | 0.82 |
| 3月10日 | 1.41 | 1.18 | 0.82 |
| 3月5日 | 2.21 | 1.99 | 0.58 |
| 2月28日 | 2.54 | 2.10 | 0.51 |
| 2月23日 | 2.63 | 2.44 | 0.49 |
当输入数据进一步提前至3月5日(约提前25 d)时,误差开始增大(RMSE=2.21 d,MAE=1.99 d),R下降至0.58,并且进一步减少输入数据的时间窗口会导致预测误差逐渐增大,这表明此时由于气温上升阶段尚未充分展开,模型预测的不确定性增大。总体而言,该结果表明所建模型在不依赖未来气象信息的情况下,仍可稳定地提前15~20 d预测苹果始花期,误差控制在±2天以内,满足生产应用对花期预测时效性和准确性的双重要求。
2.3 BiLSTM-MhA模型与机器学习对比
常见的传统的机器学习方法,如RF和支持向量机(Support Vector Machine, SVM),在许多回归任务中已表现出一定的有效性。在同一数据集与评估框架下,本研究进一步复现了RF与SVM两类经典算法,以量化其与本研究模型的性能差异。实验结果表明,在本研究的苹果始花期的预测中,这些方法存在适用性不足,预测精度较低的问题。
如表5所示,RF模型的RMSE为2.30 d、MAE为2.63 d,R仅为0.25,显示预测值与真实值之间的相关性极弱;SVM模型的RMSE为2.63 d、MAE为3.03 d,R虽略高(0.51),但仍处于较低水平。两种方法在预测过程中均存在低估,尤其是在数据分布两端(即始花期较早样点和较晚样点),预测偏差更大,导致整体预测精度受限。这说明,经典的非时间序列机器学习模型(如RF和SVM)在跨年度的情景下无法保持稳定的预测性能,而BiLSTM-MhA模型通过时间序列建模和多头自注意力机制,能够更好地应对数据的时序变化,从而在预测精度上具有优势。
表5 机器学习方法测试精度Table 5 Machine learning method test accuracy |
| 方法 | RMSE/ d | MAE/ d | R |
|---|---|---|---|
| 随机森林 | 2.30 | 2.63 | 0.25 |
| 支持向量机 | 2.63 | 3.03 | 0.51 |
| BiLSTM-MhA | 1.34 | 1.13 | 0.84 |
2.4 BiLSTM-MhA模型与机理模型对比
本研究基于温度时序数据和地理位置数据,利用深度学习的方法开展始花期预测研究。从模型预报试验结果可知,跨年份的验证方式下始花期预测RMSE为1.34 d。为对比现有机理模型的研究成果,本研究引用了相关文献中的精度指标。以西欧地区为例,DREPPER等[28]在比利时的花期预测试验中,预测平均误差分布于4.15~6.36 d。国内相关研究方面,邱美娟等[29]在北方苹果主产区开展的预报工作中,模型偏差为3.4~6.6 d。刘淼等[16]的苹果始花期预测模型预测精度RMSE约为3.44 d。而刘璐等[6]针对全国主产区构建的模型结果显示始花期误差大致为5 d。总体来看,现有研究多数精度处于3~6 d。值得注意的是,由于数据来源、模型构建和研究区域的不同,这些结果更多是展示了本研究提出的BiLSTM-MhA模型与传统机理模型相对精度的差异,但仍可发现,本研究引入的Bi-LSTM与多头注意力结构能够有效地对长时间序列进行整体建模,避免了分步计算过程中的结构性误差积累,并在可比指标上展现出具有竞争力的预测精度。
2.5 静态因子(高程经纬度)消融实验
静态因子(高程经纬度)对始花期预测有一定的影响,且在实际应用中常作为环境变量影响生长周期。为探讨经纬度和高程作为静态地理因子在苹果始花期预测中的贡献,本研究设计了消融实验对模型的输入变量进行逐步删减,以完整模型输入(动态温度序列+经纬度+高程)作为基准,评估了去除静态因子对模型预测精度的影响。实验结果见表6。
表6 静态地理因子消融对苹果始花期预测模型精度的影响Table 6 Impact of static geographic factor ablation on the prediction accuracy of the first flowering date of apples |
| 静态因子 | RMSE/ d | MAE/ d | R |
|---|---|---|---|
| 完整模型 | 1.34 | 1.13 | 0.84 |
| 去掉高程 | 1.45 | 1.11 | 0.64 |
| 去掉经纬度 | 2.54 | 2.05 | 0.50 |
| 去掉高程+经纬度 | 2.69 | 2.38 | 0.35 |
当分别去除高程和经纬度后,模型性能均发生不同程度下降,其中单独去除高程后RMSE略升至1.45 d,而R则降至0.64,表明高程虽未增加绝对误差,但对模型解释变异的能力有一定贡献;而当单独去除经纬度后,RMSE升高至2.54 d,MAE增至2.05 d,R亦降至0.50,表明经纬度在花期预测中的重要性超过高程。同时,去除经纬度与高程,仅保留动态温度变量时,模型性能大幅下降(RMSE=2.69 d,MAE=2.38 d,R=0.35),预测误差较完整模型增大超过1倍,说明经纬度与高程作为静态特征的加入提高了模型对区域花期时空差异的预测能力。
通过上述消融实验可知,静态地理因子尤其是经纬度特征,增强了模型对于空间尺度差异的敏感性,从而有效捕捉到不同区域间苹果始花期的变化规律。这也充分验证了相较于传统机理模型,本研究所提出的基于深度学习的方法融入静态地理特征,能够更为精准地描述区域尺度上的苹果始花期差异及变化趋势。
3 结论与展望
3.1 结论
本研究围绕苹果始花期预测中气温时序信息利用不足与区域适应性有限的问题,构建了一种以Bi-LSTM为核心、融合多头注意力机制与地理因子的苹果始花期预测方法,并在陕西省洛川县开展了跨年份验证分析,主要结论如下。
1)通过在Bi-LSTM框架中引入多头注意力机制,增强了模型对气温序列中关键时段信息的关注能力,有助于刻画花前气温变化过程中局部波动、整体趋势及累积效应等时变规律。在测试集上,模型的始花期预测RMSE为1.34 d,相较于传统LSTM和Bi-LSTM模型,本研究模型预测精度分别提升了39.37%和20.71%。
2)通过将地理因子(高程经纬度)作为静态特征与递归神经网络结构相融合,提高了模型的区域自适应预测能力。此外,模型能够提前15~20 d预测苹果始花期,展示了其较强的适应性和预测潜力。
综上,本研究提出的苹果树始花期预测模型在苹果始花期预测中提升了一定的精度,具有较强的实际应用潜力。
3.2 展望
尽管本研究提出的BiLSTM-MhA模型在始花期预测中取得了精度提升,但未来仍有进一步改进空间。首先,本研究主要依赖1 km分辨率的近地表气温数据,未来研究可以探索如何融合更高分辨率气象数据以进一步提高预测精度。其次,本研究仅限于洛川县,未来可以考虑将该模型推广到其他地区,以提高模型的普适性。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}