



0 引 言
1 材料与方法
1.1 研究区域概况
1.2 数据采集
1.3 高光谱数据预处理与特征构建
1.3.1 数据预处理
1.3.2 特征选择与构建
表1 冬小麦叶绿素含量估算的植被指数及其计算公式Table 1 Vegetation index and its calculation formula for estimating chlorophyll content of winter wheat |
| | | |
|---|---|---|
| | | |
| | (2) | |
| | | (3) |
| | | (4) |
| | | |
| | | (6) |
| | | (7) |
| | | (8) |
| | | (9) |
| | (10) | |
| | mND705 | (11) |
| | | (12) |
| | | (13) |
| | | (14) |
| | | (15) |
|
1.4 域偏移度量化
1.5 稳健自适应迁移学习框架
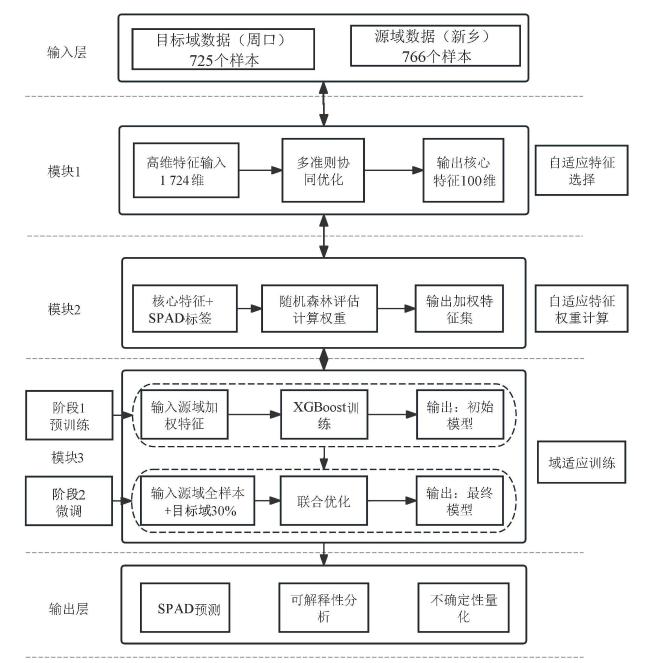
1.5.1 自适应特征选择模块
1.5.2 自适应特征权重计算
1.5.3 域适应训练策略
表2 XGBoost模型超参数设置Table 2 XGBoost model hyperparameter settings |
| 参数 | 取值 | 说明 |
|---|---|---|
| n_estimators | 100 | 提升树的数量 |
| max_depth | 6 | 单棵树的最大深度 |
| learning_rate | 0.1 | 学习率 |
| subsample | 0.8 | 样本采样比例 |
| colsample_bytree | 0.8 | 特征采样比例 |
| reg_alpha | 0.1 | L1正则化系数 |
| reg_lambda | 1.0 | L2正则化系数 |
| random_state | 42 | 随机种子 |
|
1.6 对比方法与实验设计
1.6.1 对比迁移学习方法
1.6.2 实验场景设置
1.6.3 评估指标
1.7 可解释性分析与不确定性量化
1.7.1 SHAP可解释性分析
1.7.2 预测不确定性量化
2 结果与分析
2.1 数据统计分析
表3 新乡与周口冬小麦叶绿素含量描述性统计Table 3 Descriptive statistics of chlorophyll content of winter wheat in Xinxiang and Zhoukou |
| | | |
|---|---|---|
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
| | | |
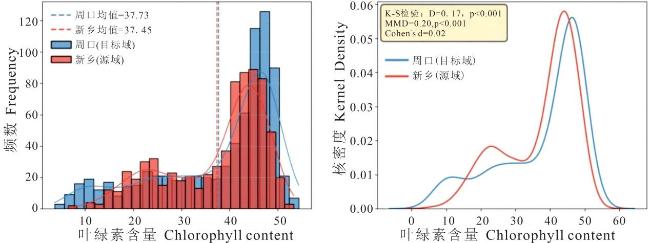
2.2 波段选择结果可视化
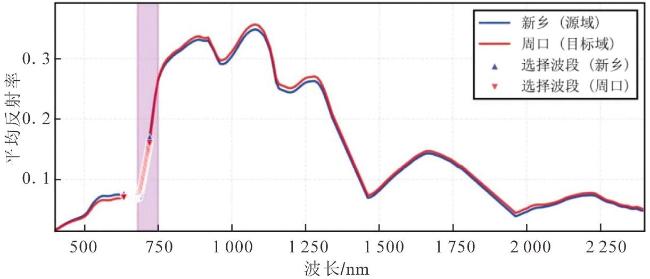
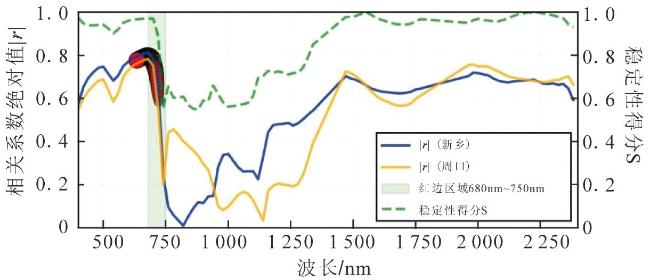
2.3 模型性能对比
表4 新乡内部验证(场景A)与两地合并性能(场景D)的模型性能汇总Table 4 Summary of model performance for Xinxiang internal validation (Scenario A) and the ideal upper bound using combined data from both regions (Scenario D) |
| | | | | |
|---|---|---|---|---|
| | | | | |
| | | | | |
表5 迁移学习方法性能对比Table 5 Performance comparison of transfer learning methods |
| | | | | | | |
|---|---|---|---|---|---|---|
| | | | | | | |
| | | | | | | |
| | | | | | | |
| | | | | | | |
|
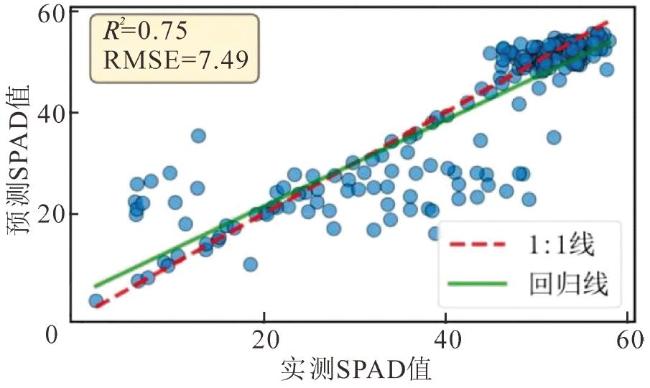
2.4 可解释性分析
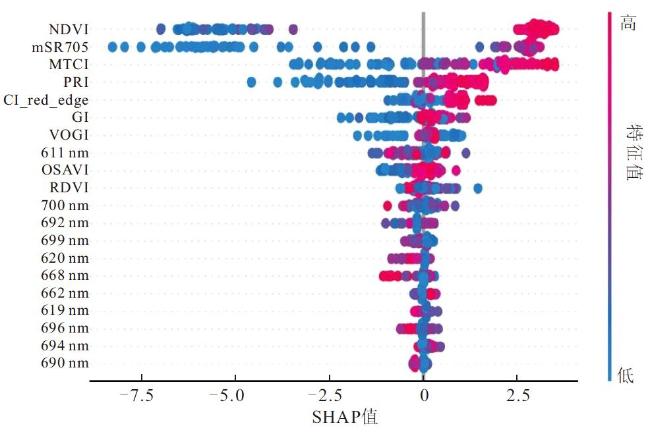
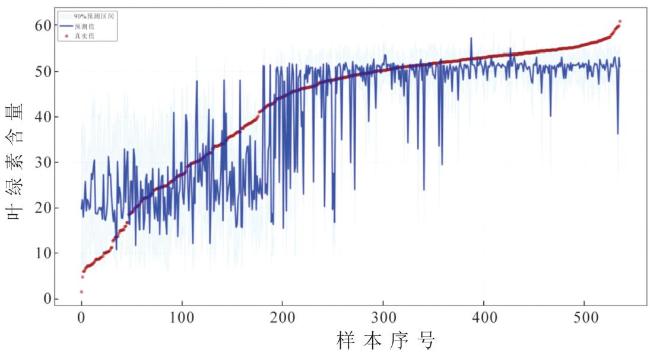
2.5 不确定性分析
表6 RATL与直接迁移不确定性对比(90%名义置信水平)Table 6 Comparison of uncertainty between RATL and direct migration ( 90% nominal confidence level) |
| | | | | | | |
|---|---|---|---|---|---|---|
| | | | | | | |
| | | | | | | |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}