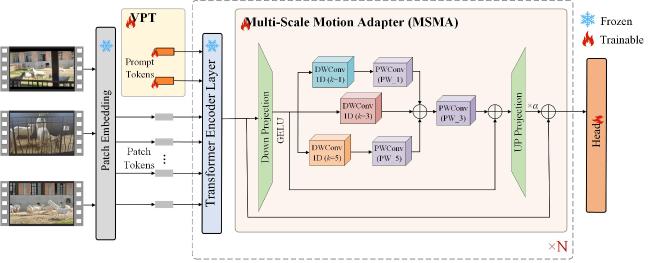
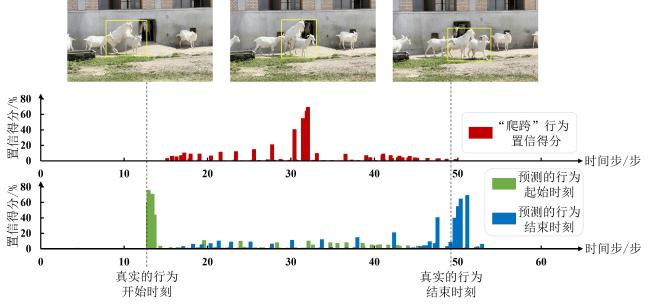
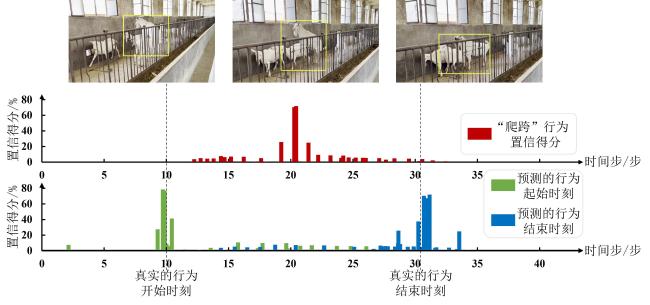
[Objective] Accurate temporal localization of mounting behaviour in dairy goats is important for intelligent reproductive management, as event frequency, onset time, and duration provide useful evidence for heat monitoring and mating decisions. Unlike simple behaviour recognition, temporal localization in untrimmed videos enables fine-grained, time-resolved records for practical farm use. However, real-world mounting behaviour is usually brief and sporadic, with few informative frames in long video streams. Moreover, weak discrimination from similar non-target interactions, together with occlusion, viewpoint variation, and background motion, often degrades boundary-aware representation learning and leads to unstable start–end localization. To address these challenges, an improved AdaTAD-based end-to-end temporal action localization approach is proposed for mounting behaviour in dairy goats, aiming to enhance localization accuracy and stability while maintaining practical efficiency for deployment. [Methods] The proposed approach adopted AdaTAD as the baseline end-to-end temporal action localization framework and introduced two complementary improvements, explicit key-frame guidance and multi-scale motion modelling, while retaining the original detection head and post-processing pipeline for generating temporal action instances. First, visual prompt tuning (VPT) was incorporated to provide task-conditioned guidance to backbone feature extraction in a parameter-efficient manner. Specifically, a small number of learnable prompt tokens were inserted into the Transformer backbone with backbone parameters frozen. Through multi-head attention interactions between prompt tokens and patch tokens, the prompts steer attention towards mounting-relevant temporal regions, strengthened feature responses at critical frames and in boundary neighbourhoods, and improved the separability between brief target segments and abundant background frames. Second, a multi-scale motion adapter (MSMA) was introduced to model motion patterns at different temporal scales and improve robustness to diverse scene dynamics. MSMA emploied parallel multi-scale temporal depthwise separable convolution branches to capture short-, mid-, and longer-range temporal variations, enhancing representations of subtle short-duration micro-actions as well as relatively complete action processes. Residual connections and nonlinear mappings further stabilised feature injection and gradient propagation, enabling multi-scale dynamics to be integrated into backbone features with limited additional optimisation burden. Overall, VPT focused on boundary-relevant attention guidance, whereas MSMA emphasises multi-scale temporal dynamics modelling; Together, they formed a complementary design within the end-to-end localization pipeline. [Results and Discussions] Comparative experiments showed that the proposed method achieves an average mAP (mean Average Precision@[0.3:0.1:0.7]) of 81.72%, improving upon the baseline AdaTAD by 5.00 percentage points, indicating that incorporating VPT and MSMA enhanced overall localization performance. At a temporal Intersection over Union (tIoU) threshold of 0.7, the proposed method attained 68.85%, exceeding AdaTAD by 4.06 percentage points, demonstrating that the performance gain was preserved under stricter temporal boundary-consistency criteria. Further comparisons with representative approached, including TadTR, VSGN, AFSD, ActionFormer, TriDet, DyFADet, and Re2TAL, showed average mAP improvements of 38.82, 33.83, 25.29, 4.09, 2.83, 1.20, and 6.06 percentage points, respectively, demonstrating stronger overall competitiveness. In terms of efficiency, the model ran at 65.78 f/s with 27.941 million trainable parameters, indicating that the accuracy gains were achieved while maintaining a relatively low parameter overhead and practical runtime efficiency. Overall, task-guided prompting and multi-scale temporal modelling improved key temporal feature representations with limited parameter increments, thereby benefiting localization of short, sporadic behaviours. [Conclusions] This study presents an improved AdaTAD-based end-to-end temporal action localization method for mounting behaviour in dairy goats. By combiningVPT for boundary-relevant attention guidance with a MSMA for multi-scale temporal dynamics modelling, the proposed approach improves localization accuracy and maintains stable advantages under stricter boundary-consistency requirements, while preserving practical inference efficiency. The method provides critical temporal information for reproductive behaviour monitoring and decision support, and offers a feasible basis for building individual-level, time-resolved management systems in real farming environments.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}