



0 引 言
为解决数据要素[4]的流转与协同计算问题,中国提出了工业互联网标识解析体系[5],构建了包含国际根节点、国家顶级节点、二级节点和递归节点的层次型架构,并在北京、上海、广州、武汉和重庆建设和部署了国家顶级节点[6]。当前,标识解析体系已在食品、服装、矿用设备等行业得到广泛应用,通过赋予每个对象唯一的身份编码并承载相关数据信息[7],起到整合加工产业资源,打通产业链、供应链和销售链,将企业、生产者与消费者进行串联的作用,还能融合工业互联网、产业互联网和消费互联网,有利于发挥集约效应[8-10]。但工业互联网标识解析技术在工业隐私数据的共享应用方面还存在一些不足。研究显示,将联邦学习、区块链和分布式计算等方法进行融合,可以有效解决隐私数据的协同计算问题。特别是联邦学习与大数据、云计算和智能边缘计算等前沿技术深度融合[11-13]能够提供解决隐私数据流通与协同计算安全问题的方案[14]。目前,联邦学习在工业工程领域应用较广,可利用横向、纵向和迁移这3种学习方式[15],解决不同地区间数据协同计算的问题[16],对不易交换的都市环境监测数据进行监测[17, 18],解决检测工厂不合格外包装、视觉检测等基础性问题,还可用于解决反恶意通信入侵等无人机通信系统安全、电动车用电需求预测等能源预测领域存在的问题[19-22]。
综上,将工业互联网标识解析体系与联邦学习算法相结合,可在多个企业中进行训练,从而实现不同主体的协同学习,且融合后的体系可以充分利用分布在不同环节中的大量数据资源,有助于提升工业互联网系统的安全性和可信度。本文结合联邦学习和标识解析的核心思想,以粮食供应链为研究对象,采用标识解析3层架构并设计相关编码,构建联邦学习模型,基于逻辑回归算法协同训练粮食供应链上的多家企业数据,打破行业间的数据孤岛,实现跨企业、跨平台的数据要素,特别是隐私数据要素的协同计算,促进工业互联网的发展和应用。
1 粮食供应链数据共享分析
粮食供应链是指从种植、收储、加工、仓储、运输到销售的一系列环节,各环节涉及不同的企业,包括但不限于种植企业、加工工厂、物流运输和销售商等。粮食供应链涉及多个种类的异构数据信息,包括种植、收储、加工、仓储、运输和销售等类别的信息。这些数据可以帮助链上企业和监管部门了解整个供应链的运作状况和性能指标,并为制定优化策略和提高粮食安全与质量水平提供有价值的参考。然而,不同环节的企业通常是独立的,它们之间的信息共享和协作往往受到一定的限制。由于缺乏有效的信息沟通和协作机制,可能会存在数据不准确、信息不完整等问题,从而影响整个供应链的效率和可靠性。在跨区域、跨行业的数据协同计算方面,由于隐私数据保护问题,使该部分数据无法上传至数据池进行共享分析,从而导致难以实现风险评估和制定优化策略[23]。
针对粮食供应链的6个环节,根据其特性需收集如品质数据、环境数据、加工数据、价格数据和供应链数据等特征数据。以稻米供应链为例,数据要素如表1所示。其中,稻米种类、生产日期、种植基地信息等公共信息可公布用于模型训练;但农药、疾病防治和含杂量等信息属于食品隐私数据,各企业一般不愿主动将其公开,导致该部分数据无法用于业务模型的训练。然而,该部分数据对于关键业务的评估和决策非常重要,其变化将会影响稻米品质的评估准确率,因此不可以舍弃,需借助联邦学习的特性解决隐私数据的协同计算难题。
表1 稻米数据要素Table 1 Rice data elements |
| 稻米全供应链环节 | 基本信息 | 环境监测信息 | |
|---|---|---|---|
| 种植 | 种植户基本信息、种植基地信息、灌溉用水水质、基地土壤质量、种子来源、稻米种类、种植时间、种植方式、育苗插秧时间、灌溉排水时间、疾病防治信息、收获时间、自然灾害信息、人为灾害情况、种植操作、肥料信息、农药信息 | 环境实时温度、昼夜温差、环境实时湿度、环境实时光照强度、土壤水分含量、环境氧气/二氧化碳浓度、土壤类型、气候、雨量、光照 | |
| 收储 | 收购 | 农药抽检记录、稻米产地信息、时间、稻米种类、地点 | 无 |
| 干燥 | 干燥方式(自然/机械)、干燥前含水量、干燥后含水量 | 环境实时温度 | |
| 除杂 | 杂质种类、含杂量、除杂率 | 环境实时湿度 | |
| 入仓 | 库存编号、仓库地址、仓库面积大小、存储环境、产品来源、产品数量、出入库时间、品质证书、质检编号、仓储人员信息 | 环境温度、湿度、氧气浓度、二氧化碳浓度、甲醛、总挥发性有机化合物(Total Volatile Organic Compounds,TVOC) | |
| 加工 | 垄谷 | 垄谷方式(垄谷机品牌)、出糙率、脱壳率 | 环境实时温度、环境实时湿度 |
| 碾米 | 碾米方式(化学法/机械法)、整米率、碎米率 | ||
| 色选 | 色选精度、带出比 | ||
| 抛光 | 抛光率 | ||
| 包装 | 商标名称、包装袋来源、规格、原料、加工人员信息、包装时间、产品包装编号、产品批次号、产品质量信息 | ||
| 仓储 | 仓储企业名称、仓储企业地址、企业法人信息、仓储管理员信息、许可证信息、管理员联系方式、库存编号、产品来源、产品数量、入库时间、质检编号、出库时间 | 环境温度、湿度、氧气浓度、二氧化碳浓度、甲醛、TVOC | |
| 运输 | 物流企业信息、运输负责人信息、许可证信息、运输工具、工具编号(车牌号)、出发地、出发时间、目的地、途经的城市与目的地、抵达时间、运输车辆内部的温度及卫生情况 | 车内环境温度、车内环境湿度、车内氧气/二氧化碳浓度 | |
| 销售 | 商家信息、商铺地址、商铺负责人信息、营业许可证信息、产品名称、产品数量、进货时间、产品存储时间、产品存储位置、进货编号、出货时间、基本情况及卫生健康情况 | 销售环境照片 | |
2 标识解析体系下的粮食供应链联邦学习架构
2.1 整体架构设计
根据工业互联网标识解析体系架构,粮食行业建设有相应的行业二级节点,生产、加工、运输、销售等相关企业节点接入行业二级节点,构成的粮食行业标识解析体系,并与联邦学习结合形成协同学习架构如图1所示。其中,粮食行业工业互联网标识解析二级节点作为联邦学习的行业第三方,负责为每袋产品打上编码[28],以追溯到该产品在各个环节的信息,从而实现供应链管理和粮食安全监管。为了精细化管理各环节的联邦学习任务,二级节点分别设置生产、加工、运输和销售等环节第三方,便于对各环节内企业的横向协同学习进行组织。另外,在跨环节的纵向联邦学习中,企业节点分别设置了工艺加工厂、运输企业等多个企业,便于组织异构企业间的纵向协同学习。

在具体实现上,扫描上传标识解析编码至第三方,由第三方下发模型至企业进行本地训练,根据反馈的信息聚合参数并更新模型直至损失函数收敛的联邦训练过程,具体如图2所示。将要执行的任务编码扫描上传至第三方,第三方根据编码中的信息判断任务类别,选择合适的联邦训练模型,设定好初始参数后下发模型至所有企业。企业根据模型要求,扫描符合要求的所有数据编码并上传数据信息至本地,再通过逻辑回归算法在本地训练该模型,迭代到指定次数后将中间参数如权重、梯度等通过发送数据训练编码的方式分别返还给第三方。由第三方通过加权平均等方法聚合,得到新参数,根据预设目标判断该参数是否达到标准,若未达到,则更新模型参数,重新下发给各个企业,继续训练至达到标准;若达到标准,则发送数据结果,并进行可视化展示。

2.2 标识编码及数据模型设计
2.2.1 标识编码设计

表2 粮食供应链协同计算的任务编码设计Table 2 Task coding design for collaborative food supply chain computing |
| a | b | c | d |
|---|---|---|---|
| 01(模型信息编码) | 模型编号 | 信息类型(主从-01、联邦类型-02参数个数-0、收敛条件-04、最大迭代次数-05、初始学习率-06) | |
| 02(模型训练编码) | 模型编号 | 信息类型(输入信息-01、输出信息-02) | 信息参数数据 |
| 03(模型结果编码) | 模型编号 | 信息类型(当前步长-01、收敛情况息-02) |
|
表3 粮食供应链协同计算的数据编码设计Table 3 Data coding design for collaborative food supply chain computing |
| a | b | c |
|---|---|---|
| 04(种植环节) | 数据编号 | 评价类型(稻谷品种-01、光照条件-02、平均温度-03、土壤类型-04、灌溉水源-05) |
| 05(加工环节) | 数据编号 | 评价类型(加工工艺等级-01、环境温度-02、环境湿度-03、水分含量-04) |
| 06(运输环节) | 数据编号 | 评价类型(运输温度-01、环境相对温度-02、储藏形式-03、运输质量-04) |
| 07(销售环节) | 数据编号 | 评价类型(环境温度-01、环境湿度、售卖时长) |
2.2.2 数据模型设计
数据模型主要是用来描述和存储标识数据,上述每个任务、数据编码都有其对应的数据模型。针对粮食供应链中标识编码规则和数据特性,设计了参数模型、信息模型和评价模型3类模型,具体如图4所示。
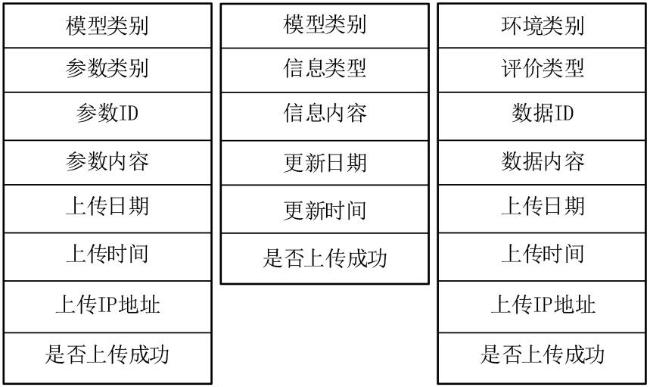
所设计的参数模型如图4(a)所示,其中“模型类别”“参数类别”和“参数ID”可确定其对应的参数数据模型。“参数内容”是该参数的具体值;“上传日期”和“上传时间”记录标识数据最近一次的更新时间,便于系统对信息进行维护或分析。通过“上传IP地址”可知该数据的上传源头;“是否上传成功”表示该信息是否已成功更新到系统或服务器。
所设计的信息模型如图4(b)所示。其中“模型类别”和“信息模型”可帮助系统快速确定所需的信息模型,并进一步获取相关描述信息;“信息内容”指该信息所包含的具体内容。其余与上一模型功能一致。
所设计的评价模型如图4(c)所示。通过“环节类别”“评价类型”和“数据ID”可确定其对应的数据模型。“数据内容”指该参数的值。其余功能与参数模型中功能一致。
3 基于联邦学习的粮食供应链隐私数据流转
联邦学习可在不公开各参与方私有数据的情况下,协同训练所有参与方。其中,参与者在本地执行算法,通过将更新的模型参数发送给中央服务器进行聚合,以更新共享模型,实现不同主体的协同计算。
3.1 同类主体间横向联邦学习
横向联邦学习是一种适用于处理具有高度特征重叠但样本ID重叠较少的数据集的方法。通过对各数据集的样本联合,扩大训练样本空间,综合多维数据特性的业务模型参数进行协同计算,进而提升模型的准确度。
3.1.1 横向联邦学习架构设计
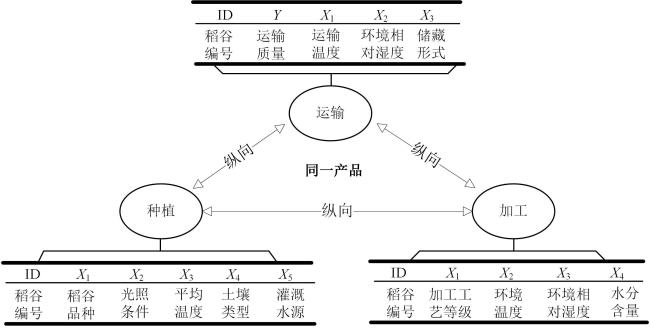
横向联邦学习在粮食行业可用于生产、加工、运输和销售等环节下的多个企业,如图5所示。粮食加工企业A和粮食加工企业B的数据均为品质质量、加工工艺等级、环境温度、环境湿度和水分含量等特征数据,但这些数据是不同批次的产品所产生的,符合横向联邦学习相同样本特征,不同样本ID的特征。

3.1.2 横向逻辑回归算法
式中: 是逻辑回归模型的系数,需要通过模型迭代确定的参数; 是样本数据的标签值; 是第i个样本数据; 是第i个样本数据的第j个特征数据。在横向联邦学习中按参与方数据集数量做横向加权聚合,各参与方都有特征值和标签值,在求梯度时各参与方只需计算本地的信息后将参数进行安全聚合,使用聚合后的结果计算损失函数和下一次迭代的梯度。以企业A和企业B为例,两方参与的横向逻辑回归的算法流程如图6所示。

以下是横向逻辑回归方法的训练步骤:
1)首先由第三方初始化参数 和参数 ,并将其分别发送给参与方A和参与方B。
2)参与方接收到初始化参数,在本地训练数据,得到梯度 和 ,并根据梯度更新参数 和参数 。
3)通过加法安全聚合技术,即通过 和 得到 参数,并将该参数发送给第三方。
4)第三方接收到所有参数后,通过 计算总梯度参数w。
5)将总梯度参数w返还给各参与方。
6)各参与方接收总梯度参数w,计算本地损失函数 和 。
7)通过加法安全聚合技术,即 和 得到参数 和 ,并将该参数发送给第三方。
8)根据接收到的参数,通过 计算得到loss损失函数,并将收敛状态发送给各参与方。
9)各参与方查看状态,若显示未收敛且未达到最大迭代次数,则继续训练,重复上述步骤。
3.1.3 粮食安全风险评估横向联邦学习实现
以粮食供应链安全风险评估作为业务场景,基于湖南省大米供应链合作企业2020—2023年供应链数据,开展横向联邦学习的协同计算验证。选取合作企业中的粮食加工厂A和粮食加工厂B,通过自动扫描标识编码获取不同批次产品的数据,累计共收集加工厂A数据90组、加工厂B数据90组和测试集数据60组。在联邦学习过程中,拥有联邦学习目标(label)信息的guest(主)方和不包含label信息的host(客)方,先在本地对原始数据进行清洗、转换和规范化的预处理操作,FATE(Federated AI Technology Enabler)平台根据前期配置好的dsl和conf文件,进行横向逻辑回归建模,并进行训练和评估测试,FATE提供可视化结果展示。
1)文件配置
① dsl流程配置文件。选用homo_lr_train_dsl.json文件进行流程配置。该文件包含reader_0(读取训练数据)、data_transform_0(转换数据类型)、scale_0(特征对齐操作)、homo_lr_0(横向逻辑回归模型训练)和evaluation_0(模型评估)这5个模块。每个模块都有输入和输出的数据和模型定义,定义的格式一致,下游模块会以上游模块的输出作为其输入。
② conf流程配置文件。选用homo_lr_train_conf.json文件进行参数配置。该文件定义了参与训练的所有角色并通过读取模型训练编码设置各个模块的初始参数。例如,data_transform_0模块的数据表名及类型;homo_lr_0模块的步长、学习率、最大迭代次数等。本实验设定初始参数如表4所示。
表4 横向联邦学习的参数设置Table 4 Parameterization of horizontal federal learning |
| 参数名称 | 数值 |
|---|---|
| 正则化方式(penalty) | L2 |
| 停止求解的标准(tol) | 0.000 01 |
| 正则化强度(alpha) | 0.01 |
| 单次训练的样本数 | 1 |
| 学习率(learning_rate) | 0.15 |
| 最大迭代次数(max_iter) | 500 |
2)横向联邦学习测试验证
横向联邦学习主要是通过流转数据参数协同计算训练模型,达到扩大样本空间,提升模型准确率的效果。若不使用联邦学习进行协同计算,只采用加工厂A自身数据进行训练,模型训练结果如表5所示。共训练加工厂A自身数据90组,其中15组数据分类错误;75组数据分类正确。若联合加工厂A和加工厂B协同训练,模型在迭代349次后收敛,损失函数约为0.272 990,模型训练结果如表5所示。auc值达到0.925 926,准确率较高,Ks值达到0.833 333,模型的区分能力较好。F 1-Score值达到0.958 333,无限接近于1,模型整体较好。根据混淆矩阵显示,共计训练90组数据,其中84组数据分类正确。准确率明显高于单个加工厂训练的模型。
表5 横向联邦学习企业模型训练结果Table 5 Horizontal federated learning enterprise model training results |
| 参与方 | Dataset | auc | Ks | Precision | Recall | F 1-Score | True lable/predict lable | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|
| 加工厂A | Train | 0.783 46 | 0.515 152 | 0.911 111 | 0.601 212 | 0.895 105 | 0 | 11 | 13 |
| 1 | 2 | 64 | |||||||
| 加工厂A和加工厂B | Train | 0.925 926 | 0.833 333 | 0.977 778 | 0.611 111 | 0.958 333 | 0 | 15 | 3 |
| 1 | 3 | 69 |
同理,若仅用加工厂A的训练结果输入60组测试数据用于评估,其训练样本较少,模型缺少普适性。风险评估验证结果如表6所示。其中52组数据验证正确;8组验证错误。若运用加工厂A和加工厂B协同训练好的模型,评估同组测试数据,其风险评估验证结果如表6所示,auc值达到0.916 149,较接近1,评估能力较好,Ks值达到0.770 186,具有较好的分类效果。F 1-Score值达到0.957 447,模型整体评估能力较好。通过混淆矩阵可看到,共60组数据,其中56组验证正确;4组验证错误;准确率约提升了6.7%。由此可得基于联邦学习的模型准确率较高,评估能力优于单个主体训练出的模型。若使用神经网络算法进行评估,由于使用小数据样本,出现了过拟合的情况,导致评估效果略差于逻辑回归算法。
表6 横向联邦学习企业风险评估验证结果Table 6 Horizontal federal learning Enterprise risk assessment validation results |
| 参与方 | 算法 | Dataset | auc | Ks | Precision | recall | F 1-Score | True lable/predict lable | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|
| 加工厂A | 逻辑回归 | Predict | 0.860 248 | 0.763 915 | 0.931 034 | 0.586 957 | 0.926 316 | 0 | 9 | 5 |
| 1 | 3 | 43 | ||||||||
| 加工厂A&加工厂B | 逻辑回归 | Predict | 0.916 149 | 0.770 186 | 0.931 034 | 0.586 957 | 0.957 447 | 0 | 12 | 3 |
| 1 | 1 | 44 | ||||||||
| 加工厂A&加工厂B | 神经网络 | Predict | 0.896 458 | 0.768 883 | 0.934 702 | 0.624 893 | 0.936 452 | 0 | 11 | 3 |
| 1 | 2 | 44 |
3.2 异构主体间纵向联邦学习
异构主体的联邦学习具有数据集间样本特征重叠较少,样本ID重叠较多的特点,大多用于处理经营不同业务但批次相同的产品。
3.2.1 纵向联邦学习架构设计
纵向联邦学习可将稻谷企业中的加工制造业和种植、运输产业联系起来,形成整体,由于同一批稻谷,它在加工、种植和运输企业所包含的数据参数各不相同,故符合纵向联邦学习同一样本,不同特征的思想,具体如图7所示,可将粮食种植企业的数据设为{X种},粮食加工企业数据设为{X加},将粮食运输企业数据设为{X物},对这些数据进行对齐的处理,只留下拥有相同稻谷编号的数据。其中设定粮食运输企业为guest方,带品质标签,粮食种植企业和粮食物流企业为host方。由于host方分别具有自己的数据集,但缺乏完整的品质标签信息。因此,需要通过同态加密的方法流转加密后的隐私数据,使host方拥有完整的信息从而共同完成模型的训练。
3.2.2 纵向逻辑回归算法
纵向联邦学习同样可采用逻辑回归的方法实现。纵向LR算法是在企业间两两进行,不含标签的host方分别和含有标签y的guest方进行交互。基于隐私数据无法传输的问题,可采用Paillier半同态加密对隐私数据进行加密处理,实现隐私数据间的流转。FATE加密方式如公式(3) 和公式(4) 所示。
式中:u、v为变量; 为加密状态。
由于加密后的数据不支持指数运算,故需要对损失函数和梯度函数进行近似的处理,处理结果分别如公式(5) 和公式(6) 所示。
式中:w是系数;y是样本数据标签;x是样本数据;l表示损失函数、 是梯度因子; 为梯度。
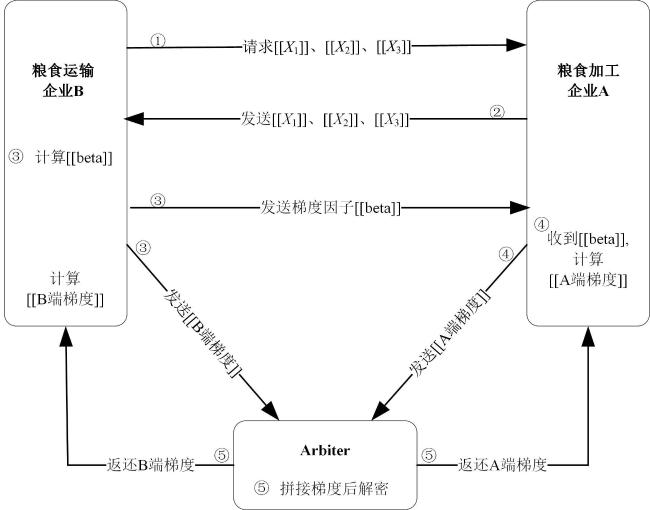
以下是纵向联邦学习逻辑回归方法的训练步骤:
1)企业B向企业A发送请求,请求得到企业A加密后的特征。
2)企业A将加密好的特征 、 、 发送给企业B。
3)企业B将自己的特征 、 加密后,根据上文提到的半同态加密的性质,通过 计算出 并将该参数发送给企业A,再结合自己的特征 、 计算出B端的梯度 并将该参数发送给第三方。
4)企业A根据收到的参数,结合自己的特征 、 和 ,计算出A端的梯度 并将该参数发送给第三方A。
5)第三方根据收到的A端和B端的参数,按行将其拼接在一起,对其进行解密操作得到完整的梯度参数,然后按照比例将A的梯度返还给企业A,将B的梯度返还给企业B。
6)企业A和企业B根据得到的返回梯度参数,更新本地的模型。
7)重复以上步骤,直至第三方判断loss函数是否收敛。若收敛,则向企业A、B两端发送停止训练的信号。( 由企业B端算出,发送至第三方解密,得到loss)。
3.2.3 粮食安全风险评估纵向联邦学习实现
纵向联邦学习主要应用于整条链的协同训练中,通过结合不同环节的数据,形成评估整个链条的模型。该模型以粮食安全风险评估作为业务场景,基于湖南省某大米供应链合作企业2020—2023年供应链数据,开展纵向联邦学习的协同计算验证。选取合作企业中的粮食种植企业、粮食加工企业和粮食运输企业,通过自动扫描编码获取同一批次产品的数据,累计收集数据共计450组,包含种植业、加工业和运输业各150组数据。其中每个参与方拿出90组数据作为训练集,剩余60组数据作为测试集用于评估。根据模型信息编码要求,先在本地对原始数据进行清洗、转换和规范化的预处理操作。FATE平台根据前期配置好的dsl和conf文件,进行纵向逻辑回归建模,并进行训练和评估测试,FATE提供可视化结果展示。
1)文件配置
① dsl流程配置文件
应用hetero_lr_normal_dsl.json文件。该文件与横向联邦学习所用文件相似,但需注意将scale_0(特征对齐操作)模块替换为data_transform_0(转换数据类型)模块;将homo_lr_0(横向逻辑回归模型训练)模块替换为hetero_lr_0(纵向逻辑回归模型训练)模块。
② conf参数配置文件
应用hetero_lr_nomal_conf.json文件。在该文件中定义参与模型训练的所有角色,通过识别模型训练编码设置各个模块的参数。例如,data_transform_0模块的数据表名及类型,hetero_lr_0模块的步长、学习率、最大迭代次数等参数。本次实验设定初始参数如表7所示。
表7 纵向联邦学习参数设置Table 7 Parameter setting of vertical federation learning |
| 正则化方式(penalty) | L2 |
|---|---|
| 停止求解的标准(tol) | 0.000 1 |
| 正则化强度(alpha) | 0.01 |
| 单次训练的样本数 | 320 |
| 学习率(learning_rate) | 0.15 |
| 最大迭代次数(max_iter) | 1 000 |
2)纵向联邦学习实现结果
表8 不同迭代条件下模型训练结果Table 8 Model training results under different iteration conditions |
| max_iter | Dataset | auc | Ks | Precision | Recall | F 1-Score | True lable/predict lable | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|
| 500次 | Train | 0.953 914 | 0.837 121 | 0.977 778 | 0.666 667 | 0.941 176 | 0 | 18 | 6 |
| 1 | 2 | 64 | |||||||
| 1 000次 | Train | 0.961 49 | 0.928 030 | 0.977 778 | 0.666 667 | 0.977 444 | 0 | 22 | 2 |
| 1 | 1 | 65 |
纵向联邦学习风险评验证结果如表9所示。auc值达到0.942 434,Ks值达到0.900 159,具有极佳的分类效果。F 1-Score值达到0.959 091,模型整体评估能力较好。通过混淆矩阵可看到,共60组数据,其中57组验证正确;3组验证错误。准确率提升了8.3%,具有良好的评估效果。
表9 纵向联邦学习风险评估验证结果Table 9 Model training results under different iteration conditions |
| Model | Dataset | auc | Ks | Precision | Recall | F 1-Score | True lable/predict lable | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|
| Hetero | Predict | 0.942 434 | 0.900 159 | 0.966 667 | 0.659 048 | 0.959 091 | 0 | 10 | 2 |
| 1 | 1 | 47 |
4 结 论
本研究提出了基于工业互联网标识解析技术和联邦学习的粮食供应链数据要素流转与协同计算架构,设计了适应模型需求的标识解析编码和数据模型,基于逻辑回归算法实现模型参数梯度的下降优化,构建了适用于单环节双企业间的同构主体模型以及三环节联合的异构主体模型,结果表明,相较于传统的单一主体评估计算,横向联邦学习的准确率提升了约6.7%,纵向联邦学习的准确率提升了约8.3%,解决了粮食供应链风险综合评估场景中的隐私数据要素协同计算问题在后续的研究中,可以进一步完善标识解析编码和数据模型,以适应更多不同类型的供应链。通过增加标识解析编码,可覆盖更多风险指标,提高模型的泛化能力;还可以加强多个环节与企业之间的联合学习,进一步扩展训练对象,更好地解决供应链中的数据要素协同计算问题,提高整个供应链的效率和安全。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}