



0 引 言
1 智能问答技术相关研究
1.1 命名实体识别
1.2 知识问答
2 果蔬农技知识需求分析
表1 果蔬农技知识需求调研种植户的基本特征Table 1 The characteristics of farmers related with the requirement study on agricultural knowledge |
| 样本种植户 | 描述 | 百分比/% |
|---|---|---|
| 性别 | 男 | 95.5 |
| 女 | 4.5 | |
| 年龄 | 40岁及以下 | 29.1 |
| 40~50 | 35.3 | |
| 50岁及以上 | 35.6 | |
| 学历 | 初中及以下 | 81.3 |
| 高中及以上 | 18.7 | |
| 家庭务农人口比例 | 30%及以下 | 14.2 |
| 30%~90% | 72.1 | |
| 90%及以上 | 13.7 | |
| 年家庭收入 | 5万及以下 | 24.4 |
| 5万~8万 | 63.9 | |
| 8万及以上 | 11.7 | |
| 草莓单产水平 | 20 t/hm2及以上 | 49.3 |
| 5~20 t/hm2 | 47.2 | |
| 5 t/hm2及以下 | 3.5 |
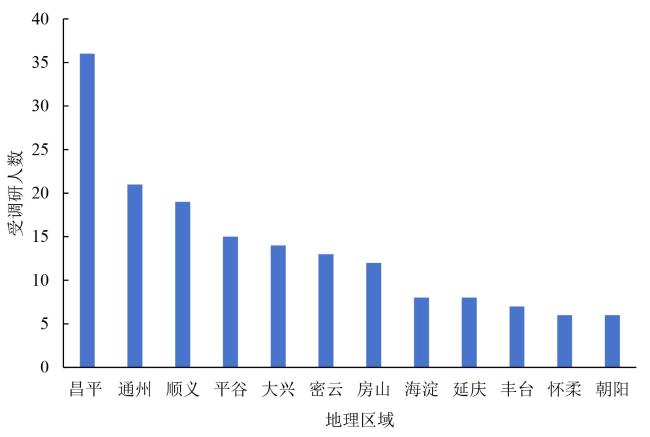
表2 草莓种植户的农技需求分布Table 2 Agticultural technology demand distribution of strawberry farmers |
| 技术类型 | 需求 比例/% | 种植户对现有技术水平的评价 | |||
|---|---|---|---|---|---|
| 满足/% | 基本 满足/% | 有待 提高/% | 亟待 提高/% | ||
| 种苗培育技术 | 75.5 | 13.85 | 23.08 | 40.00 | 23.08 |
| 水肥及管理技术 | 81.2 | 7.69 | 32.31 | 38.46 | 21.54 |
| 病虫害防治技术 | 91.3 | 7.58 | 16.67 | 51.52 | 24.24 |
| 贮运及加工技术 | 85.6 | 13.85 | 29.23 | 47.69 | 9.23 |
| 优质生产技术 | 72.1 | 10.77 | 21.54 | 41.54 | 26.15 |
| 增加产量良种技术 | 93.3 | 21.54 | 33.85 | 23.08 | 21.54 |
| 节本高效栽培技术 | 90.7 | 7.69 | 26.15 | 53.85 | 12.31 |
| 省工机械技术 | 77.7 | 10.77 | 38.46 | 33.85 | 16.92 |
| 新品种应用 | 69.3 | 25.76 | 37.88 | 16.67 | 19.70 |
| 新农药和肥料应用技术 | 67.9 | 32.31 | 26.15 | 30.77 | 10.77 |
| 新农具应用技术 | 73.7 | 29.23 | 30.77 | 26.15 | 13.85 |
| 品牌经营技术 | 49.2 | 33.85 | 15.38 | 30.77 | 20.00 |
3 果蔬农技知识智能问答大模型构建
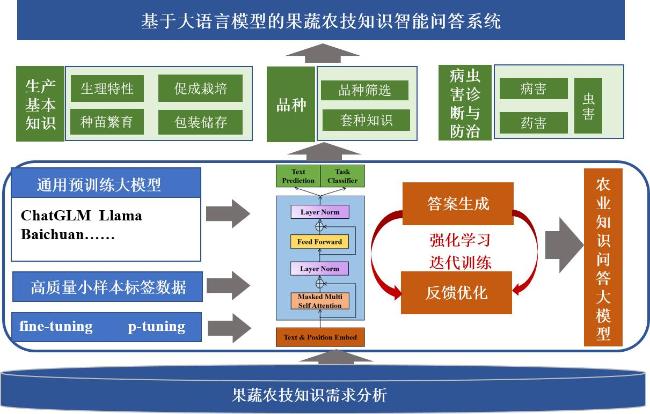
3.1 获取农技知识语料
3.2 形成小样本高质量标注语料
表3 大模型训练标注语料数据统计Table 3 The statistical analysis of labeled database for the LLM training |
| 知识专题 | 生产基本知识 | 品种筛选 | 套种知识 | 虫害诊断与防治 | 病害诊断与防治 | 药害诊断与防治 | 总量 |
|---|---|---|---|---|---|---|---|
| 标注语料 数量 | 151 | 107 | 61 | 212 | 232 | 106 | 869 |
| 知识对象 数量 | 5 | 1 | 3 | 4 | 4 | 4 | 21 |
| 知识实体类型数量 | 9 | 2 | 4 | 6 | 6 | 5 | 32 |
| 问答对数量 | 63 | 47 | 22 | 44 | 48 | 36 | 260 |
3.3 构建农业知识实体识别和农业知识问答大模型
4 结果与讨论
4.1 知识实体识别结果分析
4.1.1 性能评价指标
4.1.2 精准率分析
表4 初期预训练大模型精准率分析Table 4 Accuracy analysis of initial pre-trained LLMs |
| 知识主题 | Baichuan | Llama | ChatGPT | ChatGLM | ||||
|---|---|---|---|---|---|---|---|---|
| B/% | A/% | B/% | A/% | B/% | A/% | B/% | A/% | |
| 生产基本知识 | 62.7 | 82.9 | 66.7 | 82.9 | 62.7 | 81.9 | 79.7 | 86.5 |
| 品种筛选 | 76.3 | 87.4 | 80.3 | 87.4 | 76.3 | 82.4 | 80.3 | 89.4 |
| 套种知识 | 71.8 | 85.9 | 77.8 | 85.9 | 73.8 | 79.9 | 77.8 | 87.9 |
| 虫害诊断与防治 | 72.3 | 85.9 | 78.3 | 88.5 | 74.7 | 80.9 | 78.3 | 91.6 |
| 病害诊断与防治 | 75.0 | 86.5 | 80.3 | 89.2 | 74.1 | 81.7 | 78.3 | 92.5 |
| 药害诊断与防治 | 72.2 | 85.2 | 76.2 | 85.2 | 72.2 | 80.2 | 76.2 | 87.2 |
| 平均值 | 71.7 | 85.6 | 76.6 | 86.5 | 72.3 | 81.2 | 78.4 | 89.2 |
|
4.1.3 召回率分析
表5 初期预训练大模型召回率对比分析Table 5 Recall analysis of initial pre-trained LLMs |
| 知识主题 | Baichuan | Llama | ChatGPT | ChatGLM | ||||
|---|---|---|---|---|---|---|---|---|
| B/% | A/% | B/% | A/% | B/% | A/% | B/% | A/% | |
| 生产基本知识 | 56.1 | 47.5 | 57.3 | 59.5 | 51.8 | 46.7 | 69.7 | 70.4 |
| 品种筛选 | 70.7 | 69.6 | 70.1 | 72.9 | 70.4 | 62.4 | 70.2 | 72.1 |
| 套种知识 | 66.6 | 67.5 | 69.2 | 71.5 | 68.9 | 60.1 | 68.0 | 70.6 |
| 虫害诊断与防治 | 68.5 | 63.2 | 68.2 | 76.7 | 69.4 | 63.5 | 67.5 | 75.9 |
| 病害诊断与防治 | 67.2 | 65.4 | 68.1 | 77.9 | 68.2 | 65.9 | 69.3 | 76.3 |
| 药害诊断与防治 | 65.3 | 67.1 | 67.5 | 77.2 | 67.3 | 61.4 | 65.9 | 70.1 |
| 平均值 | 65.7 | 63.4 | 66.7 | 72.6 | 66.0 | 60.0 | 68.4 | 72.6 |
|
4.1.4 微调效果分析
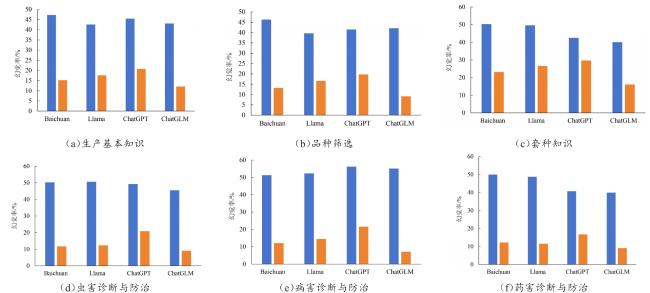
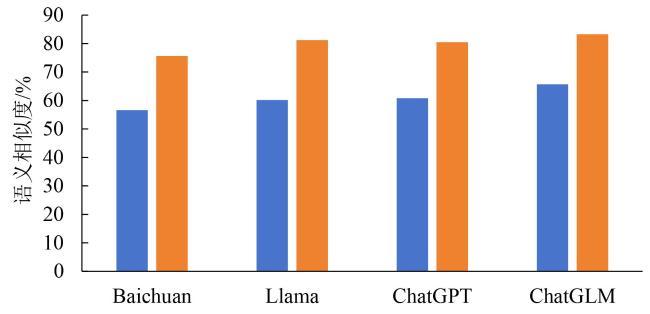
4.2 农技知识问答结果分析
4.2.1 大模型性能定量分析
4.2.2 具体问答案例分析
表6 大模型“微调+优化”前后的回复内容对比Table 6 The comparative analysis of LLMs' reply before and after fine-tuning and optimization |
| 问题 | 微调前 | 微调后 |
|---|---|---|
| 大拱棚半促成草莓栽培有什么特点 | 大拱棚半促成草莓栽培是一种草莓种植技术,其特点是: 1)大拱棚:该栽培结构较大,通常采用60~70 cm的高拱棚,顶部有通风口和排水口,可以保持土壤湿度和通风良好 2)半促成:在这种栽培结构中,草莓生长期较短,通常为20~30 d,而果实成熟期较长,通常为50~60 d。因此,草莓的生长期和果实成熟期比较接近,可以满足消费者对快速生长和大量果实的需求 3)草莓品种选择:半促成草莓栽培适合选择生长期较短、果实大小适中、口感鲜美的草莓品种,如红颜、赤星、巨峰等 4)土壤选择:半促成草莓栽培通常需要在土壤肥沃、排水良好的地区进行种植,同时需要合理施肥和浇水,以保持土壤湿度和营养供给 5)病虫害控制:半促成草莓栽培需要加强对病虫害的控制,可以使用农药进行预防和治理,以保证草莓的安全和丰收 | 大拱棚半促成草莓栽培是一种高效、经济、方便的草莓种植技术,适合在不同地区进行推广和应用。大拱棚半促成栽培是指草莓在露地促成栽培与大拱棚保护下促成栽培的混合栽培形式。相对于露地促成栽培,半促成栽培具有以下几个特点: 1)充分利用白天高温资源,加快草莓生长,缩短上市期,经济效益高 2)节省劳动力,减少人工辅助次数,节约劳动力成本 3)在半促成栽培期间,温度更为灵活,可以根据实际情况适时调整温度,使植株生长更为适宜 4)露地促成栽培草莓在低温下容易“休眠”,而半促成栽培可以在露地促成栽培与保护地促成栽培之间实现“中间状态”,顺利实现“休眠”与“清醒”的转变 5)大拱棚半促成栽培相对于露地促成栽培更为灵活,可提前采果,减少空袋率,提高果实产量 |
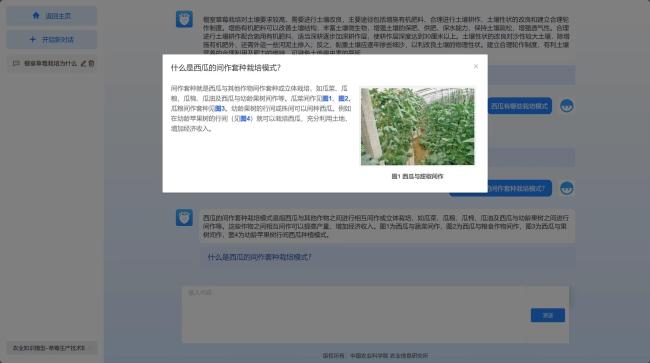





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}