



0 引 言
随着农业信息知识的日益丰富,农技服务平台在农业病害的预防和诊断中扮演着至关重要的角色。如何快速且精准地获取与农业病害相关的信息,并深入挖掘语义关系,已成为农技服务平台亟待解决的问题。命名实体识别(Named Entities Recognition, NER)是知识图谱构建过程中重要的上游任务,其目的是识别文本中具有特定意义的实体[1]。NER作为知识抽取的一项基础性工作,其准确率决定了知识图谱构建的质量。
通用领域中NER一般是将预先定义好的人名、地名等常见实体抽取出来,由于实体之间不存在交叉结构,句子中的每个字符只会属于一种实体类型,抽取相对简单。而在实际应用中,农业病害领域的实体通常由很长的词汇组成,实体中的字符可能涉及多个标签,即一个实体可以包含其他实体或成为其他实体的一部分,从而形成实体之间的嵌套结构[2]。如图1所示,在“黄瓜细菌性角斑病病原为丁香假单胞杆菌黄瓜角斑病致病变种”文本中,病害实体“黄瓜细菌性角斑病”嵌套着危害作物实体“黄瓜”;病原实体“丁香假单胞杆菌黄瓜角斑病致病变种”中,嵌套病害实体“黄瓜角斑病”。而传统实体识别方法,主要关注非嵌套实体的识别,一般采用“序列标注+特征学习”的方式对实体进行识别[3],即每一个字符只能添加一个实体标签,无法在底层文本中捕获更细粒度的语义信息,可能导致一些实体的边界信息丢失,并且难以准确捕捉到实体之间存在的交叉包含等复杂关系,降低实体识别的质量和准确性。近年来,研究者从基于规则和机器学习的技术、超图表示、特殊序列标注和跨度模型等多个方面来解决实体嵌套问题。

在早期,人们常常将基于规则和基于机器学习的方法相结合,以处理嵌套命名实体的问题。Zhang等[4]使用隐马尔可夫模型来识别最内层的非嵌套命名实体,接着采用基于规则的方法来辨识外层命名实体。徐帅博[5]则针对病虫害领域提出了一种标注规则,考虑实体边界划分问题,并且使用这些规则对病害名称、症状、农药品等进行了实体标注。Shibuya和Hovy[6]提出了一种次优序列学习和基于CRF(Conditional Random Field)的解码方法进行嵌套NER。Zhang等[7]提出了一种自动化的中文NER模型,并定义了校准实体边界的特定规则。这解决了小麦病虫害领域所面临的训练数据稀缺、实体嵌套、实体边界模糊等问题。Li等[8]提出了一种名为W2NER(Word-Word Relation Classioncation)的模型,将NER问题统一建模为“词-词”关系分类问题,推动了统一NER的最新性能。Zhang和He[9]结合了中文笔画、汉字部首以及汉字特征,利用卷积网络从中提取汉字笔画信息,并将其与字词信息相结合。这样做有效地丰富了语义信息和实体边界信息,从而减少了实体嵌套问题的出现。Wu等[10]通过汉字特征与部首级嵌入集成,得到蕴含更多信息的嵌入表示,对实体有效提取。然而,基于规则和基于机器学习的方法在解决嵌套NER问题时都会面临识别困难和高时间复杂度等问题。
随着深度学习的快速发展,利用深度学习方法在NER任务中已经取得显著的成果。Wang等[13]引入了一种创新的分层模型,以自内向外的方式处理嵌套NER任务。在这一思路下,嵌套命名实体的辨识变得更为精准和高效。Obaja Muis和Lu[14]提出了一种序列标记方法,引入一种分隔符概念,将标签分配给单词之间的间隙,来解决嵌套问题。此外,He等[15]设计了一个结合了注意力机制的卷积神经网络(Convolutional Neural Networks, CNN)-双向门控循环单元网络(Bi-Gated Recurrent Unit, BiGRU)-条件随机场(Conditional Random Field, CRF)的复合网络模型,用于识别外来海洋生物的命名实体。金彦亮等[16]则采用分层标注的方法,将嵌套实体识别划分为不同层次的任务。这种新的序列标注策略很好地解决了传统实体识别的问题,但同时也可能带来无法并行训练和错误传播等挑战。
尽管通用领域的实体嵌套研究取得一定进展,但面向通用领域的实体识别方法在专业领域上的效果不佳。不同领域实体含义存在不一致,实体边界不清晰,没有大规模地标注数据集进行训练,从而使领域小样本场景下实体识别困难。在专业领域NER中,命名实体的类型和含义通常需要根据实际情况来定义。因此,针对农业病害领域的NER缺乏公开的数据集、存在实体嵌套和类型混淆等问题,本研究完成以下工作:通过爬取网络资源和人工摘录的方式,获取农业病害实体识别语料,结合植保专家意见,构建农业病害数据集,其中包含2 867条标注语料,共10 282个实体。使用RoFormer预训练模型独特的位置编码,充分利用位置编码信息和上下文信息,获得更丰富的字词特征,从而解决一词多义导致的类型易混淆的问题。最后,采用指针网络模型进行解码。指针网络采用了两个标签序列:一个表示实体的起始位置;另一个表示实体的结束位置,有效解决存在的实体嵌套问题。
1 命名实体识别方法
NER方法由RoFormer预训练编码模块和指针网络解码模块构成,结构如图2所示。首先将文本序列 输入到RoFormer预训练模型中,根据旋转位置嵌入(Rotary Position Embedding, RoPE)的方法有效利用位置信息。利用Self-Attention机制,从语义上捕捉给定语料库的上下文表示,生成病害文本的向量表示 。然后输出的词向量输入到指针网络解码模型中,对输入向量进行首尾标注,并且在记录位置的同时,标注该实体的类别,并识别输入句子中所有可能的实体。

1.1 RoFormer预训练模型
RoPE是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码效果”。RoPE是唯一可用于线性注意的相对位置嵌入,实现了一些有价值的特性,包括序列长度的灵活性,字符间的依赖性随着相对距离的增加而递减,以及为线性自注意力配备相对位置编码的能力。在RoPE中是“通过绝对位置编码的方式实现相对位置编码”,通过公式(1) 给 q 和 k 添加绝对位置信息。
设存在一个函数 ,它定义了有绝对位置信息的 和 产生的向量之间的内积,从而表示二者的相对位置,如公式(2) 所示。
通过 给 引入绝对位置信息,然后进行attention操作后,带有相对位置信息。通过复数公式转换,将其写成矩阵形式,如公式(3) 所示。
由于矩阵乘法表示一个矩阵映射到另一个矩阵的空间变换,而上述矩阵则是对 q 进行旋转操作,所以也叫做旋转位置编码。其高维度表达简写形式如公式(4) 所示。
正是采用了独特的旋转位置编码技术,使绝对位置编码的方式实现相对位置编码效果,使RoFormer预训练模型与其他预训练模型不同,可以利用向量之间的旋转角度表示特征之间的相对关系,其独特的位置编码能够充分结合词的语义和位置信息,可以获得更丰富的字词特征,从而更好地解决一词多义导致的类型易混淆的问题。
1.2 指针网络模型
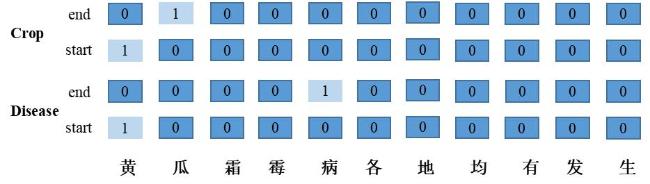
用 和 分别表示将输入序列中的第i个单词标识为对象的开始位置和结束位置的概率,如公式(5) 和公式(6) 。
式中: 表示可训练的权重; 是偏差;而 是sigmoid激活函数。
如果概率超过某个阈值,则相应的部分将被分配一个标签1,否则将被分配一个标签0。 是输入序列中第 个单词的编码表示,即 。
主题标记器优化以下似然函数,以确定给定句子表示 的主语 范围如公式(7) 所示。
式中: 表示句子的长度; 表示 中第 个单词的主语开始位置的二进制标记; 表示对象的结束位置;参数 。
指针标注通过预测实体词的起始和终止位置来识别实体。一个指针网络可以用于识别特定类别的实体,多类实体时可以使用到多个指针网络。由于指针网络仅需预测实体的起始和终止位置,所以更容易处理较长的实体,而且多个指针网络之间是独立的,因此能够直接解决嵌套问题。
2 实验结果与分析
2.1 数据集构建
本研究使用自建的农业病害数据集。数据来源有两类:一是使用爬取软件八爪鱼采集器对百度百科、惠农网等农技网站上的农业病害数据进行爬取(仅用于科研工作);二是采用人工摘录病害的方式从《蔬菜病虫害防治手册》《中国蔬菜病虫害原色图谱续集》等专业书籍上获取数据。由于多元异构数据会存在一些无用信息过多、内容重复、格式不规范等问题,因此需要对数据预处理,提高数据可靠性。数据预处理流程如图4所示。

首先对获取数据进行清洗,剔除不必要和重复的数据,然后对数据进行分词、词性标注操作,最后结合植保专家修正意见构建农业病害数据集。数据集中包含2 867条标注语料,共10 282个实体。
其中包含实体类型8种:病害名称(Disease)、作物名称(Crop)、病害特征(Feature)、病原(Pathogeny)、发病地区(Region)、发病因素(Factor)、防治方法(Method)和发病阶段(Period)。标注实体示例如表1所示。
表1 实体类型标注示例Table 1 Example of entity type annotation |
| 实体类型 | 示例 | 标签 | 数量/个 |
|---|---|---|---|
| 病害名称 | 小麦白粉病、黄瓜蔓枯病 | Disease | 1 014 |
| 作物名称 | 小麦、黄瓜、番茄 | Crop | 1 115 |
| 病害特征 | 暗绿色水渍状软腐 | Feature | 4 359 |
| 病原 | 葫芦科刺盘孢 | Pathogeny | 571 |
| 发病地区 | 长江中下游、中国上海 | Region | 617 |
| 发病因素 | 低温高湿、连作 | Factor | 1 109 |
| 防治方法 | 合理密植、轮作换茬 | Method | 1 123 |
| 发病阶段 | 结果期、成株期 | Period | 374 |
根据定义的实体类型,采用精灵标注助手工具对文本中的实体进行标注。标注过程如图5所示。

在进行作物病害NER过程中,需要通过自编译的脚本将由精灵标注助手标注后输出的NER数据集数据,转换成合适的数据格式。数据格式如图6所示。

2.2 评价指标
本研究采用精确率(Precision, P)、召回率(Recall, R)和调和平均数F 1值(F 1-Score)作为不同模型性能的评判指标[24]。各评价指标的计算如下。
精确率:正确预测的样本数量/预测中所有样本的数量。具体如公式(8) 所示。
式中:TP为将正类预测为正类的个数;FP为将负类预测为正类的个数
召回率:正确预测的样本数量/标准结果中所有样本的数量。具体如公式(9) 所示。
式中:FN为将正类预测为负类的个数。
F 1值:精确率(P)和召回率(R)的加权调和平均,具体如公式(10) 所示。
2.3 实验环境及参数设置
本研究与对照组试验均在Ubuntu20.04环境下进行,处理器为Intel Xeon(R) Gold 6248R,内存为256 G,显卡为GeForce RTX 3090 24 G,CUDA版本为11.4的实验环境下进行训练。具体参数设置参照表2。
表2 NER实验参数设置Table 2 NER experimental parameter settings |
| 参数 | 数值 |
|---|---|
| max_sqe_len | 256 |
| epoch | 50 |
| Batch_size | 32 |
| warmup_proportion | 0.01 |
| learning rate | 3e-5 |
| Dropout | 0.5 |
2.4 实验结果分析
2.4.1 不同向量化模型的性能对比
表3 不同嵌入向量模型性能对比Table 3 Performance comparison of model with different embedded vector |
| 模型 | 精确率/% | 召回率/% | F 1值/% |
|---|---|---|---|
| PointerNet | 80.03 | 74.52 | 77.17 |
| Word2Vec-PointerNet | 80.67 | 75.11 | 77.79 |
| BERT-PointerNet | 85.58 | 79.64 | 82.50 |
| RoBerta-PointerNet | 86.03 | 79.91 | 82.86 |
| RoFormer-PointerNet | 87.49 | 85.76 | 86.62 |
Word2Vec-PointerNet模型是一类神经网络模型,通过神经网络对词的上下文进行训练,得到词的向量化表示。该模型在自建数据集中F 1值为77.79%。然而,在处理农业病害数据集时,Word2Vec方法无法有效解决一词多义的问题,导致实体类型混淆。例如,“黄点子”既可以表示一种病害特征,又可以表示一种病害,从而影响实体识别结果。相比之下,BERT-PointerNet模型中,BERT采用多层Transformer编码器,充分挖掘大规模文本中的语义信息,融合左右两侧语境信息,获取更为丰富的字级别语义表示,加深了自然语言处理模型的深度。这解决了农业病害领域中不同语境下一词多义的问题,相较于Word2Vec模型,F 1值提升4.71%。RoFormer-PointerNet模型中,RoBERTa预训练模型在BERT基础上进行了改进,采用动态掩码技术提高数据的复用效率,并引入更多预训练数据、更大批次、更长预训练步数和更大的BPE词表。这使得RoBERTa获取更为丰富的语义表示,相对于BERT为预训练的模型,F 1值提升0.36%。不同于以上模型思路,RoFormer预训练模型采用旋转位置编码(RoPE)技术,通过旋转向量之间的角度来表示特征之间的相对关系。其独特的位置编码能够充分结合词的语义和位置信息,获得丰富的字词特征。在模型识别效果方面表现出色,最高的识别精确率达到87.49%,F 1值为86.62%。实验结果表明,RoFormer预训练模型在实体抽取上具有显著优势。
2.4.2 不同解码模型的性能对比
表4 RoFormer联合不同解码模型的性能对比Table 4 Performance comparison of RoFormer combined with different decoding models |
| 模型 | 精确率/% | 召回率/% | F 1值/% |
|---|---|---|---|
| RoFormer-BiLSTM | 85.48 | 78.47 | 81.82 |
| RoFormer-CRF | 84.32 | 77.84 | 80.95 |
| RoFormer-BiLSTM-CRF | 85.20 | 80.45 | 82.75 |
| RoFormer-PointerNet | 87.49 | 85.76 | 86.62 |
基于RoFormer预训练模型,融入不同解码结构,在自建的农业领域数据集上进行对比试验,RoFormer-PointerNet结构的方法性能优于其他基准模型,其精确率、召回率和F 1值分别为87.49%、85.76%和86.62%。
RoFormer-BiLSTM模型可以通过双向LSTM[30]有效地捕捉到了输入的过去和未来特征,对序列每个字符进行分类。RoFormer-CRF模型通过数据学习标签转移关系和一些约束条件,帮助模型选择正确合理的实体标签序列,可以减少无效的实体标签序列的预测判断,其中RoFormer-BiLSTM模型和RoFormer-CRF模型的F 1值分别为81.82%和80.95%。
RoFormer-BiLSTM-CRF模型是将BiLSTM和CRF两模型进行结合。首先对文本字符序列进行编码表征,再利用BiLSTM对序列每个字符进行分类,最后利用CRF进行最终标签判断确定。相比较RoFormer-BiLSTM和RoFormer-CRF,F 1值分别提升0.93%和1.8%。但基于BiLSTM模型和CRF模型的方法,均采用序列标注的方式进行NER。利用BIO、BIOES和BMES等常用的标注规则对经过分词的文本进行字符标注。这种标注方法只有一个标签序列,每个字符只能标注一次,表达能力较弱,因此不能很好地解决一个字符存在多个实体中的嵌套问题。
在指针网络标注体系中,使用Span标注的方法,以半指针-半标注的结构预测实体的起始位置,标注过程中同时给出实体类别。该方法能够很好地处理嵌套和不连续的问题,并且泛化能力较强。例如,“黄瓜靶斑病”,黄瓜是表示作物的实体。“黄瓜靶斑病”是表示病害的实体,是农业病害数据集中典型的嵌套实体类型。如果用一般序列标注的方法来提取,只能提取出其中的一个实体,但是用指针网络模型就可以很好解决这一问题。
实体的嵌套抽取主要会影响实体类型的抽取结果。如图7所示,为各个模型抽取不同实体类型的识别结果。在自建的农业病害文本中,实体嵌套的问题主要存在于病害(Disease)和作物实体(Crop),病害(Disease)和病原(Pathogeny)实体中。通过与RoFormer-BiLSTM、RoFormer-CRF、RoFormer-BiLSTM-CRF模型的对比结果可以发现,本研究提出的方法在抽取Crop实体类型上远远高于其他模型。这是因为本方法可以很好地抽取出嵌套在Disease实体中的Crop实体,从而提高Crop实体抽取的结果。说明本方法可以加强实体边界信息的识别,增强文本的语义特征,很好地解决了实体与实体之间存在的嵌套问题。

2.4.3 不同模型性能对比
表5 不同NER模型的性能对比Table 5 Performance comparison of different NER models |
| 模型 | 精确率/% | 召回率/% | F 1值/% |
|---|---|---|---|
| BilSTM-CRF | 71.93 | 73.66 | 72.79 |
| BERT-BiLSTM-CRF | 85.43 | 76.04 | 80.46 |
| RoBERT-BiLSTM-CRF | 84.38 | 78.29 | 81.22 |
| TPLinker | 82.57 | 85.60 | 84.06 |
| UIE | 72.93 | 58.02 | 64.63 |
| MRC | 81.77 | 83.58 | 82.57 |
| W2NER | 76.29 | 81.77 | 78.55 |
| Cascade | 87.46 | 84.22 | 85.81 |
| RoFormer-PointerNet | 87.49 | 85.76 | 86.62 |
BiLSTM-CRF模型中,BiLSTM通过隐藏层获得输入序列丰富的上下文信息,再添加CRF层,利用实体间相邻的标签动态规划最优的序列标注,模型F 1值为72.79%。与BiLSTM-CRF模型相比,BERT-BiLSTM-CRF模型借助BERT预训练模型的优点,BERT的动态词向量获取能力很强,词向量表现上要优于BiLSTM-CRF的embedding的方式,与BiLSTM-CRF模型相比,BERT-BiLSTM-CRF的F 1值提升7.67%。而RoBERTa-BiLSTM-CRF模型采用RoBERTa预训练模型,与BERT-Bi-LSTM-CRF模型相比,F 1值提升0.76%。TPLinker[32]融合了多头multi-head抽取范式和3种自定义标注方式的思想,实体抽取F 1值为84.06%。UIE模型是一种统一信息抽取的框架,也是采用指针标注的方式。在使用UIE做实体识别时,预测的时间与实体类别数量成正比,有多少个实体类别,实体识别中每次取一个类别作为prompt与原文本拼接作为模型的输入,所以有多个实体类别就会预测多次。但是对于单一实体识别,抽取效果并不好。MRC模型的F 1值为82.57%,在使用之前,需要进行大量的数据预处理操作,在不同的数据集上的效果差异比较大,而且数据处理也非常影响模型的性能,MRC模型是一个性能非常不稳定的模型。W2NER是一个统一的NER模型,将NER任务转换预测word-word的关系类别,W2NER基于bert+lstm进行词编码,获得词的上下文向量,在自建的农业病害数据集上F 1值为78.55%。Cascade模型实体识别F 1值为85.81%。该模型是将NER任务改成一个多任务学习的框架,将实体抽取和判断实体类型分成两个任务来判断:一个任务用来单纯抽取实体;另一个任务用来判断实体类型。但抽取的实体要两个任务都判断正确才可以。本方法使用带有旋转位置编码(RoPE)技术的RoFormer预训练模型,以利用位置信息进入预训练的学习过程,链接指针网络解码模型。通过实验对比发现,本方法识别效果优于其他模型,识别精确率最高达到87.49%、F 1值为86.62%,可以有效地识别中文农业病害文本中的实体,缓解抽取过程中存在的实体嵌套问题。
3 结 论
针对农业病害NER中缺少公开数据集和中文实体抽取过程中存在实体嵌套和类型易混淆的问题,本研究通过爬取网络资源和人工摘录的方式,获取农业病害实体识别语料,经过一系列预处理,构建了农业病害领域语料集,提出一种基于RoFormer预训练模型的指针网络农业病害NER方法。在该方法中采用具有独特位置编码方式的RoFormer预训练模型来编码绝对位置,同时在Self-Attention中增强了明确的相对位置依赖性,充分利用位置编码信息和上下文信息,获得了丰富的字词特征,解决了一词多义导致的类型易混淆的问题。用指针网络模型进行解码,可以对每个字符进行多次标签标注,有效解决存在的实体嵌套问题。
本研究提出的模型RoFormer-PointerNet在自建的农业病害数据集上,精确率、召回率、F 1值分别达到87.49%,85.76%和86.62%。通过对比实验,验证了本方法在中文农业病害领域知识抽取中的有效性,为农业病害相关智能问答、智能搜索等农业信息化下游任务提供技术支持。
本研究提出方法仍存在不足,接下来的工作着重于以下几点:收集更多高质量的作物病害相关数据;继续深入研究当前使用的数据抽取方法,不断进行优化和改进;通过引入更先进的模型和技术,提高模型对数据特征的学习能力,以更好地满足研究和应用的需求。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}