



0 引 言
随着计算机视觉技术不断发展,国内外学者在作物果实识别定位[3, 4]上取得很多新的成果。何梁等[5]将YOLO(You Only Look Once)与DeepLabV3+[6]网络相结合,实现了莲蓬与茎秆位置的精准定位。李惠鹏等[7]更换金字塔场景解析网络(Pyramid Scene Parseing Network, PSPNet)的主干网络,实现了葡萄采摘点的定位识别。李艳文等[8]提出了改进后的SegNet网络,对苹果采摘点的准确率达到了83.1%。Santos和Gebler[9]提出了一种利用空中图像序列自动检测和定位苹果园中果实的方法。Giménez-Gallego等[10]通过人工神经网络(Artificial Neural Network, ANN)模型对咖啡作物中的成熟红色果实进行分割识别,其交并比达到了81.9%。上述研究成果为茶叶嫩芽采摘点定位提供了新的思路。
在茶叶嫩芽采摘领域,国内外学者也取得了很多成果。黄家才等[11]提出了一种基于自适应标记分水岭算法的茶叶嫩芽图像分割方法,相对于传统分水岭算法提升了13.6%交并比。胡和平等[12]在YOLOv5s主干网络尾部加入卷积注意力模块(Convolutional Block Attention Module, CBAM)机制对多角度茶叶嫩芽进行分级识别,准确率达到了94.2%。Liu等[13]将可变形卷积引入茶芽检测模型中,对茶叶嫩芽的识别准确率达到了90.6%。Karunasena和Priyankara[14]提出了一种基于机器视觉的茶叶芽长度的识别方法,对于长度为0~40 mm的茶芽其总体识别准确性达到了55%。Junagade等[15]通过YOLOv5x网络在由无人机拍摄的茶叶嫩芽测试集中的识别准确率达到了89.23%,取得了较为精准的检测效果。
在茶叶嫩芽识别与定位领域,目前主要采用YOLO系列等目标检测方法,适用于快速检测小目标。然而,在采摘机械臂接近茶叶嫩芽时,茶叶嫩芽从远距离的小目标转变为近距离的大目标。在此情境下,语义分割相较于目标检测可以提供更精确的位置信息。同时为了解决语义分割模型体量大、训练时间长、场景复杂等问题,本研究提出一种改进的DeepLabV3+模型。该模型引入MobileNetV2[16]作为主干网络,结合高效通道注意力网络[17](Efficient Channel Attention Network, ECANet)与空洞空间卷积池化金字塔(Atrous Spatial Pyramid Pooling, ASPP)模块构建ECA_ASPP模块,旨在降低模型参数量并保持一定准确率,实现对名优茶的准确识别,以及采摘点的精准定位,以期为后续智能采茶机器人研发提供技术支持。
1 实验数据与网络结构
1.1 数据集构建
数据采集地点为湖南省溪清茶园,位于湖南省长沙市长沙县高桥镇,总占地面积66.7 hm2。茶园地处温暖湿润的气候区,充足的阳光和适宜的降水为茶树的生长提供了良好的条件。茶园地势起伏,其中包括平坦地区和山坡地地形,具有多样化的地势生长环境。茶园内种植大片绿茶树,以“湘波绿”和“高桥银峰”两种为主要品种。

1.2 MobileNetV2网络
MobileNetV2是一种轻量级卷积神经网络,其网络结构由不同的模块堆叠而成,具体结构见表1。其主要特点在于引入了线性瓶颈逆残差结构,其结构的主要思想为先进行升维操作再进行卷积降维并与原特征进行拼接以获得更多提取特征。MobileNetV2将拥有不同升维倍数的Bottleneck进行堆叠,这些Bottleneck模块通过深度可分离卷积和逐点卷积的组合来减少计算量和参数量,同时在每个模块中引入残差连接以增强训练稳定性。线性瓶颈结构能够避免信息在传递过程中丢失,保留更多特征信息。
表1 MobileNetV2结构表Table 1 Structure table of MobileNetV2 |
| 特征输入尺寸 | 操作类型 | Bottleneck内部升维的倍数 | 通道数/个 | Bottleneck重复的次数/次 | 步长 |
|---|---|---|---|---|---|
| 2242×3 | conv2d | ‒ | 32 | 1 | 2 |
| 1122×32 | bottleneck | 1 | 16 | 1 | 1 |
| 1122×16 | bottleneck | 6 | 24 | 2 | 2 |
| 562×24 | bottleneck | 6 | 32 | 3 | 2 |
| 282×32 | bottleneck | 6 | 64 | 4 | 2 |
| 142×64 | bottleneck | 6 | 96 | 3 | 1 |
| 142×96 | bottleneck | 6 | 160 | 3 | 2 |
| 72×160 | bottleneck | 6 | 320 | 1 | 1 |
| 72×320 | conv2d 1×1 | ‒ | 1 280 | 1 | 1 |
| 72×1 280 | avgpool 7×7 | ‒ | ‒ | 1 | ‒ |
| 1×1×1 280 | conv2d 1×1 | ‒ | m | ‒ | ‒ |
|
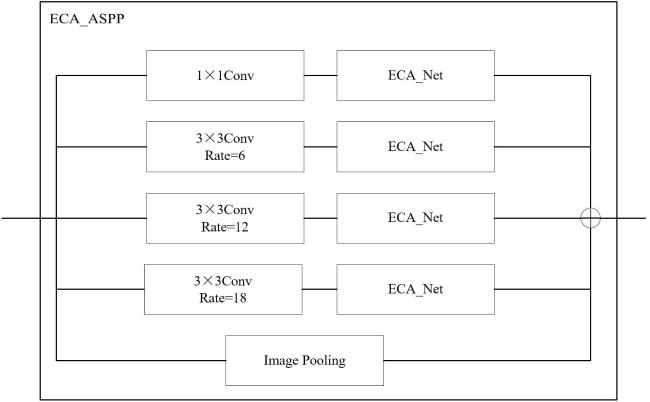
1.3 ECA_ASPP模块
ECANet是对SENet(Squeeze-and-Excitation Networks)的改进,主要是将SENet中的全连接层使用卷积层进行替代。这一改进的优点是能够在全局平均池化之后的特征上引入1D卷积进行学习。这样的设计既减少了SENet在全连接层的计算量和参数量,又避免了SENet的降维操作所带来的信息损失。
DeepLabV3+算法中的ASPP模块通过使用空洞卷积来获取更大的感受野,但在处理特征种类近似的茶叶嫩芽分割问题时,容易出现混淆和特征丢失等问题,从而导致分割效果较差。为了解决这些问题,本研究将ECANet与ASPP模块进行融合,得到ECA_ASPP模块。其改进具体表现为在ASPP模块的每个分支中添加ECANet模块。在分支中,首先通过全局平均池化层获得大小为1×1×C的特征图,然后根据公式(1) 获取内核 的大小。
式中: 表示最接近 的奇数; ; ; 为通道数。随后根据内核 执行一维卷积,对网络中的不同通道的特征权重进行调整,最后通过Sigmoid函数学习通道注意力,如公式(2) 所示。

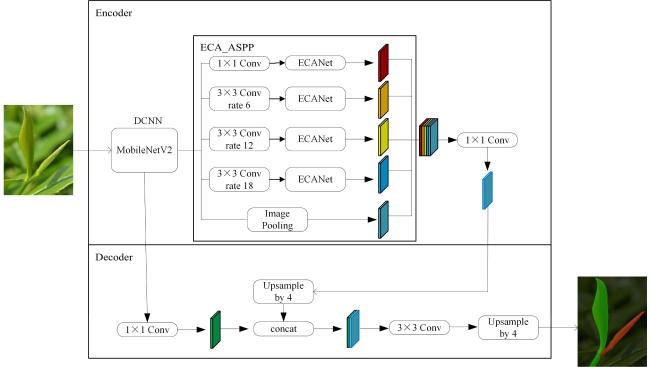
1.4 改进的DeepLabV3+网络
本研究以传统的DeepLabV3+为基础,对其进行轻量化操作以降低模型的计算量和参数量。改进方案如图4所示。采用轻量化网络MobileNetV2作为主干提取网络,将其第3层通道数为24的部分作为浅层特征输入到Decoder中,将第8层通道数为320的部分作为深层特征输入到Encoder中。深层特征输入到ECA_ASPP模块中,以增强对边缘特征的提取能力,浅层特征进行卷积操作。随后对Encoder部分的输出进行4倍上采样操作,与浅层特征通道数进行匹配,拼接并进行卷积操作,最后通过上采样操作将图像恢复至原始尺寸。
2 实验结果与分析
2.1 实验环境及评价参数
表2 实验环境配置Table 2 Experimental environment configuration |
| 实验环境项目 | 配置 |
|---|---|
| 操作系统 | Windows 11操作系统 |
| 开发语言 | Python 3.11 |
| 深度学习框架 | Pytorch 1.7.1 |
| CPU | Intel® i5-13400f@2.5 GHz |
| GPU | NVIDIA RTX3060(12 GB) |
| 内存 | DDR4 32 G 4 000 MHz |
在模型训练过程中,学习率设定为5e-4,Batch Size被设置为4,使用cos学习率下降方式,选择Adam作为模型的优化器,Epoch上限设置为400,但为防止过度拟合,当训练的损失和平均交并比多次未改善时,停止模型训练并保存模型权重。
实验中,数据集的输入尺寸被设置为512×512,神经网络的初始学习率为0.005。在模型评价过程中,采用交叉熵损失函数。对于多分类图像的标签和预测值对应的批次损失(Batch Loss),可以通过公式(3) 表示。
式中: 为批次中的样本数量; 为类别的数量; 为样本 属于类别 的标签值(1或0,表示是否属于该类别); 为观测样本 属于类别 的预测概率。通过损失函数对网络的输出结果进行评价,利用反向传播机制对网络进行优化训练,直到网络收敛。
在本研究中,精度评价方面主要采用4个关键指标,分别是交并比(Intersection over Union, IoU)、平均交并比(Mean Intersection over Union, MIoU)、像素准确率(Pixel Accuracy, PA)以及平均像素准确率(Mean Pixel Accuracy, MPA)。其中,IoU衡量了网络预测结果与实际标签结果的重合度;而MIoU表示所有类别的平均IoU值;PA指预测正确的像素数占总像素数的比例;MPA表示所有类别的像素准确率。上述指标的计算方式如公式(4)~公式(7) 所示。
式中: 表示需要识别的种类; 表示本属于 类却预测为 类的像素点总数; 表示真阳性的数量; 表示假阳性的数量; 表示假阴性的数量。
2.2 不同主干网络的精确度与计算量对比
表3 DeepLabV3+不同主干网络识别效果比Table 3 Comparison of recognition performance of different backbone networks in DeepLabV3+ |
| Backbone | MPA/% | MIoU/% | Recall/% | Parameters/M |
|---|---|---|---|---|
| Xception | 97.75 | 95.31 | 97.75 | 54.714 |
| ResNeXt | 94.14 | 90.21 | 94.14 | 103.589 |
| ResNet | 96.57 | 92.33 | 96.57 | 59.346 |
| MobileNetV2 | 97.00 | 93.01 | 97.00 | 5.818 |
表4 不同主干网络下茶叶嫩芽识别效果对比Table 4 Comparison of tea bud recognition effects under different backbone networks |
| Net | Tender_shoot | A_leaf | Two_leaves | Wrapped_bud |
|---|---|---|---|---|
| Xception | 0.93 | 0.96 | 0.91 | 0.98 |
| ResNeXt | 0.88 | 0.89 | 0.80 | 0.96 |
| ResNet | 0.90 | 0.94 | 0.84 | 0.96 |
| MobileNetV2 | 0.90 | 0.95 | 0.86 | 0.96 |
从表4可以看出,以MobileNetV2为主干网络的DeepLabV3+在茶叶嫩芽、一叶、二叶和叶包芽方面表现持平甚至部分超过以ResNet为主干网络的DeepLabV3+网络。值得注意的是,前者的参数量仅为后者的9.8%。无论在精准度还是参数量方面,MobileNetV2都取得了一定的提升。
2.3 ECA_ASPP模块对模型准确率的影响
随后,在上述数据集中进行ECA_ASPP模块的改进版DeepLabV3模型与未集成该模块的原版模型之间的性能差异实验。实验结果如表5所示。
表5 ECA_ASPP模块识别效果对比Table 5 Comparison of ECA ASPP module recognition effects |
| Net | MPA/% | MIoU/% |
|---|---|---|
| DeepLabV3+ | 97.00 | 93.01 |
| DeepLabV3+ | 97.25 | 93.71 |
表5中的数据显示,引入ECA_ASPP模块后,模型性能再次得到提升,MPA和MIoU分别提升0.26%和0.75%。这表明ECA_ASPP模块对于原版ASPP模块更加适用于茶叶嫩芽分割。
2.4 不同算法检测效果比较
为了验证改进后的DeepLabV3+对茶叶嫩芽采摘点的适用度,在训练环境与训练参数相同情况下,将改进后的DeepLabV3+网络与UNet、PSPNet和DeepLabV3+的结果进行对比,结果如表6所示。
表6 茶叶嫩芽识别研究不同网络结果对比Table 6 Comparison of different network results for tea sprout identification research |
| Net | MPA/% | MIoU/% | Recall/% | Time/s |
|---|---|---|---|---|
| UNet | 88.97 | 82.01 | 88.97 | 0.202 |
| PSPNet | 86.86 | 79.08 | 86.86 | 0.161 |
| DeepLabV3+ | 97.75 | 95.31 | 97.75 | 0.247 |
| Improved DeepLabV3+ | 97.25 | 93.71 | 96.85 | 0.165 |
从表6中数据可以看出,Improved DeepLabV3+在此数据集上表现最为出色。与UNet和PSPNet相比,Improved DeepLabV3+在MPA分别提高8.51%和10.68%;MIoU分别提升12.48%和15.61%;Recall分别提升8.13%和10.31%。与UNet相比,Improved DeepLabV3+识别速度提升0.037 s;与DeepLabV3+相比,Improved DeepLabV3+识别速度提升0.082 s。实验结果显示,Improved DeepLabV3+在名优茶嫩芽分割方面效果更佳,对茶叶嫩芽的边缘信息提取与处理能力更强,更适用于茶叶嫩芽的识别。
由图5可知,4种算法都成功提取了茶叶嫩芽的不同部位,但本研究的提取完整度要明显优于其他模型。PSPNet网络的提取结果未能完全覆盖茶叶嫩芽部分,其对茶叶嫩芽边缘的提取效果较差,不能完整有效的提取。UNet虽然对茶叶嫩芽的边缘信息较为敏感,但由于过于敏感导致在部分位置出现误判,易出现错误分割的情况。DeepLabV3+对茶叶嫩芽的准确度较高,但其识别时间较长。相比之下,改进后的DeepLabV3+网络改善了茶叶嫩芽边缘信息的获取,在保证了较高准确度的同时,又具有较快的检测速度。

2.5 不同季节检测效果对比
茶叶嫩芽的颜色状态在不同季节的变化较大。从图6中可以观察到,春季时新生的茶叶嫩芽颜色鲜艳且边缘清晰,与茶树老叶之间的颜色对比较为明显,茶叶嫩芽的分割效果较好。秋季茶树逐渐转向成熟状态,新生的茶叶嫩芽与茶树老叶的颜色相近,茶叶嫩芽分割难度增加。在图6两季茶叶嫩芽识别结果的对比中,春季茶叶嫩芽的MIoU达到93.50%,而秋季茶叶嫩芽的MIoU仅为88.54%,并且在叶包芽的分割中出现了分割缺失与错误分割。因此,茶叶嫩芽语义分割的难点主要在于秋季茶叶嫩芽的颜色变化,在茶叶嫩芽颜色与背景颜色相近的情况下,语义分割效果较差。因此,可以将YOLO与DeepLabV3+相结合从局部分割的方法出发进行进一步的研究。

2.6 茶叶嫩芽采摘点定位方法
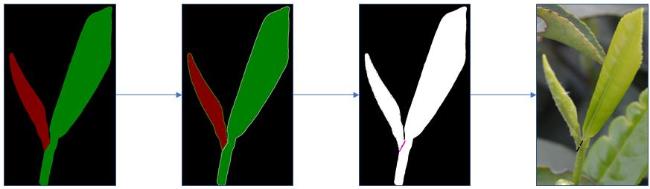
茶叶嫩芽采摘的定位主要依赖于对识别结果的颜色进行判断。具体流程如图7所示。由于RGB色彩空间是通过混合三原色获取不同颜色,其在颜色提取方面的效果较差。相比之下,HSV颜色空间通过度数描述色彩,更加清晰明了。因此,本研究将分割结果转换为HSV图片,根据不同标签颜色的范围来定义识别的标准,并创建相应的掩码。然后,对图片进行形态学操作,以消除噪声等干扰因素。随后,根据掩码进行多边形拟合,以获取嫩芽不同部位的轮廓像素点坐标。将相互连接的嫩芽部位轮廓进行欧式距离计算,得到两组距离相近的二维像素坐标点。随后,对获取的坐标点进行拟合直线操作,并确定其中心点。最后,将中心点映射回原图中,确定真正的采摘点。
3 讨论与结论
3.1 讨论
在茶叶嫩芽采摘任务中,UNet通过其编码器-解码器结构成功地减小了特征传递中的信息损失。其采用的跳跃连接方式有助于茶叶嫩芽的多尺度信息融合,在小型数据集上表现出明显优势。然而,UNet对图像输入尺寸的敏感性,以及最大池化层引入的信息丢失问题导致其在提取细节特征方面表现不完整[21]。PSPNet引入了金字塔池化模块,有效地捕捉了多尺度信息,并增强了对全局图像语境的理解,改善了分割结果。然而,由于金字塔池化模块的引入,PSPNet的模型计算量和内存占用量较大,导致相对于其他轻量级网络,PSPNet需要更多的计算时间,并且对边缘特征的提取能力较弱[22]。DeepLabV3+结合了UNet的解码器模块和ASPP模块,有效地保留了图像中的细节信息,产生更精细的分割结果。然而,由于ASPP模块和编码器模块需要较大的计算量和内存占用,使得DeepLabV3+的训练时间相对较长[23]。本研究针对以上问题,将MobileNetV2作为主干提取网络,并构建了新的ECA_ASPP结构。这一改进降低了DeepLabV3+的模型计算量和训练时间,同时提高了在茶叶嫩芽的识别中的准确性和分割效果。通过将分割结果与采摘点定位方法结合,实现了茶叶嫩芽采摘点的定位。结果表明,本研究的分割方法能够准确地定位嫩芽的位置,为后续采摘点的确定提供了可靠的基础。这一分割方法在采摘点定位识别上的有效性得到了验证,并展示了其在实际应用中的可行性和准确性。
3.2 结论
本研究通过对茶叶嫩芽采摘点识别研究中存在的问题进行深入分析,并提出了一种改进后的DeepLabV3+模型,使用自主构建的茶叶嫩芽数据集,解决传统方法中存在的模型体量大、训练时间长、场景复杂等问题。取得以下结论:
1)将DeepLabV3+的主干网络从Xception替换为MobileNetV2后,虽然在MIoU精度略有下降,但在MPA和MIoU方面分别达到97.25%和93.71%。这表明MobileNetV2作为主干网络更适合应对茶叶嫩芽分割任务,尤其在需要满足实时性要求的情境下具有优势。
2)在引入ECA_ASPP模块后,模型性能再次得到提升,表明ECA_ASPP模块对于提升模型性能具有一定效果。该结构通过加强对边缘特征的提取能力,使得模型更好地聚焦于茶叶嫩芽的语义信息,进一步提高了模型的准确性。
3)通过与其他常用的分割网络UNet和PSPNet进行对比,发现改进后的DeepLabV3+在茶叶嫩芽采摘点定位上在MPA分别提高8.51%和10.68%;MIoU分别提升12.48%和15.61%;Recall分别提升8.13%和10.31%。这进一步验证了本研究提出的改进方法的有效性和实用性。
综上所述,本研究提出的改进后的DeepLabV3+模型在茶叶嫩芽采摘点定位任务中取得了显著的性能提升,具有较高的准确性和效率。然而,本研究也存在一些局限性,如只针对特定品种的茶叶进行了实验,模型在多品种茶叶嫩芽数据集上的泛化能力有待进一步验证。未来,可以进一步优化模型结构,提高模型的泛化能力,并探索更多适用于茶叶采摘点定位的机器视觉技术。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}