



0 引 言
为降低标注成本并提高计数准确率,有研究者尝试采用密度回归的方式研究苗木计数。密度回归只需对目标的中心点进行标注,通过与高斯核卷积转换为密度图,再对密度图进行空间求和,即可实现目标计数[10]。近年来,密度回归已广泛应用于水稻[11]、玉米[12]、麦穗[13]等目标的计数。然而,将点标签数据转换成粗糙的密度图,会对计数结果的准确性造成影响[14]。此外,密度回归模型只能估计目标的数量和近似分布,相较于基于目标检测的方法,具有更高的精度但无法获取目标的尺寸信息[15]。为了集成基于密度回归方法中点标签的低成本标注方式,以及基于目标检测方法中能够获取目标位置和大小的优点,Bai等[16]提出一种新的深度学习网络RiceNet,通过植物位置检测器和植物大小估计器模块提供植物位置和大小信息,为下游作物表型研究提供参考,但该模型无法适用于检测分布不均的目标。Sam等[17]提出密集检测计数网络(Locate, Size And Count, LSC-CNN)用于研究密集人群的数量、位置和头部大小信息,在密集场景下模型的各方面效果明显优于RiceNet。
为在准确统计苗木数量的同时获取位置和大小信息,本研究以在密集苗木数据集上表现较好的LSC-CNN模型为基础模型。针对密集苗木图像中苗木粘连边界难以区分、目标尺度差异大的特点改进LSC-CNN模型。通过将LSC-CNN模型特征提取网络最后一层的普通卷积替换为扩张卷积(Dilated Convolutions, DConv),以提升模型感受野;并在每个尺度分支前引入注意力机制(Convolutional Block Attention Module, CBAM)提高模型的上下文信息提取能力,帮助网络更好地理解和关注苗木的细节信息,以提升模型对苗木数量的准确估计能力。此外,将损失函数替换为标签平滑交叉熵损失函数,提高模型泛化能力。
1 数据集构建
1.1 数据获取
本研究在公开苗木数据集Yosemite[18]和KCL-London[19]的基础上,结合现场使用大疆精灵4无人机采集的云杉图像数据,构建了本研究的苗木检测和计数数据集。其中,Yosemite数据集采集自美国加利福尼亚州的约塞米蒂国家公园,图像像素大小为19 200×38 400,图像内总共包含98 949株苗木。通过将裁剪后的图像进行数据清洗,筛选出高质量图像593幅,如图1a所示。KCL-London数据集是收集自谷歌地图中伦敦地区的高分辨率树木图像,其每个像素对应于地面上0.2 m×0.2 m的区域。该数据集中共有613幅已标记图像,包含95 067株苗木。挑选苗木密集粘连覆盖区域图像共447张,平均每幅图像包含苗木177株,如图1b所示。

云杉图像数据采自内蒙古苗圃育种实验基地(111º49´47″E,40º31´47″N),海拔高度为1 134 m。基地内主要种植云杉、油松和樟子松等多种苗木,其中云杉育种区域占地面积约75 313 。选择地形相对平坦的云杉种植地域作为研究区域,培育的云杉株龄在4~30年不等,种植行间距约为1.5 m,株距约为1 m。为提升数据多样性,采用大疆精灵4无人机分别于5∶30~7∶30、9∶00~10∶00和17∶00~18∶00三个不同时间段采集云杉图像。无人机搭载像素2 000万相机,镜头焦距20 mm,像元尺寸2.4 um,镜头成像角度为-90°~30°,采集图像分辨率像素为4 000×3 000,无人机在60~100 m飞行高度下按照“S”型路线飞行,以定点悬停方式采集云杉图像,如图1c所示。
1.2 数据集构建
根据多样性原则挑选采集的云杉图像共480幅,每幅图像平均包含云杉947株。针对数据集云杉密集、数量较多、目标较小的特点,考虑到标注成本,通过MATLAB对云杉树冠中心点进行点标注。公开数据集Yosemite和KCL-London均对苗木中心点进行了标记,共获取密集苗木图像1 520幅,按照7∶3的比例划分训练集和测试集,训练集包含图像1 064幅,测试集包含图像456幅。
考虑光照条件、无人机飞行高度和苗木自身生长因素等问题影响,将训练集图像采用调整对比度和变换图像大小的方法进行数据增强,进而提升模型对于不同尺度苗木个体和光照条件变化的适应能力。分别通过在[0.3,1.7]和[0.5,1.5]区间内随机生成对比度系数和缩放比例,对原始训练集苗木图像进行数据增强,得到扩充后的训练集图像3 192幅。
2 研究方法
2.1 改进LSC-CNN网络模型
采用点监督学习的LSC-CNN模型能够同时实现目标的检测和计数,在密集苗木数据集上展现出优异的性能,因此选择LSC-CNN模型作为本研究的基础模型。LSC-CNN模型采用端到端结构,通过自顶向下的特征调制器网络融合多尺度特征,采用赢家通吃 (Grid Winners-Take-All, GWTA)策略反向传播。然而,在实际测试中发现LSC-CNN模型存在部分误检现象,并且在部分区域出现大量漏检的现象。分析发现,这与无人机航拍图像中苗木密集、粘连,且数个苗木边界重叠难以有效区分苗木个体有关。由于无人机飞行高度的变化,密集苗木图像中苗木存在个体差异,导致模型对于不同高度的苗木图像数量统计存在误差。此外,不同数据集的苗木数量和尺寸等存在较大差异,尤其数据集中云杉数量较多,进而出现了类别不平衡问题。为解决上述问题,本研究改进了LSC-CNN模型,将LSC-CNN模型特征提取网络中最后一层卷积层替换为扩张卷积,在不损失分辨率和覆盖率的基础上提升模型感受野,帮助网络更好地理解图像中的全局信息。同时,在不同尺度特征网络中加入CBAM模块以增强局部和全局信息捕获能力,帮助网络更加关注苗木关键特征。此外,将LSC-CNN模型中的交叉熵损失函数替换为标签平滑交叉熵损失函数,使模型适用于多种苗木计数任务,改进后的LSC-CNN模型结构如图2所示。
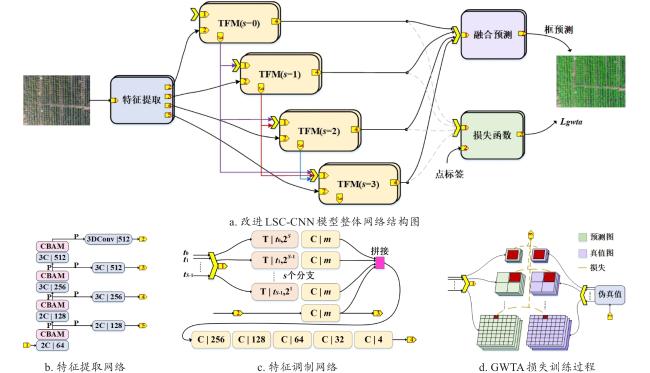
2.1.1 改进LSC-CNN网络结构
改进LSC-CNN网络由主干网络VGG16 (Visual Geometry Group 16)、自顶向下的特征调制网络和融合预测网络构成,如图2a所示。改进LSC-CNN网络通过VGG16网络进行苗木特征提取,将VGG16最后一层的普通卷积替换为扩张卷积。再分别以输入分辨率的1/2,1/4,1/8和1/16尺寸创建特征图,并在每个分支中引入CBAM注意力机制,如图2b所示。不同分辨率的特征图作为对应尺度分支的输入,分别经过一组自顶向下的特征调制器模块(Top-Down Feature Modulation, TFM),通过接收低尺度的信息来评估全局上下文。如图2c所示,每个TFM的端口1接收来自不同尺度的特征,通过转置卷积进行上采样。端口2的输入取自于特征提取网络对应的尺度特征分支,通过若干3×3的卷积层,一方面作为端口3的输出为下一个TFM提供自顶向下特性,另一方面和来自端口1的不同尺度特征进行拼接。最终通过端口4输出检测到的头部预定义框或背景,通过非极大值抑制(Non-Maximum Suppression, NMS)从多个尺度分支中选择合理的预测,从而得到检测结果。
2.1.2 CBAM机制
由于无人机飞行高度和拍摄角度以及苗木自身生长因素的影响,无人机航拍的密集苗木图像尺度差异较大,苗木个体之间边界重叠难以明确区分,严重影响苗木的检测和计数。为了准确区分和定位苗木个体,使模型在识别苗木时将注意力聚焦于苗木的关键特征,本研究在LSC-CNN的主干网络中引入CBAM注意力模块。其包含通道注意力模块(Channel Attention Module, CAM)和空间注意力模块(Spatial Attention Module, SAM),如图3所示。
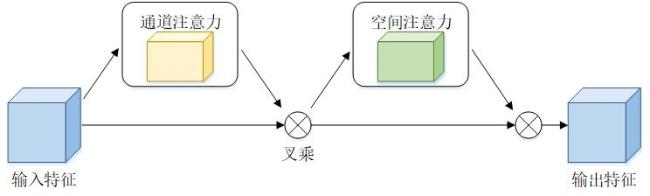
通道注意力模块沿通道方向捕获特征图的全局信息,通过为每个通道分配不同的权重,调整对不同通道特征的关注度,有效提取苗木的轮廓特征,获取苗木目标的重要特征,过滤无关特征的干扰。将优化后的特征图输入空间注意力模块进一步细化,使模型聚焦于特征图中苗木的位置信息,提升特征区分度以辨别重叠的苗木。两种注意力机制的结合使得CBAM能够在不同尺度和空间位置上对苗木的重要特征信息进行增强,从而增强模型对粘连苗木的检测[20]。CBAM注意力机制在解决密集麻鸭[21]和植物叶片[22]的重叠问题上,都起到了关键性的作用,模型检测精度得到有效提升,故本研究引入CBAM注意力机制。为了多尺度分支保留更多的苗木特征信息,本研究将CBAM模块分别置于VGG16前4个卷积层之后,如图2b所示。
2.1.3 扩张卷积
LSC-CNN网络随着卷积层数的增加,特征图的空间分辨率下降,致使高层次特征提取层丧失苗木部分细节和特征信息。密集苗木目标较小,若丢失了部分全局信息,对其特征的损失将更为显著,密集粘连的小目标在低分辨率特征图上可能会被模糊成一株苗木。而扩张卷积能够在不损失分辨率和覆盖率的基础上提升模型感受野,有效处理大范围特征,减少特征信息的丢失,增强对不同大小目标的检测能力。密集苗木数据集采集自不同复杂场景,苗木分布较广、目标尺寸差异大,故引入扩张卷积替换模型原有卷积以提高模型分辨能力。扩张卷积通过在卷积核内引入固定间隔的零值,扩大卷积核的感受野,其中间隔大小由膨胀系数r决定。对于大小为k×k的卷积核,通过扩张卷积后其大小 如公式(1) 所示。
当膨胀系数为1时,扩张卷积等同于常规卷积,感受野为3×3;当膨胀系数为2时,能获得5×5的感受野,如图4所示。

2.2 损失函数
在苗木检测和计数数据集中,云杉的样本数量相对较多,造成了类别不平衡的问题。交叉熵损失对类别不平衡非常敏感,容易偏向于预测多数类别,并存在极端自信问题。为了解决苗木类别不平衡的问题,提高模型泛化能力,采用标签平滑交叉熵损失训练模型,单个像素的交叉熵损失定义如公式(2) 所示。
式中: 是总类别数量; 是模型预测第 个类别的概率; 是真实标签的类别; 和 分别表示类别概率 和真实标签 的集合; 是用来平衡训练的权重。标签在平滑后的概率分布如公式(3) 所示。
式中: 为平滑参数,试验中设置为0.08;y表示真实类别的标签索引。
2.3 评价指标
式中:N为测试集苗木图像数量,株; 为第i幅图像中苗木的真实数量,株; 为模型预测的第i幅图像中苗木数量,株。
2.4 试验设置
本研究的苗木计数算法和试验均在Ubuntu20.04 LTS操作系统上实现,硬件环境为Intel Xeon Gold 5220R,NVIDIA RTX 3090,16 GB运行内存,1 TB固态硬盘和16 TB机械硬盘。软件环境为Python 3.8.16和Pytorch 1.12.1。改进LSC-CNN模型的训练次数为50,图像切块数设置为100,学习率为0.001,批处理量大小为8,动量为0.9,采用随机梯度下降(Stohastic Gradient Descent, SGD)算法优化训练模型,如图5所示。
3 结果与分析
3.1 消融试验
本研究在LSC-CNN模型基础上,将VGG16最后一层的普通卷积替换为膨胀率为2的扩张卷积,并在VGG16的前四个卷积层后引入CBAM注意力机制。此外,用标签平滑交叉熵损失函数替换原有交叉熵损失函数。为证明改进LSC-CNN能够具有更好的性能,采用MAE、RMSE和MCA三种评价指标进行定量评价,给定阈值为0.16,通过5组消融试验验证改进算法的性能,试验结果如表1所示。
表1 改进LSC-CNN模型苗木检测计数消融试验结果Table 1 Ablation experiment results of nursery stock detection and counting based on the improved LSC-CNN model |
| 试验 编号 | DConv | LSCE Loss | CBAM | MAE | RMSE | MCA/% |
|---|---|---|---|---|---|---|
| 1 | × | × | × | 24.50 | 34.37 | 88.89 |
| 2 | √ | × | × | 20.93 | 28.53 | 90.34 |
| 3 | × | √ | × | 21.94 | 30.13 | 89.15 |
| 4 | × | × | √ | 18.19 | 25.07 | 90.70 |
| 5 | √ | √ | √ | 14.24 | 22.22 | 91.23 |
|
据表1结果,基础模型LSC-CNN的MAE为24.50株,RMSE为34.37株,MCA为88.89%。将VGG16最后一个卷积层的常规卷积替换为扩张卷积后,相较于原始网络,模型MAE下降了3.57株,RMSE降低了5.84株,MCA提升了1.45%。结果表明,将常规卷积替换为扩张卷积提升卷积感受野后,模型能够保留更多苗木细节特征,有效解决了密集苗木粘连造成的漏检问题,从而提高模型性能。将交叉熵损失函数替换为标签平滑交叉熵损失函数后,模型MAE下降了2.56株,RMSE降低了4.24株,MCA提升了0.26%。分别在1/2,1/4,1/8和1/16尺寸特征分支前加入CBAM注意力机制后,相较于原始网络,模型MAE下降了6.31株,RMSE降低了9.30株,MCA提升了1.81%。根据试验结果来看,模型引入CBAM注意力机制后,模型对苗木关键特征的关注度得到有效提升,能够更好地应用于不同尺度的苗木,模型MCA得到提升。
同时引入CBAM注意力机制、扩张卷积和标签平滑交叉熵损失函数后,模型效果达到最好,在各方面都优于原始模型和加入单一模块的模型。相较于原始网络,MAE减少了10.26株,RMSE降低了12.15株,模型MCA提升了2.34%。为验证改进的LSC-CNN模型是否能够有效检测和计数密集场景下的苗木,以测试集中的456张苗木图像为试验数据,对改进LSC-CNN模型进行测试。改进后的模型MAE为14.24株,RMSE为22.22株,MCA为91.23%。
3.2 不同模型检测性能对比试验
为验证改进LSC-CNN模型对密集种植苗木的检测和计数性能,选用基于密度图回归的玉米计数网络IntegrateNet[23];遥感图像密集目标计数网络(Pyramidal Scale and Global Context Guided Network, PSGCNet)[24];在密集目标计数中表现性能较好的密度回归网络(Context Aware Crowd Counting, CANet[25]);拥挤场景下表现良好的计数网络(Congested Scene Recognition Network, CSRNet)[26];能够获取目标位置的回归计数网络(Crowd Location Detection Transformer, CLTR[27]);密集检测模型LSC-CNN和改进LSC-CNN模型对测试集456幅苗木图像进行试验。所有模型采用相同的点标签苗木数据集,在同一试验平台上训练。按照数据集中苗木数据量分布,分别选取测试图像中包含苗木数量870、1 372和1 625株的测试图像进行展示,试验情况和结果如图6所示。
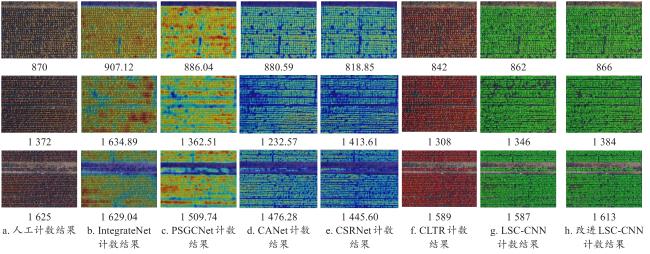
IntegrateNet模型在测试的三幅图像中全部出现了高估的现象,这是由于模型将密集场景下粘连遮挡的苗木视为多个目标导致的。PSGCNet和CANet模型在第一幅测试图像中预测结果出现高估的现象,在第二、三幅图像中出现低估的现象,模型对于密集苗木的识别能力较弱。CSRNet模型对苗木分布不均的处理能力较弱,第三幅图像中苗木数量最多,计数准确率较前两幅图像明显降低。由于密集苗木目标较小,在定位过程中较小的位置偏移会造成较大的误差。CLTR模型在预测过程中出现了不同程度的低估,虽然该模型能够定位单个苗木的位置,但位置偏差较大无法准确判断造成苗木计数结果低估的具体原因。
本研究选取的LSC-CNN模型的预测结果较为贴近人工标注真值,但在第二幅图像上半部分处LSC-CNN模型出现大量漏检,导致计数结果明显低于实际结果。从改进LSC-CNN模型的预测结果来看,苗木计数准确率得到有效提升,模型计数误差明显降低。第一幅图像人工标注真值为870株,改进LSC-CNN模型统计结果为866株,复杂的野外背景会对苗木的检测造成影响。第二幅图像中苗木数量为1 372株,改进LSC-CNN模型预测结果为1 384株,略高于实际值,模型对于边界不完整苗木也具有较好的识别性能。第三幅图像人工标注真值为1 625株,改进LSC-CNN模型统计结果为1 613株,预测结果略低于真实结果,经分析认为这是由于密集苗木图像中苗木分布不均导致的。根据对比试验可视化结果来看,针对无人机航拍的点标注密集苗木图像,改进LSC-CNN模型的预测结果最接近人工标注结果,有效解决了密集苗木尺度差异大、粘连难以区分苗木个体的问题,在计数准确度上明显优于IntegrateNet、PSGCNet、CANet、CSRNet、CLTR和LSC-CNN模型。
以MAE、RMSE和MCA为评价指标,对上述模型试验结果进行定量分析,结果如表2所示。就MCA来说,改进LSC-CNN模型达到了91.23%,相较于IntegrateNet、PSGCNet、CANet、CSRNet、CLTR和LSC-CNN模型分别提升了6.67%、2.33%、6.81%、5.31%、2.09%和2.34%。改进LSC-CNN模型的MAE和RMSE分别为14.24和22.22株,相比IntegrateNet、PSGCNet、CANet、CSRNet、CLTR和LSC-CNN模型的MAE降低了21.19、11.54、18.92、13.28、11.30和10.26株,RMSE降低了28.22、28.63、26.63、14.18、24.38和12.15株。结果表明,改进LSC-CNN模型在MAE、RMSE和MCA方面明显优于其他模型。
表2 改进LSC-CNN苗木检测计数对比试验定量分析结果Tabel2 Quantitative analysis of comparative experiments for the improved LSC-CNN |
| 模型 | MAE/株 | RMSE/株 | MCA/% |
|---|---|---|---|
| IntegrateNet | 35.43 | 50.44 | 84.56 |
| PSGCNet | 25.78 | 50.85 | 88.90 |
| CANet | 33.16 | 48.85 | 84.42 |
| CSRNet | 27.52 | 36.40 | 85.92 |
| CLTR | 25.54 | 46.60 | 89.14 |
| LSC-CNN | 24.50 | 34.37 | 88.89 |
| 改进LSC-CNN | 14.24 | 22.22 | 91.23 |
综上所述,本研究提出的改进LSC-CNN模型不仅能够通过点监督学习实现苗木检测和计数,而且能够根据检测结果明确分析苗木计数情况,各方面指标均优于回归模型。
3.3 模型实际检测结果
为验证改进的LSC-CNN模型是否能够有效检测和计数密集场景下的苗木,以测试集中的456幅苗木图像为试验数据,对改进LSC-CNN模型进行测试。改进后的模型MAE为14.24株,RMSE为22.22株,MCA为91.23%,图7为改进LSC-CNN模型对于点标签苗木数据的检测和计数结果。

图7表明,第一组苗木图像中苗木数量较多、粘连严重,苗木MCA为99.01%。第二组苗木图像中苗木受光照强度、环境因素影响边界模糊,模型能够有效分割粘连苗木,苗木MCA为97.43%。第三组苗木图像中环境复杂,苗木分布不均、粘连遮挡,苗木MCA为94.50%。根据检测结果来看,改进LSC-CNN模型能够准确检测和计数不同尺寸的密集苗木,对于不同复杂背景均有较好的适用性。
LSC-CNN模型通过点标注数据进行训练,在实现苗木计数的同时,能够获取苗木的位置和大小。为了检验模型的检测效果,从测试集中随机挑选了91幅苗木图像进行框标注,并使用目标检测领域常用评价指标精确率P、召回率R和 分数,对密集苗木图像的检测情况进行研究。统计结果如表3所示。
表3 改进LSC-CNN模型云杉苗木检测结果统计Tabel3 Statistical analysis of detection results for the improved LSC-CNN model of spruce seedlings detection and counting |
| 网络模型 | 平均检测数/株 | 平均漏检数/株 | 评价指标 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 云杉 | Yosemite | KCL-London | 云杉 | Yosemite | KCL-London | 漏检率/% | 精确率P/% | 召回率R/% | 分数/% | |
| LSC-CNN | 862 | 199 | 220 | 44 | 30 | 38 | 11.66 | 93.08 | 88.34 | 90.61 |
| 改进LSC-CNN | 868 | 206 | 237 | 37 | 16 | 19 | 6.56 | 94.88 | 93.44 | 94.15 |
由表3可知,针对不同采集环境下的苗木,改进LSC-CNN模型的漏检数量明显减少,漏检率为6.56%,比原LSC-CNN模型降低了5.10%。此外,改进LSC-CNN 模型在精确率P、召回率R和 分数上也有所提升,相较于原始模型分别提高了1.8%、5.10%和3.54%。由此可以看出,通过将扩张卷积替换为普通卷积,并在不同尺度特征网络中引入CBAM模块,有助于改进LSC-CNN网络更加关注苗木关键特征,区分粘连的苗木个体,有效减少对密集苗木的漏检数量,提高苗木计数准确性。
4 结 论
本研究以无人机航拍密集苗木图像为研究对象,针对不同高度拍摄下图像存在的苗木密集、粘连的问题,提出改进LSC-CNN模型,实现无人机航拍的密集苗木检测和计数。为了提高模型计数准确率,首先将LSC-CNN模型特征提取网络最后一层的普通卷积替换为扩张卷积,扩大网络的感受野,保留更多的苗木特征信息。同时,在特征提取网络的多个尺度分支前引入CBAM注意力机制,将模型注意力聚焦于苗木关键特征,帮助模型检测出粘连的苗木。在训练阶段,采用标签平滑交叉熵损失函数通过GWTA策略关注造成损失最大的区域更好地学习苗木特征。试验结论如下:
1)本研究提出的改进LSC-CNN模型能够有效解决LSC-CNN模型存在的漏检问题,提升了无人机航拍密集苗木图像中苗木计数准确率。在456幅测试集图像上试验,改进LSC-CNN模型的MAE为14.24株,RMSE为22.22株,MCA为91.23%。改进LSC-CNN模型有效解决了密集苗木粘连、尺度差异大的问题,准确实现了密集苗木检测和计数。
2)将IntegrateNet、PSGCNet、CANet、CSRNet、CLTR、LSC-CNN模型和改进LSC-CNN模型作对比试验,从MAE、RMSE和MCA三个方面来看,本研究改进的LSC-CNN模型的性能均优于其他模型。改进的LSC-CNN模型集成了基于密度回归方法中点监督学习和基于检测方法中生成目标框的优点,相较于IntegrateNet、PSGCNet、CANet、CSRNet、CLTR和LSC-CNN模型MAE降低了21.19、11.54、18.92、13.28、11.30和10.26株,RMSE降低了28.22、28.63、26.63、14.18、24.38和12.15株,MCA提升了6.67%、2.33%、6.81%、5.31%、2.09%和2.34%。
3)本研究通过点监督学习实现苗木目标的检测,不仅降低标注成本,还能够达到与目标检测任务相同的结果,为下游作物表型研究提供更多参考信息。然而,本研究改进的LSC-CNN模型检测的苗木位置和大小仍存在略微偏移,在后续的研究中,可以进一步改进,以适用于更多的应用场景。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}