



0 引 言
1 图像采集与数据集的建立
表1 草莓病害领域泛化数据集的详细信息Table 1 Details of domain generalization dataset for strawberry disease recognition |
| 类别标签 | 病害类别 | DGSR1数量/幅 | DGSR2数量/幅 | 合计/幅 |
|---|---|---|---|---|
| 0 | 细菌性叶斑病 | 509 | 435 | 944 |
| 1 | 炭疽病(果实) | 121 | 97 | 218 |
| 2 | 灰霉病(果实) | 396 | 477 | 873 |
| 3 | 蛇眼病 | 312 | 615 | 927 |
| 4 | 白粉病(果实) | 145 | 135 | 280 |
| 5 | 白粉病(叶子) | 407 | 533 | 940 |
| 共计 | 6类 | 1 890 | 2 292 | 4 182 |

2 基于实例白化与特征恢复的草莓病害识别领域泛化方法
2.1 实例白化与特征恢复模块
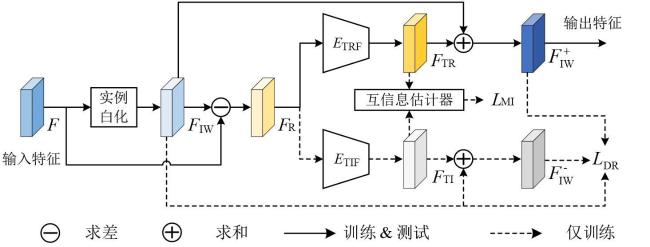
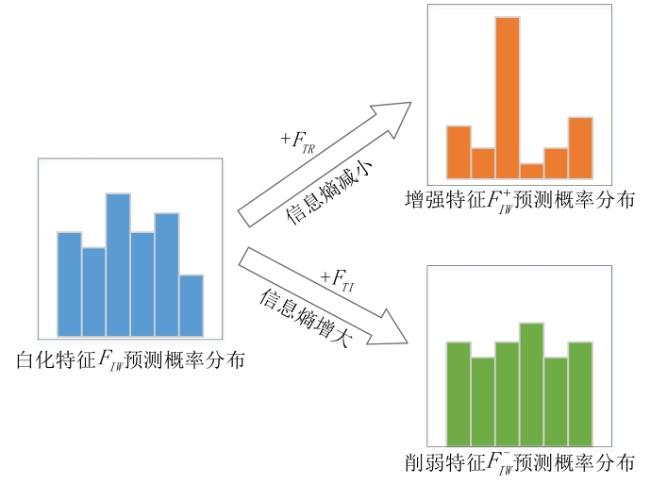
2.2 IW去除风格特征
2.3 特征恢复保留任务相关特征
表2 任务相关特征提取器 和任务无关特征提取器 详细信息Table 2 Implementation details of and |
| 提取任务相关特征 | 提取任务无关特征 | |
| Conv 5×5×128, stride=1, padding 2 | Conv 3×3×128, stride=1, padding 1 | |
| Instance Normalization, ReLU | Instance Normalization, ReLU | |
| Conv 5×5×128, stride=1, padding 2 | Conv 3×3×128, stride=1, padding 1 | |
| Instance Normalization, ReLU | Instance Normalization, ReLU | |
| Conv 5×5×128, stride=1, padding 2 | Conv 3×3×128, stride=1, padding 1 | |
| Instance Normalization, Sigmoid | Instance Normalization, Sigmoid |
2.4 损失函数
表3 互信息估计器 的详细信息Table 3 Implementation details of mutual information estimator |
| 互信息估计器 |
|---|
| FC1 128×128, FC2 128×128 |
| FC3 128×1 |
2.5 优化策略
表4 IWR模型训练流程Table 4 Training process of IWR |
| 算法 1 分离优化算法 | ||
|---|---|---|
| Input:输入样本集(X,Y);骨干网络 ;任务相关特征提取器 ;任务相关特征提取器 ;互信息估计器 | ||
| Output:骨干网络 ;任务相关特征提取器 ;任务相关特征提取器 ;互信息估计器 | ||
| 1 | While 模型不收敛 do | |
| 2 | 从(X,Y)选取一批样本; | |
| 3 | 特征类别区分度优化: | |
| 4 | 固定互信息估计器 参数; | |
| 5 | 计算损失 ; | |
| 6 | 通过 更新 、 、 ; | |
| 7 | 特征独立性优化: | |
| 8 | 固定骨干网络 参数; | |
| 9 | 计算损失 ; | |
| 10 | 通过 更新 、 、 ; | |
| 11 | End | |
| 12 | return ; ; ; | |
2.6 实验环境与评价指标
2.6.1 实验设置与环境
2.6.2 评价指标
3 结果与分析
3.1 消融实验
3.1.1 不同特征分离方法
表5 不同特征分离方法领域泛化性能比较Table 5 Comparison results of domain generalization performance of different style normalization methods |
| 方法 | F 1-Score/% | |
|---|---|---|
| DGSR1 DGSR2 | DGSR2 DGSR1 | |
| 67.75 | 66.62 | |
| 68.32 | 67.89 | |
| 68.01 | 66.63 | |
| 68.64 | 68.12 | |
| 69.46 | 68.97 | |
3.1.2 双段恢复损失的有效性
表 6 双段恢复损失的消融实验结果Table 6 Results of ablation experiment on dual restitution loss |
| 方法 | F 1-Score/% | |
|---|---|---|
| DGSR1 DGSR2 | DGSR2 DGSR1 | |
| ResNet-50 | 66.65 | 65.15 |
| IWR w/o | 66.81 | 65.53 |
| IWR w/o | 68.63 | 68.27 |
| IWR w/o | 67.96 | 66.92 |
| IWR | 69.46 | 68.97 |
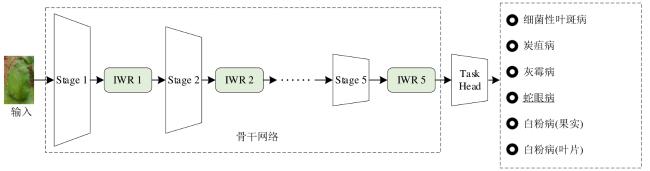
3.1.3 不同Stage加入IWR
表7 不同Stage加入IWR对Resnet泛化性能影响Table 7 Generalization performance of adding IWR to different stages of ResNet |
| 方法 | F 1-Score/% | |
|---|---|---|
| DGSR1 DGSR2 | DGSR2 DGSR1 | |
| Stage 1 | 67.54 | 65.81 |
| Stage 2 | 67.75 | 66.35 |
| Stage 3 | 67.91 | 66.76 |
| Stage 4 | 68.19 | 67.48 |
| Stage 5 | 68.72 | 68.39 |
| IWR (All Stage) | 69.46 | 68.97 |
3.2 模型性能对比
3.2.1 对不同病害识别模型领域泛化性能提升
表8 IWR对不同网络领域泛化性能提升效果对比Table 8 Comparison results of IWR domain generalization performance improvement for different networks |
| 方法 | F 1-Score/% | |||
|---|---|---|---|---|
| DGSR1 DGSR2 | DGSR2 DGSR1 | |||
| DGSR1 | DGSR2 | DGSR2 | DGSR1 | |
| AlexNet | 90.90 | 62.12 | 95.39 | 62.25 |
| AlexNet-IWR | 91.96 | 66.09 | 95.48 | 65.04 |
| GoogLeNet | 92.44 | 62.87 | 95.62 | 63.44 |
| GoogLeNet-IWR | 92.86 | 67.45 | 95.69 | 65.81 |
| ResNet-18 | 92.91 | 64.80 | 96.85 | 64.06 |
| ResNet-18-IWR | 92.99 | 67.99 | 96.82 | 66.79 |
| ResNet-50 | 93.90 | 66.65 | 97.33 | 65.15 |
| ResNet-50-IWR | 94.21 | 69.46 | 97.30 | 68.97 |
| MobileNetV2 | 93.47 | 66.76 | 97.29 | 62.55 |
| MobileNetV2-IWR | 93.74 | 68.35 | 97.38 | 65.31 |
| MobileNetV3 | 91.84 | 62.92 | 96.01 | 60.67 |
| MobileNetV3-IWR | 92.65 | 66.43 | 96.15 | 63.89 |
3.2.2 与其他泛化方法比较结果
表9 不同风格归一化方法领域泛化性能比较Table 9 Comparison results of IWR domain generalization performance improvement for different networks |
| 骨干网络 | 方法 | DGSR1 DGSR2 | DGSR2 DGSR1 | ||||
|---|---|---|---|---|---|---|---|
| 平均值/% | 标准差/% | 95%置信区间/% | 平均值/% | 标准差/% | 95%置信区间/% | ||
| ResNet-50 | 原模型 | 66.65 | 1.74 | 65.12~68.18 | 65.15 | 1.98 | 63.41~66.89 |
| IBNNet | 67.72 | 1.69 | 66.24~69.20 | 66.34 | 1.83 | 64.74~67.94 | |
| SW | 67.41 | 1.65 | 65.96~68.85 | 66.62 | 1.87 | 64.98~68.26 | |
| SNR | 68.62 | 1.54 | 67.27~69.97 | 67.83 | 1.72 | 66.32~69.34 | |
| IWR | 69.46 | 1.50 | 68.15~70.77 | 68.97 | 1.66 | 67.51~70.43 | |
3.3 特征差异分析
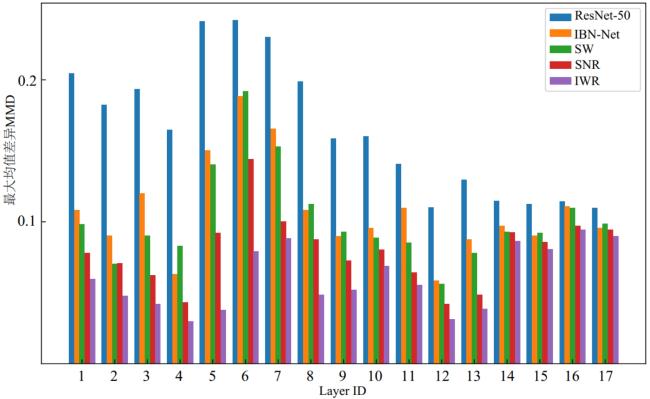
3.4 特征图可视化

3.5 复杂度分析
表 10 ResNet加入IWR前后模型复杂度和参数量对比Table 10 Comparison of complexity and model size before and after IWR added in ResNet |
| 模型 | 参数量/ M | 计算量(FLOPs)/G |
|---|---|---|
| ResNet-18 | 11.18 | 1.82 |
| ResNet-18-IWR | 14.04 | 7.93 |
| ResNet-50 | 23.52 | 4.13 |
| ResNet-50-IWR | 30.07 | 16.02 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}