



0 引 言
在全球人口快速增长和资源日益紧张的背景下,农业生产正面临着空前的挑战。联合国粮农组织(Food and Agriculture Organization of the United Nations, FAO)预测,到2050年,全球粮食需求将增长近70%,这对农作物的产量和资源利用效率提出了更高的要求[1]。同时,气候变化导致的环境不确定性加剧了农作物产量的波动,使得可持续的农业生产模式变得尤为重要[2]。在此背景下,精准农业逐渐成为应对全球农业挑战的关键技术。精准农业依托于传感器、遥感技术、物联网、大数据等先进科技手段,实现对土壤、水分、气候等农业生产要素的精准监控和实时管理,以提高生产效率、减少资源浪费和环境影响[3]。然而,现有的精准农业方法更多关注大规模农业生产,采用统一的管理模式,忽视了小规模农户和不同地区的个性化需求。对于作物生产,个性化的管理策略尤为重要[4]。作物种类繁多,不同种类对气候、水肥条件的需求差异巨大,且各地区的农户在生产目标上也存在显著差异[5, 6]。例如,一些农户更注重作物产量的最大化,而另一些则可能优先考虑降低人力资源或水肥消耗,以实现可持续发展目标[7]。此外,随着消费者对健康、绿色食品的需求增加,农户对作物质量的要求也变得更加多样化。因此,在精准农业的框架下,如何根据农户的具体需求和偏好,提供个性化的作物管理策略,已成为提高农业生产效率和实现可持续发展的关键问题[8]。
现有的作物种植专家系统多依赖于传感器数据、模型驱动预测,以及基于规则的决策支持,这些技术已在大田作物管理中取得了一定的成效[9]。例如,利用土壤湿度传感器和气象数据动态调节灌溉方案,或采用无人机和遥感技术进行病虫害监测等。然而,现有系统存在诸多局限性。首先,大多采用通用的管理模式,忽视了不同农户在作物产量、资源消耗、经济效益等方面的差异化需求[10, 11],难以针对农户的具体目标(如优先降低资源消耗或提高作物质量)进行动态调整[12];其次,传统系统多通过预定义的规则或参数配置进行操作,缺乏有效的自然语言交互能力,难以精准捕捉农户的多样化需求[13];此外,由于这些系统主要依赖于大量的历史数据,缺乏有效的人机交互手段,农户难以通过自然语言表达其需求,无法及时应对外部环境的变化或用户需求的调整[14, 15]。这些局限性限制了现有作物管理系统在实际应用中的推广和效能提升。
为了实现个性化作物管理,研究者们开发了多种模型和算法,以帮助农业生产者做出更精准的决策。例如,基于Pareto多目标优化模型的农作物最优种植策略,可以在考虑作物产量、经济效益和环境影响等多个目标的同时,为农业生产提供优化的种植方案[16]。此外,机器学习技术也被广泛应用于作物管理中,通过分析大量的农业数据,为农民和农业企业提供科学、精准的决策支持,从而提高作物产量和质量,降低生产成本[17]。然而,个性化作物管理的实施面临着数据获取和处理的挑战。需要大量的田间实验数据、气候数据、土壤数据和市场数据等来训练模型和优化算法。此外,如何将这些模型和算法与实际的农业生产流程相结合,也是研究者们需要解决的问题。为了克服这些挑战,研究人员正在探索如何利用人工智能和大数据技术来提高数据处理的效率和准确性,以及如何通过智能化的决策支持系统来辅助农业生产者做出更好的管理决策[18]。
随着人工智能技术的发展,大语言模型(Large Language Model, LLM)在理解和生成自然语言方面展现出巨大潜力,为个性化作物管理提供了新的解决方案[19]。LLM能够通过自然语言处理技术与用户进行有效沟通,准确捕捉用户在蔬菜生产中的多样化需求,并将这些需求转化为作物管理策略的决策参数[20,21]。这种能力使得LLM不仅能够处理复杂的文本信息,还能够通过学习大量的农业知识库和用户交互历史,推理出用户对蔬菜作物管理的偏好,并实时动态调整管理策略。与传统基于规则和静态模型的系统不同,LLM可以通过持续学习和优化,灵活应对用户的需求变化与外部环境的不确定性,极大地增强了系统的自适应性。
在现代农业生产中,多目标智能决策方法对于提高作物产量和质量、降低资源消耗、实现可持续发展具有重要意义。多目标强化学习能够在多个目标之间寻找最优权衡解,例如在最大化作物产量的同时,最小化水资源和肥料的使用。通过与环境的不断交互,智能体学习在不同条件下采取何种行动以实现最优决策。这种方法不仅可以在动态环境中进行策略优化,还能够在面对外部环境变化时灵活调整决策方案,保证作物的稳产增效[22,23]。在实际应用中,多目标强化学习算法需要考虑如何有效地处理多个目标之间的冲突和权衡。例如,可以通过为每个目标分配权重来构建一个综合的目标函数,或者采用Pareto优化等方法来寻找最优解集合。此外,强化学习算法的设计也需要考虑到计算效率和实时性,以适应农业生产的实时决策需求。
为了解决当前作物管理中个性化需求难以捕捉、决策过程缺乏灵活性的难题[24],本研究提出一种基于LLM的个性化作物管理智能决策方法。该方法的核心思想是通过自然语言交互,动态获取农户在作物管理过程中的多样化需求,并将这些需求转化为多目标优化问题进行求解。本研究并不限于特定的作物或特定的作物类型,而是尝试利用LLM的推理性能,在用特定作物数据集进行微调的情况下实现精准作物管理[25]。具体来说,首先利用LLM与用户进行自然语言对话,准确获取用户在作物种植过程中对产量、资源消耗、劳动投入等方面的偏好。通过自然语言处理技术,系统能将用户的个性化需求转化为结构化的输入信息,以更好地服务于后续的决策过程。在此基础上,将作物管理问题建模设为一个多目标决策问题,结合用户偏好设计相应的优化目标。通过强化学习算法,系统与仿真环境进行持续交互,不断调整和优化作物管理策略,使得智能体学到的管理策略能泛化到不同的先验条件,满足用户的个性化需求。强化学习算法不仅可以在动态环境中进行策略优化,还能在面对外部环境变化时灵活调整决策方案,保证作物的稳产增效。同时,本研究在决策过程中引入多目标权衡机制,确保系统能够根据用户在作物产量、水肥资源和人力消耗等方面的不同优先级,生成最符合其需求的管理方案。
1 研究方法
所提的个性化作物水肥管理智能决策方法由两个部分组成:1)设计LLM,通过多轮对话捕捉用户的偏好;2)构建基于偏好强化学习的作物管理决策模型。基于LLM的个性化蔬菜作物管理方法整体结构如图1所示,LLM在经过设计后,拥有了通过多轮对话估计用户偏好的能力,该偏好用于下游的强化学习智能体,通过多目标强化学习训练得到个性化的蔬菜作物管理策略。
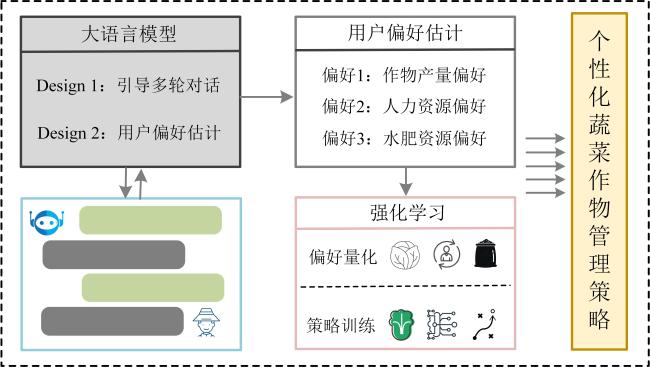
1.1 LLM偏好估计
本研究中的LLM通过两个阶段进行优化:提示设计和对抗性微调,以准确估计用户的个性化偏好。在提示设计阶段,目标是创建能够有效引导用户表达偏好的对话提示。这些提示通过预定义的问题或指令来实现,旨在激发用户提供详细的需求和偏好信息。数学上可以将提示设计表示为一个优化问题,其中目标是最大化用户偏好信息的质量,见公式(1) 。
式中: 为在给定提示参数 的条件下用户偏好 的条件概率; 表示用户偏好的分布,本研究将其设置为均匀分布; 为期望符号。优化过程涉及调整提示参数 ,以提高模型对用户偏好的预测准确性。
对抗性微调阶段涉及两个LLM的交互,一个扮演用户(User Model),另一个扮演系统(System Model)。User Model初始化为具有特定偏好的模型,而System Model通过对话来估计这些偏好。User Model的目标是生成符合其偏好的响应。这可以表示为公式(2) 。
式中: 为User Model在参数 下的策略; 为System Model可能采取的策略集;s为从S中采样。
System Model的目标是准确地估计User Model的偏好。这可以通过最小化预测偏好和实际偏好之间的差异来实现,见公式(3) 。
式中: 是System Model对用户偏好的预测; 是User Model的真实偏好分布;KL散度用于衡量两个分布之间的差异。
在对抗性微调的训练过程中,两个模型通过交替训练进行改进。User Model生成响应,而System Model尝试预测User Model的偏好。这个过程可以用更新规则来描述,User Model更新表示为公式(4) 。
而System Model更新则为公式(5) 。
式中: 和 均为学习率参数; 表示训练的迭代次数。通过这种方式,System Model将学会在多轮对话中准确捕捉和预测用户的个性化偏好,从而为作物管理策略提供决策支持。微调阶段的核心在于通过对抗性训练,强化LLM对用户偏好比例的准确估计。这种方法能够帮助模型捕捉偏好权重之间的微妙差异,例如用户在作物产量和资源消耗之间的具体平衡点,从而将用户需求有效转化为优化目标。通过微调后的模型,系统可以在多目标优化问题中提供更切合实际需求的解决方案,增强模型在动态环境中的适应性。
与传统的微调方法相比,采用对抗性微调的方式能使LLM摆脱数据量不足引起的限制。在该微调过程中,无需大量采集包含标注的用户偏好性对话,而是通过自然语言对话的形式,通过User Model动态地引导System Model。使用LLM来捕捉用户个性化偏好能够通过自然语言对话的方式,以更直观和更符合人类交流习惯的方式获取用户的偏好信息,这比传统的问卷调查或数据输入方式更为便捷和直观。大模型能够处理和理解复杂的语言表述,从中提取出用户的隐含偏好,这是传统方法难以实现的。此外,大模型还可以通过对话过程中的上下文信息,动态调整提问策略,以更准确地捕捉用户的个性化需求。
1.2 多目标强化学习
LLM估计出的用户偏好被用作多目标强化学习中的目标量化标准。本研究使用PPO(Proximal Policy Optimization)算法来训练一个基于用户偏好的作物管理策略,并采用gym-DSSAT(gym-Decision Support System for Agrotechnology Transfer)作为训练用的仿真环境。偏好从均匀分布中初始化,表示为随机初始化的偏好向量 ,其值从均匀分布中初始化,并且满足 和 ,其中 代表第 个目标的偏好权重。
多目标强化学习问题可以定义为一个元组 ,其中 是状态空间,是蔬菜生长状态的高维数据组成的空间; 是动作空间,代表每个时间节点的灌溉或施肥用量; 是状态转移概率函数集合,对于第i个目标, 表示在状态 下执行动作 ,转移到状态 并收到奖励 的概率; 是奖励函数集合,每个 表示在状态 下执行动作 ,转移到状态 时获得的奖励; 是折扣因子,用于衡量未来奖励的当前价值。
在多目标强化学习中,设计合理的奖励函数是至关重要的。作物产量奖励函数 需要鼓励策略提高作物产量。产量奖励见公式(6) 。
式中: 和 分别为当前状态和下一状态的作物产量; 为作物产量的权重系数,即为用户对作物产量的偏好。
节约人力资源是提高农业生产效率的关键。因此,奖励函数 应该鼓励策略减少人力资源的消耗,见公式(7) 。
式中: 和 分别为最大和当前的人力资源使用情况,人次/天; 为人力资源的权重系数,即为用户对人力资源的偏好。
水肥资源的奖励函数 应该鼓励策略优化水肥资源的使用, 见公式(8) 。
式中: 和 分别为当前状态和下一状态的水肥余量,kg/ma; 是水肥资源的权重系数,即为用户对水肥资源的偏好。综合考虑上述三个目标,总奖励函数可以表示为三个目标奖励函数的加权和见公式(9) 。
在多目标强化学习中,智能体的目标是最大化偏好加权的累积奖励,定义见公式(10) 。
式中: 是智能体的策略, 是偏好向量; 是多目标强化学习中的目标数量,在本研究中为3。本研究使用PPO算法来训练作物管理策略;先定义优势函数 用于估计在状态 下采取动作 的相对价值,定义见公式(11) 。
式中: 是状态-动作对的期望回报; 是状态的价值函数。优势函数表示采取动作 相比于平均行为所能获得的额外回报。使用广义优势估计来计算优势函数 见公式(12) 。
式中: 是时间步 的TD误差; 是GAE(Generalized Advantage Estimation)参数,控制优势估计的平滑程度。价值函数 的估计通过时间差分误差来完成,见公式(13) 。
PPO的目标函数结合了策略梯度和优势估计,以优化策略参数,使用裁剪的代理目标函数来限制策略更新的幅度,见公式(14) 。
式中: 是策略在时间 下的概率比率; 为上下界,位于0到1之间; (裁剪)函数限制了概率比率的变化范围。通过这种方式,PPO算法能够在每次迭代中使用相同的数据多次进行策略更新,提高数据效率,并保持策略更新的稳定性。
总体来说,所提出方法包含四步,如表1所示,分别为用户需求、偏好建模、策略训练和实时调整四部分。
表1 个性化作物水肥管理智能决策模型训练及学习流程Table 1 Workflow for the training and learning of the personal decision model |
| 步骤 | 描述 |
|---|---|
| 用户交互 | LLM通过自然语言对抗学习获取用户需求,涵盖产量、人力资源、水肥消耗等方面的个性化目标 |
| 偏好建模 | 根据用户需求生成结构化的偏好模型,将其转化为多目标优化问题中的权重参数 |
| 策略训练 | 利用PPO在仿真环境中训练作物管理策略,优化用户目标与资源分配 |
| 实时调整 | 根据环境反馈动态调整策略,保证作物产量的同时优化资源使用 |
2 结果与分析
通过一系列实验来验证所提出的基于LLM的个性化作物管理智能决策方法的有效性。实验分为两个主要部分。首先,通过LLM的对抗模拟验证LLM在偏好估计方面的性能。其次,通过随机初始化偏好在gym-DSSAT平台验证多目标强化学习训练出的作物管理策略的有效性和效率。
2.1 偏好估计验证
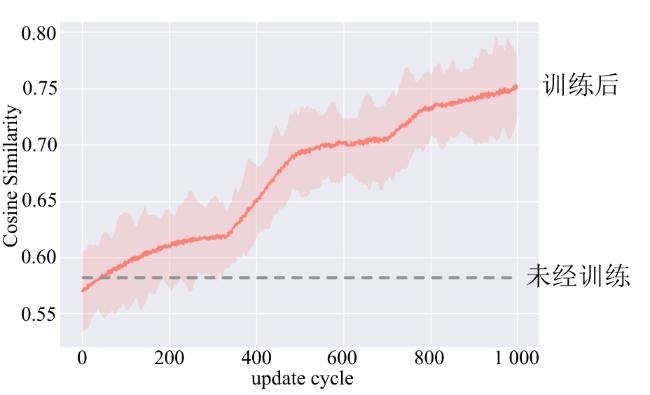
为了验证LLM在偏好估计方面的性能,本研究采用Qwen-VL-Chat-Int4作为基模型,实例化一个LLM作为User Model。该模型被训练以模拟用户在蔬菜作物管理中的偏好,包括产量、人力资源消耗和水肥资源消耗三个维度。System Model的目标是准确估计User Model的偏好。在训练过程中,User Model随机初始化自身偏好 ,并根据该偏好与System Model进行交互。System Model则通过对话结果估计User Model的偏好值,其估计结果为 。为了度量三维偏好的准确率,将User Model的偏好表示为一个三维向量 ,其中 , 和 分别代表对产量、人力资源和水肥资源的偏好权重。使用余弦相似度来度量System Model估计的偏好向量 与User Model实际偏好向量 之间的相似度。余弦相似度的计算为公式(15) 。
图2展示了LLM在提示设计以及对抗性微调时对User Model的偏好估计情况。在未经训练前,所估计的偏好与真实偏好的余弦相似度只有0.57左右,经过1 000个更新周期,训练后的余弦相似度接近0.75,远超过未经训练的模型本身。这说明所提出的提示设计和对抗性微调方法能有效增加LLM通过多轮对话对用户意图的捕捉以及用户偏好的估计能力。图3给出了训练后的对话实例。其中一个LLM扮演User Model并随机初始化其自身偏好,经过提示设计和对抗性微调的LLM,能够通过多轮对话引导User Model回答问题并提供对其偏好进行准确估计。User Model在任务开始前初始化偏好:对作物产量的偏好为0.52,对人资资源的偏好为0.40,对水肥资源的偏好为0.08。System Model通过引导User Model对话,对其偏好进行估计,估计结果为:作物产量偏好0.60,人力资源偏好0.30,水肥资源偏好0.10。

2.2 作物管理策略验证
为了验证作物管理策略的性能,在gym-DSSAT平台上进行实验,于玉米生产过程中选择灌溉和施肥任务进行实验验证。在这些实验中,一集(episode)模拟了一个生长季节,每一步代表一天,最多160天。模拟在种植前开始,以作物收割结束,收割日期自动定义为作物成熟日期。本实验中的作用空间由灌溉水量和施肥量组成,两者都是连续值。灌溉的最大值设定为50 mm/m2,施肥的最大值为200 kg/hm2。观测空间的各种变量详见表2,这些变量对于评估作物及其环境的状态至关重要。实验中使用的强化学习模型由OpenAI stable-baselines接口生成,网络参数默认为两个隐藏层,每个隐藏层拥有64个神经元。使用的其他超参数如表3示。
表2 水肥灌溉任务的观测空间Table 2 Observation space in irrigation and fertilization task |
| 状态 | 定义 | 灌溉 | 施肥 |
|---|---|---|---|
| rtdep | 根部深度/cm | √ | × |
| srad | 当日太阳辐射/(MJ/m2/d) | √ | × |
| sw | 土层体积土壤含水量/ml | √ | × |
| tmax | 当日最高气温/℃ | √ | × |
| totir | 总灌溉水量/mm | √ | × |
| wtdep | 水位埋深/cm | √ | × |
| cumsumfert | 累积氮肥施用量/(kg/ha2) | × | √ |
| nstres | 植物氮胁迫指数 | × | √ |
| swfac | 植物水分胁迫指数 | √ | √ |
| xlai | 植物群体叶面积指数 | √ | √ |
| dap | 播种后天数 | √ | √ |
| dtt | 当天的生长度/(°C/day) | √ | √ |
| ep | 实际植物蒸腾速率/(mm/d) | √ | √ |
| grnwt | 粒重干物质/(kg/hm2) | √ | √ |
| istage | 作物生长阶段 | √ | √ |
| topwt | 地上种群生物量/(kg/hm2) | √ | √ |
| vstage | 营养生长阶段(叶片数)/个 | √ | √ |
|
表3 多目标强化学习实验超参数设置Table 3 Hyper-parameters in experiments for multi-objective reinforcement learning |
| 超参数 | 定义 | 值 |
|---|---|---|
| 策略网络学习率 | 0.000 1 | |
| 价值学习率 | 0.000 3 | |
| 折扣因子 | 0.99 | |
| n_epochs | 每个迭代的训练周期数 | 10 |
| clip_param | 策略比率的裁剪阈值 | 0.2 |
| GAE的权重因子 | 0.95 | |
| PPO算法的裁剪比率参数 | 0.2 |
在实验中,通过模拟一个完整的生长季节来评估作物管理策略的性能。衡量作物产量和资源消耗的方法如下。
1)作物产量。通过仿真平台提供的作物生长模型,可以获取每个时间步的作物产量数据。作物产量通常以单位面积的重量(如kg/hm2)来衡量。
2)人力资源消耗。在仿真环境中,人力资源的消耗可以通过记录在作物管理过程中所需的劳动时间或劳动次数来衡量。
3)水肥资源消耗。可以通过模拟环境中的灌溉和施肥记录来衡量。这包括总灌溉水量(mm/m²)和累积氮肥施用量(kg/hm2)。
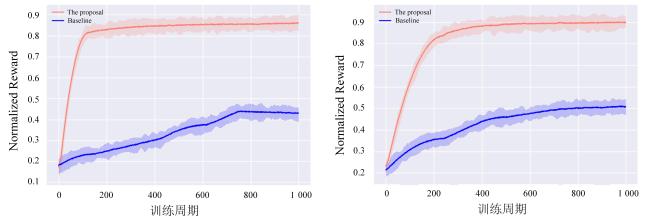
由于多个任务目标的存在,使用归一化奖励(实际奖励/理论最大奖励)来评估所提出的方法。并采用不考虑多目标的PPO方法作为baseline。实验结果如图4所示,其中图4a为灌溉任务下的归一化结果,图4b为施肥任务下的归一化结果。在两种任务下都采用不同的随机种子重复实验5次,曲线代表5次的平均结果,阴影代表对应的标准差。可以看到在两种任务下所提出的方法(The proposal)都远高于baseline,并且极度靠近理论最大奖励。在灌溉任务上,经历130左右的episode,所提出方法的归一化奖励都超过了0.8,而baseline在经历完整训练后的结果只有0.45。施肥任务也有相同趋势。这进一步说明了,在个性化作物管理场景中,将作物管理任务建模为一个多目标任务更加有潜力。
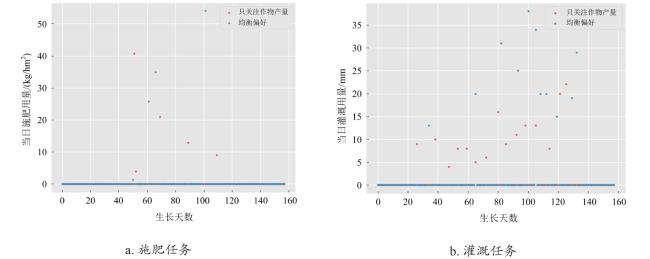
为了进一步说明所提出方法的效果,选择了两个经典的固定偏好,分别为只关注作物产量(作物产量偏好为1,人力资源和水肥资源的偏好均为0),以及均衡偏好(作物产量偏好、人力资源偏好、水肥资源偏好权重都为0.33),来观察上述策略在这些偏好空间上的决策结果。结果如图5所示,可以看到,在两种典型偏好(只关注作物产量和只关注均衡偏好)设置下,只关注作物产量在总体作业次数上均高于均衡偏好设置。在施肥任务中,但只关注作物产量时,施肥策略在累计158天的生长时间内总共进行了5次施肥,而均衡偏好仅仅进行了4次施肥作业。同样地,在灌溉任务中,当只关注作物产量时,一共进行了15次灌溉,而均衡偏好设置下仅在10天进行了灌溉作业。这一结果反映出所学策略能在不同偏好设置下调节自身决策。但只关注作物产量时,人力资源和水肥用量便不再考虑,因此灌溉/施肥次数变多且总用量相比均衡偏好要高。而均衡偏好设置下,由于要考虑人力资源和总用量,策略尽可能在保证作物健康生长的情况下减少总水肥用量和作业次数。
3 结 论
本研究提出了一种基于LLM的个性化蔬菜管理智能决策方法,通过自然语言处理技术准确捕捉用户需求,并结合多目标强化学习优化作物管理策略。实验结果表明,该方法能够有效提升作物产量,同时显著降低资源消耗,满足用户的多维偏好需求。这一研究为农业智能决策提供了新的技术路径,具有良好的应用潜力。未来工作将围绕模型的可解释性、对多样化农业场景的适应能力展开,进一步推动智能农业的精准化和可持续发展。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}