



(登录www.smartag.net.cn免费获取电子版全文)
0 引 言
水稻作为重要的粮食作物之一,对于国家的粮食安全以及经济发展具有重要意义[1],优良的品种是实现水稻高产、优质、高效、生态和安全的重要基础[2]。水稻品种的选育需要考虑多个方面,如品种的生育期、产量、米质和抗逆性等[3],而世界上稻属作物的种类繁多,不同品种又具有不同的特性,如何快速有效地进行水稻品种信息检索,满足用户水稻品种选育需求成为一个重要问题。传统方法在搜索引擎上进行检索,但其返回的结果不能很好地满足用户信息检索的需求,用户还需二次或多次筛选,增加了工作量。近年来,推荐系统[4, 5]在信息检索领域展现出了巨大的潜力,其能够快速及有效地解决用户的需求,为用户提供有价值的相关信息,帮助用户做出决策。
有关推荐系统的研究主要是协同过滤算法[6],其核心思想是基于对用户历史行为数据的挖掘,发现用户的喜好偏向,并基于不同的偏好对用户进行群组划分,进而完成推荐。He等[7]提出一种基于神经网络的协同过滤模型(Normalized Discounted Cumulative Gain, NDCG),使用非线性的深度神经网络作为交互函数,从而提高推荐系统的性能。Wang等[8]将用户和项目的关系建模为图结构,利用图神经网络强大的特征提取能力来捕获用户和项目之间的高阶关系,有效地将协同信号注入嵌入表示过程中。然而,推荐系统仍面临着数据稀疏和冷启动问题[9],即缺乏历史交互数据的项目,难以进行准确的建模和推荐。为解决这一问题,相关研究提出将知识图谱中丰富的语义知识作为辅助信息融入协同过滤算法中,用于知识增强的推荐[10-12]。例如,Wang等[13]提出一种基于知识图谱的意图学习框架(Knowledge Graph-based Intent Network, KGIN),通过建模用户意图和关系路径,以捕捉用户与项目之间的复杂交互模式。Yang等[14]提出一种基于知识图谱的对比学习模型(Knowledge Graph Contrastive Learning, KGCL),通过数据增强和正负样本对比学习,以抑制信息聚合过程中的知识图谱噪声[15],从而学习更稳健的知识感知表征,提高推荐系统的准确性和鲁棒性。
上述方法皆在推荐系统领域取得显著成果,交互数据中的意图因素和知识图谱对于推荐工作有着重要作用。然而,目前水稻品种选育缺少相应的数据支持,此外,在方法层面上,水稻品种选育由用户的意图和品种特性共同决定,现有的方法未考虑二者共同作用下对模型性能的影响,而构建的水稻品种特性的知识图谱在一定程度上存在着噪声问题。
针对上述问题,本研究从数据和方法两方面出发,提出一种(Bi-intentional Modeling and Knowledge Graph Diffusion, BMKGD)模型去噪的推荐模型。在数据层面,通过在一些权威网站上面进行数据收集和处理,构建相应的水稻品种选育数据集作为支撑。在方法层面,同时兼顾意图建模和知识图谱去噪。在意图建模上,引入双意图建模的方法,考虑到用户在选择水稻品种时选育意图的个体独立性和从众性。对于构建的水稻知识图谱中的噪声问题,结合扩散模型,进行去噪处理;之后在不同视图之间进行跨视图对比学习,编码两个视图共享的信息,以提高模型的性能,为用户推荐更相关的水稻品种。
1 水稻品种选育推荐方法架构
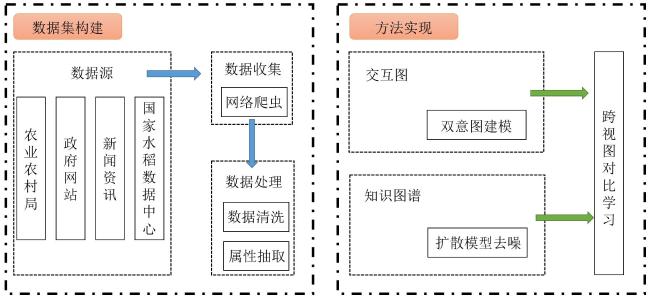
2 数据集构建
2.1 数据获取
本研究使用的数据集为自构建的水稻品种选育数据集,主要由交互数据和知识图谱数据两部分构成。对于交互数据,数据源为政府网站、地区农业农村局和相关新闻资讯,考虑到目前无法获取到具体的用户-项目交互数据,先以县区为单位,在数据源中检索并使用网络爬虫收集该地区历史种植过的水稻品种作为交互数据[16]。再由农业专家指导,以地区为单位模拟生成一批用户,并从该地区历史交互数据中进行随机采样,构建相应的“用户-项目”交互数据。
对于知识图谱数据,数据源为国家水稻数据中心网站(https://www.ricedata.cn/),涵盖了历史审定的水稻品种以和性状描述,使用的采集方法为编写网络信息收集工具,对网站上相关水稻品种的文本描述信息进行采集,再从所属品种、生育期、抗病性、耐寒性和抗倒伏等多个属性出发,对文本信息进行属性抽取,构建相应的知识图谱数据[17-19],部分交互数据和部分知识图谱数据如表1和图2所示。
表1 水稻交互数据部分示例Table 1 Partial examples of rice interaction data |
| 地区/用户 | 交互水稻品种 |
|---|---|
| 安徽省合肥市肥西县 | 荃两优2118、南粳60、隆两优608、徽两优1133、晶两优1237、徽两优719、扬籼优953、桃两优316……隆两优608、桃两优316、Q两优169、吨两优900、深两优008、旺两优1577、南粳2728、玮两优1206 |
| 肥西县模拟用户-0 | 荃两优2118、南粳60……隆两优608、桃两优316 |
| 肥西县模拟用户-1 | 隆两优608、徽两优1133……Q两优169、吨两优900 |
| 肥西县模拟用户-2 | 晶两优1237、徽两优719……深两优008、旺两优1577 |
| 肥西县模拟用户-3 | 扬籼优953、桃两优316……南粳2728、玮两优1206 |
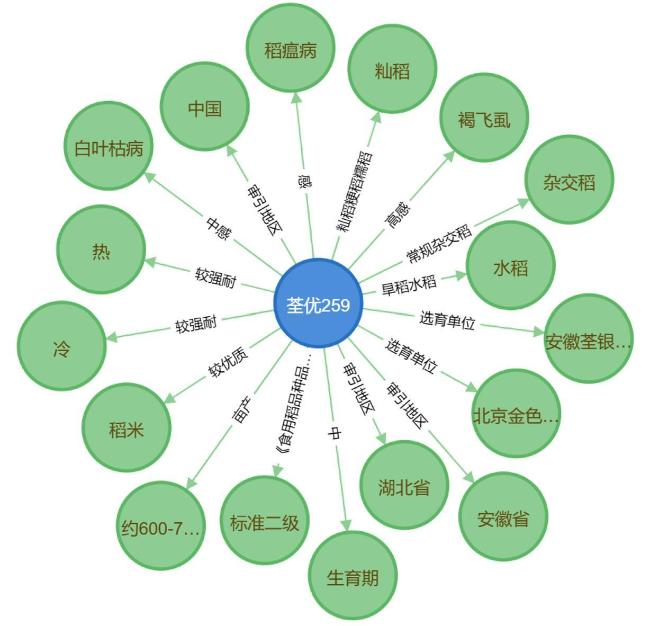
数据在收集过程中,选择了合适的数据收集方法和工具,确保了数据录入的准确性,其次对数据进行清洗,剔除异常值和错误数据,再由专家指导,对数据进行检查验证,以确保数据的可靠性。
2.2 数据集构建
自构建的水稻品种选育数据集共收集了1 051个县区的交互数据,再根据交互数据数量的多少,按照一定的比例模拟生成用户,进一步地扩充到11 235个用户,总交互水稻品种类别数共2 641种,由这些水稻品种构建的知识图谱三元组数共计29 508条,交互数据量共100 603条,并将这些交互数据按7∶2∶1的比例划分为训练集、测试集和验证集。
3 研究方法
本研究提出的BMKGD模型整体架构如图3所示,主要分为三个部分:双意图建模、知识图谱扩散和跨视图对比学习。对于由用户和项目交互数据构建的交互图,建立双意图空间,将用户和项目送入其中,得到增强后的用户和项目表示;对于知识图谱,扩散模型能很好地去除其中的噪声数据,对去噪处理后的知识图谱进行信息聚合,得到相应的项目表示;不同视图间项目表示的对比学习方法能够充分学习到两个视图中的信息,提升推荐效果。
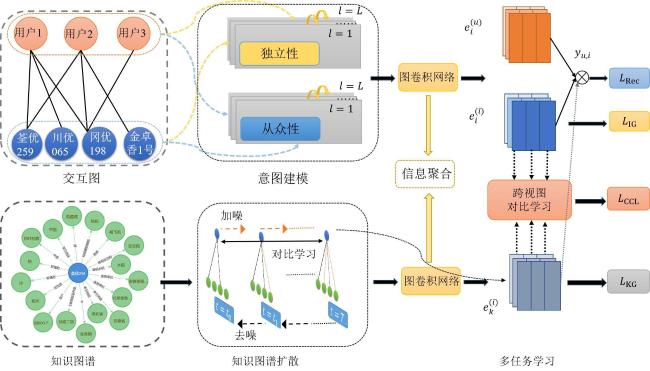
3.1 双意图建模
基于此,本研究从个体独立性和从众性两方面出发,对意图进行建模表示,虽然项目不具有主动性,但仍可以将项目侧的意图理解为其本身所具有的属性,对其进行意图建模。具体的独立性和从众性的意图空间可表示为 和 ,并在对应的意图空间中定义 个意图原型 和 ,通过将不同的意图原型与用户和项目表示进行信息聚合,得到对应的意图表示,见公式(1) 和公式(2) 。
式中: 表示图神经网络的层数; 、 分别表示用户、项目; 、 表示用户和项目在第 层的嵌入表示。用户 和任意意图 之间的相关性分数 通过公式(3) 计算。
为了利用高阶协同信息,本研究在不同图层之间执行基于图卷积网络的嵌入传播。
在意图空间中,每种意图都具有独特的语义,如果任意意图可以被其他意图进行表达,则可能会造成语义冗余,这里通过对比正则化以约束意图之间的相似性,定义交互图中双意图建模的损失函数,如公式(4) 和公式(5) 所示。
式中: 表示余弦相似度; 为温度系数,控制着模型对负样本的区分度; 表示交互图中用户和项目的集合。此处 、 和 皆为临时表示符号,并无具体含义。
3.2 知识图谱扩散
知识图谱扩散包含正向和反向两个过程,在正向传播过程中,定义初始状态 下项目与实体属性构成的图结构为原始图结构,并向其不断地添加高斯噪声,从 到 的过渡可表示为公式(6) 。
式中: 表示扩散步骤; 表示高斯分布,每一步添加的高斯噪声的规模由 控制; 表示项目的集合。之后,扩散模型再从 状态下的图结构去除添加的噪声,以恢复原始的图结构,去噪过程可表示为公式(7) 。
式中: 和 分别表示由参数化的神经网络生成的高斯分布的均值和协方差。
为避免噪声数据的影响,选择在原始图结构中的项目表示 与生成的图结构中的项目表示 之间进行对比学习,定义知识图谱侧的损失函数如公式(8) 所示。
式中: 为项目 在所有图结构中的表示。
在得到去噪处理的知识图谱后,借助图神经网络[25]的信息聚合机制,得到融合了知识图谱信息的项目表示,再将其引入到具体的推荐任务中,通过交互行为中的协作信号又能增强扩散模型的学习表示。
3.3 多任务学习
4 结果与分析
4.1 评价指标
4.2 参数分析
表2 权重参数 设置对 模型性能的影响Table 2 Effect of weight parameter α setting on BMKGD on model performance |
| 参数 | Recall | NDCG |
|---|---|---|
| α=100 | 0.324 6 | 0.148 8 |
| α=10 | 0.327 6 | 0.149 9 |
| α=1 | 0.323 0 | 0.146 2 |
表3 权重参数 设置对 模型性能的影响Table 3 Effect of weight parameter setting on BMKGD on model performance |
| 参数 | Recall | NDCG |
|---|---|---|
| β=10 | 0.326 7 | 0.149 6 |
| β=1 | 0.327 6 | 0.149 9 |
| β=0.1 | 0.327 4 | 0.149 3 |
表4 权重参数 设置对 模型性能的影响Table 4 Effect of weight parameter setting on BMKGD on model performance |
| 参数 | Recall | NDCG |
|---|---|---|
| γ =10 | 0.322 4 | 0.145 9 |
| γ =1 | 0.327 6 | 0.149 9 |
| γ =0.1 | 0.324 3 | 0.148 1 |
由实验结果可见,当 设置为10, 设置为1, 设置为1,模型的性能最佳,偏高或偏低的参数设置,都会造成模型性能的下降。此外,双意图和跨视图对比学习模块对于模型性能的影响较大,其参数的改变导致模型性能的变化较为明显,而知识图谱扩散模型去噪模块则次之,说明双意图模块在推荐任务中发挥着重要作用。
4.3 对比实验
为了验证 模型的有效性,将其在水稻品种选育数据集上与不同的基线模型进行比较,主要模型如下。
[28]:该方法利用矩阵分解的隐式反馈导出成对排名损失。
基于协同过滤和知识图谱特征的模型(Collaborative Knowledge Based Embedding, CKE)[32]:集成协同过滤方法和知识图谱嵌入,丰富了项目侧的表示。
基于知识感知图神经网络和标签平滑的模型(Knowledge-aware Graph Neural Networks with Label Smoothness, KGNN-LS)[33]:考虑了用户对图卷积中的不同知识三元组的偏好,并引入标签平滑作为正则化。
基于知识图谱卷积网络的模型(Konwledge Graph Convolutional Networks, KGCN)[31]:引入图卷积网络整合高阶信息,并使用用户嵌入的偏好作为权重。
基于知识图谱注意力机制的模型(Knowledge Graph Attention Network, KGAT)[34]:引入了协作知识图谱的概念,在知识图谱聚合上使用了注意力机制。
[13]:对用户关系意图进行建模,使用关系路径感知聚合以获取知识图谱上的丰富信息。
[14]:利用自监督学习来融合知识图谱信息,通过随机破坏图结构生成对比视图,以解决知识图谱中存在的噪声问题。
基于双向意图指导的协同过滤模型(Bilateral Intent-guided Graph Collaborative Filtering, BIGCF)[21]:从因果关系的角度考虑了用户和项目之间的交互,针对交互空间和意图空间提出了图对比正则化。
基于知识图谱扩散的模型(Knowledge Graph Diffusion, DiffKG)[35]:通过扩散模型对知识图谱进行处理,并结合协同知识图卷积机制。
对比结果如表5所示。
表5 BMKGD模型与不同基线模型水稻品种选育的对比结果Table 5 The overall performance for BMKGD and baseline models of selection of rice varieties |
| 模型 | Recall | NDCG |
|---|---|---|
| BPR | 0.283 3 | 0.129 1 |
| CKE | 0.292 7 | 0.130 8 |
| KGNN-LS | 0.274 3 | 0.115 6 |
| KGCN | 0.276 7 | 0.118 7 |
| KGAT | 0.259 7 | 0.112 7 |
| KGIN | 0.283 0 | 0.125 0 |
| KGCL | 0.301 2 | 0.135 7 |
| BIGCF | 0.318 5 | 0.144 5 |
| DiffKG | 0.268 0 | 0.122 3 |
| BMKGD | 0.327 6 | 0.149 9 |
由实验结果可见,本研究提出的方法在水稻品种选育数据集取得了最优的表现,其 值和 值相较于次优模型提升了2.9%和3.7%,性能的提升在一定程度上验证了方法的有效性,说明 模型更适用于水稻品种推荐。
模型在水稻品种选育数据集上的 值为0.327 6满足推荐系统的基本要求,说明本研究提出的方法可用于实际水稻品种选育工作中,减少用户信息检索过程中的工作量,辅助用户做出决策。
相较于只考虑意图指导的 模型和知识图谱去噪的 模型,本研究提出的方法要优于二者,结合具体的推荐任务分析可以得到,交互意图和知识图谱对于推荐预测都有着重要作用,兼顾二者的方法有助于提升推荐效果。
对于考虑到意图因素的模型,如 模型和 模型,都有着不错的表现,意图一定程度上指导着用户做出选择,合理有效地对其进行处理能够更好地分析用户行为。
对于传统的知识感知推荐模型,如 、 模型等,在水稻品种选育数据集上并未取得很好的效果,其性能还要弱于未引入知识图谱的模型,如 和 分析可得,交互数据中的协同信号发挥着主要作用,同时构建的知识图谱质量还有一定的提升空间。
4.4 消融实验
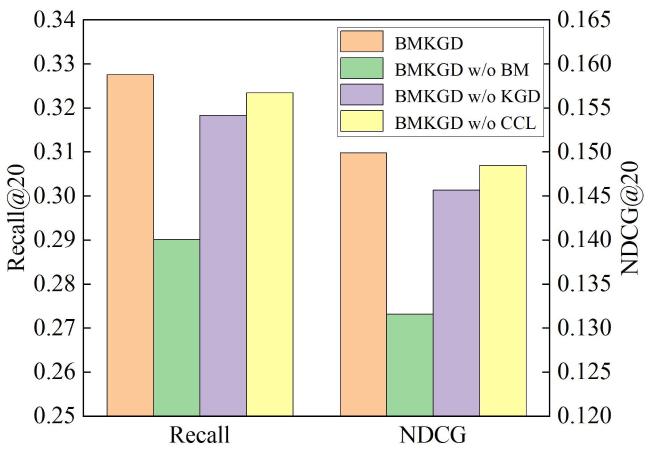
由消融实验结果可见,去除关键组件的模块变体相较于原模型,性能都有所下降,这验证了各模块的有效性;去除双意图建模组件的模型变体性能下降较为明显,说明意图因素对于推荐任务有着重要作用;同样地,去除知识图谱扩散去噪模块的模型变体性能也有所下降,在知识图谱构建过程不可避免地会引入无关噪声,去噪处理有助于减少对无关信息的聚合,强化项目的嵌入表示;去除跨视图对比学习模块的模型变体性能下降较小,说明该模块在充分利用两个视图之间的协作关系上还有一定的提升空间,对其进行分析,推测可能是由于经双意图建模处理后的项目表示聚合了意图信息,在进行跨视图对比学习过程中,其中一部分被当作噪声,对模型性能产生了影响。
5 结 论
本研究面向水稻品种选育,构建了一个水稻品种选育推荐数据集,并提出一种BMKGD的推荐模型。模型在交互图中进行双意图建模,考虑到交互意图的个体独立性和从众性;在知识图谱侧,使用了扩散模型去除无关噪声,通过引入随机噪声逐步损坏原始的图结构,再通过多次迭代去除增加的噪声,以恢复原始知识图结构,过程中完成对知识图谱的去噪处理;此外,项目侧的跨视图对比学习能很好地编码两个视图中的信息,充分学习到其中的协作关系,以完成更好的推荐。
本研究提出的推荐模型与其他模型对比,就实验结果而言,所提出的模型性能相较于表现最优的基线模型 ,其 值和 值分别提升了2.9%和3.7%,表明模型具有更好的推荐效果。
在未来的工作中,考虑构建多领域、多场景的数据,不只局限于水稻作物,进一步扩展至小麦、玉米等其他类型农作物,同时推荐场景也从育种扩展到生产和病虫害防治等,此外,也将对现有的推荐模型进行方法上的改进,确保其可以满足多元化的推荐任务。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}