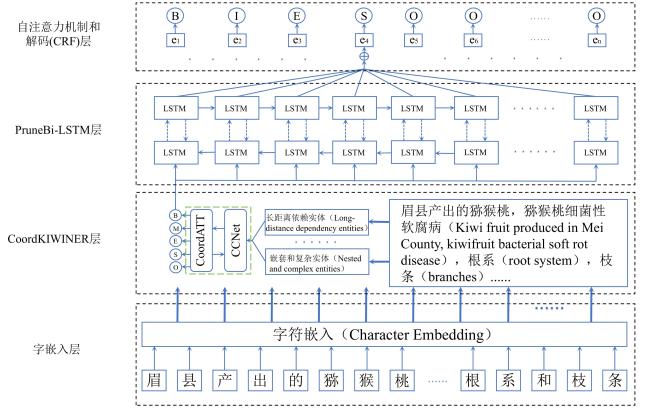
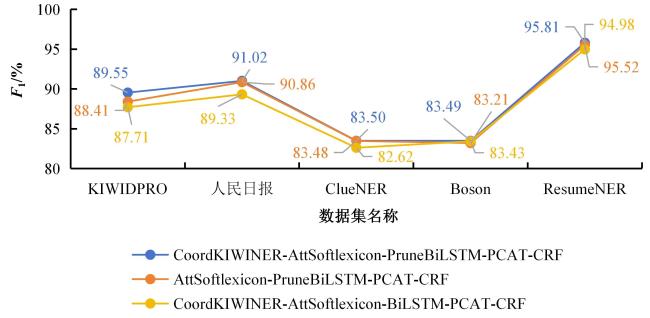
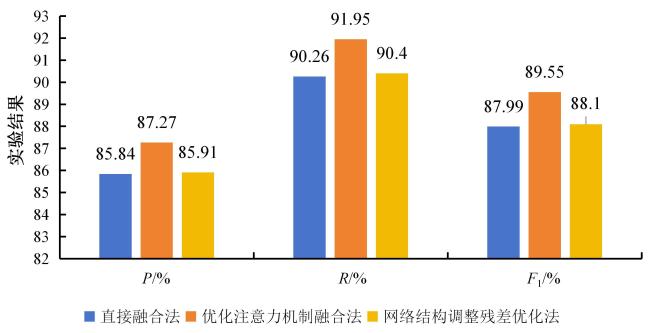
[Objective] Chinese kiwifruit texts exhibit unique dual-dimensional characteristics. The cross-paragraph dependency is complex semantic structure, whitch makes it challenging to capture the full contextual relationships of entities within a single paragraph, necessitating models capable of robust cross-paragraph semantic extraction to comprehend entity linkages at a global level. However, most existing models rely heavily on local contextual information and struggle to process long-distance dependencies, thereby reducing recognition accuracy. Furthermore, Chinese kiwifruit texts often contain highly nested entities. This nesting and combination increase the complexity of grammatical and semantic relationships, making entity recognition more difficult. To address these challenges, a novel named entity recognition (NER) method, KIWI-Coord-Prune(kiwifruit-CoordKIWINER-PruneBi-LSTM) was proposed in this research, which incorporated dual-dimensional information processing and pruning techniques to improve recognition accuracy. [Methods] The proposed KIWI-Coord-Prune model consisted of a character embedding layer, a CoordKIWINER layer, a PruneBi-LSTM layer, a self-attention mechanism, and a CRF decoding layer, enabling effective entity recognition after processing input character vectors. The CoordKIWINER and PruneBi-LSTM modules were specifically designed to handle the dual-dimensional features in Chinese kiwifruit texts. The CoordKIWINER module applied adaptive average pooling in two directions on the input feature maps and utilized convolution operations to separate the extracted features into vertical and horizontal branches. The horizontal and vertical features were then independently extracted using the Criss-Cross Attention (CCNet) mechanism and Coordinate Attention (CoordAtt) mechanism, respectively. This module significantly enhanced the model's ability to capture cross-paragraph relationships and nested entity structures, thereby generating enriched character vectors containing more contextual information, which improved the overall representation capability and robustness of the model. The PruneBi-LSTM module was built upon the enhanced dual-dimensional vector representations and introduced a pruning strategy into Bi-LSTM to effectively reduce redundant parameters associated with background descriptions and irrelevant terms. This pruning mechanism not only enhanced computational efficiency while maintaining the dynamic sequence modeling capability of Bi-LSTM but also improved inference speed. Additionally, a dynamic feature extraction strategy was employed to reduce the computational complexity of vector sequences and further strengthen the learning capacity for key features, leading to improved recognition of complex entities in kiwifruit texts. Furthermore, the pruned weight matrices become sparser, significantly reducing memory consumption. This made the model more efficient in handling large-scale agricultural text-processing tasks, minimizing redundant information while achieving higher inference and training efficiency with fewer computational resources. [Results and Discussions] Experiments were conducted on the self-built KIWIPRO dataset and four public datasets: People's Daily, ClueNER, Boson, and ResumeNER. The proposed model was compared with five advanced NER models: LSTM, Bi-LSTM, LR-CNN, Softlexicon-LSTM, and KIWINER. The experimental results showed that KIWI-Coord-Prune achieved F1-Scores of 89.55%, 91.02%, 83.50%, 83.49%, and 95.81%, respectively, outperforming all baseline models. Furthermore, controlled variable experiments were conducted to compare and ablate the CoordKIWINER and PruneBi-LSTM modules across the five datasets, confirming their effectiveness and necessity. Additionally, the impact of different design choices was explored for the CoordKIWINER module, including direct fusion, optimized attention mechanism fusion, and network structure adjustment residual optimization. The experimental results demonstrated that the optimized attention mechanism fusion method yielded the best performance, which was ultimately adopted in the final model. These findings highlight the significance of properly designing attention mechanisms to extract dual-dimensional features for NER tasks. Compared to existing methods, the KIWI-Coord-Prune model effectively addressed the issue of underutilized dual-dimensional information in Chinese kiwifruit texts. It significantly improved entity recognition performance for both overall text structures and individual entity categories. Furthermore, the model exhibited a degree of generalization capability, making it applicable to downstream tasks such as knowledge graph construction and question-answering systems. [Conclusions] This study presents an novel NER approach for Chinese kiwifruit texts, which integrating dual-dimensional information extraction and pruning techniques to overcome challenges related to cross-paragraph dependencies and nested entity structures. The findings offer valuable insights for researchers working on domain-specific NER and contribute to the advancement of agriculture-focused natural language processing applications. However, two key limitations remain: 1) The balance between domain-specific optimization and cross-domain generalization requires further investigation, as the model's adaptability to non-agricultural texts has yet to be empirically validated; 2) the multilingual applicability of the model is currently limited, necessitating further expansion to accommodate multilingual scenarios. Future research should focus on two key directions: 1) Enhancing domain robustness and cross-lingual adaptability by incorporating diverse textual datasets and leveraging pre-trained multilingual models to improve generalization, and 2) Validating the model's performance in multilingual environments through transfer learning while refining linguistic adaptation strategies to further optimize recognition accuracy.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}