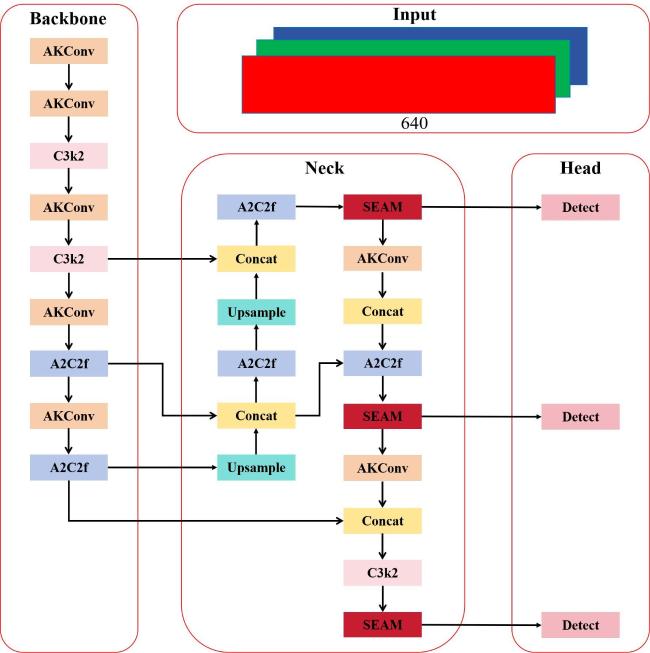
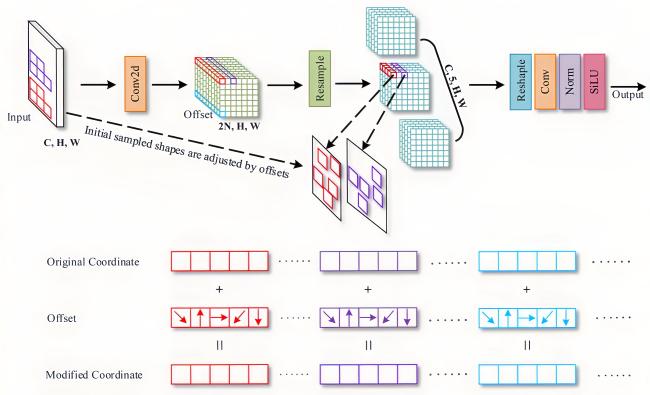
[Objective] With the rapid development of intelligent agriculture, computer vision-based livestock detection technology has become increasingly important in modern farming management. Among various livestocks, beef cattle play a crucial role in animal husbandry industry all over the world. Accurate detection and counting of beef cattle are essential for improving breeding efficiency, monitoring animal health, and supporting government subsidy distribution. However, in real-world farming environments, cattle often gather and move closely together, leading to frequent occlusions. These occlusions significantly degrade the performance of traditional object detection algorithms, resulting in missed detections, false positives, and poor robustness. Manual counting methods are labor-intensive, error-prone, and inefficient, while existing deep learning-based detection models still struggle with occlusion scenarios due to limited feature extraction capabilities and insufficient use of global contextual information. To address these challenges, an improved object detection algorithm named YOLOv12s-ASR, based on the YOLOv12s framework, was proposed in this research. The goal is to enhance detection accuracy and real-time performance in complex occlusion conditions, providing a reliable technical solution for intelligent beef cattle monitoring. [Methods] The proposed YOLOv12s-ASR algorithm introduced three key improvements to the baseline YOLOv12s model. First, part of the standard convolution layers with a modifiable kernel convolution module (AKConv) was replaced. Unlike traditional convolutions with fixed kernel shapes, AKConv could dynamically adjust the shape and size of the convolution kernel according to the input image content. This flexibility allowed the model to better capture local features of occluded cattle, especially in cases where only partial body parts were visible. Second, a self-ensembling attention mechanism (SEAM) was integrated into the Neck structure. SEAM combined spatial and channel attention through depthwise separable convolutions and consistency regularization, enabling the model to learn more robust and discriminative features. It enhanced the model's ability to perceive global contextual information, which was crucial for inferring the presence and location of occluded targets. Third, a repulsion loss function was introduced to supplement the original loss. This loss function included two components: RepGT, which pushed the predicted box away from nearby ground truth boxes, and RepBox, which encouraged separation between different predicted boxes. By reducing the overlap between adjacent predictions, the repulsion loss helped mitigate the negative effects of non-maximum suppression (NMS) in crowded scenes, thereby improving localization accuracy and reducing missed detections. The overall architecture maintained the lightweight design of YOLOv12s, ensuring that the model remained suitable for deployment on edge devices with limited computational resources. Extensive experiments were conducted on a self-constructed beef cattle dataset containing 2 458 images collected from 13 individual farms in Ningxia, China. The images were captured using surveillance cameras during daytime hours and included various occlusion scenarios. The dataset was divided into training, validation, and test sets in a 7:2:1 ratio, with annotations carefully reviewed by multiple experts to ensure accuracy. [Results and Discussions] The proposed YOLOv12s-ASR algorithm achieved a mean average precision (mAP) of 89.3% on the test set, outperforming the baseline YOLOv12s by 1.3 percent points. The model size was only 8.5 MB, and the detection speed reached 136.7 frames per second, demonstrating a good balance between accuracy and efficiency. Ablation studies confirmed the effectiveness of each component: AKConv improved mAP by 0.6 percent point, SEAM by 1.0 percent point and repulsion loss by 0.6 percent point. When all three modules were combined, the mAP increased by 1.3 percent points, validating their complementary roles. Furthermore, the algorithm was evaluated under different occlusion levels—slight, moderate, and severe. Compared to YOLOv12s, YOLOv12s-ASR improved mAP by 4.4, 2.9, and 4.4 percent points, respectively, showing strong robustness across varying occlusion conditions. Comparative experiments with nine mainstream detection algorithms, including Faster R-CNN, SSD, Mask R-CNN, and various YOLO versions, further demonstrated the superiority of YOLOv12s-ASR. It achieved the highest mAP while maintaining a compact model size and fast inference speed, making it particularly suitable for real-time applications in resource-constrained environments. Visualization results also showed that YOLOv12s-ASR could more accurately detect and localize cattle targets in crowded and occluded scenes, with fewer false positives and missed detections. [Conclusions] Experimental results show that YOLOv12s-ASR achieves state-of-the-art performance on a self-built beef cattle dataset, with high detection accuracy, fast processing speed, and a lightweight model size. These advantages make it well-suited for practical applications such as automated cattle counting, behavior monitoring, and intelligent farm management. Future work will focus on further enhancing the model's generalization ability in more complex environments and extending its application to multi-object tracking and behavior analysis tasks.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}