



0 引 言
1 材料与方法
1.1 数据收集
1.2 知识库构建
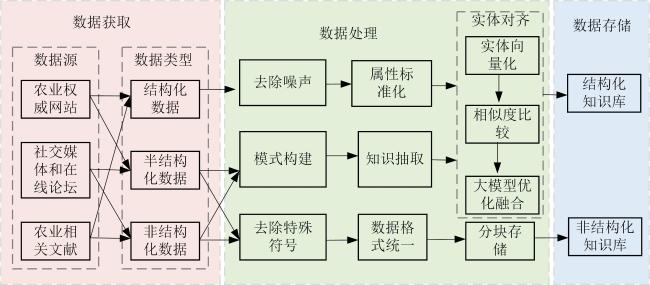
图1 农作物病虫害知识库构建流程Fig. 1 Construction process of crop diseases and pests knowledge base |
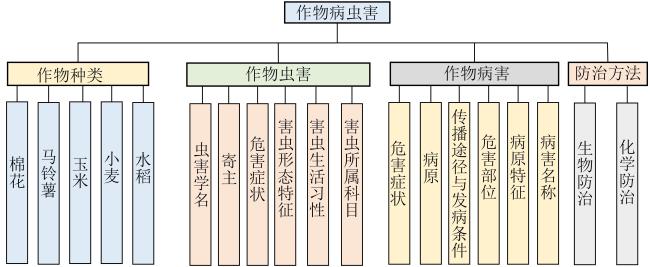
表1 农作物病虫害知识部分抽取结果展示Table 1 Display of extraction results for crop diseases and pests knowledge |
| 实体 | 属性 | 属性值 |
|---|---|---|
| 水稻稻瘟病 | 寄主 | 水稻 |
| 玉米黑束病 | 危害部位 | 叶片 |
| 棉花叶烧病 | 寄生方式 | 菌丝体 |
| 水稻稻瘟病 | 病害名称 | 稻瘟病 |
| 小麦锈病 | 危害部位 | 叶片、叶鞘 |
| 小麦蚜虫 | 危害部位 | 叶片、茎部 |
| 玉米矮花叶病 | 传播途径 | 蚜虫的扩散 |
| 棉花枯萎病 | 危害症状 | 叶脉褪绿变黄 |
| 水稻稻瘟病 | 发病条件 | 高温高湿环境 |
1.3 检索增强生成方法
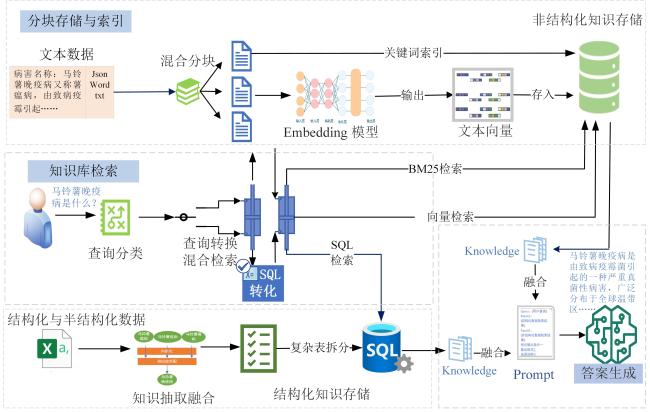
1.3.1 混合分块
1.3.2 检索推理
表2 农作物病虫害研究单跳查询模板Table 2 Single-hop query template for crop diseases and pests research |
| 模板类型 | 表达式示例 | 用户输入示例 |
|---|---|---|
| 症状解决 | {作物}{症状}怎么办? | 小麦叶锈病怎么办? |
| 病虫害 | {症状}是什么病? | 水稻叶子上的白点是什么病? |
| 方法询问 | {病害}用什么药? | 小麦赤霉病用什么药? |
| 传播途径 | {病虫害}是如何传播的? | 稻瘟病是如何传播的? |
| 环境影响 | {病虫害}与哪些环境因素有关? | 稻瘟病与哪些环境因素有关? |
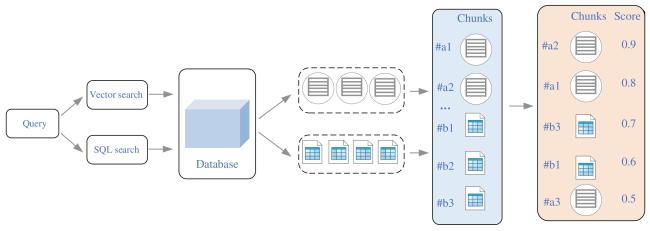
1.4 大模型生成
表3 答案生成提示词设计模板Table 3 Answer generation prompt word design template |
| 环节 | 步骤 | 内容 |
|---|---|---|
| 上下文组织(为模型推理提供背景等信息) | P1 | 你是一名农业病虫害防治专家,需基于知识库检索到的内容,依据解读的用户问题生成专业、可信的答案。请严格遵循以下步骤生成回答:用户查询{query} **上下文组织** 读取定位相关片段并排序: - 文档1:{检索片段1} - 文档2:{检索片段2} - ……(最多保留Top K个相关片段) 根据这些片段与{query}的相关性,从高到低对文档片段重新排序,结果存入数组中如[文档2编号,文档1编号……] |
| P2 | **关键信息提炼** - 从上述文档中提取与问题直接相关的信息;(如症状描述、病原特征、防治方案等) | |
| 模型多步推理与答案生成 | P3 | **模型多步推理** 根据以下链式模板分步分析问题,确保答案逻辑严谨: 1. *症状匹配*: - 用户描述:“{用户输入症状}” - 匹配知识库症状:“{检索片段中的症状描述}” - 关联病害:“{病害名称}”(引用文档) - 关联特征:{斑点/断裂/疱状病斑/表皮破裂}(引用文档) - 关联部位:{叶片/茎/穗}(引用文档) 2. *病因推断*: - 病原类型:{真菌/细菌/病毒/害虫}(引用文档) - 诱发因素:{环境条件/种植习惯}(引用文档) - 传播途径:{昆虫/真菌/风雨}(引用文档) 3. *防治建议*: - 农业防治:{轮作/土壤处理}(引用文档) - 化学防治:{农药}推荐2~3种农药,注明用量(引用文档) - 生物防治:{天敌/微生物制剂}(引用文档) |
| P4 | **答案生成** 请从病虫害名称、病原、病原特征、危害部位、危害症状、发病条件、传播方式、防治方法这些方面对{query}全面分析,结果控制在200字左右;逻辑清晰,确保内容简练、无冗余。 |
2 结果与分析
2.1 实验环境与评价指标
表4 实验环境及参数配置信息Table 4 Experimental environment and parameter configuration information |
| 实验环境及参数 | 配置信息 |
|---|---|
| 操作系统 | Linux Ubuntu |
| Python | 3.10 |
| CUDA | 13.4 |
| GPU | 4*NVIDIA GeForce GTX 1080Ti |
| Torch | 1.21.3 |
| 显存 | 48 G |
| BM25算法参数 | = 1.5; b=0.75 |
| RRF算法参数 | = 60 |
| 模型回答超参数 | Temperature= 0.3 |
2.2 检索召回量Top K确定实验
表5 召回率与准确率随Top K的变化Table 5 Recall and precision vary with Top K |
| Top K | 准确率 | 召回率 | ||||||
|---|---|---|---|---|---|---|---|---|
| AHR | DVR | SQL | BM25 | AHR | SQL | DVR | BM25 | |
| 1 | 0.607 | 0.554 | 0.452 | 0.407 | 0.523 | 0.487 | 0.412 | 0.376 |
| 2 | 0.705 | 0.654 | 0.559 | 0.501 | 0.634 | 0.598 | 0.521 | 0.463 |
| 3 | 0.756 | 0.703 | 0.608 | 0.554 | 0.692 | 0.649 | 0.584 | 0.531 |
| 4 | 0.782 | 0.758 | 0.659 | 0.626 | 0.745 | 0.708 | 0.642 | 0.604 |
| 5 | 0.822 | 0.774 | 0.706 | 0.679 | 0.791 | 0.743 | 0.726 | 0.657 |
| 6 | 0.785 | 0.743 | 0.653 | 0.627 | 0.762 | 0.721 | 0.668 | 0.613 |
| 7 | 0.764 | 0.698 | 0.621 | 0.582 | 0.733 | 0.683 | 0.637 | 0.561 |
| 8 | 0.735 | 0.662 | 0.578 | 0.547 | 0.705 | 0.647 | 0.602 | 0.535 |

2.3 对比实验
2.3.1 基线模型对比
表6 农作物病虫害智能问答研究基线模型对比Table 6 Comparison of baseline models for Intelligent Q&A research on crop diseases and pests |
| RAG | Model | Recall | Precision | F 1 | Time/s |
|---|---|---|---|---|---|
| No RAG | Qwen1.5-7B-Chat | 0.725 | 0.703 | 0.714 | 1.02 |
| Naive RAG | Qwen1.5-7B-Chat | 0.751 | 0.735 | 0.743 | 1.13 |
| Self-RAG | Qwen1.5-7B-Chat | 0.823 | 0.845 | 0.834 | 3.42 |
| Adaptive-RAG | Qwen1.5-7B-Chat | 0.848 | 0.878 | 0.863 | 2.63 |
| AHR-RAG | Qwen1.5-7B-Chat | 0.872 | 0.896 | 0.884 | 2.43 |
| AHR-RAG | GLM | 0.865 | 0.868 | 0.866 | 2.71 |
| AHR-RAG | Baichuan | 0.867 | 0.857 | 0.862 | 2.68 |
表7 农作物病虫害智能问答研究公共数据集测试Table 7 Test on public dataset for intelligent Q&A research on crop diseases and pests |
| Method | Recall | Precision | F 1 | Time/s |
|---|---|---|---|---|
| 无(RAG) | 0.352 | 0.437 | 0.389 | 0.56 |
| Naive-RAG | 0.448 | 0.451 | 0.449 | 1.36 |
| Self-RAG | 0.528 | 0.496 | 0.511 | 3.54 |
| Adaptive-RAG | 0.601 | 0.562 | 0.581 | 2.46 |
| AHR-RAG | 0.709 | 0.583 | 0.640 | 3.23 |
2.3.2 不同查询类型实验
表8 农作物病虫害智能问答研究不同查询类型准确率测试Table 8 Accuracy testing for different query types of intelligent Q&A research on crop diseases and pests |
| 模型 | 比较型 | 判断型 | 选择型 |
|---|---|---|---|
| Qwen | 0.652 | 0.803 | 0.741 |
| Naive-RAG | 0.684 | 0.847 | 0.795 |
| Self-RAG | 0.725 | 0.882 | 0.836 |
| Adaptive-RAG | 0.754 | 0.899 | 0.852 |
| AHR-RAG | 0.883 | 0.925 | 0.898 |
2.3.3 不同复杂度查询实验
表9 单跳查询与多跳查询准确率测试Table 9 Accuracy test of single-hop and multi-hop queries |
| 模型 | 单跳查询 | 多跳查询 | ||||
|---|---|---|---|---|---|---|
| Recall | Precision | F 1 | Recall | Precision | F 1 | |
| Qwen | 0.681 | 0.722 | 0.701 | 0.469 | 0.461 | 0.465 |
| Naive-RAG | 0.750 | 0.797 | 0.773 | 0.603 | 0.593 | 0.598 |
| Self-RAG | 0.843 | 0.882 | 0.862 | 0.678 | 0.666 | 0.672 |
| Adaptive-RAG | 0.861 | 0.892 | 0.876 | 0.701 | 0.689 | 0.695 |
| AHR-RAG | 0.895 | 0.921 | 0.908 | 0.723 | 0.748 | 0.735 |
2.3.4 消融实验
表10 农作物病虫害智能问答研究消融实验结果Table 10 Results of ablation experiments of intelligent Q&A research on crop diseases and pests |
| 模型对比组 | Recall | Precision | F 1 | Time/s |
|---|---|---|---|---|
| AHR-RAG | 0.872 | 0.896 | 0.884 | 2.6 |
| NO chunk | 0.851 | 0.878 | 0.864 | 3.1 |
| NO Retrieval | 0.835 | 0.823 | 0.829 | 3.4 |
| NO Prompt | 0.867 | 0.883 | 0.875 | 2.5 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}