



0 引 言
近年来,图像处理技术在水稻秧盘播种检测领域得到了广泛应用。现有研究主要分为两类:一是基于传统机器视觉的方法;二是基于深度学习的方法[3]。传统机器视觉技术通常依赖阈值分割提取目标区域,并结合形态学运算进行后处理。例如,Dong等[4]采用色相-饱和度-亮度(Hue-Saturation-Lightness, HSL)色彩空间模型进行分割;Bai等[5]提出基于投票机制的分割方法。然而,这类方法易出现籽粒特征丢失,难以处理密集重叠的种子,导致漏检与误检率较高。相比之下,深度学习方法在复杂场景下展现出更好的适应性。Wang等[6]提出改进YOLOv5s算法实现秧盘稻种检测。Yan等[7]利用YOLOv5x模型对番茄穴盘种子进行识别,并建立了漏播检测与补种定位方法。
实例分割技术[8]能够在识别物体类别的同时精准勾勒其边界,即使在密集分布的情况下,也能有效克服基于锚框的目标检测方法在重叠目标上的不足,从而提升检测精度。作为目标检测[9]与语义分割[10]的结合,实例分割方法实现了对象类别识别与像素级分割的统一。典型代表,如掩码区域卷积神经网络(Region-Based Convolutional Neural Networks for Instance Segmentation, Mask R-CNN)[11]在快速区域卷积神经网络(Region-based Convolutional Neural Networks, Faster R-CNN)[12]基础上引入掩膜分支,实现目标检测向实例分割的拓展。该方案虽保留两阶段检测框架的高精度特性,但仍存在检测速度较慢的问题。随着Transformer模型[13]在计算机视觉领域的崛起,Mask2Former[14]在MaskFormer[15]架构中融入掩膜增强型Transformer模块,通过基于查询的机制直接生成分割掩膜,摆脱区域建议框依赖,在精度与速度层面实现双重突破。然而其参数化查询机制仍受训练数据语义范畴制约,对未见类别泛化能力有限。为满足更高精度与鲁棒性需求,视觉语言模型[16]通过融合视觉-文本信息提升实例分割性能,为后续研究开辟新范式。
目前,已有学者将实例分割算法应用于种子分割任务。Toda等[17]、Ye等[18]与Gao等[19]利用实例分割技术对图像中种子进行分割并提取其表型性状,然而,这类研究多在背景单一、籽粒特征相对单纯的条件下开展。与此同时,不少研究聚焦于复杂环境中的作物实例分割[20-22],尽管更贴近实际场景,但其目标对象普遍尺寸较大,分割难度相对较低。Xing等[23]探索了重叠条件下的种子实例分割问题,提出的方法在重叠区域的种子检测精度超过88%。Wu等[24]研究了密集分布水稻种子的实例分割,然相比秧盘环境其复杂度仍显不足。在秧盘场景中,种子常呈密集重叠状态且受土壤局部遮挡,传统实例分割方法在此条件下难以取得理想效果。因此,融合语言文本特征以提升此类复杂场景下的分割性能与鲁棒性具有重要研究价值。
综上所述,本研究提出一种基于实例分割算法的水稻育秧盘内的复杂背景下的播种效果检测。并通过与Mask R-CNN及Mask2Former这两种主流实例分割模型的性能对比,评估图文定位生成(Caption Grounding and Generation, CGG)模型的分割精度与适用性。本研究的成果可为水稻播种检测提供技术支撑,为智能化育秧盘监测奠定基础。
1 研究材料
1.1 稻种在气振式育苗精密播种装置中的处理流程
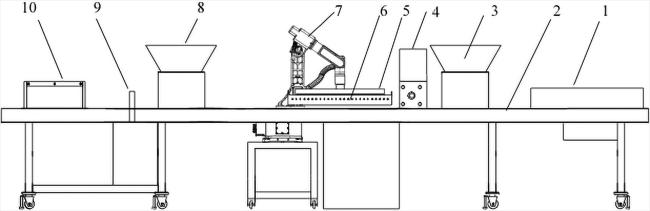
如图1所示,气振式育苗精密播种装置主要由供盘机、输送流水线、铺底土装置、吸种盘、供种盘、六轴机械臂、覆表土装置、洒水装置和叠盘机构等部分构成。其工作流程为:育秧盘经供盘机进入播种流水线,依次经过铺底土环节,随后由振动供种盘启动供种过程。六轴机械臂控制吸种盘完成下行吸种、水平移动至流水线上方,并将所吸附的稻种释放至育秧盘中。之后,育秧盘继续通过覆表土和洒水装置,最终输送至叠盘机进行收集。
1.2 数据集采集与制作
为实现对气振式育苗精密播种装置播种效果的检测,在播种与覆表土工序之间增设育秧盘图像采集装置,其结构如图2所示。该装置主要由相机、镜头、光源和漫反射式光电传感器组成。由于流水线运行过程中存在轻微抖动,为保障图像采集的稳定性,在流水线两侧搭建铝型材支架以提供支撑。中孔面光源固定于流水线正上方50 cm处,相机及镜头安装于光源中心位置。当育秧盘运行至采集区域下方时,漫反射光电传感器检测到育秧盘并触发相机拍摄,从而获取播种后的育秧盘图像。

实验所用水稻种子为广两优476品种,育秧基质由泥炭土与蛭石按3∶1配比制备,并控制湿度为65%~75%,以保证播种条件的一致性。从2023年4月初至2024年3月底,本研究在江苏大学农业测量大楼按时间段对播种后的育秧盘进行图像采集。为保证数据集的多样性并提高训练后模型的鲁棒性,使用了两种设备:工业相机 Basler acA1920-40uc(分辨率1 920×1 200,配套 Computar 12 mm 定焦镜头)固定于育秧盘上方进行垂直俯视拍摄,共采集2 532张图像;同时,使用分辨率为3 024×4 032的iPhone 13手机手持拍摄,共采集906张图像,以增加数据多样性。两种设备共计采集原始图像3 438张,用于构建高质量育秧盘稻种图像数据集。拍摄过程中采用环形LED光源(照度约15 000 lux),并通过漫射罩实现均匀照明,以减少阴影和反射对图像质量的影响。

2 研究方法
2.1 CGG的网络结构
CGG[27]的网络架构专注于开放词汇实例分割任务,通过联合对象定位和文本生成来处理图像中新类别的检测和分割。传统方法通过使用大规模的图像-文本对数据集训练模型来建立图像区域与文本词汇之间的一对一映射。CGG提出了一种更加高效的方法,通过对对象名词进行定向的匹配来提高学习效率。
为提升CGG网络在育秧盘图像中对密集遮挡稻种的语义理解能力,本研究引入大语言模型技术模块,并在网络结构中实现了多模态特征融合。首先,采用自举式语言-图像预训练(Bootstrapping Language-Image Pre-training, BLIP)模块对输入的原始育秧盘图像自动生成高层次语义描述,从而将视觉特征转化为可解释的文本表征。随后,利用双向编码器表示的Transformer(Bidirectional Encoder Representations from Transformers, BERT)模块对生成文本中的词汇进行上下文相关的向量编码,以获得语义一致性更强的词嵌入表示。此类语言嵌入与CGG主干网络所提取的视觉特征在特定融合层进行交互,实现了视觉与语言模态的深度融合与协同建模。该机制有效弥补了纯视觉特征在处理密集小目标及高遮挡区域时存在的语义表达能力局限,为稻种实例分割与计数任务提供了更鲁棒的判别基础。相较于传统仅依赖卷积视觉特征的方法,本研究通过将CGG与大语言模型有机集成,在复杂播种场景中显著增强了模型的语义感知能力与分割精度。
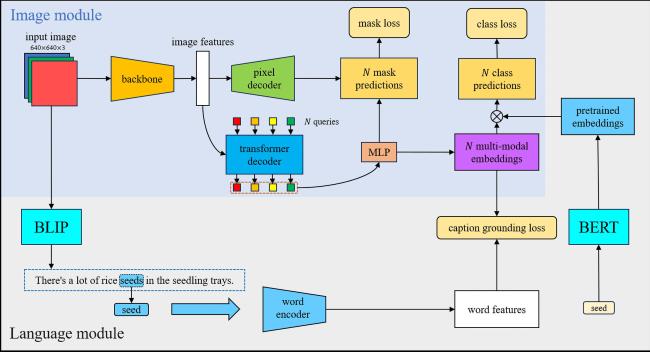
CGG网络架构图如图4所示,CGG主要分成图像模块和语言模块两个部分。在图像模块中,将原始的水稻种子的RGB图像转化成640×640×3的向量,输入到Mask2Former的基线当中。首先,图像会经过主干网络进行原始图像的特征提取得到图像特征,然后提取到的这些特征会被送入到Transformer解码器中处理。其得到的输出被输入到多层感知机(Multilayer Perceptron, MLP)中,该MLP会和像素级解码器的输出一起得到N个掩码预测。同时,将对象查询转换成N个多模态嵌入,然后计算这些嵌入和类别嵌入之间的相似度,从而得到N个类别的预测。在语言模块中,还分为两个部分:一部分是计算标题和图像的接地损失;另一部分是进行类别预测。得到的每张原始图像会经过BLIP模型生成5个标题文本信息,然后会从标题中提取到所需要的seed的名词。这些单词会经由单词编码器进行提取得到单词的特征,参与到接地损失的计算当中。在类别预测中,使用预训练好的BERT模型,直接对seed这个单词进行提取得到预训练的词向量。通过计算类别的损失、掩码的损失,以及文本图像对齐的损失[28],来不断地训练网络模型。最终训练得到的模型,即可对水稻种子图像进行预测分割。
2.2 网络核心改进模块
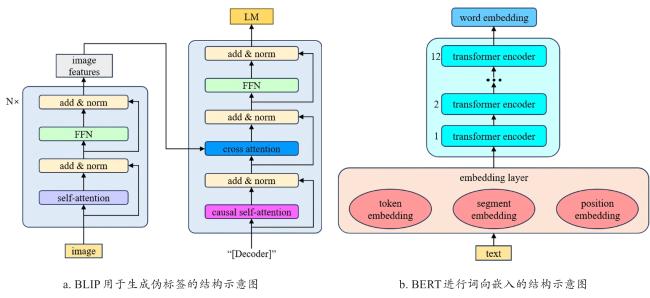
BLIP[29]是一种视觉-语言预训练模型,能够深度融合图像与文本信息,具备强大的跨模态理解与生成能力。该模型基于大规模图像-文本对进行训练,通过对比学习和自引导伪标注策略,有效捕捉视觉与语言之间的语义关联,并提升泛化性能。其核心优势在于能够根据输入图像生成流畅且准确的文本描述,不仅识别显著视觉特征,还能融合上下文语义信息,增强对复杂场景的理解能力。针对水稻种子图像数据量大、重复性高、人工标注成本高的问题,本研究利用预训练BLIP模型对每幅图像自动生成5组描述文本,以提供高质量语义监督。
BERT[30]是一种基于Transformer架构的语言表示模型,能够生成深层次上下文相关的词嵌入。本研究采用BERT基础版本,其结构包含12层Transformer编码器。在处理文本表征任务时,BERT依托其双向自注意力机制,同步整合词语的上下文信息,进而生成更具上下文依赖性的高质量语义表示。相比传统单向语言模型,BERT在多项自然语言处理任务中表现出更强的语义建模能力。本研究借助BERT对BLIP生成的文本描述进行编码,以获取具有上下文一致性的词向量表示。
3 结果与讨论
3.1 评价指标
本研究在对水稻种子图像进行检测分割的基础上,对水稻种子进行计数。所以前置的分割指标格外重要。本研究选择边界框的平均精度均值(Mean Average Precision, )和掩码的 作为主要评价指标。交并比(Intersection over Union, IoU)的阈值设置为0.5。如果标记多边形的IoU大于0.5,则将预测的边界框识别为真阳性(True Positive, TP),否则,将其归类为假阳性(False Positive, FP)。如果是模型漏检的目标,将其归类为假阴性(False Negative, FN)。精度是准确检测到的实例与检测到的实例总数的比率,而召回率是准确检测到的实例与数据集中总体实例的比率。 是衡量在不同置信阈值下的总体性能。最终,这些指标可以定义成公式(1)~公式(4) 。
式中: 为类别数; 为精确率; 为召回率; 为平均精度。
此外,为了系统评估模型的整体性能,本研究引入参数规模(Params)、计算复杂度(FLOPs)与推理速度(Frame rate)3项指标,分别用于反映模型规模、理论运算量和实际推理效率,如公式(5)~公式(7) 所示。
式中 为网络层数; 为第 层权重矩阵的元素数量; 为第 层偏置向量的元素数量。
式中 和 分别为输出特征图的高和宽,px; 和 分别为输入和输出通道数; 为卷积核尺寸;系数 表示一次乘加运算。
式中 为推理的图像数量,张; 为推理所用时间,s。
为了比较CGG和其他实例分割算法得出种子数量的结果,本研究考虑使用平均绝对误差(Mean Absolute Error, MAE)、平均绝对百分误差(Mean Absolute Percentage Error, MAPE)和误差均方根(Root Mean Square Error, RMSE)等指标进行评估。RMSE常用于衡量预测值与真实值之间的偏差,它能够反映模型的预测误差大小;MAE用于衡量预测值与真实值之间的平均绝对偏差;MAPE常用于评价预测值与真实值之间的相对误差。计算如公式(8)~公式(10) 所示。
式中 为第 个样本真实的数量,粒; 为第 个样本预测的数量,粒;n为样本总数,个。
3.2 试验与模型性能比较
本研究所采用的加速硬件为NVIDIA GeForce RTX 3060图形处理器,具备12 GB显存。模型构建所使用的编程语言为Python(版本3.8),深度学习框架为PyTorch(版本1.10),并结合CUDA(版本11.8)进行GPU加速。基础学习率设定为0.000 1,优化器选用ADAMW,动量参数设置为0.937。输入图像像素为640×640,训练轮数为200。
为评估所提出的CGG模型中改进模块的有效性,本研究在4种不同配置下进行了消融实验,结果如表1所示。基线模型(第1组)为未引入伪标签与语义嵌入的CGG模型;第2组在训练过程中加入由BLIP生成的伪标签,实验结果表明各项准确率指标均有明显提升,说明BLIP伪标签有效增强了训练数据的语义丰富性,从而提升了模型的泛化能力。第3组在基线模型中引入基于BERT的词向量嵌入,进一步提升了稻种分割精度,表明语义特征嵌入增强了模型在复杂密集场景下的识别能力。第4组同时结合BLIP伪标签与BERT词向量嵌入,在各项评估指标中均表现出最优性能,验证了两者在模型中的互补性,共同促进了分割精度的提升。该配置在计算开销上略有增加,其主要原因在于:一方面,BLIP伪标签的生成在训练阶段引入了额外的数据处理与语义对齐步骤;另一方面,BERT模块作为多层Transformer架构,增加了参数量和前向推理计算量,从而导致整体浮点运算量上升,推理帧率略有下降。尽管如此,该额外开销仍处于可接受范围内。此外,与基线模型相比,该组合策略在准确率方面提升超过3个百分点,展现出其在精量播种与智慧农业等实际应用中的显著优势。另外,下文中所提到的CGG均是加入了BLIP与BERT结构的模型。
表1 CGG模型在不同配置下的消融实验Table 1 Ablation study of the CGG model under different configurations |
| Group | BLIP | BERT | mAP50bb/% | mAP50seg/% | Prams/M | FLOPs/G | Frame rate/FPS |
|---|---|---|---|---|---|---|---|
| 1 | 87.5 | 88.3 | 33.9 | 225.1 | 15 | ||
| 2 | √ | 89.8 | 90.6 | 34.5 | 229.2 | 15 | |
| 3 | √ | 90.3 | 91.1 | 34.0 | 202.1 | 18 | |
| 4 | √ | √ | 90.7 | 91.4 | 35.7 | 207.5 | 18 |
为了验证所提出CGG模型的有效性,本研究选取了两类具有代表性的实例分割方法作为对比对象:一方面,Mask R-CNN作为经典的两阶段实例分割模型,能够在目标检测与分割精度上提供较强基准,但其推理速度较慢;另一方面,Mask2Former作为近年来基于Transformer 的先进模型,同时也是CGG的主要框架,其通过引入查询机制实现了精度与速度的兼顾,代表了实例分割领域的发展趋势。通过与这两类主流方法的对比,可以更全面地评估CGG模型在复杂育秧盘场景下的性能优势。
实验结果如表2所示,CGG模型在mAP50bb指标上达到90.7%,分别较Mask R-CNN和Mask2Former高出9.6和6.3个百分点;在mAP50seg指标上表现同样优异,达到91.4%,分别高出10.7与5.3个百分点。虽然CGG模型参数数量最少,但其计算开销相对较高。
表2 不同模型在稻种实例分割中的性能对比Table 2 Performance comparison of different models in rice seed instance segmentation |
| Model | Input size | mAP50bb/% | mAP50seg/% | Prams/M | FLOPs/G | Frame rate/FPS |
|---|---|---|---|---|---|---|
| Mask R-CNN | 640 | 81.1 | 80.7 | 44.1 | 137.7 | 13 |
| Mask2Former | 640 | 84.4 | 86.1 | 44.4 | 226.0 | 16 |
| CGG | 640 | 90.7 | 91.4 | 35.7 | 207.5 | 18 |
在推理速度方面,本研究对3种模型的帧率进行了量化对比。实验结果表明,Mask R-CNN 的推理速度为13 FPS,Mask2Former为16 FPS,而所提出的CGG模型达到18 FPS。在保证分割精度提升的同时,CGG在推理效率上也表现出一定优势,验证了其在实际应用场景中具备更高的可用性。
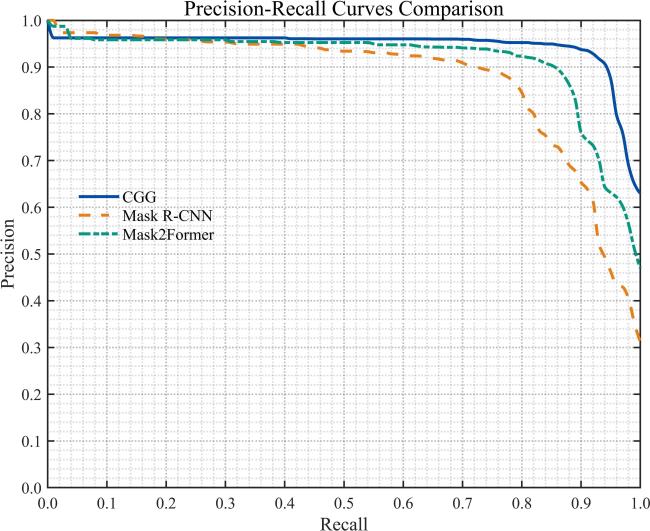
精确率-召回率(Precision-Recall, PR)曲线反映了模型在不同置信度阈值下的检测能力,其中较高的Precision表示较少的FP,较高的Recall表示较少的FN。这两个指标通常相互制约:提高精确率往往会降低召回率,反之亦然。曲线越接近右上角,说明模型在保持较高精确率的同时也具备较高的召回率,表明其整体性能更优。图6展示了3种模型的PR曲线。可以明显看出,CGG模型的曲线更接近右上角,相较于另外两种模型表现更佳,进一步验证了CGG模型在实例分割任务中的优越性能。
3.3 育秧盘内稻种实例分割结果分析

图8分别展示了Mask R-CNN、Mask2Former和CGG对育秧盘内同一个局部区域的分割结果,分别标注为a、b和c。每组中的子图(a)显示了在同一裁剪区域上的整体推理结果;每组子图(b)(c)(d)和(e)则对应于每组子图(a)中用边界框标记的4个局部区域,依序按从左至右、从上至下的顺序排列。

从图8各子图(a)可以看出,Mask R-CNN与Mask2Former存在较明显的漏检现象,其中漏检实例已在图中以青色圆圈标注,而CGG能完整识别该区域内的所有稻种,表明CGG模型在整体检测性能上表现更优。进一步观察各组中的子图(b)~(e),可发现Mask R-CNN在所有局部区域均存在漏检,尤其是子图8a(e)中的中间稻种,分割效果较差,几乎无明显掩膜覆盖,显示其分割不完整。Mask2Former在图8b(d)中实现了较为准确的分割,但在图8b(b)、图8b (c)和图8b(e)中仍有漏检现象,整体优于Mask R-CNN但仍存在不足。而CGG模型在4个子区域中均成功识别并分割出全部稻种,表现最为稳定。此外,尽管CGG在图8c(b)中对一粒被土壤部分遮盖的稻种分割置信度仅为0.78,略低于理想水平,但相较于Mask R-CNN与Mask2Former未能识别该种子的情况,CGG仍显示出更强的鲁棒性。这也反映出当稻种被部分覆盖时,实例分割仍面临一定挑战。
综上所述,在稻种密集重叠且背景复杂的场景中,与其他两个模型相比,CGG模型在实例分割任务中展现出最优的性能,具有更高的检测完整性与分割精度。
3.4 育秧盘穴播种子量测试结果
为了进一步验证CGG算法的有效性,本研究在真实流水线上连续进行20盘实际播种试验,采用不同的算法模型及人工检测方法,对每盘及每个穴位中的稻种数量进行统计,最终汇总每盘检测出的稻种总数,并计算各类型穴位在整盘(共434个穴位)中的比例,所得结果如表3所示。其中,误差指的是各算法模型与人工检测结果之间的直接数值差异,数值越接近0,表明算法检测结果越接近真实值。然而,该误差仅反映了表层的差距,未能充分考虑算法在某些特定情况下的识别偏差。例如,当算法将某一穴位检测为含1粒稻种,而实际该穴位可能包含2粒或3粒稻种时,仅以“1粒”计入误差将低估检测的实际偏差。因此,本研究进一步引入“真实误差”的概念,即将此类识别错误归入对应的真实类别(如2粒或3粒稻种),从而更准确地衡量检测算法与真实情况之间的偏差。
表3 不同检测方法下对单盘不同稻种穴位平均占比统计表 ( %)Table 3 Statistics on the average percentage of cavities of different rice species in a single disk |
| 单穴稻种数量 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 检测方法 | Mask R-CNN | 3.30 | 10.83 | 29.19 | 30.26 | 20.20 | 4.07 | 1.77 | 0.38 | |
| Mask2Former | 2.69 | 10.98 | 33.33 | 23.50 | 20.35 | 7.45 | 0.92 | 0.77 | ||
| CGG | 2.38 | 10.22 | 33.10 | 22.50 | 22.73 | 6.99 | 1.38 | 0.69 | ||
| 人工检测 | 2.07 | 9.52 | 32.41 | 23.12 | 22.12 | 8.76 | 1.08 | 0.92 | ||
| 真实误差 | Mask R-CNN | 0.00 | 1.23 | 3.69 | 4.84 | 7.83 | 5.99 | 1.15% | 0.54 | |
| Mask2Former | 0.00 | 0.61 | 3.69 | 3.53 | 3.46 | 3.15 | 0.46 | 0.15 | ||
| CGG | 0.00 | 0.31 | 2.46 | 2.84 | 3.15 | 2.23 | 0.69 | 0.23 | ||
| 误差 | Mask R-CNN | -1.23 | -1.31 | 3.23 | -7.14 | 1.92 | 4.69 | -0.69 | 0.54 | |
| Mask2Former | -0.61 | -1.46 | -0.92 | -0.38 | 1.77 | 1.31 | 0.15 | 0.15 | ||
| CGG | -0.31 | -0.69 | -0.69 | 0.61 | -0.61 | 1.77 | -0.31 | 0.23 | ||
结果显示,真实误差普遍大于表层误差,反映出前者在评估算法性能方面的更高敏感性与准确性。此外,在“真实误差”中,稻种检测为空穴时对应栏目的误差值为0,这是由于算法对于空穴位的识别均为正确。若某一穴位中实际存在1粒稻种但未被检测出,该错误将被统计至“1粒稻种”对应的真实类别中。
图9展示了3个模型在预测育秧盘中每个穴内稻种数量方面的混淆矩阵。结果表明,CGG模型在单个孔位上的预测准确率达到88%,明显高于Mask R-CNN(75%)和Mask2Former(85%)。在推理效率方面,CGG模型的帧率为18 FPS,优于Mask2Former的16 FPS和Mask R-CNN的13 FPS。这表明,CGG模型在保证较高预测准确率的同时,还具备更快的推理速度,从而在精度与效率之间实现了更优的平衡。综上,CGG模型在该任务中展现出显著的综合优势。
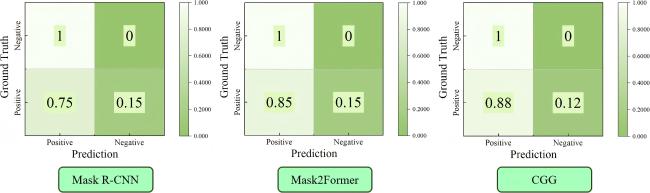
表4 不同模型针对单粒稻种的误差结果Table 4 Error analysis results for individual rice seeds by different models |
| Model | RMSE/颗 | MAE/颗 | MAPE/% |
|---|---|---|---|
| Mask R-CNN | 49.6 | 44.4 | 7.27 |
| Mask2Former | 30.9 | 26.4 | 5.21 |
| CGG | 16.8 | 13.7 | 2.46 |
4 结 论
本研究提出了一种面向育秧盘稻种检测的实例分割模型。该模型融合了CGG网络架构与大型语言模型,实现了秧盘图像中单粒稻种的高精度分割。本模型在mAP50bb和mAP50seg指标上分别达到90.7%与91.4%,显著优于Mask R-CNN与Mask2Former基准模型。同时,其RMSE、MAE和MAPE均低于对比模型,验证了模型在数量预测与误差控制上的优势。在效率表现上,所提模型在实现高精度分割的同时,仍保持了具有竞争力的推理速度,推理帧率达到18 FPS,展现出良好的实用性与可部署性。
本研究为精准农业实践及智能化补种系统的实施提供了可靠技术支撑。未来将进一步结合智能补种技术,解决育秧盘中漏播或播种量不足的问题,从而有效提升整体播种质量。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}