



0 引 言
藜麦(Chenopodium quinoa)原产于南美洲安第斯山脉地区,又称“南美黄金谷物”,已有5 000多年的种植历史[1]。因其卓越的营养价值和环境适应性,被联合国粮食及农业组织(Food and Agriculture Organization of the United Nations, FAO)誉为“最适宜人类的全营养食品”,并被美国航空航天局(National Aeronautics and Space Administration, NASA)列为宇航员太空食品之一。藜麦耐旱、耐盐碱、适应性强,适合在干旱或贫瘠的土地种植[2-4],一般种植于高海拔、温差大、种植面积广的区域,这些特点也使得传统田间调查方法面临效率低、覆盖面有限等挑战。
无人机遥感技术具有快速、便捷、高效的特点[5, 6],为作物长势评估提供了理想解决方案,已广泛应用于多种作物的调查研究,如彭小丹等[7]提出了基于无人机图像的密集苗木检测和计数方法,改进后的模型在测试集上的平均绝对误差、均方根误差和平均计数准确率分别为14.24株、22.22株和91.23%,准确实现密集种植苗木的检测和计数。杨福芹等[8]利用无人机搭载的高光谱相机和数码相机获取冬小麦的冠层光谱数据,根据所得数据构建起冬小麦氮营养指数遥感监测模型。DASH等[9]利用无人机热成像和多光谱影像评估印度恒河流域此类作物密集型地区的田间尺度作物水分状况,发现无人机估算的地表温度与实地测量高度相关(绝对差异≤±1 K),且植被温度状况指数与土壤湿度呈显著正相关(r = 0.6~0.81),证实无人机遥感可有效评估高分辨率作物水分状况。
基于无人机遥感的这些优势,越来越多研究者把无人机遥感作为主要技术手段引入藜麦长势评估中。井梅秀等[10]通过无人机多光谱影像进行藜麦长势分析,分析归一化植被指数、绿光归一化植被指数与归一化差值红边指数3种植被指数,证实藜麦全生育期3种指数呈现先升后降的健康生长态势,实现了对藜麦全生育期长势的快速、精准监测。RUIZ等[11]利用无人机多光谱传感器和地面光谱辐射计,研究了不同归一化植被指数的计算方法与地面实测归一化植被指数在藜麦受控实验和商业种植中的相关性,结果表明,在植被密度不足的区域,由于土壤背景干扰显著,应用归一化植被指数不可行。FLORES[12]基于无人机获取的多光谱图像,利用机器学习方法实现对藜麦进行分类。这些研究充分证明了无人机遥感技术在藜麦长势监测中的有效性和应用潜力。
近年来,农业目标检测领域的技术发展呈现出从传统人工调查向智能化、精准化快速演进的过程,将机器视觉运用到农业目标检测领域中,采用深度学习等算法获得理想检测精度,成为了技术应用的主要流派[13, 14]。将无人机遥感与先进的深度目标检测技术相结合,实现小麦穗、玉米雄穗、水稻穗等多种作物的大规模、高通量检测与计数也成为目标检测领域的热门方向。翁海勇等[15]基于无人机遥感和改进YOLOv7_Neckblast模型的水稻穗颈瘟抗性智能鉴定方法,通过引入压缩注意力机制和可变形卷积,在保持模型轻量化的同时将检测精度提升至89.2%,抗性评估准确率达86.67%。JIA等[16]基于无人机图像与融入坐标注意力机制的CA-YOLO模型,在实现96%检测精度的同时,显著提升了模型对复杂场景下玉米雄穗的检测鲁棒性。为解决单一尺度图像的检测局限,QIU等[17]提出了一种结合多源图像与基于注意力的内部尺度特征交互(Attention-based Intrascale Feature Interaction, AIFI)等机制的改进YOLOv5模型,有效提升了水稻穗检测的精度与鲁棒性。张晓勐[18]基于无人机遥感技术构建玉米雄穗数据集,提出Swin T-YOLO检测模型,实现95.11%的检测精度,并在Jetson Nano边缘设备上实现高速检测。高姻燕等[19]利用无人机红、绿、蓝三原色(Red, Green, Blue, RGB)图像与YOLOv3算法,开发出高效的小麦穗数检测方法,实现超过90%的识别准确率。
尽管利用无人机对主粮作物(如水稻、小麦)穗部进行高效检测的技术已较为成熟,但针对藜麦穗的精确目标检测研究仍属空白。由于藜麦穗多为分支状花序,形态结构复杂,且在成熟期易出现“垂头”现象,与主粮作物普遍具有的直立或棒状穗型差异显著,导致现有针对主粮作物的穗部检测方法难以直接迁移应用。此外,在无人机航拍场景下,藜麦穗的识别还面临两大挑战:一方面,藜麦种植密度高、穗部目标分布密集、彼此遮挡严重,同时,复杂的花序结构对特征提取的精细化程度提出了更高要求;另一方面,无人机机载平台存在存储容量有限、计算资源受约束等问题,对检测模型的高效性与轻量化提出了严峻考验。因此,针对上述难点,并着眼于目前尚无基于深度学习的藜麦穗目标检测研究的现状,本研究提出一种基于改进YOLOv8n的藜麦穗部检测方法,旨在构建一种精度高、速度快、参数量小、适于无人机平台部署的专用检测模型,以期为实现航拍场景下藜麦生长状态的精准监测提供技术参考,并为后续产量评估提供可靠依据。
1 材料与方法
1.1 藜麦穗数据集构建
1.1.1 数据采集
本研究构建的藜麦穗数据集,采自山东省东营市广饶县农高区藜麦种植基地(平均海拔13 m,118°39′12.20″E,37°17′56.34″N)。该区域地处暖温带,年平均气温12.3 ℃,年平均降水量587.4 mm,年平均无霜期为198 d,年日照极值2 881.4 h。选取DY160、DY154、DY1533、DY1534、DY1537、DY1540、DY1541、DY1381、DY1382、DY1383、DY1384和DY1385共12个藜麦育种品种作为试验材料,上述品种在试验田中采用均匀种植模式。采用大疆Inspire 2无人机作为遥感平台,搭载MicaSense Altum 6波段多光谱相机,获取高精度多光谱遥感数据。多光谱相机包括5个光谱通道(蓝、绿、红、红外、近红外,中心波长分别为475、560、668、717、840 nm,带宽分别为20、20、10、10、40 nm)和1个长波红外(Long Wave Infra Red, LWIR)通道(中心波长为11 um,带宽为6 um),多光谱相机各通道中心波长与半波宽如表1所示,在本研究的模型训练中仅使用了RGB通道数据。
表1 多光谱相机的通道参数Table 1 Channel parameters of the multispectral camera |
| 通道 | 中心波长/nm | 半波宽/nm | 反射率校正系数/% |
|---|---|---|---|
| Blue | 475 | 20 | 48.871 |
| Green | 560 | 20 | 49.028 |
| Red | 668 | 10 | 49.028 |
| Red-edge | 717 | 10 | 48.969 |
| NIR | 840 | 40 | 48.758 |
无人机设定飞行高度为25 m,飞行速度2 m/s,航向和旁向重叠率为80%,多光谱相机间隔1 s垂直拍摄,每幅图像的地面覆盖范围约为18.28 m×14.19 m。图像采集时间为2023年10月26—28日、31日和11月3日、7日、14日,于当地时间11∶00—14∶00进行数据采集。由于每幅图像的地面覆盖范围较大,包含藜麦株数过多,因此将原始图像均匀分割为244×244像素大小的图像,共得1 831幅图像。
1.1.2 数据增强以及标注
为确保数据质量,从采集到的1 831幅图像中筛选,剔除因过度曝光或欠曝光、运动模糊和离焦等问题导致的低质量图像,并剔除目视解译藜麦穗被遮挡率大于40%或边界截断的图像,针对遮挡率小于等于40%的目标,采用基于可见部分的矩形标注方案,标注框严格依据目标可见轮廓绘制,仅包围实际可见像素区域,不推测被遮挡部分,并在保证矩形框完整的前提下使其紧贴目标可见部分的外接矩形,最大限度减少背景干扰,最终筛选出113幅的高质量藜麦穗图像数据集,涵盖不同光照条件、地块位置及植株密度场景。
为了提高模型泛化能力和鲁棒性,对上述数据集系统实施了亮度调整、翻转与锐化3类数据增强操作,通过±50%的亮度调整模拟不同光照环境;采用0.5~1.0强度的拉普拉斯锐化增强图像边缘与细节,同时保持自然清晰度;以及通过100%水平翻转平衡样本方向性偏差。经增强后,数据集规模由113幅扩展至452幅,为模型训练提供了更丰富、更多样化的样本基础。数据集如图1所示。采用Labelimg软件对藜麦穗数据集中的藜麦麦穗进行标注。将标记后数据集按7∶3比例随机划分为训练集和测试集。

1.2 YOLOv8n基准模型
YOLOv8n是Ultralytics推出的YOLOv8系列中轻量化的模型(Nano版本),专为实时目标检测设计,适用于计算资源受限的场景(如边缘设备和移动端),在保持帧率(Frame Per Second, FPS)较高的同时,精度优于其他轻量级模型。其核心架构延续了YOLOv8的模块化设计,由主干网络Backbone层、特征融合Neck层和检测头Head层三大部分组成,具体结构如图2所示。
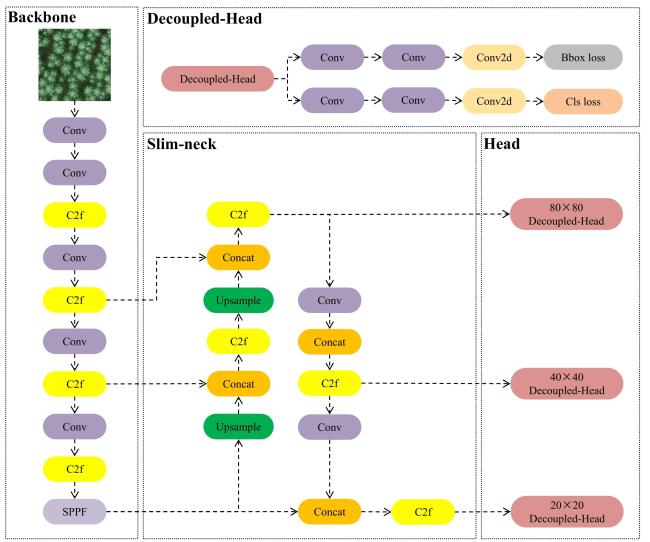
YOLOv8n的Backbone层由5个卷积模块、4个C2f模块和1个快速空间金字塔池化(Spatial Pyramid Pooling-Fast, SPPF)模块构成,卷积模块用于降采样和非线性化表示、C2f模块用于特征提取、SPPF模块采用空间金字塔的方法将不同尺寸的图像传入下1层,其中C2f可以针对藜麦穗特点进行替换,以增强其特征提取能力;Neck层的核心作用在于特征融合,它依托路径聚合网络-特征金字塔网络(Path Aggregation Network with Feature Pyramid Network, PAN-FPN)结构,对Backbone所输出的不同尺度特征图进行上采样与卷积操作,以完成融合,但这种方法的Neck层计算量较大且存在一定的计算冗余;Head层将Neck层输出的特征图进行处理最终产出模型的输出结果,在Head层前加入注意力机制可以使结果更加注意藜麦穗的关键区域,可以提升模型对藜麦穗的检测能力。
1.3 轻量化航拍藜麦穗目标检测模型设计
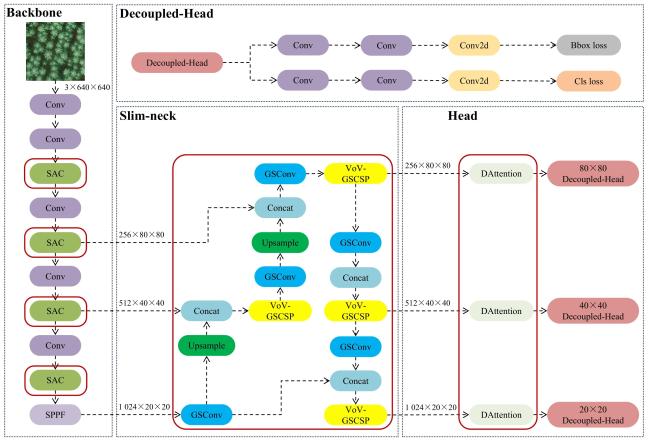
本研究基于YOLOv8n基础架构提出了一种改进的轻量化藜麦穗目标检测模型:YOLOv8n-SSND(YOLOv8n with Switchable Atrous Convolution, Slim Neck, and Deformable Attention),改进后网络结构如图3所示。首先,将Backbone部分的C2f模块替换成可切换空洞卷积(Switchable Atrous Convolution, SAC)模块,对相同输入特征应用不同的空洞率进行卷积,提高网络处理藜麦穗部不同尺度和复杂度特征时的适应性和准确性。其次,引入Slim-Neck替换特征融合层,采用组混洗卷积(Group Shuffle Convolution, GSConv)、组混洗卷积瓶颈层(Group Shuffle Convolution Bottleneck, GS Bottleneck)、基于一次聚合的组混洗卷积跨阶段部分网络(One-Shot Aggregation-based Group Shuffle Convolution Cross Stage Partial Network, VoV-GSCSP)模块构建Slim-Neck层,降低计算量和参数量的同时保证检测藜麦穗目标准确性。此外,在检测头前添加可变形注意力(Deformable Attention, DA)机制,使模型在做出最终预测之前,更加集中注意力于藜麦穗关键的特征,从而提升检测精度和鲁棒性。
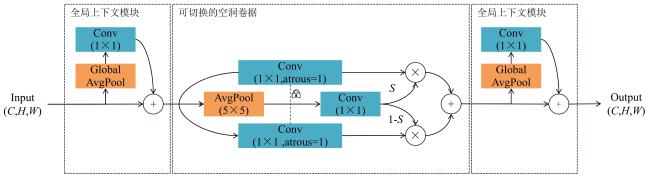
1.3.1 SAC可切换空洞卷积
在藜麦穗航拍图像中,由于不同藜麦品种的生长状况差异,藜麦穗部在图像中具有不同的尺度大小和不同的穗部形状,导致检测精度下降。因此本研究将YOLOv8n基准模型中的C2F模块替换为可切换空洞卷积(Switchable Atrous Convolution, SAC)模块,提高网络在处理不同穗部大小和形状的特征时的精确度。SAC模块是一种动态可切换的空洞卷积机制,其输入输出特征图维度相同,通过自适应选择不同空洞率的卷积核,并通过特别设计的开关函数来融合这些不同卷积的结果,使得网络能够更灵活地适应不同尺寸的藜麦穗部的特征,从而更准确地识别和分割图像中的藜麦穗[20-22]。SAC模块的实现如图4所示。
传统卷积模块可以表示为公式(1) 。
式中:y为输出的融合特征图; 为输入特征图; 为卷积核权重;r C2F为空洞率。SAC模块可以用公式(2) 表示。
式中: 为SAC模块的超参数; 为可训练参数的偏移量; 为开关函数。
1.3.2 引入Slim-Neck特征融合层
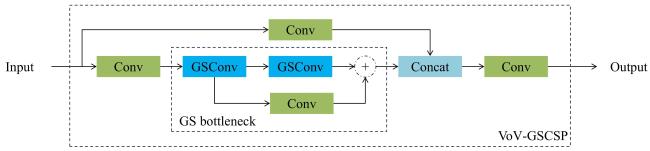
为了提高推理速度并减小计算量和模型大小,本研究将YOLOv8n原特征融合层替换为模块化设计的Slim-Neck轻量特征融合层。YOLOv8n在网络中使用大量的标准卷积提取图像特征,会消耗大量的时间[23]。而藜麦穗目标检测可能受光照、种植密度、叶片间的相互遮挡等复杂环境的影响,对模型的检测速度和检测精度都有很高的要求,因此将一种新范式设计Slim-Neck融入YOLOv8n网络中。Slim-Neck模块是利用GSConv模块和VoV-GSCSP模块设计的轻量化结构,在保持准确性的同时减少模型的复杂度。
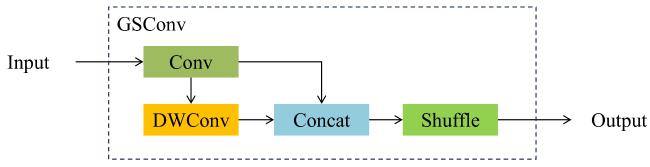
GSConv模块用于减少藜麦穗目标检测模型的运行时间,其结构如图5所示,输入图像经过特征提取层得到初步特征图,这些特征图进入GSConv模块,先执行分组卷积,再进行深度可分离卷积,接着利用shuffle操作混合不同通道的信息,增强跨通道交互效果,经过这些变换后的特征会被用于后续的目标检测或其他任务中。其中,GS bottleneck模块是基于传统卷积模块和GSConv模块的一种增强模块,大幅降低计算成本的同时,保持甚至提升特征表达能力。
1.3.3 添加DA机制
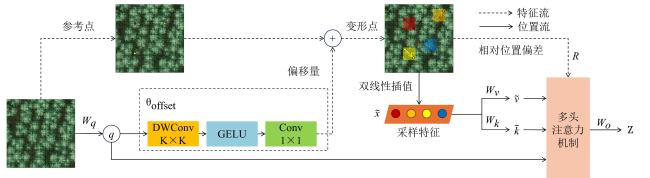
卷积神经网络采用固定的卷积核来进行采样,因此在对形状不固定的特征图进行建模时存在一定缺陷。现有的视觉Transformer在建模长距离依赖时,存在计算成本高、信息冗余等问题。同时,为了进一步增强对藜麦不同穗部形状的处理能力,本研究在模型的探测头前引入DA机制,通过动态采样,关注藜麦穗部的关键区域,提高检测的精度。
DA是一种结合可变形卷积(Deformable Convolution)和自注意力机制(Self-attention)的混合模块,其核心思想是通过动态学习特征图中每个位置的偏移量,自适应调整感受野,从而更精准地聚焦目标的关键区域。相较于传统注意力机制,DA的优势在于:通过偏移量学习,使模型能适应目标的形变、遮挡等复杂场景;数据依赖的注意力机制能够动态选择采样点,自适应地关注重要区域;通过共享偏移量,减少了计算开销,同时保持了线性空间复杂度。
将特征图 作为输入,然后生成1个均匀的参考点网格 ,其中, ,H为特征图的高,W为特征图的宽, 为网格大小从输入特征图大小向下采样的因子。为了获得每个参考点的偏移量,对特征图进行线性投影以获得查询标记q,然后将其输入1个轻量级子网络偏移量 网络,以生成参考点p的偏移量∆p。具体来说, 子网络包含两个非线性激活的卷积模块。首先,输入特征经过深度卷积以捕捉局部特征。然后,采用高斯线性误差单元(Gaussian Error Linear Unit, GELU)激活和1×1卷积来计算偏移量。在生成参考点的偏移量后,使用采样函数,如公式(3) 所示。
式中: ;( , )为 上的所有位置; 和 为对应参考点的偏移量。
用双线性插值法对变形点位置的特征进行采样,然后投影为键值 和值 。接下来,对 进行标准的多头关注,其中有M个头的多头注意力模块如公式(4)~公式(6) 所示。
式中: , , , 为投影矩阵;q为查询标记; 为采样特征; (⋅)为softmax函数; 为每个头部的维度; 为第m个注意力头的输出; 为查询、变形键和值嵌入。
1.4 评价指标
为了准确评估模型的有效性,本研究采用精确率(Precision, P)、召回率(Recall, R)、计算量GFLOPs、平均精度均值(Mean Average Precision, mAP)、FPS、模型体积作为模型性能的评价指标。其中,在评价mAP时,检测框与真实框的重叠度(Intersection over Union, IoU)阈值为0.5[26]。精确率、召回率、平均精度和平均精度均值的计算如公式(7)~公式(10) 所示。
式中: 为被正确检测到的藜麦穗的数量; 为背景被错误识别成藜麦穗的数量; 为漏检的藜麦穗的数量; 为召回率 处经过插值后的精确率; 为目标的总数; 为第 个类别的平均精度。
目标检测算法的性能主要涵盖分类能力和定位能力两个方面,最直观的度量方式是mAP值。mAP值越小代表算法的准确性较低,反之表示算法的精确性更高。另外,检测速度通常用模型帧率来衡量,更高的帧率值意味着模型能够处理更多数据,提供更强的实时性[27]。
1.5 实验环境与参数设置
本研究实验在同一台笔记本电脑上,搭载Windows11操作系统,CPU配置为13th Gen Intel(R) Core(TM)i7-13620H。GPU配置为NVIDIA GeForce RTX 4060 Laptop显卡,显存为8 G。具体的软件环境为Python 3.9,CUDA版本为11.8,Pytorch版本为2.5.1。改进YOLOv8n模型训练的超参数设置如下,初始学习率设置为0.01,输入图像像素大小为640×640,Batch Size为16,Epochs为100,优化器设置为Auto,开启自动混合精度进行训练,未采用余弦学习率调度器,其他参数均为官方推荐参数。
2 结果与分析
2.1 检测结果热力图可视化
为进一步了解YOLOv8n-SSND对藜麦穗部的检测效果,将改进模型的检测结果与原基准模型的检测结果通过热力图呈现,如图8所示。通过对比,改进模型比原基准模型显著减少了误检和漏检的情况,同时对于图像边缘处的不完整藜麦穗部的检测能力显著提高。这些数据充分证明,本研究的改进方案在检测效果、精度、速度和模型复杂度多个维度实现了最佳平衡。

2.2 DA与其他注意力机制的对比
为系统验证本研究所采用的DA模块性能,本研究选取了当前具有代表性的两种注意力机制——混合注意力(Hattention, HA)与可变形大核注意力(Deformable Large-Kernel Attention, DLKA)作为对比基准。通过在相同实验环境下对YOLOv8n模型进行模块替换与性能测试,从模型大小、计算效率、检测精度等多个维度进行综合评估,以确保比较的公平性与结论的可靠性,实验结果如表2所示。
表2 DA与其他注意力机制对航拍藜麦穗目标检测模型中的对比Table 2 Comparison of DA and other attention mechanisms in the aerial photography-based Chenopodium quinoa willd spike target detection model |
| 模型 | 模型大小/MB | P/% | R/% | mAP50/% | 计算量/GFLOPs | Params/M | FPS/(帧/s) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-DA | 6.8 | 89.1 | 86.7 | 93.6 | 8.3 | 3.3 | 87.7 |
| YOLOv8n-HA | 16.9 | 89.8 | 85.7 | 93.4 | 8.1 | 8.2 | 294.1 |
| YOLOv8n-DLKA | 9.8 | 89.0 | 85.9 | 93.2 | 9.5 | 4.8 | 185.2 |
HA采用并行混合注意力架构,通过构建通道与空间双路径实现特征增强。其通道路径通过全局池化与全连接层学习通道间依赖关系,空间路径则通过卷积操作生成空间注意力图,最终通过加权融合机制整合双路径输出。这种设计在保持较高精度的同时显著提升了计算效率,如表2中YOLOv8n-HA实现294.1帧/s的优异表现。
DLKA创新性地将可变形卷积与大核卷积相结合,通过7×7及以上尺寸的大卷积核构建基础感受野,同时引入可变形机制使采样点能够根据特征内容自适应偏移。这种设计既保留了大规模感受野对长距离依赖的捕获能力,又增强了对不规则目标几何变换的适应性,在精度与速度间取得了良好平衡。
相比之下,融合DA模块的YOLOv8n模型展现出更为均衡的综合性能优势。在检测精度方面,该模型取得了93.6%的mAP50,较HA与D-LKA分别提升0.2和0.4个百分点;在模型复杂度方面,其6.8 MB的模型体积显著小于HA的16.9 MB和DLKA的9.8 MB;同时在计算效率方面,DA以更低的参数量和更优的FPS表现突出。实验结果表明,DA在精度保持、模型轻量化与计算效率3个关键维度上实现了最佳平衡,尤其适合部署于计算资源严格受限的无人机机载平台。
2.3 消融实验
在进行消融实验之前,首先对YOLOv8n、YOLOv11n、YOLOv12n这3个目标检测模型的基准模型进行了对比实验,结果如表3所示。
表3 航拍藜麦穗目标检测基准模型对比实验Table 3 Aerial photography-based comparison experiment of benchmark models for Chenopodium quinoa Willd grain target detection |
| 模型 | 模型大小/MB | P/% | R/% | mAP50/% | 计算量/GFLOPs | Params/M | FPS/(帧/s) |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 6.3 | 90.4 | 84.0 | 92.5 | 8.1 | 3.0 | 131.6 |
| YOLOv11n | 5.5 | 89.6 | 85.0 | 93.4 | 6.3 | 2.6 | 59.5 |
| YOLOv12n | 5.4 | 87.9 | 83.9 | 92.2 | 5.8 | 2.5 | 243.9 |
实验结果表明,YOLOv8n在精确率(90.4%)上表现更为出色,这表明其对于正样本的判断更为谨慎,误检率较低。而YOLOv11n则在综合性能上展现出更大优势,其平均精度、召回率、模型大小、计算复杂度,以及参数量均优于YOLOv8n。鉴于目标检测任务中mAP是衡量模型综合性能的核心指标,更高的mAP50意味着模型在各种IoU阈值下拥有更稳定和准确的平均检测能力。因此,本研究选择mAP50值更高的YOLOv11n和YOLOv8n一同进行后续深入的消融实验。
本研究提出的3种改进方法分别是SAC、DA、SN,为了验证它们对YOLOv8n模型的性能优化有效,对不同的改进部分进行消融实验,实验的结果如表4所示。
表4 基于YOLOv8n的航拍藜麦穗目标检测模型消融实验Table 4 Ablation experiments on the aerial Chenopodium quinoa Willd spike target detection model based on by YOLOv8n |
| YOLOv8n | SAC | Slim-Neck | DA | 模型大小/MB | P/% | R/% | mAP50/% | 计算量/GFLOPs | Params/M | FPS/(帧/s) |
|---|---|---|---|---|---|---|---|---|---|---|
| √ | × | × | × | 6.3 | 90.4 | 84.0 | 92.5 | 8.1 | 3.0 | 131.6 |
| √ | √ | × | × | 6.9 | 89.0 | 87.6 | 93.8 | 7.4 | 3.3 | 108.7 |
| √ | × | √ | × | 5.9 | 87.9 | 84.9 | 92.7 | 7.3 | 2.8 | 204.1 |
| √ | × | × | √ | 6.8 | 89.1 | 86.7 | 93.6 | 8.3 | 3.3 | 87.7 |
| √ | √ | √ | × | 6.5 | 89.6 | 85.7 | 93.4 | 6.6 | 3.4 | 208.3 |
| √ | √ | × | √ | 7.5 | 89.6 | 86.9 | 93.9 | 7.6 | 3.6 | 270.3 |
| √ | × | √ | √ | 6.5 | 88.3 | 86.8 | 93.2 | 7.5 | 3.1 | 227.3 |
| √ | √ | √ | √ | 7.1 | 90.8 | 86.2 | 94.3 | 6.8 | 3.4 | 166.7 |
|
可以看出,单独引入SAC模块使mAP50提升1.3个百分点,FPS提升17.4%;DA模块在保持精度的同时召回率显著提高了2.7个百分点;而Slim-Neck结构则展现出显著的轻量化效果,将模型体积压缩了6.3%,并将参数量降低了0.2 M,实现了204.08帧/s的极速推理。3个模块联合的最终模型将mAP50提升1.8个百分点到达94.3%的同时,计算量降低16%,达到6.8 GFLOPs,FPS提高26%,达到166.7帧/s,验证了各改进组件的互补性和协同方案的技术优势。该优势源于3个模块在功能上的高效互补,Slim-Neck作为轻量化基石,通过优化特征融合结构显著压缩了模型复杂度,为引入更强力但稍显复杂的模块腾出了计算预算,SAC模块则在此基础上增强了网络在处理不同穗部大小和形状特征时的精确度,而DA模块通过对藜麦穗部关键区域进行聚焦。最终,这3个模块共同构建了一个“轻量骨架-精准感知-区域聚焦”的协同体系,在藜麦穗部检测任务中实现了精度、轻量与速度的均衡提升。
将3种改进方法应用于YOLOv11n目标检测模型,进一步验证改进方法的性能优化有效,对不同的改进部分进行消融实验,实验的结果如表5所示。
表5 基于YOLOv11n的航拍藜麦穗目标检测模型消融实验Table 5 Ablation experiments on the aerial Chenopodium quinoa Willd spike target detection model based on by YOLOv11n |
| YOLOv11 | SAC | Slim-Neck | DA | 模型大小/MB | P/% | R/% | mAP50/% | 计算量/GFLOPs | Params/M | FPS/(帧/s) |
|---|---|---|---|---|---|---|---|---|---|---|
| √ | × | × | × | 5.5 | 89.6 | 85.0 | 93.4 | 6.3 | 2.6 | 59.5 |
| √ | √ | × | × | 7.8 | 90.4 | 85.8 | 93.8 | 6.5 | 3.7 | 166.7 |
| √ | × | √ | × | 5.9 | 88.9 | 84.7 | 92.7 | 6.4 | 2.8 | 217.4 |
| √ | × | × | √ | 6.1 | 89.7 | 83.3 | 92.2 | 6.5 | 2.9 | 222.2 |
| √ | √ | √ | × | 8.9 | 89.0 | 86.1 | 93.2 | 7.8 | 4.2 | 125.0 |
| √ | √ | × | √ | 8.4 | 89.7 | 85.1 | 93.6 | 6.7 | 4.0 | 131.6 |
| √ | × | √ | √ | 6.5 | 88.4 | 85.7 | 93.2 | 6.6 | 3.1 | 172.4 |
| √ | √ | √ | √ | 9.4 | 89.2 | 85.9 | 93.6 | 8.1 | 4.5 | 137.0 |
|
对YOLOv11n的消融实验结果进行分析可得,本研究提出的改进方法在该新型架构上依然有效,但其收益特性与在YOLOv8n上有所不同。单独引入SAC模块使mAP50提升了0.4个百分点(从93.4%至93.8%),这验证了其增强模型感受野、捕获多尺度信息的能力在YOLOv11n架构上依然具有稳健的有效性。然而,Slim-Neck和DA模块未能带来预期的正向提高,其根本原因在于YOLOv11n本身相较于YOLOv8n进行了深刻的架构优化。具体而言,YOLOv11n引入了全新的C3k2模块和嵌入金字塔挤压注意力的跨阶段部分网络(CCross Stage Partial Network with Pyramid Squeeze Attention, C2PSA)模块,替代了YOLOv8n中的C2f模块,同时YOLOv11n已经在SPPF层后集成了其自研的C2PSA注意力模块,该模块已有效地增强了模型对复杂场景的适应能力。这些改进本身就极大地提升了特征提取效率,显著减少了模型参数和计算量。这意味着,旨在压缩Neck部分复杂度的Slim-Neck模块与YOLOv11n本身高度精简和优化的新结构存在功能冗余,其轻量化效果的边际收益因此大幅降低。同样地,DA机制模块旨在增强模型对关键特征的关注能力,但也因此,再额外引入DA模块不仅造成了功能上的重叠,还可能在一定程度上破坏了原架构中精心设计的特征流,导致计算成本增加却未能带来显著的性能增益,甚至引起轻微的精度下降。最终,3模块联合的模型在YOLOv11n上达到了93.6%的mAP50,仍比基线提升了0.2个百分点,这表明本研究的改进组合仍具有一定的互补性和有效性。
2.4 对比实验
为了充分验证改进YOLOv8n模型对航拍图像中的藜麦穗的检测能力,将改进后的YOLOv8n-SSND模型与主流检测模型YOLOv11n、YOLOv12n、YOLOv7、YOLOv5s、SSD(Single Shot MultiBox Detector)、Fast R-CNN(Fast Region-based Convolutional Neural Network),以及YOLOv11n-SSND进行对比实验,实验结果如表6所示。
表6 不同模型检测的航拍藜麦穗目标性能结果Table 6 Comparison performance results of different models for target detection of Chenopodium quinoa Willd grains |
| 模型 | 模型大小/MB | P/% | R/% | mAP50/% | 计算量/GFLOPs | Params/M | FPS/(帧/s) |
|---|---|---|---|---|---|---|---|
| YOLOv8n-SSND | 7.1 | 90.8 | 86.2 | 94.3 | 6.8 | 3.4 | 166.7 |
| YOLOv11n-SSND | 9.4 | 89.2 | 85.9 | 93.6 | 8.1 | 4.5 | 136.7 |
| YOLOv11n | 5.5 | 89.6 | 85.0 | 93.4 | 6.3 | 2.6 | 250.0 |
| YOLOv12n | 5.4 | 87.9 | 83.9 | 92.2 | 5.8 | 2.5 | 243.9 |
| YOLOv7 | 71.3 | 88.0 | 86.4 | 92.9 | 103.2 | 36.9 | 53.2 |
| YOLOv5s | 3.9 | 89.4 | 86.2 | 92.3 | 4.1 | 7.0 | 119.1 |
| SSD | 90.6 | 79.0 | 62.6 | 71.2 | 30.4 | 23.3 | 135.3 |
| Fast R-CNN | 108.0 | 79.3 | 74.9 | 74.7 | 369.7 | 41.3 | 13.7 |
实验数据表明,改进模型YOLOv8n-SSND在mAP50指标上达到94.3%,相较于YOLOv11n-SSND、YOLOv11n、YOLOv12n、YOLOv7、YOLOv5s、SSD、Fast R-CNN和YOLOv8n模型,分别提升0.7、0.9、2.1、1.4、2.0、23.1、19.6、1.8个百分点。在保持高精度的同时,改进模型的FPS达到166.67帧/s,是YOLOv7的3.1倍;且模型体积仅7.1 MB,远小于YOLOv7的71.3 MB;模型参数量仅为3.4 M,远低于YOLOv7的36.9 M。与轻量级YOLOv5s相比,改进模型在mAP50上提升2.0个百分点的同时,参数量减少约52%,计算效率仍保持竞争优势。
相较于最新的YOLOv11n和YOLOv12n模型,虽然YOLOv11n模型的mAP50、模型体积、计算量,以及FPS略微优于YOLOv8n模型,但以YOLOv11n为基准模型加入SAC、DA、Slim-Neck3种改进方法形成的YOLOv11n-SSND模型,除了模型体积略小于YOLOv8n-SSND模型,精确率、召回率、mAP50、计算量、参数量和FPS等指标上都不及YOLOv8n-SSND模型。YOLOv12n的精确度和mAP50均低于YOLOv8n模型。总体而言,YOLOv8n-SSND相较于其他主流目标检测模型具有明显优势,充分验证其对航拍图像中的藜麦穗部的检测能力。
3 结 论
本研究针对无人机航拍场景中,藜麦穗部性状目标密集、特征复杂,以及无人机平台机载算力受限等问题,提出一种基于YOLOv8n模型改进后的YOLOv8n-SSND目标检测模型,实现了在自然环境中对藜麦穗目标的准确检测。相对于原模型,YOLOv8n-SSND主要做了3点改进:1)在Backbone中构建SAC模块,通过动态调整卷积核的空洞率,使模型能够自适应地捕捉不同尺度的特征信息。2)引入Slim-Neck特征融合层,采用GSConv替代标准卷积,通过分组可分离卷积和通道重排技术,在保持特征表达能力的同时,降低Neck部分的计算量。特别设计的VoV-GSCSP模块实现了跨阶段特征的高效融合,同时大幅度压缩了模型体积。3)在检测头前添加DA机制,通过预测特征点的动态偏移量,使模型能够更精准地聚焦于藜麦穗部的关键区域。
结果表明,改进后的YOLOv8n模型训练效果更为理想,藜麦穗部的检测重复率,以及误检率得到显著下降,同时对于图片边缘处的不完整藜麦穗的检测能力显著提高。改进模型对测试集的检测精确度达到94.3%,召回率达到86.2%,表明其能准确识别绝大多数藜麦穗目标,同时有效降低误检率。此外,模型在轻量化方面表现优异,计算量仅为6.8 GFLOPs,模型大小压缩至7.1 MB,并结合166.67帧/s的高帧率处理能力,充分满足无人机机载平台对低算力、低存储和高实时性的严苛要求,为航拍场景下的藜麦穗高效检测提供了可行的轻量化解决方案。在后续研究中,将针对藜麦不同品种的穗部特点,提高对其他藜麦品种的检测能力,从而提出更全面的藜麦目标检测模型。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}