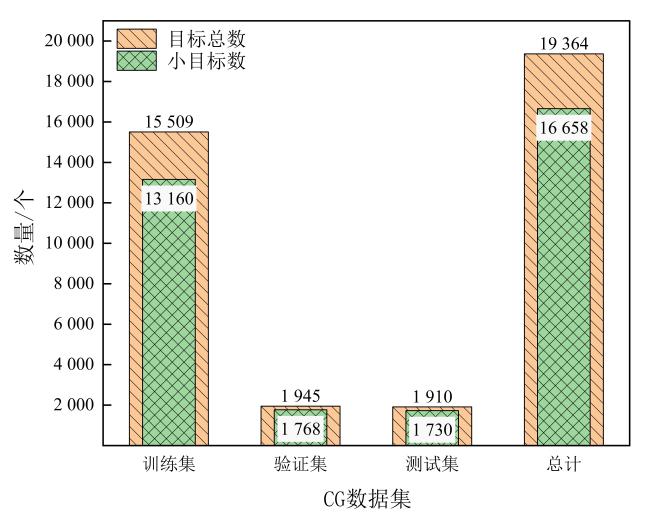
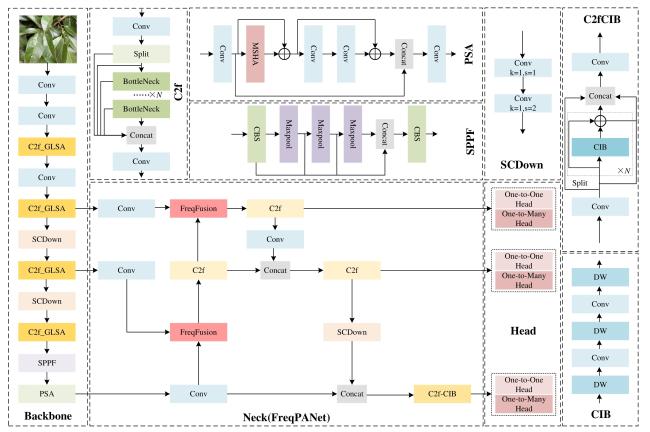
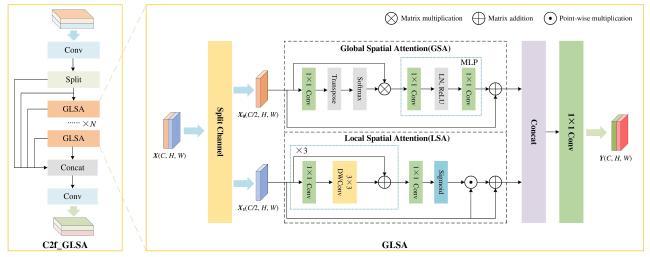
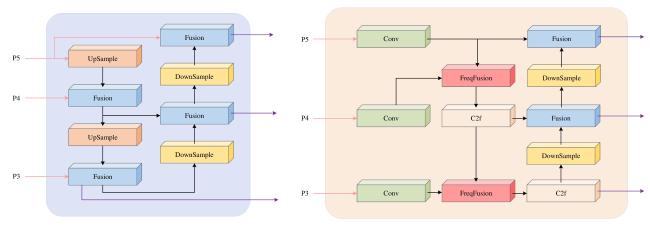
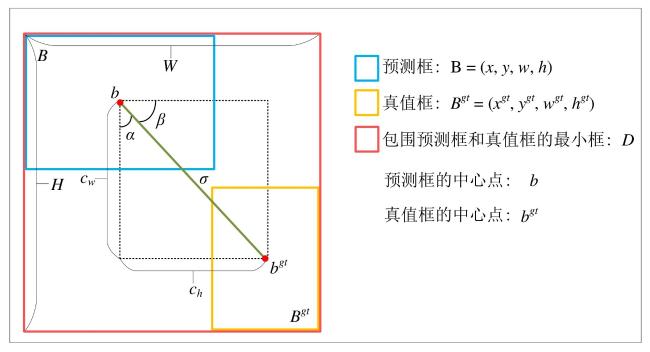
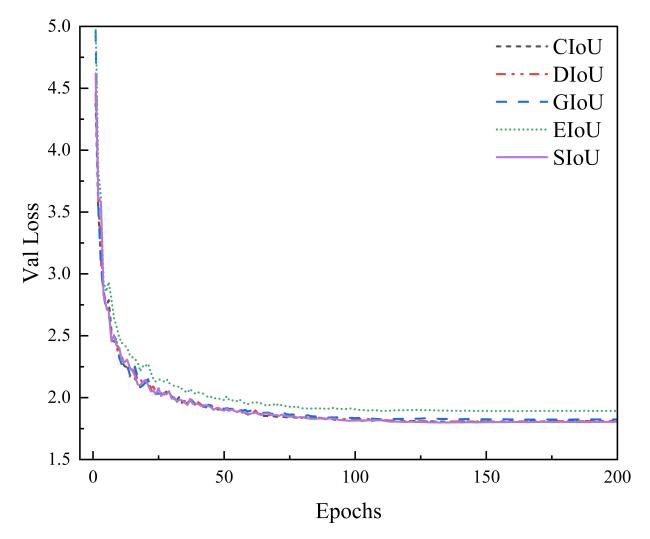
[Objective] The accuracy of identifying litchi pests is crucial for implementing effective control strategies and promoting sustainable agricultural development. However, the current detection of litchi pests is characterized by a high percentage of small targets, which makes target detection models challenging in terms of accuracy and parameter count, thus limiting their application in real-world production environments. To improve the identification efficiency of litchi pests, a lightweight target detection model YOLO-LP (YOLO-Litchi Pests) based on YOLOv10n was proposed. The model aimed to enhance the detection accuracy of small litchi pest targets in multiple scenarios by optimizing the network structure and loss function, while also reducing the number of parameters and computational costs. [Methods] Two classes of litchi insect pests (Cocoon and Gall) images were collected as datasets for modeling in natural scenarios (sunny, cloudy, post-rain) and laboratory environments. The original data were expanded through random scaling, random panning, random brightness adjustments, random contrast variations, and Gaussian blurring to balance the category samples and enhance the robustness of the model, generating a richer dataset named the CG dataset (Cocoon and Gall dataset). The YOLO-LP model was constructed after the following three improvements. Specifically, the C2f module of the backbone network (Backbone) in YOLOv10n was optimized and the C2f_GLSA module was constructed using the global-to-local spatial aggregation (GLSA) module to focus on small targets and enhance the differentiation between the targets and the backgrounds, while simultaneously reducing the number of parameters and computation. A frequency-aware feature fusion module (FreqFusion) was introduced into the neck network (Neck) of YOLOv10n and a frequency-aware path aggregation network (FreqPANet) was designed to reduce the complexity of the model and address the problem of fuzzy and shifted target boundaries. The SCYLLA-IoU (SIoU) loss function replaced the Complete-IoU (CIoU) loss function from the baseline model to optimize the target localization accuracy and accelerate the convergence of the training process. [Results and Discussions] YOLO-LP achieved 90.9%, 62.2%, and 59.5% for AP50, AP50:95, and AP-Small50:95 in the CG dataset, respectively, and 1.9%, 1.0%, and 1.2% higher than the baseline model. The number of parameters and the computational costs were reduced by 13% and 17%, respectively. These results suggested that YOLO-LP had a high accuracy and lightweight design. Comparison experiments with different attention mechanisms validated the effectiveness of the GLSA module. After the GLSA module was added to the baseline model, AP50, AP50:95, and AP-Small50:95 achieved the highest performance in the CG dataset, reaching 90.4%, 62.0%, and 59.5%, respectively. Experiment results comparing different loss functions showed that the SIoU loss function provided better fitting and convergence speed in the CG dataset. Ablation test results revealed that the validity of each model improvement and the detection performance of any combination of the three improvements was significantly better than the baseline model in the YOLO-LP model. The performance of the models was optimal when all three improvements were applied simultaneously. Compared to several mainstream models, YOLO-LP exhibited the best overall performance, with a model size of only 5.1 MB, 1.97 million parameters (Params), and a computational volume of 5.4 GFLOPs. Compared to the baseline model, the detection of the YOLO-LP performance was significantly improved across four multiple scenarios. In the sunny day scenario, AP50, AP50:95, and AP-Small50:95 increased by 1.9%, 1.0 %, and 2.0 %, respectively. In the cloudy day scenario, AP50, AP50:95, and AP-Small50:95 increased by 2.5%, 1.3%, and 1.3%, respectively. In the post-rain scenario, AP50, AP50:95, and AP-Small50:95 increased by 2.0%, 2.4%, and 2.4%, respectively. In the laboratory scenario, only AP50 increased by 0.7% over the baseline model. These findings indicated that YOLO-LP achieved higher accuracy and robustness in multi-scenario small target detection of litchi pests. [Conclusions] The proposed YOLO-LP model could improve detection accuracy and effectively reduce the number of parameters and computational costs. It performed well in small target detection of litchi pests and demonstrated strong robustness across different scenarios. These improvements made the model more suitable for deployment on resource-constrained mobile and edge devices. The model provided a valuable technical reference for small target detection of litchi pests in various scenarios.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}