



0 引 言
目前,牛只个体识别技术主要分为接触式与非接触式两大类。常见的接触式识别包括耳标、项圈、截耳法、烙印、无线射频识别(Radio Frequency Identification, RFID)等[3]。其中,耳标和项圈直观显示编号等信息,但因其较大的尺寸和不合理的形状设计,不利于在复杂养殖环境中保持稳固,导致掉标率高达10%左右,影响数据的连续性与准确性;截耳法和烙印虽能留下永久性标记,但会对牛只造成不可逆的伤害,存在损害动物福利的问题;RFID技术凭借电子芯片存储与数据识别,具有高效、准确的特点,加之其紧密贴合牛耳的设计,有效降低被剐蹭和咬掉风险,掉标率可控制在1%左右。然而,RFID技术在实际应用中仍存在明显短板:在规模化部署时,读写器及管理系统的前期投入较大;在长期使用过程中,电子芯片存在老化问题,后期维护成本较高。同时,RFID系统依赖稳定的电力供应与网络环境,在偏远山区或网络覆盖薄弱的养殖场,数据传输与实时管理难以保障。非接触式识别借助先进的计算机视觉、传感器等技术,可实现远距离、无应激的牛只身份确认,主要包括牛脸识别、鼻纹识别和虹膜识别等。鼻纹识别和虹膜识别由于数据采集难度大、设备成本高昂等问题,在实际应用中尚未普及。相比之下,基于牛脸图像识别的非接触式分类技术具有高效、低成本和动物福利友好等优势,成为肉牛智能化养殖的重要发展方向[4, 5]。鉴于此,发展非接触式的肉牛面部个体识别技术势在必行。
随着深度学习发展,Faster R-CNN(Faster Region-Based Convolutional Neural Network)[6]、SSD(Single Shot MultiBox Detector)[7]、YOLO(You Only Look Once)[8, 9]系列等目标检测网络的提出,以及FaceNet[10]人脸识别系统的出现,为进一步开展牛脸识别工作提供了多方面的支持。朱敏玲等[11]提出以卷积神经网络(Convolutional Neural Networks, CNN)为主体且引入ResNet和支持向量机(Support Vector Mechine, SVM)相结合的牛脸识别与检测的算法与模型,解决了传统CNN网络结构在牛脸识别中存在的训练收敛速度慢、识别率低及泛化性弱等问题。但该算法在光照强度与角度变化比较大时,识别准确率明显下降,难以在实际环境中应用。Kawagoe等[12]利用提取的特征描述值,采用SVM作为分类器进行奶牛个体识别,在自建的奶牛图像数据集上进行实验,结果表明,所提出的基于图像处理技术的奶牛个体识别方法具有较高的识别准确率。Xu等[13]通过将轻量级RetinaFace-mobilenet与ArcFace损失函数集成,提出了一种新的牛脸识别框架——CattleFaceNet,识别准确率达到91.3%,检测速度达到24帧/s,仍存在改进空间。Yang等[14]提出了一种融合RetinaFace和改进FaceNet的奶牛个体识别方法,FaceNet的核心特征网络通过MobileNet集成得到增强,损失函数与Cross Entropy Loss和Triplet Loss联合优化。改进的FaceNet模型在训练集上实现了99.5%的精度,在测试集上得到83.6%的精度,暴露出模型对光照突变和视角变化的泛化缺陷。齐咏生等[15]提出一种复杂场景下基于自适应注意力机制的牛脸检测算法,通过在YOLOv7-tiny主干特征提取网络引入复合双分支自适应注意力(Composite Dual-branch Adaptive Attention, CDAA)和调整损失函数等方法,检测精度达到89.58%,检测速度达到62帧/s。高洁和曹浩[16]提出一种基于改进YOLOv7的牛脸识别方法YOLO_C,通过使用FReLU激活函数代替原有激活函数,添加卷积块注意模块(Convolutional Block Attention Module,CBAM)和轻量级上采样算子(Content-Aware ReAssembly of FEatures,CARAFE)对模型YOLOv7进行改进,改进后的算法识别精确率、召回率和平均精度均值分别为89.4%、94.4%和92.9%。但在实际复杂场景中仍存在误检率较高的问题,且由于训练样本覆盖的个体数量有限,模型的泛化能力仍有待提升。
1 材料与方法
1.1 数据集
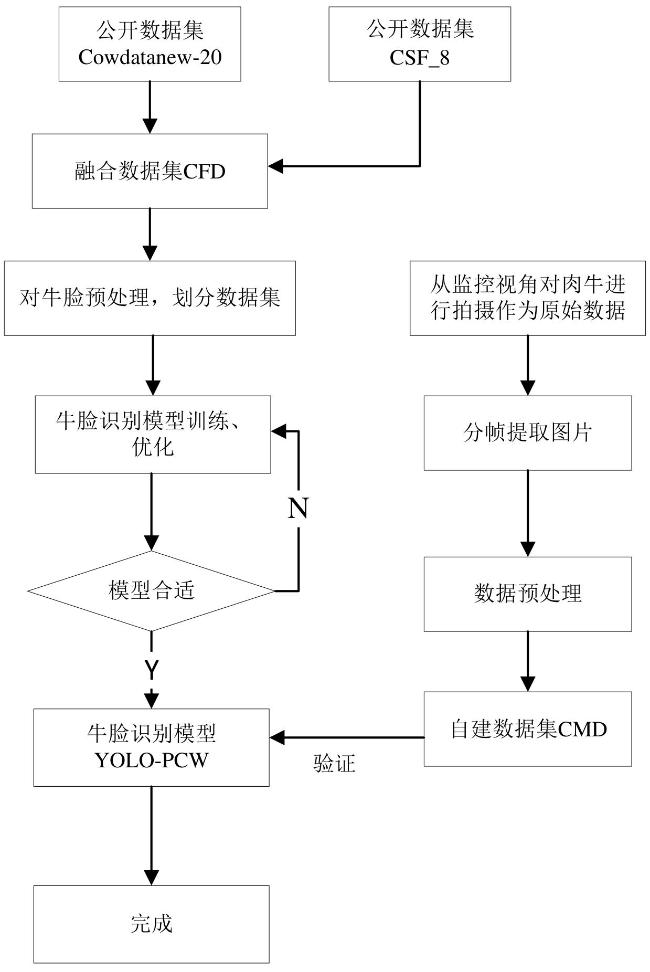


本研究将数据集CFD、CMD分别按照8∶1∶1的比例分为训练集、验证集、测试集,进行肉牛个体识别。运用Labelme这款开源的图像标注工具对肉牛数据集的图像进行标注。具体操作流程为:首先生成具有标注形式的json类型文件,随后将其转换为txt类型文件。标注遵循以下原则:1)每头牛独有的编号作为标签。2)鉴于牛角包含重要信息,尽可能将牛角完整标注进去。3)对于图像中部分被遮挡的牛脸区域,应根据可见部分的特征进行合理推测标注,以确保标注的完整性和准确性。
1.2 实验运行环境
采用的硬件设备为一台配备Intel(R)Core(TM)i7-14700KF处理器、NVIDIA GeForce RTX 4060Ti图形处理器(8 GB显存)的电脑。操作系统为Windows 11,深度学习框架选用PyTorch,编程平台为PyCharm,编程语言为Python 3.10。所有比较算法均在相同的环境下进行。
训练参数设定如下:每个批次的图片数量(Batch Size)设为8,此数值经多番调试选定,既能兼顾模型迭代效率,又可避免内存占用过高问题,保障训练平稳推进;输入图像尺寸(Imgsz)为224×224,在能提取特征的同时不会给硬件带来过重的计算负担;训练轮次(Epochs)设为50,既能让模型充分学习数据规律,又可有效预防过拟合,确保良好泛化能力,且能在各个模型之间的对比较为明显;在实际训练阶段,本研究采用了AdamW优化器,配置学习率(lr)为0.000 5且动量值为0.9,利于模型快速、稳定收敛,找到最优参数。
1.3 评价指标
采用精确率、召回率、平均精度均值mAP0.5(IoU阈值为0.5时的平均精度)、mAP0.5-0.95(IoU阈值为0.5~0.95的平均精度)、计算量、参数量作为评价指标。其中,精确率(Precision, P)表示在机器预测为正类的所有样本中实际为正类的样本所占的比例,是衡量对样本预测准确程度的一项重要指标;召回率(Recall, R)为模型成功检测到的真实目标数量与数据集中所有真实目标数量的比率,是衡量模型识别目标方面覆盖能力的一项指标;平均精度均值(Mean Average Precision, mAP)是衡量目标检测模型性能的重要指标,mAP值越高,说明模型在目标检测任务中的性能越好;计算量和参数量是评估深度学习模型复杂度和计算开销的重要指标,以确保模型在保持高性能的同时,能够在计算资源有限的情况下进行有效的训练和推理。各指标计算如公式(1)~公式(4) 所示。
式中:P为精确率,%;R为召回率,%;TP、FP、FN分别为模型正确预测正样本、误判负样本为正样本和误判正样本为负样本的个数;AP为每个类别的平均精度,%。
2 网络模型及改进
2.1 YOLOv11
YOLOv11在YOLOv8的基础上进行了全面且深入的改进。相较于YOLO系列其他模型,YOLOv11在准确率和检测速度上都取得了显著提升,这得益于其对骨干网络、颈部,以及检测头的全面优化和创新改进。具体包括:采用改进的骨干和颈部架构,将C2f模块转变为C3K2模块,其内部拥有较小的核卷积,且结合了卷积和分组卷积的特性,并允许选择使用自定义卷积核大小的C3k模块或标准的Bottleneck模块,能够优化网络中的信息流[19],在保持高效特征提取的同时,提供更灵活的配置以适应不同的计算需求。除C3k2模块外,YOLOv11的颈部架构还另外在快速-空间金字塔池化层(Spatial Pyramid Pooling-fast, SPPF)之后添加了一层类似注意力机制的C2PSA。该模块是基于PSA(Pyramid Squeeze Attention)注意力机制的卷积模块,负责处理输入张量并通过注意力机制增强特征表示。这一改进让模型更加聚焦于关键信息,增强对重要特征的捕捉能力。此外,检测头内部有重要更新,将两个传统卷积替换为深度可分离卷积(DWConv),这有助于减少模型的参数量并提高计算效率。同时,模型的深度和宽度参数经过了大幅度的精心调整,以优化模型的性能。在损失函数方面,依旧沿用了CIoU作为边界框回归损失,确保了在目标定位准确性上的优势。
2.2 模型改进方法
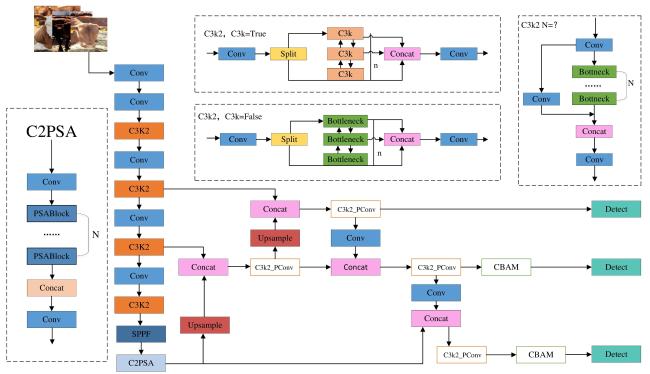
本研究在YOLOv11的基础上,提出一种轻量级的YOLO-PCW模型。该模型对以下3个方面进行了优化和改进。
1)将部分卷积(PConv)融合进YOLOv11头部网络中的C3K2模块。利用部分卷积优化卷积结构,减少计算冗余和内存访问,同时可以提高检测精度。
2)引入CBAM注意力机制。同时考虑通道和空间两个维度的注意力,通过对特征图进行自适应的加权调整,使得模型能够准确提取图像目标区域,抑制无关信息的干扰。
3)采用WIoU(Weighted Intersection over Union)损失函数。WIoU损失函数能够根据目标的大小和形状自适应地调整权重,更加准确地衡量预测框与真实框之间的差异。
改进后的YOLO-PCW结构如图4所示。
2.2.1 PConv
部分卷积(PConv)作为一种创新性的卷积技术,通过同时减少冗余计算和内存访问,更高效地提取空间特征[20]。其基本原理是利用特征图的冗杂(特征图的某些通道可能会包含与其他通道高度相似的特征,这意味着在进行网络的前向传播时,这部分信息的多次处理并没有提供额外的有用信息,反而增加了计算量和内存访问的开销),只在输入通道的一部分应用常规卷积进行空间特征提取,保持剩余通道不变,从而减少计算和内存访问。其计算量如公式(5) 所示。
内存访问量如公式(6) 所示。
MAV=
式中: 和MAV表示计算量和内存访问量;h和 分别为输入通道的高和宽; 为卷积部分通道数;k为卷积核大小。由此可见,若 为总通道数1/4时,计算量则为常规Conv的1/16,内存访问量也仅为常规Conv的1/4,能够极大地减少模型的计算量和内存访问。PConv的结构如图5所示。
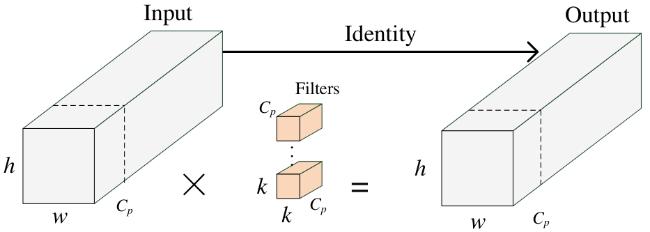
PConv引入了掩码(Mask)机制。掩码中的值以0和1来标识:0代表相应像素不参与当前的卷积计算;1则表示参与。在卷积核滑动计算时,依据掩码值决定输入特征图像素的参与与否,掩码为0的像素将被跳过。这一特征使得在YOLOv11的head层中将部分卷积(PConv)与C3K2相结合为牛脸识别带来显著功效:一方面,能大幅削减计算量,在牛脸图像背景及无关纹理区域,PConv依掩码跳过非关键像素计算,如同精准筛选拼图关键块,摒弃冗余,让计算资源得以高效利用;另一方面,极大提升计算效率,使模型前向传播加速,使其在实时牛脸监测场景中能够快速输出识别结果。同时,其掩码可依牛脸特征设计或学习优化,与C3K2协作下,让卷积聚焦牛眼、口鼻等关键部位,强化特征提取针对性,精准捕捉牛脸判别特征,有力助推牛脸识别精度提升。
2.2.2 注意力机制CBAM
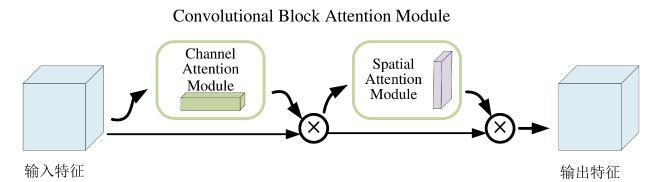
通道注意力模块专注于对特征图的不同通道进行重要性加权。在牛脸识别过程中,由于牛脸图像包含多种特征信息,如纹理、颜色、形状等,不同通道所承载的特征对于最终识别的贡献度各异。CBAM能够自动学习并判断各通道的重要性,通过对关键通道赋予更高权重,使模型聚焦于牛脸最具判别力的特征信息。例如,牛眼、口鼻周围的纹理细节通常在特定通道中有突出体现,通道注意力可强化这些关键信息的提取,减少无关或干扰通道的影响;而空间注意力模块,则侧重于特征图的空间维度,精准定位牛脸图像中需要重点关注的区域。考虑牛脸在图像中的位置、角度多变,以及可能存在的遮挡情况。空间注意力机制通过对空间位置上的像素点进行分析,突出牛脸关键部位所在的区域,抑制背景或遮挡物区域的干扰。
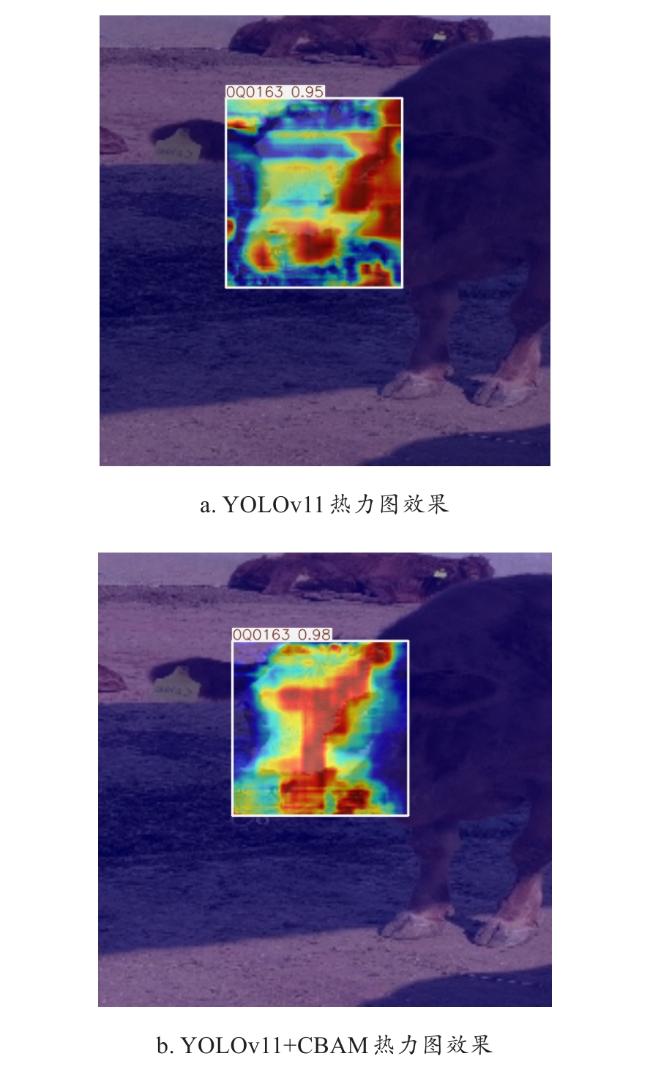
2.2.3 损失函数
YOLOv11继续使用DF Loss和CIoU Loss计算边界框回归损失。CIoU在惩罚项基础上增加了一个影响因子。该因子考虑了预测框与真实框纵横比的匹配,从而加强了长宽比一致性的考量,在一定程度上可以加快预测框的回归收敛过程。CIoU损失函数及相关计算如公式(7)~公式(10) 所示。
式中: 为离群度,其值越小代表锚框质量越高; 为超参数,用于调整不同损失项的权重;上标*表示该项不参与反向传播,有效避免模型产生无法收敛的梯度; 为归一化因子,代表增量的滑动平均值。
与CIoU相比,WIoU更加关注普通质量的样本。WIoU设计了一种合理的梯度增益分配,减少了极端样本中出现的大梯度或有害梯度,且其训练过程减少了因均匀对待所有定位误差而导致的优化方向偏差,让模型朝着提升关键区域定位精度的方向高效前进。本研究使用WIoU作为损失函数,使模型更多地关注普通质量的样本,进而提高牛脸识别网络模型的泛化能力和整体性能。
3 结果与分析
3.1 损失函数对比试验
YOLOv11目标检测模型的损失函数是CIoU,是在DIoU惩罚项的基础上增加了一个影响因子,从而加强了长宽比一致性的考量。但其采用单调聚焦机制,未能充分平衡难例样本与简单样本之间的影响。EIoU在CIoU的惩罚项基础上,将纵横比的影响因子拆分为独立的长宽计算,分别对目标框和锚框的宽度和高度进行优化,提高收敛速度[28]。虽然解决了CIoU中难易样本不均衡的问题,但其聚焦机制是静态的,并未充分挖掘非单调聚焦机制的潜能。相比之下,WIoU引入了一种动态非单调机制,并设计了一种合理的梯度增益分配,该策略减少了极端样本中出现的大梯度或有害梯度。为了比较不同损失函数的性能,本研究对YOLOv11模型在CIoU、DIoU、EIoU和WIoU损失函数下的收敛情况进行了对比,结果如图8所示。
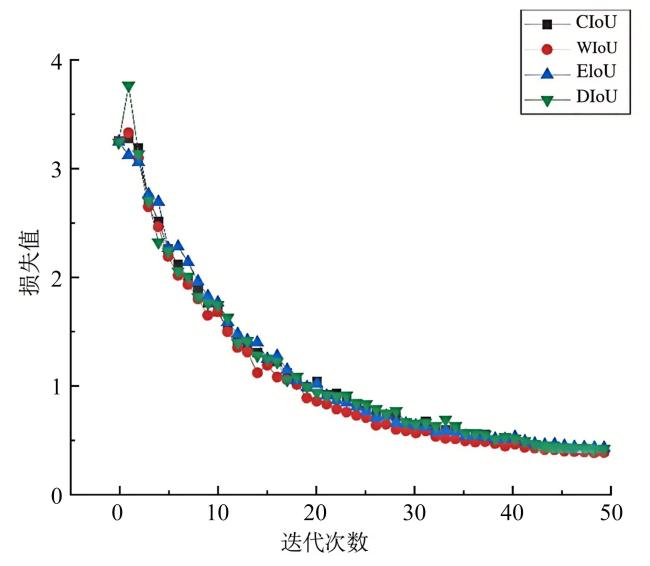
由图8可知,随着迭代次数(Epochs)的增加,4种模型(CIoU、WIoU、EIoU、DIoU)的损失值(Loss)均呈现出逐渐下降的趋势,表明所有模型在训练过程中都在不断收敛,逐渐学习到数据中的模式和规律。在整个训练过程中,WIoU模型的损失值曲线始终处于相对较低的位置,尤其是在训练的中后期,其优势更为明显。这表明WIoU模型能够更高效地学习数据中的特征和规律,从而更快地逼近最优解,具有较强的学习能力和优化能力,为牛脸识别精度和效率的提升提供有力支撑。
3.2 消融实验
为评估本研究模型中各改进模块对识别结果的影响,本研究以YOLOv11作为基线模型,通过多种改进模块的不同组合方式,进行消融实验。具体的试验结果见表1。
表1 YOLO-PCW消融实验结果Table 1 Ablation study results of YOLO-PCW |
| 试验编号 | PConv | CBAM | WIoU | 精确率/% | 召回率/% | mAP0.5/% | mAP0.5-0.95/% | 计算量/GFLOPs | 参数量/M |
|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | 92.8 | 91.7 | 94.3 | 73.4 | 6.3 | 2.6 |
| 2 | × | √ | × | 95.2 | 94.8 | 96.5 | 76.8 | 6.4 | 2.7 |
| 3 | × | × | √ | 93.8 | 94.4 | 95.4 | 75.9 | 6.3 | 2.6 |
| 4 | × | √ | √ | 96.4 | 95.9 | 97.2 | 77.6 | 6.4 | 2.7 |
| 5 | √ | × | × | 93.1 | 92 | 94.8 | 75.2 | 5.5 | 2.2 |
| 6 | √ | × | √ | 94.2 | 92.4 | 97.1 | 76.3 | 5.5 | 2.2 |
| 7 | √ | √ | × | 95.6 | 93.1 | 96.4 | 76.9 | 5.6 | 2.3 |
| 8 | √ | √ | √ | 96.4 | 96.7 | 98.7 | 78.4 | 5.6 | 2.3 |
|
对比试验1和试验2可知,仅添加CBAM后,精确率从92.8%提升至95.2%,召回率由91.7%提升至94.8%,mAP0.5从94.3%增长到96.5%,mAP0.5-0.95也从73.4%提高至76.8%。观察试验1和试验3,引入WIoU损失函数之后,精确率提升至93.8%,召回率达94.4%,mAP0.5-0.95提升至75.9%,证明了其在优化目标定位准确性方面的积极效能,让模型衡量预测框与真实框差异时更为精准,进而全方位提高整体检测精度;比较试验1和试验5,融合PConv模块使得计算量从6.3 GFLOPs降至5.5 GFLOPs,参数量从2.6 M减少至2.2 M,凸显出其对优化模型计算资源利用效率的助力。当试验8同时使用PConv、CBAM和WIoU时,模型各项指标达到试验最高值,精确率为96.4%,召回率为96.7%,mAP0.5高达98.7%,mAP0.5-0.95为78.4%,计算量稳定在5.6 GFLOPs,参数量保持在2.3 M,分别为原模型的88.9%和88.5%。由此可见,三者相辅相成,CBAM强化特征提取针对性,WIoU精准优化目标定位,PConv高效利用计算资源,这些因素相互配合,为牛脸识别模型性能的提升提供了有力支持。
3.3 不同目标检测算法的性能比较
为评估本研究提出的模型与其他主流的卷积神经网络在目标检测任务上的性能差异,将该研究算法YOLO-PCW与Faster-RCNN、SSD、YOLOv5、YOLOv7-tiny、YOLOv8算法在相同的条件下进行对比试验,训练配置均为1.2节所述。试验结果如表2所示。
表2 不同模型在肉牛面部识别任务中的性能对比Table 2 Performance comparison of different models for cattle face recognition tasks |
| 模型 | 精确率/% | 召回率/% | mAP0.5/% | 计算量/GFLOPs | 参数量/M |
|---|---|---|---|---|---|
| Faster-RCNN | 88.7 | 73.5 | 84.3 | 205.6 | 38.4 |
| SSD | 79.4 | 72.1 | 76.5 | 74.2 | 19.4 |
| YOLOv5 | 90.7 | 92.1 | 89.8 | 5.8 | 2.2 |
| YOLOv7-tiny | 91.0 | 90.4 | 87.2 | 13.2 | 6.0 |
| YOLOv8 | 91.8 | 93.3 | 95.0 | 8.1 | 3.0 |
| YOLOv11 | 92.8 | 91.7 | 94.3 | 6.3 | 2.6 |
| YOLO-PCW | 96.4 | 96.7 | 98.7 | 5.6 | 2.3 |
由表2可知,本研究提出的模型YOLO-PCW展现出显著优势,与Faster-RCNN、SSD模型相比,其精确率分别提高了7.7个百分点和17个百分点,且计算量与参数量显著减少。在YOLO系列其他模型中,从YOLOv5、YOLOv7-tiny、YOLOv8、YOLOv11到YOLO-PCW,性能逐步提升,在保证相对低计算量和参数量时,识别精度不断提高。其中YOLO-PCW模型优势最为突出,远超其他对比模型,与基准模型YOLOv11相比,YOLO-PCW在准确率、召回率、mAP0.5分别提升了3.6、5.0、4.4个百分点。试验结果表明,YOLO-PCW在牛脸精准识别任务中表现优越,能够兼顾识别精度与运算效率,实现计算资源的高效利用。
3.4 YOLO -PCW模型的测试与分析
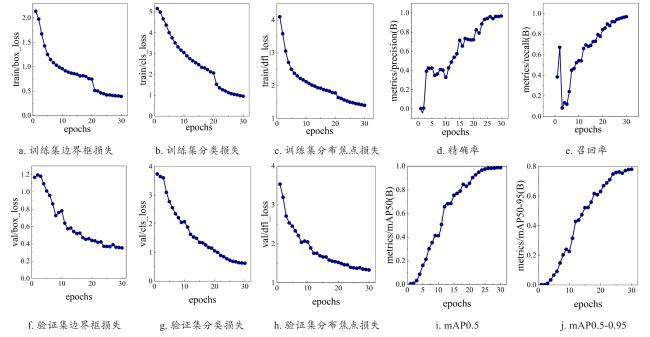
图9展示了YOLO-PCW模型训练和验证过程中的多个关键指标的变化曲线,随着训练轮次增加,模型的损失函数不断降低,精确率、召回率和平均精度均值等评估指标持续上升,说明模型在训练过程中不断优化,性能逐步提高。
为了充分展示改进模型的识别效果,本研究挑选了部分牛脸样本进行测试,这些样本涵盖了正面、侧面、低头等角度,并且牛与牛之间存在一定程度的相互遮挡情况,加之地面为沙地,整体场景具有较高的复杂性和挑战性,能够全面检验模型的性能。改进后的YOLO-PCW模型和原始YOLOv11模型的牛脸识别结果如图10所示。
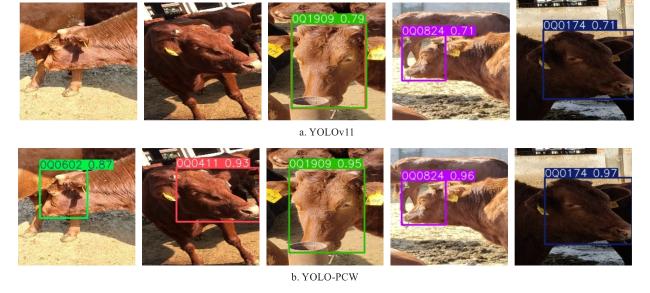
从图10识别结果可以看出,原模型在某些特定情况下暴露了明显的缺陷,存在漏检及检测框不够准确等问题。在一些牛脸角度较为特殊或者存在遮挡的情形下,原模型未能完整框出牛脸,而且其检测框的置信度相对较低。与原模型相对比,YOLO-PCW模型则表现出色,能够更加精准地框选出牛脸,无论是面对不同姿态、角度的牛脸,还是存在一定遮挡的情况,都能做到较为准确地检测和框选,检测框与牛脸的贴合度更高,置信度也普遍较高,可以看出YOLO-PCW在牛脸识别任务上的改进是有效的。
此外,为验证YOLO-PCW模型的泛化能力,本研究利用自建数据集CMD开展了对比实验,模型生成的预测标注结果如图11所示,可以看出,在实际监控条件下,该模型也能准确通过牛脸判定个体ID从而精准识别肉牛个体。这表明YOLO-PCW模型能够适配实际牧场的复杂环境,具有在真实养殖场景中应用的潜力。

4 结 论
本研究提出的YOLO-PCW轻量级牛脸识别模型,通过将PConv融合进头部的C3k2模块,有效降低了模型的参数量和浮点计算量,使模型在保持较高性能的同时,减少了计算资源的消耗,提高了模型的运行效率。加入CBAM注意力机制,引导模型聚焦牛脸关键部位如牛眼、口鼻等,精准捕捉细微特征,显著提升检测精度,增强了模型对复杂场景下牛脸的鲁棒性。将CIoU损失函数改进为WIoU损失函数,WIoU收敛更快、损失更低,能够更好地引导模型进行优化,增强模型收敛性能的同时可以生成更高质量的检测框,进一步优化了模型的训练过程,使模型在学习牛脸特征时更加精准地拟合目标边界,进一步提升了识别性能。
改进后的YOLO-PCW模型精确率达到96.4%,召回率达到96.7%,mAP0.5高达98.7%,mAP0.5-0.95为78.4%,计算量和参数量分别降低到5.6 GFLOPs和2.3 M,仅为原模型的88.9%和88.5%。因此,YOLO-PCW模型在模型复杂度、识别精度与速度等方面达到更好平衡,为肉牛养殖管理中的个体精准识别提供了一种高效、准确的技术手段,具有重要的实际应用价值和广阔的应用前景。未来,将探索无需大量标注数据的训练方法,提升模型的泛化能力和适应性,进一步将肉牛面部识别技术应用于智能监控系统,实现个体身份追踪、行为分析、健康监测等功能,为畜牧业的智能化发展提供更有力的技术支持。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}