



0 引 言
葡萄作为一种重要的农作物,其种植面积和产量逐年攀升,在农业生产和经济发展中扮演着重要的角色。准确进行产量评估是葡萄精准栽培中最关键的任务之一[1],对农业生产管理和农业经济发展具有关键作用。然而,考虑到葡萄的特性——复杂的穗状结构,果实相互遮挡,果实大小差异显著,以及外界光照条件不同等多种因素,使得葡萄产量的精准估计成为一项复杂的任务。
近年来,随着深度学习技术的发展,葡萄产量估计工作逐渐从传统的方法转向基于计算机视觉图像处理技术的方法。传统的葡萄产量估计方法通常是耗时、费力和具有破坏性的,这些措施往往都有偏差并且容易出错[2] 。通常需要对手工收获的一组葡萄串进行计数和加权,或者利用机械设备根据葡萄树芽、串、葡萄颗粒计数预测葡萄产量。Wohlfahrt等[3]通过显微镜解剖葡萄树芽评估葡萄芽的繁殖力预测下一季的产量,这个方法具有破坏性且耗时。De La Fuente等[4]通过在葡萄生长的不同时期预测葡萄产量,并与田间测量的产量进行比较,确定转色期方法在生长季节预测的准确性。可用于生长周期不同时期的预测,但比较耗时和费力。Diago等[5]拍摄了不同红色葡萄品种的葡萄串,并且在图像采集后手动确定葡萄串的产量,这种方法虽然廉价,但是估计产量的精度较低。Carrillo等[6]通过多光谱机载影像的方法,对收获时浆果重量、葡萄串数、葡萄个数进行测量,这种方法能够优化管理并且限制操作的成本,但往往会由于操作员的错误影响产量估计的准确率。
传统图像检测技术的不足在于难以处理复杂场景、计算复杂度高、需要手动选择参数、无法适应动态场景等。这些问题导致传统技术在图像检测精度、实时性和适应性等方面存在局限性。相比之下,基于计算机视觉的图像处理方法,尤其是在目标分类和检测技术上的应用,通过从图像中提取特征实现定位与计数,显示出巨大潜力。近年来,基于卷积神经网络(Convolutional Neural Network, CNN)的葡萄产量估计方法为农业生产提供了新的技术手段,主要是利用深度学习技术通过卷积操作和池化操作从图像中提取特征,通过训练模型来实现检测和产量的精确估计。Silver和Monga[7]通过图像处理和CNN的结合提出的模型,能够从智能手机拍摄的图像中估计葡萄藤上葡萄的重量。Buayai等[8]提出了一种基于深度神经网络的新型端到端浆果技术方法,用于在现场拍摄的葡萄图像上检测葡萄串和葡萄颗粒,该技术能够为真实的葡萄园环境提供实际的应用,但会因为拍摄角度不同而影响对同一束葡萄串的浆果数量预测,影响葡萄产量估计的准确性。Aquino等[9]提出了一种基于图像分析的解决方案,使用基于数学形态和像素分类的新图像分析算法对葡萄浆果图像进行分析,开发了一个监督分类器,用于检测葡萄浆果,这种方法仅方便于葡萄生长早期产量预测和评估。Shen等[10]提出了一种基于YOLOv5s深度学习算法的葡萄串实时检测方法,最终实现了对葡萄串的快速、准确检测,但由于该网络仅仅是基于红葡萄品种训练的,因此难以准确识别绿葡萄。张传栋等[11]提出了一种轻量级融合随机注意力机制(Shuffle attention, SA)的改进YOLOv8n模型(SAW-YOLOv8n)的实时检测方法,能够对葡萄簇的幼果识别实现高精度和轻量化的要求,并适应不同遮挡。Coviello等[12]介绍了葡萄浆果计数网络架构(Grape Berries Counting Net, GBCNet),能够通过智能手机摄像头准确估计葡萄产量,使用空洞卷积神经网络(Dilated Convolutional Neural Network, Dilated CNN)生成葡萄浆果的密度图,利用葡萄数据取得了良好的表现。Zabawa等[13]使用全卷积神经网络,通过语义分割方法对图像中的浆果进行检测和计数,能够正确检测到94%的浆果。Wang等[14]提出了谷物作物头数计数统一模型(Counting Heads of Cereal Crops Net, CHCNet),可以通过小样本学习对多个谷物作物头进行计数,其中跨作物泛化能力方面表现得很好。刘畅等[15]提出了3C-YOLOv8n目标检测模型,能够有效地对葡萄进行识别和定位。Yu等[16]提出了一种基于MobileVit-Large选择性内核的GSConv-YOLO(MobileVit-Large Selective Kernel-GSConv-YOLO, MLG-YOLO)模型,能够有效地对冬枣进行检测和定位,基于YOLOv8n并引入轻量级卷积技术提高了检测冬枣的准确性。
Transformer架构通过独特的注意力机制设计,在文本理解和图像分析等多个AI领域展现出卓越性能,在促进人工智能技术发展和应用落地方面也有着重要的作用。Du和Liu[17]提出了一种将Swin Transformer作为骨干,在颈部网络中引入自适应特征融合的葡萄浆果分割与浆果计数方法,这种方法能够在浆果计数估计中表现出优势,但对于葡萄浆果太小、照明和复杂条件下的情况会受到影响。Lu等[18]提出了一种集成Swin-Transformer-YOLOv5的检测模型用于实时酿酒葡萄串检测,在天气条件不同、日照强度不同,以及浆果成熟阶段不同的情况下进行测试,该方法在检测精度方面得到了验证,但在检测未成熟浆果时表现不佳。Wang等[19]提供了Swin Transformer和Detection Transformer模型来实现葡萄串的检测,能够在光照条件过度曝光、过度黑暗,以及遮挡的情况下更稳定地识别葡萄串,但在葡萄的形状和大小差别过大时,葡萄串相较难被识别出来。Xia等[20]提出了一种基于Transformer的新型深度学习估计算法,采用了在自然语言处理方面的转换器模型,能够减少像素估计误差,增强了模型预测深度图的能力,对于复杂的环境具有良好的性能。Wang等[21]提出了一种DualSeg的并行网络结构,利用CNN和Transformer结合对葡萄图像进行处理,保留其局部和全局特征,在不同的情景下也能够保证模型的稳健性,但模型的参数数量较大,模型的泛化能力有待提高。Ahmedt-Aristizabal等[22]使用带有Swin Transformer的掩码基于区域的卷积神经网络(Mask Region-based Convolutional Neural Network, Mask R-CNN)识别和分割葡萄串,利用葡萄串权重回归来估计葡萄产量,从而获得葡萄串重量估计值。Zheng等[23]引入了类似于U型网络(UNet)的多层特征融合结构,并使用Transformer和CNN来改善鱼类密度分布不均匀的问题,更好地对鱼类进行计数。Zhang等[24]提出了Swin-transformer-YOLOv5模型用于检测植物物种的花粉,具有较高的准确度,是一种适应性广泛、稳健,以及准确的花粉定量检测方法。
近年来,跨领域知识迁移技术在图像识别、文本分析等多个人工智能(Artificial Intelligence, AI)分支中展现出强大的实用价值,涵盖了许多不同的技术和应用,为各种机器学习问题提供了许多创新的解决方案,这种技术可以将已训练好的模型应用于新场景,显著减少数据采集和人工标注的投入。另外能够有效地解决数据集稀缺和标注困难等问题。Cecotti等[25]利用CNN和迁移学习的方法检测两种类型的葡萄,对于产量检测还需要从多个位置和多个角度获取图像,从而提高产量检测的精度。Xue等[26]引入了一种简单而高效的分支级迁移学习策略,通过结合分支级迁移学习和多层网络融合,显著增强了网络在广泛场景下的特征提取能力,但需要更进一步地评估幼苗出苗情况,提高预测产量的准确性。Cao等[27]由于缺乏用于水果抓取检测的数据集,设计了四种端到端的检测模型,应用迁移学习技术和数据增强技术提高了模型的准确性和泛化性能。该方法能够应用于水果采摘和分拣等,但对于复杂的工作环境还需要增加注意力机制等提高准确率。Bai等[28]提出了一种结合单阶段目标识别网络、UNet语义分割网络、迁移学习和数据处理的成熟黄瓜分割与识别的方法,引入迁移学习方法优化了网络结构,使用迁移学习的三种网络结构都能在黄瓜的图像处理中表现出良好的性能。Chen等[29]通过迁移学习方法评估了35个先进的深度学习模型,进行反复验证,为杂草识别任务建立了广泛的基准,大大提高了杂草类别识别的准确率。Zha等[30]使用CNN迁移学习对红葡萄图像进行分级,比较了五种不同网络深度的CNN模型的效果,对葡萄产业生产质量有一定的指导意义。Gai等[31]使用迁移学习对模型进行预训练,以此优化模型参数,实现了较高的精确率和召回率,能够有效地检测蓝莓果实。
尽管计算机视觉图像处理方法在农业应用上取得了较好的效果,但仍然面临着一些挑战。一是模型在检测红葡萄品种以及葡萄成熟时期的情况下效果较好,但对葡萄果实与葡萄叶片颜色相似的绿葡萄品种具有局限性;二是当葡萄果实或者葡萄串较小时,模型的检测效果较差;三是面对多样化的葡萄品种,模型的适应性不足,重新训练成本高昂。
针对上述问题,本研究结合多模态学习和迁移学习方法,专注于实现快速且精准的葡萄检测,从而实现准确的葡萄检测和计数。本研究选择在大规模数据上预训练的模型作为基础,以提高模型的初始性能,减少在目标任务上的训练时间和成本,加速模型的训练过程。由于目标任务的数据量较小,通过微调,可以提高模型的性能和泛化能力,从而提升葡萄串检测的识别精度,进而提高葡萄产量估计的准确性。在复杂情况下,如葡萄果实颜色与背景或葡萄叶片相似、果实大小不一,仅依赖单一图像特征进行检测可能导致识别的可靠性和准确性较低。本研究认为,当不同特征之间存在一定程度的互补性时,模型能够更完整地提取输入信息的核心要素,有效增强系统的分析精度和推理性能。因此,本研究采用注意力机制增强了图像和文本特征,实现了图像-文本和文本-图像的跨模态特征学习,从而有效地预测葡萄位置并提取相应的类别信息。此外,本研究引入了语言引导的查询选择模块,从图像特征中选择合适的跨模态查询,用于预测葡萄对象框并提取相应的文本特征。跨模态解码器将文本特征注入查询中,以获得更准确的模态对齐。从而全面提升模型性能和在实际应用中的表现,为相关产业带来更多的益处。
1 研究数据
表1 WGISD数据集的详细说明Table 1 A detailed description of WGISD dataset |
| 葡萄品种 | 图像/张 | 标记框/组 |
|---|---|---|
| 霞多丽(Chardonnay, CDY) | 65 | 840 |
| 法国品丽珠(Cabernet Franc, CFR) | 65 | 1 069 |
| 赤霞珠(Cabernet Sauvignon, CSV) | 57 | 643 |
| 白苏维翁(Sauvignon Blanc, SVB) | 65 | 1 317 |
| 西拉(Syrah, SYH) | 48 | 563 |
| 总计 | 300 | 4 432 |
另外,为了验证模型在不同环境和不同葡萄品种上的性能,本研究增加了实地拍摄的葡萄数据集,采集于中国安徽省合肥市大圩葡萄园,包括四个种类:醉金香、美人指、玫瑰香和甬尤,共280张葡萄图片,分辨率像素为2 048×1 365,图1所示为增加的四种葡萄类别的图像实例。

实地拍摄的葡萄数据集,其中将一串葡萄作为一组,总计2 411组带有定位标记的果穗标本,具体说明如表2所示。
表2 实地拍摄葡萄数据集的详细说明Table 2 Detailed description of on-site shooting grape datase |
| 葡萄品种 | 图像/张 | 标记框/组 |
|---|---|---|
| 醉金香(Fragrant Gold, FTG) | 70 | 705 |
| 美人指(Manicure Finger, MFN) | 70 | 593 |
| 玫瑰香(Muscat Hamburg, MHB ) | 70 | 654 |
| 甬尤(Yongyou, YGU) | 70 | 459 |
| 总计 | 280 | 2 411 |
2 研究方法
迁移学习是在大规模数据集上训练的模型,这些模型已学习到丰富的特征,当处理葡萄图像时,在较少的葡萄图像上利用这些特征微调即可适应任务,从而能够降低标注数据成本。本研究通过迁移学习更好地捕捉到葡萄的特征,提升葡萄检测和产量估计的准确性。本研究的多模态框架采用双编码-单编码结构,如图2中所示。该框架由三个核心模块组成:图像特征-文本特征提取-增强模块、语言引导查询选择模块和跨模态解码器模块。

对于每个葡萄图像中的葡萄串及对应类别文本,通过文本和图像特征提取网络分别提取对应特征,这些特征随后被输入增强模块进行跨模态特征融合,生成增强的跨模态图像和文本特征。接着,语言引导的查询选择模块从增强图像特征中选择合适的跨模态查询。类似于DETR模型[33]中的对象查询,这些跨模态查询将被送到跨模态解码器中,从图像和文本的模态特征中检测所需要的特征并更新。最后,解码器的输出查询结果将用于预测葡萄对象框并提取对应类别的文本信息。
2.1 特征增强模块
在处理葡萄串图像和对应类别文本时,本研究提取具有图像主干的多尺度图像特征(如Swin Transformer)和具有文本主干的文本特征(如基于Transformer结构的预训练语言表示模型(Bidirectional Encoder Representations from Transformers, BERT))。图像特征和文本特征如公式(1) 和公式(2) 所示。
式中: 为提取特征函数,分别从图像中提取葡萄的图像和文本特征。img和text分别表示输入的葡萄串图像和对应类别文本,在提取葡萄串图像和文本特征后,跨模态特征交互模块对输入特征进行增强与融合。图3展示了特征增强器,包括多个特征增强器层。增强的图像特征和文本特征如公式(3) 和公式(4) 所示。
式中:UpdImgFeatures和UpdTextFeatures分别表示增强后的图像特征和文本特征。
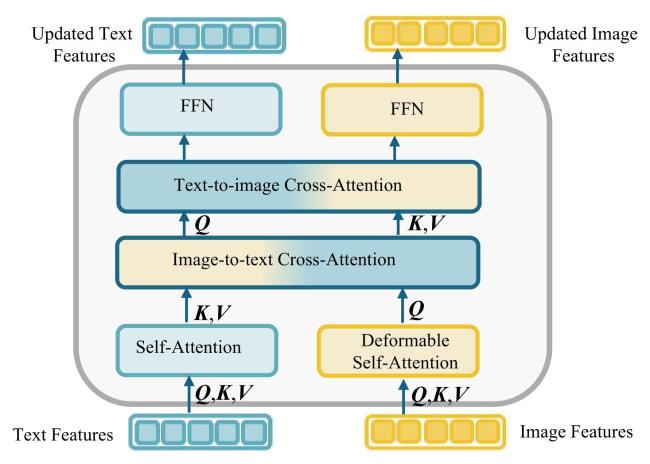
本研究利用可变自注意力机制来增强图像特征,并利用自注意力机制来增强文本特征。受到用于图像和语言多模态学习的预训练模型(Grounded Language-Image Pre-training, GLIP)[34]的启发,本研究增加了图像到文本和文本到图像的交叉注意力机制进行特征融合,这种方法有助于不同模态之间的对齐和融合。
2.2 语言引导查询选择
本研究主要从输入文本指定的图像中进行目标检测。设计的语言引导查询模块是为了更加有效地利用输入文本去指导对象进行目标检测,从而选择与输入文本更相关的特征作为解码器的查询。
首先,计算图像特征和文本特征之间的匹配得分,如公式(5) 所示。
式中: UpdImgFeatures 和 UpdTextFeatures 分别为输入特征增强器进行交叉模态特征融合的图像特征矩阵和文本特征矩阵; Scores 是得到的匹配得分,Scoreij 表示第i个图像特征与第j个文本特征之间的匹配得分。
之后,选择每个图像特征的最大匹配得分。计算最大匹配得分如公式(6) 所示。
式中:MaxImgScores是每个图像特征的最大匹配得分。
最后,选择解码器中的查询数量作为最大的图像特征匹配得分,并按照从大到小的匹配得分排序,输出其对应的索引。索引如公式(7) 所示。
式中:num_query是解码器中的查询数量,在本研究中设置为900。GetIndices是输出的索引值。
在语言引导的查询选择模块中最后输出num_query个查询索引,便可以利用这些选择的索引提取特征来初始化查询。根据自监督学习的视觉表征学习(Distillation with No Labels, DINO)模型[35]的方法,本研究采用混合查询选择来初始化解码器查询。每个解码器查询包含两个部分:内容部分和位置部分。内容部分在训练期间设为可学习参数,能够适应不同的任务需求。位置部分则采用动态锚盒,由编码器来输出初始化。
2.3 跨模态解码器
如图4所示,跨模态解码器模块主要用于结合图像和文本模态特征。首先将每个跨模态查询输入到自注意层。跨模态查询如公式(8) 所示。
式中: Q 为输入的查询向量,该向量负责处理输入查询,用来增强查询内部的特征。Q self是自注意力层的输出。

然后,分别将通过图像交叉注意层和文本交叉注意层进行处理,以融合图像和文本特征,如公式(9) 和公式(10) 所示。
式中:Q img为图像交叉注意层的输出;K text和V text是文本特征的键和值;K img和V img是图像特征的键和值。文本交叉注意层能够将文本信息融入查询中,获得更准确的模态对齐,并且每个解码器层都有一个额外的文本跨注意力层,因此可以更有效地融合图像和文本信息。
最后,文本交叉注意层的输出Q text再经过前馈全连接层(Feed-Forward Network, FFN),得到跨模态解码器的输出,如公式(11) 所示。
2.4 损失函数
本模型损失函数主要由五部分组成:loss_bbox(边界框回归损失函数)、loss_cls(分类损失函数)、loss_iou(预测框与真实框之间的交并比(Intersection Over Union, IoU)损失)、loss_mae(绝对误差损失函数),以及loss_rmse(均方根误差损失函数)。如公式(12) 所示,采用L1损失(衡量预测值与真实值之间的误差)来计算边界框回归。
式中:gi 为真实标记框;pi 为预测标记框。N为坐标维度;L bbox为边界回归损失。
本研究遵循GLIP模型使用预测对象与语言标记之间的对比损失进行分类。具体通过公式(13) 将每个查询与文本特征进行点积运算来预测每个文本标记的logit值,然后对每个logit值应用焦点损失。分类损失和IoU损失如公式(13)~公式(16) 所示。
式中:p t为模型预测正确类别的置信度;α为调节正负样本的权重;γ为控制简单样本的贡献度衰减的重点参数,以使样本易于分类,预测框与真实框之间的IoU损失;C为闭合包含两个边界框的最小区域;U为两个边界框的并集;L cls为分类损失;L iou为IoU损失。公式(17) 采用L1损失来计算绝对误差损失,公式(18) 计算均方根误差损失。
式中: 为样本数量,个;yi 为第i个样本的真实值; 为第i个样本的预测值;L mae为平均绝对误差损失;L rmse为均方根误差损失。
这些损失函数改进有助于提高模型对复杂多变场景的适应性和精确度。
2.5 实验配置
为了保证实验的公平性和可比性,本研究所有模型均在一台服务器上统一的硬件和软件环境下实验,该服务器的硬件配置为Intel Xeon Platinum 8350C处理器(主频2.6 GHz)和NVIDIA RTX 3090显卡,所有实验代码基于PyTorch深度学习平台开发,使用Python 3.8编程环境完成实现。综合考虑硬件要求和训练效果,根据模型的训练行为设置了训练轮数和批量大小的参数,其中batch size根据所使用的GPU(Graphics Processing Unit)数量和每个GPU可以处理的样本数计算得出;学习率采用auto_scale_lr技术,根据batch size自动缩放动态调整学习率,避免因人为调参等使学习率过高导致训练发散或者过低导致训练收敛变慢,从而使训练更加稳定,以优化训练过程。
2.6 评价指标
在果实检测环节,采用WGISD公开数据集评估检测模型性能,每个葡萄果穗实例均通过边界框(Bounding Box)进行空间定位。模型评估采用以下指标:在目标检测性能评估中,主要采用两项核心指标:平均精度均值(Mean Average Precision, mAP)和召回率均值(Average Recall, AR)。
在本研究中,mAP主要包括以下几种形式:mAP(IoU@[0.5∶0.95])、mAP50(IoU@[0.5])和mAP75(IoU@[0.75])。
mAP定义如公式(19)~公式(22) 所示。
式中:TP(True Positive)为正确检测的葡萄串数;FP(False Positive)为检测到的误报的数量;FN(False Negative)为漏检的数量;Ni 是IoU阈值的数量;AP为通过计算一系列交并比阈值下的PR曲线和坐标轴的面积。mAP是多个AP类的平均值,代表了算法对所有类的通用检测性能。
AR衡量在给定IoU阈值下,模型能够正确检测到的目标占所有实际目标的比例。在本研究中,mAR是在一系列IoU阈值(从0.5到0.95)的平均召回率。如公式(23) 所示。
式中:M为评估的IoU阈值的数量,个;Rk 为在第k个IoU阈值下的召回率。
葡萄产量通常基于三个关键参数计算:单位面积的葡萄藤蔓数(N v,个)、每颗藤蔓的葡萄串结果数(N b,串)和单个葡萄串平均重量(P b,g)。通过这三个变量的乘积关系,可推算出葡萄串预估产量如公式(24) 所示。
式中:Y为串级别葡萄产量预估公式。
基于葡萄藤结果数量的检测数据,可准确估算果园总产量。因此,在葡萄产量估计的计数模块中,本研究选用平均绝对误差(Mean Absolute Error, MAE)与均方根误差(Root Mean Square Error, RMSE)两项指标评估模型的计数效果。其中,MAE反映预测结果与实际值的平均偏差程度,表征了模型输出结果与实测数据之间的平均偏差水平。而RMSE则衡量预测误差的离散程度。计算MAE和RMSE如公式(25) 和公式(26) 所示。
式中:Ne 为图像样本总量,串; 为第i幅图像中葡萄果穗的实际数量,串; 则为对应的预测值。
上述指标评估模型在葡萄串检测任务上的性能和葡萄产量估计的准确性,可以确保该算法在真实场景中展现出良好的实用价值和可靠性。
3 结果与分析
3.1 模型训练结果
本研究主要对比几种常见的主流模型和经典模型在葡萄检测上的表现。其中,选择的基准模型涵盖了目标检测领域的主要技术路线,包括适合实时性要求高的农业场景的单阶段检测模型(YOLOv3[36],密集无痕查询方法(Dense Distinct Queries, DDQ[37]),AutoAssign[38],自适应训练样本选择算法(Adaptive Training Sample Selection, ATSS[39]))、适用于复杂场景的两阶段检测模型(Faster R-CNN[40],Dynamic R-CNN[41])、基于区域提议的改进模型(Grid R-CNN[42])、特征金字塔优化模型(Neural Architecture Search for Feature Pyramid Network, NAS-FPN[43]),以及样本分配策略模型(PrIme Sample Attention, PISA[44])。这些基准模型既能体现传统性能,又能探索前沿技术对农业场景的适配性,从而全面评估检测性能的影响因素。由于不同模型所需要的计算机资源不同,因此本研究根据模型的实际情况观察训练和验证损失的变化趋势,当损失在一定的epoch后不显著下降,最终确定模型已经收敛时确定设置epochs值。
表3 葡萄检测研究不同模型目标检测实验的结果Table 3 Results of object detection experiments of different models in grape detection research |
| 模型 | mAP/% | mAP50/% | mAP75/% | mAR/% | epochs |
|---|---|---|---|---|---|
| YOLOv3 | 22.0 | 57.0 | 11.3 | 37.3 | 200 |
| DDQ | 27.7 | 45.5 | 28.6 | 66.7 | 70 |
| Grid R-CNN | 32.0 | 63.3 | 28.6 | 48.5 | 70 |
| AutoAssign | 6.50 | 21.2 | 1.50 | 26.2 | 170 |
| PISA | 29.7 | 60.0 | 25.6 | 44.2 | 100 |
| NAS-FPN | 39.8 | 77.6 | 36.2 | 52.8 | 80 |
| Faster R-CNN | 28.0 | 53.4 | 26.4 | 48.4 | 100 |
| Dynamic R-CNN | 23.0 | 48.9 | 19.7 | 40.3 | 80 |
| ATSS | 9.60 | 28.6 | 3.20 | 32.6 | 170 |
| Grounding DINO | 1.50 | 2.90 | 1.60 | 33.1 | — |
| GDCNet | 53.2 | 80.3 | 58.2 | 76.5 | 30 |
|
为了更直观地表现每个模型的性能,本研究绘制了各个模型经过50轮训练后,mAP、mAP50和mAP75的曲线,以及在模型收敛时对应的mAR值对比,如图5所示,在训练的前几个epochs,大多数模型的mAP值显著上升,通常是因为模型在学习阶段逐渐适应数据集;在10到20个epochs之间波动较大,可能是由于模型的学习率调整,数据集样本数量和噪声等特性影响;随着训练周期的增加,mAP值逐渐趋于稳定,表明模型在不断优化和收敛。对于检测的五种葡萄品种,相对其他基准模型,本研究提出的模型检测快速,准确率更高,适应性更好。
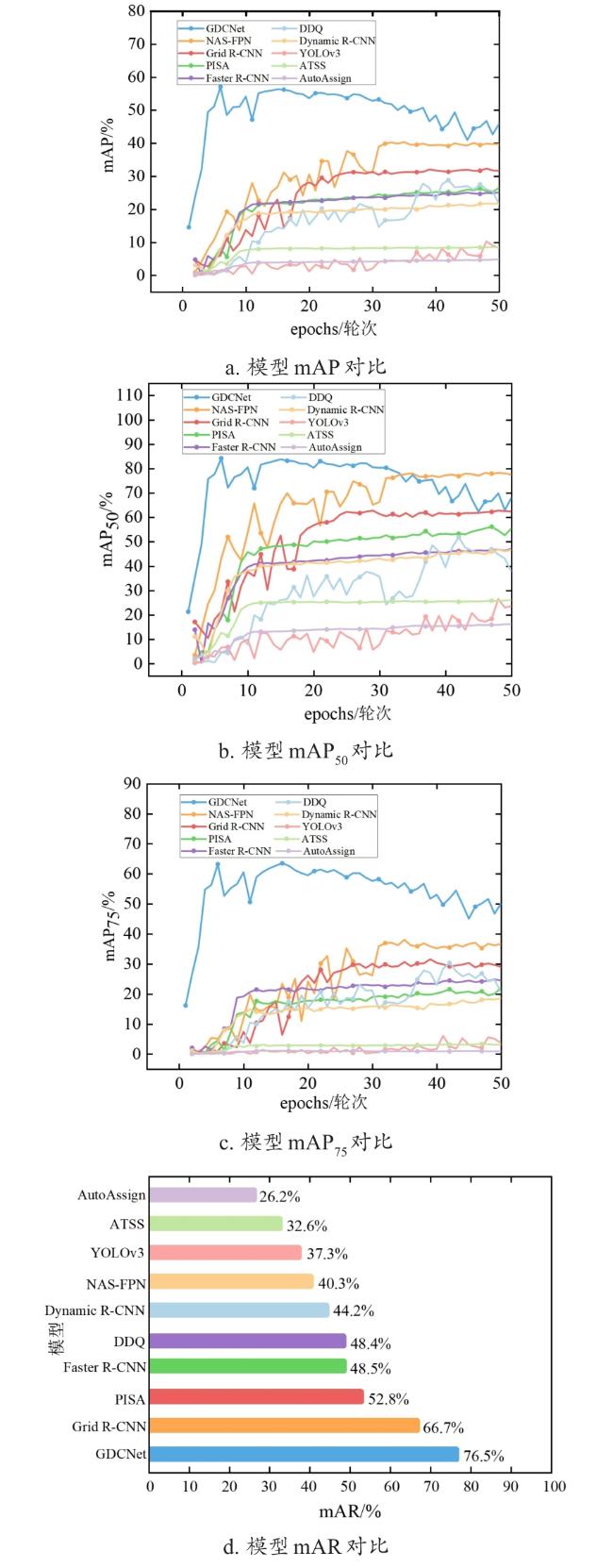
另外为了提高模型结果的可靠性,本研究进一步评估了模型对不同目标大小的识别效果,见表4。结果显示,本研究提出的模型不仅在识别大葡萄串目标上的效果较好,其中小葡萄串目标上的表现也优于其他基线模型,在检测任务上,mAP_s达到74.2%,相较于次高DDQ模型提升了9.5个百分点。另外为了更直观地表现每个模型在葡萄串较小时的性能,本研究绘制了各个模型经过50轮训练后,mAP_s曲线和在模型收敛时对应的mAR_s值对比,根据epochs的增加,模型的mAP_s值从上升到逐渐趋于平稳,表明这些模型对于检测葡萄串较小时任务的不断学习并改进其性能,但不同模型的表现差异显著,可以看出相对其他基准模型,本研究在葡萄串较小时,模型的检测效果最好,如图6所示。
表4 葡萄检测研究中不同规模目标检测的结果 (%)Table 4 Results of target detection at different scales in grape detection research |
| 模型 | mAP_s | mAP_m | mAP_l | mAR_s | mAR_m | mAR_l |
|---|---|---|---|---|---|---|
| YOLOv3 | 35.7 | 15.6 | 18.3 | 35.6 | 27.0 | 41.8 |
| DDQ | 64.7 | 15.9 | 24.9 | 64.9 | 57.7 | 71.7 |
| Grid R-CNN | 47.0 | 26.6 | 28.8 | 46.9 | 36.2 | 54.6 |
| AutoAssign | 28.4 | 2.4 | 4.4 | 28.3 | 8.0 | 29.0 |
| PISA | 44.3 | 16.8 | 27.1 | 44.3 | 26.8 | 48.7 |
| NAS-FPN | 51.7 | 31.2 | 36.7 | 51.8 | 43.7 | 57.3 |
| Faster R-CNN | 47.0 | 21.7 | 24.6 | 46.9 | 36.5 | 54.7 |
| Dynamic R-CNN | 39.2 | 14.8 | 19.6 | 39.2 | 23.9 | 45.5 |
| ATSS | 34.2 | 7.4 | 6.2 | 34.0 | 16.6 | 35.1 |
| Grounding DINO | 36.2 | 5.60 | 0.90 | 36.0 | 12.9 | 34.6 |
| GDCNet | 74.2 | 45.9 | 43.8 | 74.7 | 75.4 | 83.5 |
|

3.2 模型计数结果
在葡萄串计数方面,本研究模型与基线模型的MAE和RMSE的对比结果如表5所示,可以看出模型在计数方面的效果优于其他基线模型,其中MAE的值为1.65串,RMSE为2.48串。另外,通过对测试集可视化结果的分析发现,误差主要集中在以下情况:绿葡萄串与葡萄叶片颜色相似,且葡萄串被叶片大面积遮挡、露出部分较小。
表5 葡萄计数实验结果Table 5 Results of grape counting experiments |
| 模型 | MAE/串 | RMSE/串 |
|---|---|---|
| YOLOv3 | 6.85 | 8.47 |
| DDQ | 10.55 | 12.03 |
| Grid R-CNN | 4.80 | 6.21 |
| AutoAssign | 16.30 | 17.03 |
| PISA | 10.05 | 11.71 |
| NAS-FPN | 2.10 | 2.72 |
| Faster R-CNN | 10.65 | 12.08 |
| Dynamic R-CNN | 12.60 | 13.34 |
| ATSS | 16.30 | 17.03 |
| GDCNet | 1.65 | 2.48 |
3.3 可视化结果
为了更加直观地展示模型识别检测葡萄串和计数的效果,本研究随机选择一张测试集中种类为Syrah的葡萄图像,该葡萄图像为葡萄果实与葡萄叶片颜色相似的绿葡萄品种,并将对比的基准模型中前七种效果较好的模型,为直观呈现模型效果,图7展示了详细的对比分析结果。本研究通过文本和图像特征的交叉注意力机制增强信息互补,能够有效融合颜色和形状等信息,并且利用语言特征指导查询选择优化特征提取过程,生成更具针对性的查询,使模型更好地区分颜色相似的绿葡萄和叶片。其中Label为原本数据集中标注的信息,可以观察出本模型检测效果的精确度更高,计数效果更好。

3.4 消融实验
为了验证模型设计的有效性,本研究进行消融实验以评估关于编码器融合和文本交叉注意力的模块组件的贡献,结果如表6所示,可以得出,编码器融合模块显著提升了系统性能,在架构中发挥着关键性作用。而文本交叉注意力模块虽然提供了一些优点,但它对于模型检测准确性的影响相对较小。总的来说,这些结果表明,不同的模块在改善模型性能中都起着重要的作用。
表6 GDCNet模型消融实验结果Table 6 Results of ablation experiments of GDCNet |
| 模型 | mAP/% | mAP50/% | mAP75/% | mAR/% |
|---|---|---|---|---|
| GDCNet | 53.2 | 80.3 | 58.2 | 76.5 |
| 去掉编码器融合 | 35.9 | 63.4 | 35.5 | 62.8 |
| 去掉文本交叉注意力模块 | 50.5 | 75.1 | 55.3 | 76.5 |
另外为了更直观地展示不同模块的效果,本研究采用了一种模型可视化方法,使用特征提取技术揭示模型的内部处理,应用梯度加权类激活映射算法[46]增强模型的解释性,该算法通过生成热力图来展示输入图像中哪些区域对模型的结果最为重要,从而有助于理解模型在做出预测时关注的图像区域。
如图8所示,展示了模型、删掉编码器融合模块,以及删掉文本交叉注意力模块的葡萄检测热力图。具体而言,通过对比可以展现出本模型的热力图中葡萄串更清晰,易识别,能够有效地聚合关键特征,使其能够更精确地关注目标区域;对于删掉文本交叉注意力模块的热力图,整体清晰,展示了葡萄串的分布情况,但颜色的过渡在某些区域表现不明显,可能会导致对热点的误解;对于删掉编码器融合模块的热力图,聚合关键特征效果较差可能会导致难以捕捉到重点信息,背景的颜色较为复杂,并且热点与背景的对比度较低,会对热点的识别造成一定影响。

表明本模型检测更具有优势,尤其是在特征融合和背景抑制方面,梯度加权类激活映射算法的热力图也验证了该模型的感兴趣区域,突出了编码器融合模块和文本交叉注意力模块对模型最终性能的重要性。
3.5 模型泛化性能评估
为了验证本模型方法的实用性和鲁棒性,选择WGISD数据集和实地拍摄的数据集作为补充,共计9个葡萄品种6 843组带有定位标记的果穗标本,其中选择5 503个边界框作为训练数据,1 340个边界框作为验证数据,1 340个边界框作为测试数据进行实验。如表7所示,展示了本模型在9个葡萄品种的性能,其中mAP达到58.5%,mAP50为82.5%,mAP75为64.4%,mAR为77.1%,MAE为1.44,RMSE为2.19。
表7 GDCNet模型9个种类葡萄品种的实验结果Table 7 Experimental results of 9 grape varieties using GDCNet model |
| 指标 | mAP/% | mAP50/% | mAP75/% | mAR/% | mAP_s/% | mAP_m/% | mAP_l/% | mAR_s/% | mAR_m/% | mAR_l/% | epochs |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 数值 | 58.5 | 82.5 | 64.4 | 77.1 | 72.7 | 40.0 | 56.6 | 73.4 | 62.8 | 81.7 | 30 |
为了更直观展现本模型在9个种类葡萄品种的性能,绘制了经过50轮训练后的mAP、mAP50、mAP75和mAP_s曲线,如图9所示,可见本模型在多样化葡萄品种数据集的鲁棒性,具有较好的适应性和有效性。

另外,本研究通过精准识别葡萄串位置并统计结果数量,可实现对葡萄园总产的智能化评估,该技术能够应用于估算果园总产量、降低采前测产误差,以及避免因预估不准导致的供应链调配难题等,更有效地提升葡萄园的精细化管理水平。
4 结 论
本研究提出一种基于迁移学习的多模态葡萄检测框架,能够有效地解决不同葡萄品种的检测和产量估计问题。所提出的方法关键步骤在于利用在大规模公共数据集上预训练的模型提取特征;采用语言引导的查询选择模块,从图像特征中选择合适的跨模态查询,选择与目标密切相关的特征作为解码器的输入;使用跨模态解码器将文本特征注入查询中以获得更准确的模态对齐,从而实现对葡萄串的识别和定位。
基于WGISD基准数据集的测试验证,本研究提出的算法实现了53.2%的mAP和76.5%的mAR,在计数上的MAE的值为1.65,RMSE为2.48,这些结果证明了本研究的模型在葡萄产量估计上的有效性。总体而言,本研究在葡萄串检测和计数领域具有重要的实际应用价值,将为葡萄种植业的智能化发展提供重要技术支撑。
后续研究将重点探索以下几个方向:开发适用于现场部署的边缘计算设备,实现图像数据的实时处理,构建云端数据分析和存储平台,设计用户友好的可视化界面,为管理者提供决策支持,进一步提升系统的实用性和易用性。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}