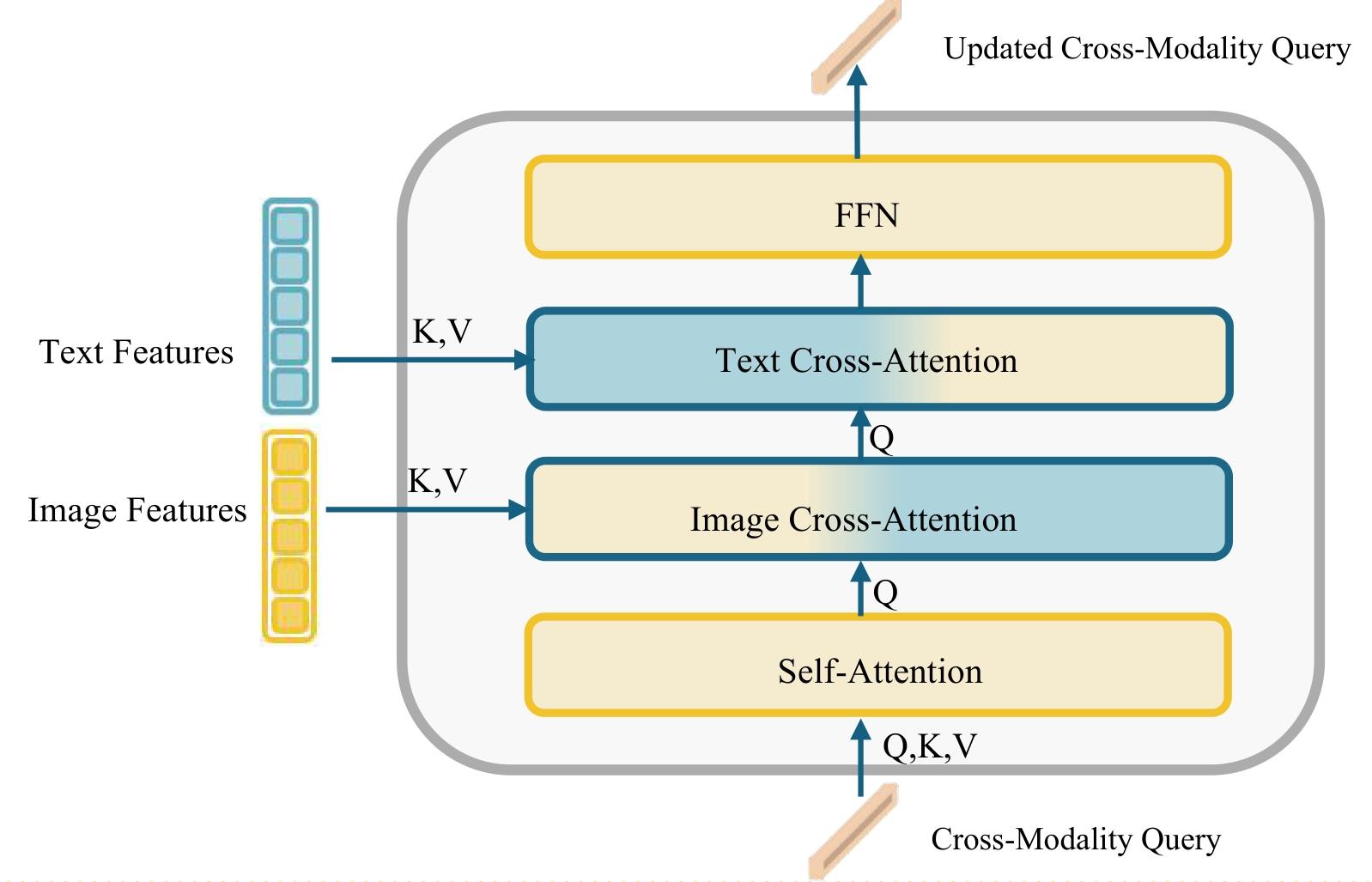
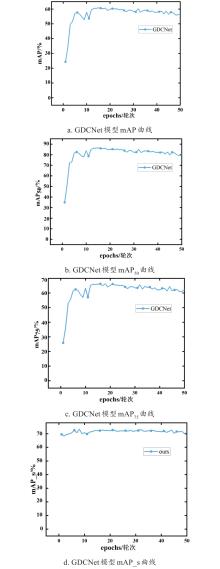
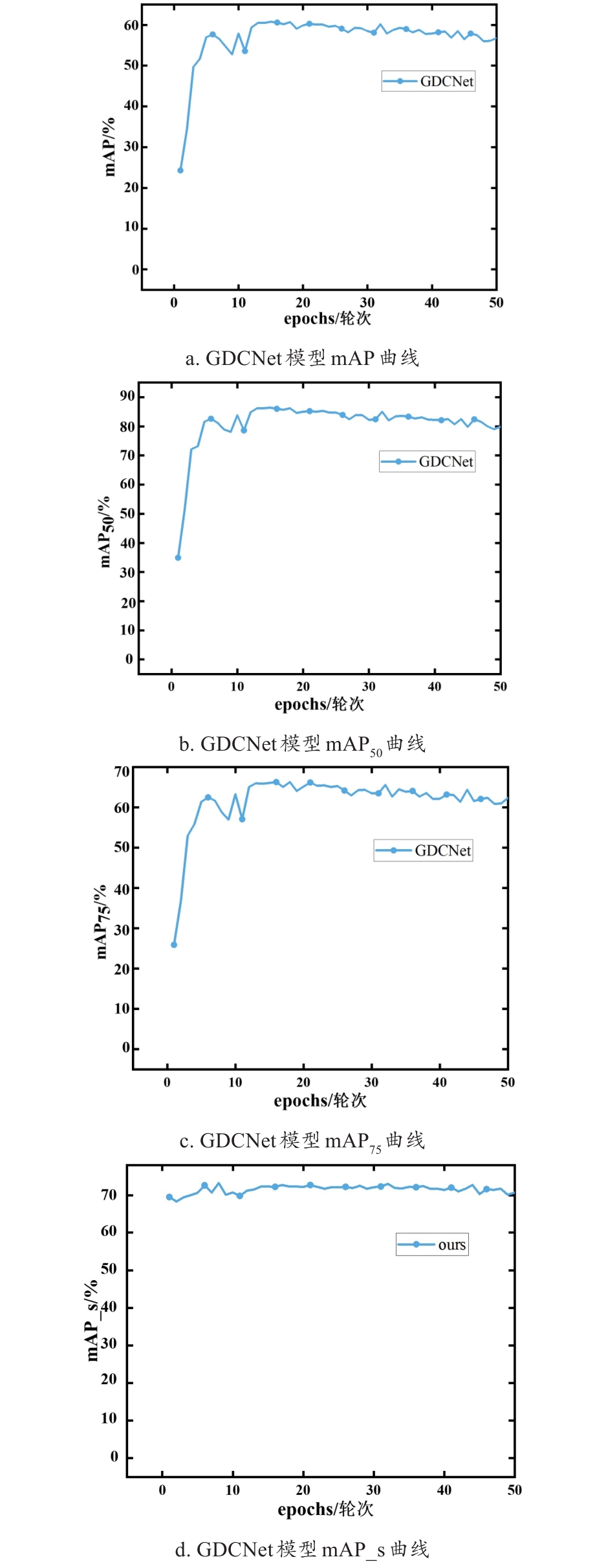
| [1] |
PALACIOS F, MELO-PINTO P, DIAGO M P, et al. Deep learning and computer vision for assessing the number of actual berries in commercial vineyards[J]. Biosystems engineering, 2022, 218: 175-188.
|
| [2] |
LIU S, COSSELL S, TANG J L, et al. A computer vision system for early stage grape yield estimation based on shoot detection[J]. Computers and electronics in agriculture, 2017, 137: 88-101.
|
| [3] |
WOHLFAHRT Y, COLLINS C, STOLL M. Grapevine bud fertility under conditions of elevated carbon dioxide[J]. OENO one, 2019, 53(2): ID 2428.
|
| [4] |
DE LA FUENTE M, LINARES R, BAEZA P, et al. Comparison of different methods of grapevine yield prediction in the time window between fruitset and veraison[J]. OENO one, 2016, 49(1): ID 27.
|
| [5] |
DIAGO M P, TARDAGUILA J, ALEIXOS N, et al. Assessment of cluster yield components by image analysis[J]. Journal of the science of food and agriculture, 2015, 95(6): 1274-1282.
|
| [6] |
CARRILLO E, MATESE A, ROUSSEAU J, et al. Use of multi-spectral airborne imagery to improve yield sampling in viticulture[J]. Precision agriculture, 2016, 17(1): 74-92.
|
| [7] |
SILVER D L, MONGA T. In vino veritas: Estimating vineyard grape yield from images using deep learning[M]// Advances in Artificial Intelligence. Cham: Springer International Publishing, 2019: 212-224.
|
| [8] |
BUAYAI P, SAIKAEW K R, MAO X Y. End-to-end automatic berry counting for table grape thinning[J]. IEEE access, 2021, 9: 4829-4842.
|
| [9] |
AQUINO A, MILLAN B, DIAGO M P, et al. Automated early yield prediction in vineyards from on-the-go image acquisition[J]. Computers and electronics in agriculture, 2018, 144: 26-36.
|
| [10] |
SHEN L, SU J Y, HE R T, et al. Real-time tracking and counting of grape clusters in the field based on channel pruning with YOLOv5s[J]. Computers and electronics in agriculture, 2023, 206: ID 107662.
|
| [11] |
张传栋, 高鹏, 亓璐, 等. 基于SAW-YOLO v8n的葡萄幼果轻量化检测方法[J]. 农业机械学报, 2024, 55(10): 286-294.
|
|
ZHANG C D, GAO P, QI L, et al. Lightweight detection method for young grape cluster fruits based on SAW-YOLO v8n[J]. Transactions of the Chinese society for agricultural machinery, 2024, 55(10): 286-294.
|
| [12] |
COVIELLO L, CRISTOFORETTI M, JURMAN G, et al. GBCNet: In-field grape berries counting for yield estimation by dilated CNNs[J]. Applied sciences, 2020, 10(14): ID 4870.
|
| [13] |
ZABAWA L, KICHERER A, KLINGBEIL L, et al. Detection of single grapevine berries in images using fully convolutional neural networks[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Piscataway, New Jersey, USA: IEEE, 2019: 2571-2579.
|
| [14] |
WANG Q, FAN X J, ZHUANG Z Q, et al. One to all: Toward a unified model for counting cereal crop heads based on few-shot learning[J]. Plant phenomics, 2024, 6: ID 271.
|
| [15] |
刘畅, 孙雨, 杨晶, 等. 基于3C-YOLOv8n和深度相机的葡萄识别与定位方法[J]. 智慧农业(中英文), 2024, 6(6): 121-131.
|
|
LIU C, SUN Y, YANG J, et al. Grape recognition and localization method based on 3C-YOLOv8n and depth camera[J]. Smart agriculture, 2024, 6(6): 121-131.
|
| [16] |
YU C H, SHI X Y, LUO W K, et al. MLG-YOLO: A model for real-time accurate detection and localization of winter jujube in complex structured orchard environments[J]. Plant phenomics, 2024, 6: ID 258.
|
| [17] |
DU W S, LIU P. Instance segmentation and berry counting of table grape before thinning based on AS-SwinT[J]. Plant phenomics, 2023, 5: ID 0085.
|
| [18] |
LU S L, LIU X Y, HE Z X, et al. Swin-transformer-YOLOv5 for real-time wine grape bunch detection[J]. Remote sensing, 2022, 14(22): ID 5853.
|
| [19] |
WANG J H, ZHANG Z Y, LUO L F, et al. SwinGD: A robust grape bunch detection model based on swin transformer in complex vineyard environment[J]. Horticulturae, 2021, 7(11): ID 492.
|
| [20] |
XIA L H, LIU J B, WU T. Depth estimation algorithm based on transformer-encoder and feature fusion[C]// 2024 7th International Conference on Advanced Algorithms and Control Engineering (ICAACE). Piscataway, New Jersey, USA: IEEE, 2024: 160-164.
|
| [21] |
WANG J H, ZHANG Z Y, LUO L F, et al. DualSeg: Fusing transformer and CNN structure for image segmentation in complex vineyard environment[J]. Computers and electronics in agriculture, 2023, 206: ID 107682.
|
| [22] |
AHMEDT-ARISTIZABAL D, SMITH D, KHOKHER M R, et al. An in-field dynamic vision-based analysis for vineyard yield estimation[J]. IEEE access, 2024, 12: 102146-102166.
|
| [23] |
ZHENG S J, WANG R J, ZHENG S T, et al. Adaptive density guided network with CNN and Transformer for underwater fish counting[J]. Journal of king Saud university-computer and information sciences, 2024, 36(6): ID 102088.
|
| [24] |
ZHANG C J, LIU T, WANG J X, et al. DeepPollenCount: A swin-transformer-YOLOv5-based deep learning method for pollen counting in various plant species[J]. Aerobiologia, 2024, 40(3): 425-436.
|
| [25] |
CECOTTI H, RIVERA A, FARHADLOO M, et al. Grape detection with convolutional neural networks[J]. Expert systems with applications, 2020, 159: ID 113588.
|
| [26] |
XUE X Q, NIU W D, HUANG J X, et al. TasselNetV2++: A dual-branch network incorporating branch-level transfer learning and multilayer fusion for plant counting[J]. Computers and electronics in agriculture, 2024, 223: ID 109103.
|
| [27] |
CAO B Y, ZHANG B H, ZHENG W, et al. Real-time, highly accurate robotic grasp detection utilizing transfer learning for robots manipulating fragile fruits with widely variable sizes and shapes[J]. Computers and electronics in agriculture, 2022, 200: ID 107254.
|
| [28] |
BAI Y H, GUO Y X, ZHANG Q, et al. Multi-network fusion algorithm with transfer learning for green cucumber segmentation and recognition under complex natural environment[J]. Computers and electronics in agriculture, 2022, 194: ID 106789.
|
| [29] |
CHEN D, LU Y Z, LI Z J, et al. Performance evaluation of deep transfer learning on multi-class identification of common weed species in cotton production systems[J]. Computers and electronics in agriculture, 2022, 198: ID 107091.
|
| [30] |
ZHA Z H, SHI D Y, CHEN X H, et al. Classification of appearance quality of red grape based on transfer learning of convolution neural network[J]. Agronomy, 2023, 13(8): ID 2015.
|
| [31] |
GAI R L, LIU Y, XU G H. TL-YOLOv8: A blueberry fruit detection algorithm based on improved YOLOv8 and transfer learning[J]. IEEE access, 2024, 12: 86378-86390.
|
| [32] |
SANTOS T T, DE SOUZA L L, DOS SANTOS A A, et al. Grape detection, segmentation, and tracking using deep neural networks and three-dimensional association[J]. Computers and electronics in agriculture, 2020, 170: ID 105247.
|
| [33] |
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers[M]// Computer Vision-ECCV 2020. Cham: Springer International Publishing, 2020: 213-229.
|
| [34] |
LI L H, ZHANG P C, ZHANG H T, et al. Grounded language-image pre-training[C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2022: 10955-10965.
|
| [35] |
ZHANG H, LI F, LIU S L, et al. DINO: DETR with improved DeNoising anchor boxes for end-to-end object detection[EB/OL]. arXiv: 2203.03605, 2022.
|
| [36] |
REDMON J, FARHADI A. YOLOv3: An incremental improvement[EB/OL]. arXiv: 1804.02767, 2018.
|
| [37] |
ZHANG S L, WANG X J, WANG J Q, et al. Dense distinct query for end-to-end object detection[C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2023: 7329-7338.
|
| [38] |
ZHU B J, WANG J F, JIANG Z K, et al. AutoAssign: Differentiable label assignment for dense object detection[EB/OL]. arXiv: 2007.03496, 2020.
|
| [39] |
ZHANG S F, CHI C, YAO Y Q, et al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2020: 9756-9765.
|
| [40] |
REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137-1149.
|
| [41] |
ZHANG H, CHANG H, MA B, et al. Dynamic R-CNN: Towards high quality object detection via dynamic training[C]// Computer Vision–ECCV 2020: 16th European Conference. Cham, Germany: Springer International Publishing, 2020: 260-275.
|
| [42] |
LU X, LI B Y, YUE Y X, et al. Grid R-CNN[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2019: 7355-7364.
|
| [43] |
GHIASI G, LIN T Y, LE Q V. NAS-FPN: Learning scalable feature pyramid architecture for object detection[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2019: 7029-7038.
|
| [44] |
Cao Y, Chen K, Loy C C, et al. Prime sample attention in object detection[C]// Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. Piscataway, New Jersey, USA: IEEE. 2020: 11583-11591.
|
| [45] |
LIU S L, ZENG Z Y, REN T H, et al. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection[EB/OL]. arXiv: 2303.05499, 2023.
|
| [46] |
SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: Visual explanations from deep networks via gradient-based localization[C]// 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, New Jersey, USA: IEEE, 2017: 618-626.
|
 )
)