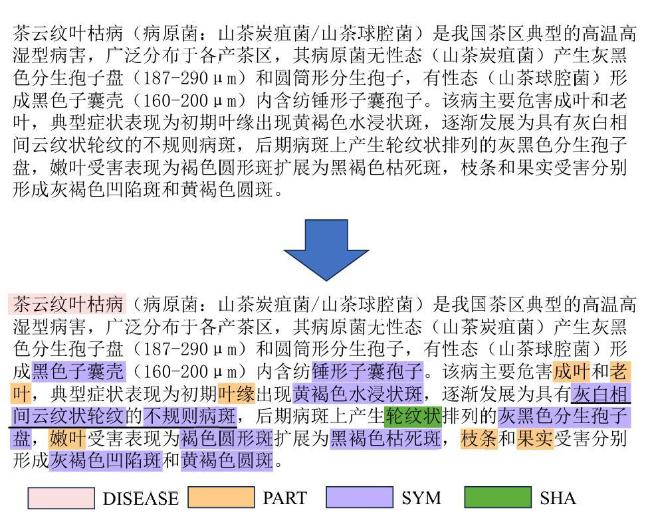
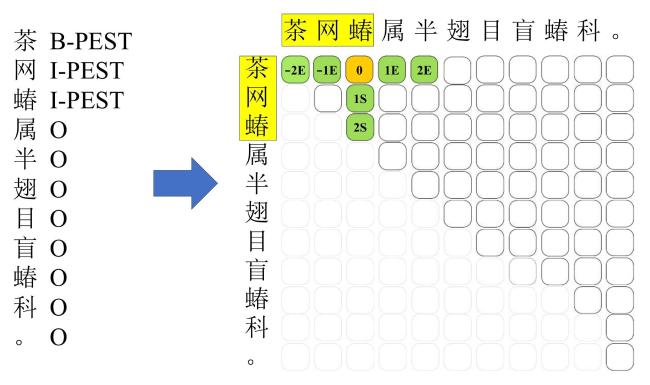
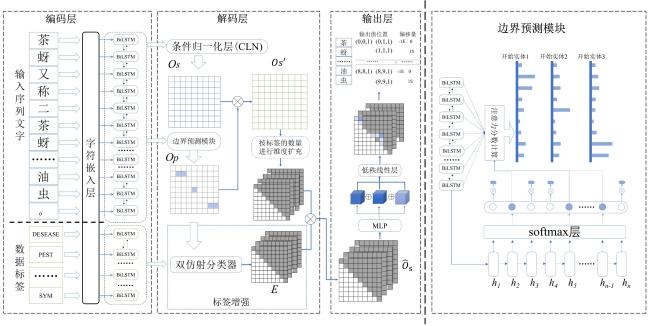
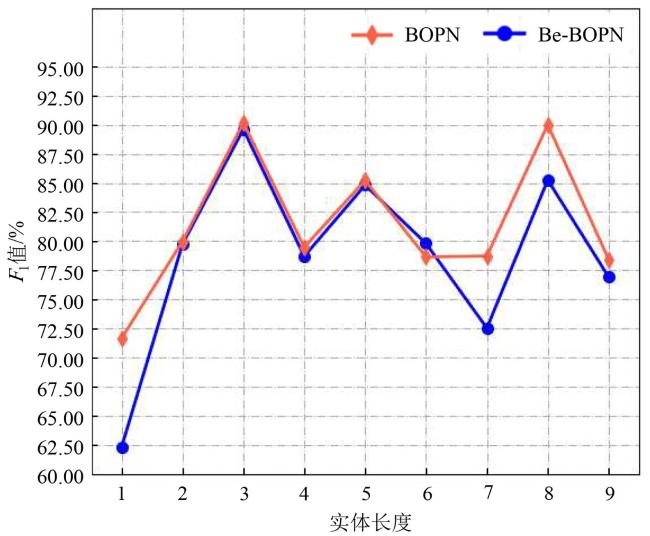
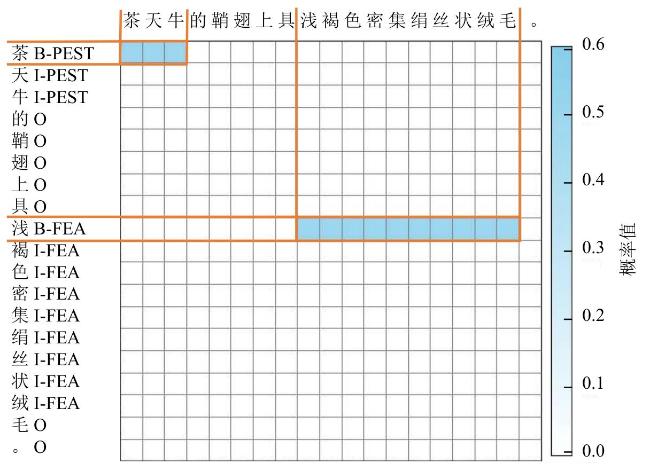
[Objective] Named entity recognition (NER) is vital for many natural language processing (NLP) applications, including information retrieval and knowledge graph construction. While Chinese NER has advanced with datasets like ResumeNER, WeiboNER, and CLUENER (Chinese language understanding evaluation NER), most focus on general domains such as news or social media. However, there is a notable lack of annotated data in specialized fields, particularly agriculture. In the context of tea pest and disease, this shortage hampers progress in intelligent agricultural information extraction. These domain-specific texts pose unique challenges for NER due to frequent nested and long-span entities, which traditional sequence labeling models struggle to handle. Issues such as boundary ambiguity further complicate accurate entity recognition, leading to poor segmentation and labeling performance. Addressing these challenges requires targeted datasets and improved NER techniques tailored to the agricultural domain. [Methods] The proposed model comprises two core modules specifically designed to enhance performance in BOPN (Boundary-Oriented and Path-aware Named Entity Recognition) tasks, particularly within domains characterized by complex and fine-grained entity structures, such as tea pest and disease recognition. The boundary prediction module was responsible for identifying entity spans within input text sequences. It employed an attention-based mechanism to dynamically estimate the probability that consecutive tokens belong to the same entity, thereby addressing the challenge of boundary ambiguity. This mechanism facilitated more accurate detection of entity boundaries, which was particularly critical in scenarios involving nested or overlapping entities. The label enhancement module further refines entity recognition by employing a biaffine classifier that jointly models entity spans and their corresponding category labels. This joint modeling approach enabled the capture of intricate interactions between span representations and semantic label information, improving the identification of long or syntactically complex entities. The output of this module was integrated with conditionally normalized hidden representations, enhancing the model's capacity to assign context-aware and semantically precise labels. In order to reduce computational complexity while preserving model effectiveness, the architecture incorporated low-rank linear layers. These were constructed by integrating the adaptive channel weighting mechanism of Squeeze-and-Excitation Networks with low-rank decomposition techniques. The modified layers replace traditional linear transformations, yielding improvements in both efficiency and representational capacity. In addition to model development, a domain-specific NER corpus was constructed through the systematic collection and annotation of entity information related to tea pest and disease from scientific literature, agricultural technical reports, and online texts. The annotated entities in the corpus were categorized into ten classes, including tea plant diseases, tea pests, disease symptoms, and pest symptoms. Based on this labeled corpus, a Chinese NER dataset focused on tea pest and disease was developed, referred to as the Chinese tea pest and disease dataset. [Results and Discussions] Extensive experiments were conducted on the constructed dataset, comparing the proposed method with several mainstream NER approaches, including traditional sequence labeling models (e.g., BiLSTM-CRF), lexicon-enhanced models (e.g., SoftLexicon), and boundary smoothing strategies (e.g., Boundary Smooth). These comparisons aimed to rigorously assess the effectiveness of the proposed architecture in handling domain-specific and structurally complex entity types. Additionally, to evaluate the model's generalization capability beyond the tea disease and pest domain, the study performed comprehensive evaluations on four publicly available Chinese NER benchmark datasets: ResumeNER, WeiboNER, CLUENER, and Taobao. Results showed that the proposed model consistently achieved higher F1-Scores improved across all used datasets: 0.68% on the self-built dataset, 0.29% on ResumeNER, 0.96% on WeiboNER, 0.7% on CLUENER, and 0.5% on Taobao. With particularly notable improvements in the recognition of complex, nested, and long-span entities. These outcomes demonstrate the model's superior capacity for capturing intricate entity boundaries and semantics, and confirm its robustness and adaptability when compared to current state-of-the-art methods. [Conclusions] The study presents a high-performance NER approach tailored to the characteristics of Chinese texts on tea pest and disease. By simultaneously optimizing entity boundary detection and label classification, the proposed method significantly enhanced recognition accuracy in specialized domains. Experimental results demonstrated strong adaptability and robustness of the model across both newly constructed and publicly available datasets, indicating its broad applicability and promising prospects.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}