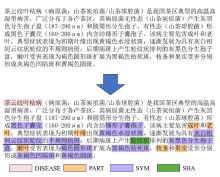
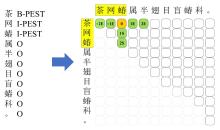
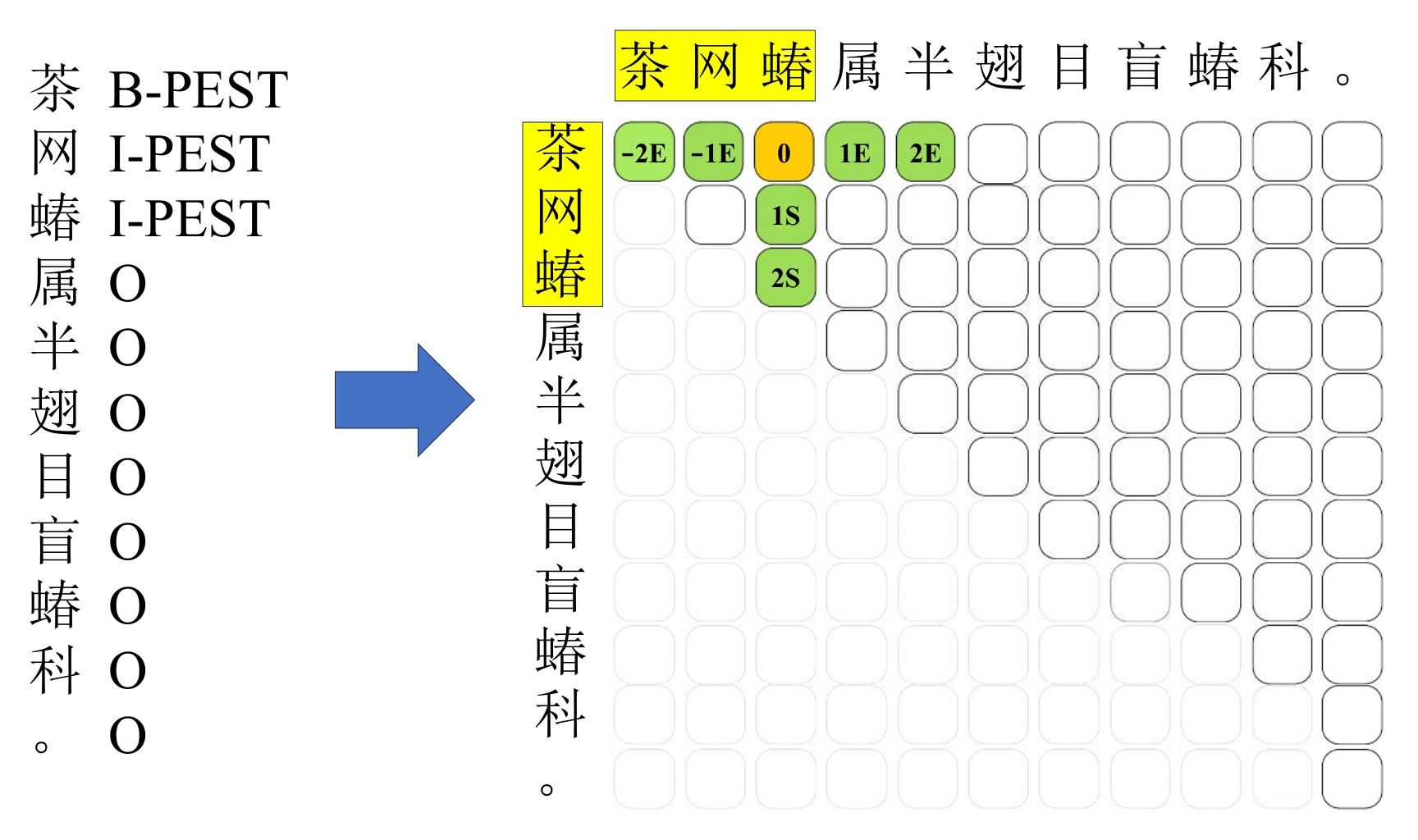
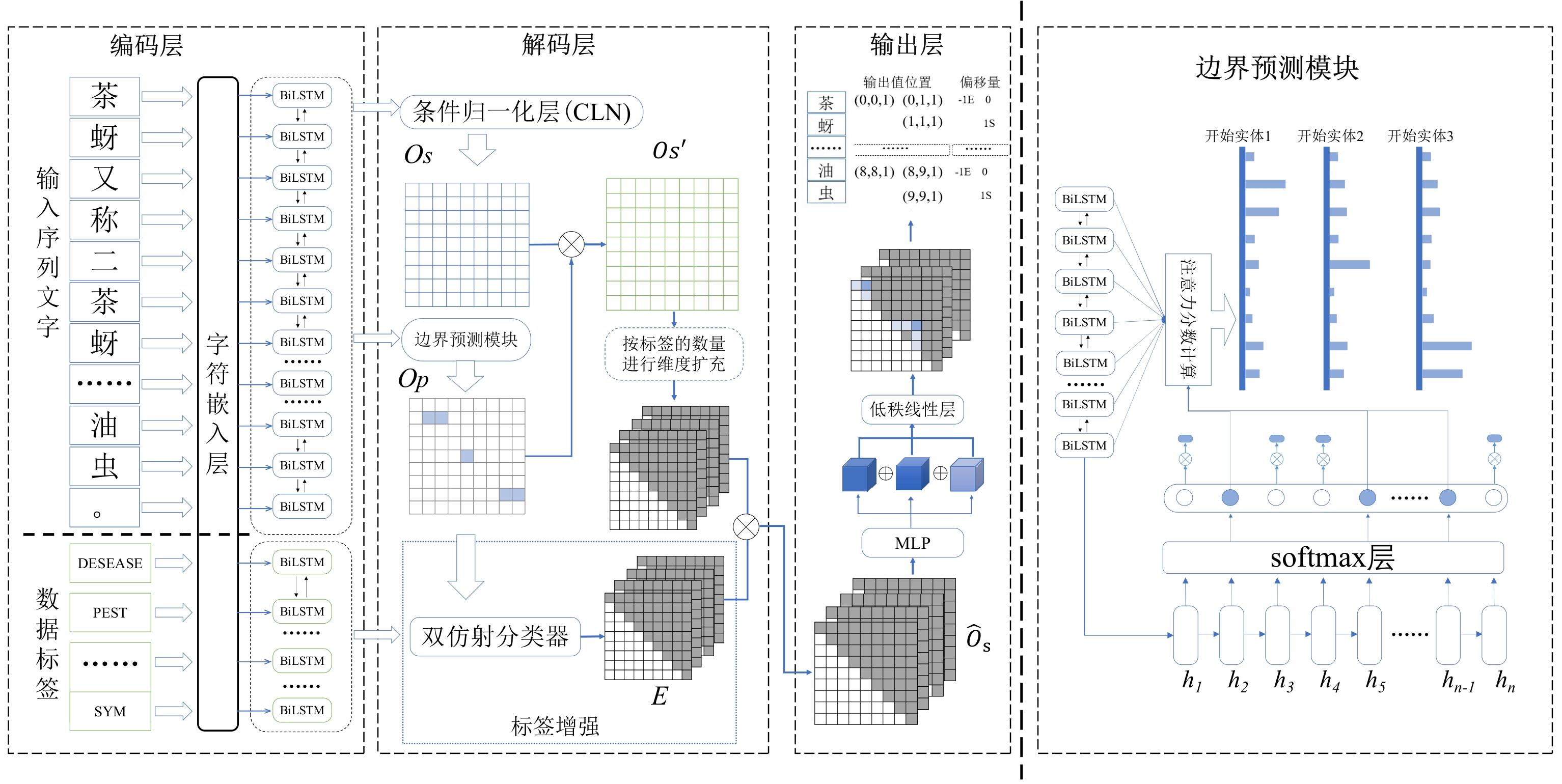
| [1] |
聂啸林, 张礼麟, 牛当当, 等. 面向葡萄知识图谱构建的多特征融合命名实体识别[J]. 农业工程学报, 2024, 40(3): 201-210.
|
|
NIE X L, ZHANG L L, NIU D D, et al. Multi-feature fusion named entity recognition method for grape knowledge graph construction[J]. Transactions of the Chinese society of agricultural engineering, 2024, 40(3): 201-210.
|
| [2] |
王彤, 王春山, 李久熙, 等. 基于RoFormer预训练模型的指针网络农业病害命名实体识别[J]. 智慧农业(中英文), 2024, 6(2): 85-94.
|
|
WANG T, WANG C S, LI J X, et al. Agricultural disease named entity recognition with pointer network based on RoFormer pre-trained model[J]. Smart agriculture, 2024, 6(2): 85-94.
|
| [3] |
齐梓均, 牛当当, 吴华瑞, 等. 基于双维信息与剪枝的中文猕猴桃文本命名实体识别方法[J]. 智慧农业(中英文), 2025, 7(1): 44-56.
|
|
QI Z J, NIU D D, WU H R, et al. Chinese kiwifruit text named entity recognition method based on dual-dimensional information and pruning[J]. Smart agriculture, 2025, 7(1): 44-56.
|
| [4] |
贺子康, 杨勇, 杨国峰, 等. 基于BERT-BiLSTM-CRF的农产品信息文本命名实体识别研究及应用展望[J]. 农业展望, 2022, 18(5): 105-111.
|
|
HE Z K, YANG Y, YANG G F, et al. Research on named entity recognition of agricultural products information text and its application prospect based on BERT-BiLSTM-CRF[J]. Agricultural outlook, 2022, 18(5): 105-111.
|
| [5] |
陈瑛, 张晓强, 陈昂轩, 等. 基于信息抽取的食品安全事件自动问答系统方法研究[J]. 农业机械学报, 2020, 51(S2): 442-448.
|
|
CHEN Y, ZHANG X Q, CHEN A X, et al. Methods of food safety question answering system based on LSTM[J]. Transactions of the Chinese society for agricultural machinery, 2020, 51(S2): 442-448.
|
| [6] |
韦婷婷, 葛晓月, 熊俊涛. 基于层级多标签的农业病虫害问句分类方法[J]. 农业机械学报, 2024, 55(1): 263-269, 435.
|
|
WEI T T, GE X Y, XIONG J T. Hierarchical multi-label classification of agricultural pest and disease interrogative questions[J]. Transactions of the Chinese society for agricultural machinery, 2024, 55(1): 263-269, 435.
|
| [7] |
朱张莉, 饶元, 吴渊, 等. 注意力机制在深度学习中的研究进展[J]. 中文信息学报, 2019, 33(6): 1-11.
|
|
ZHU Z L, RAO Y, WU Y, et al. Research progress of attention mechanism in deep learning[J]. Journal of Chinese information processing, 2019, 33(6): 1-11.
|
| [8] |
李金鹏, 张闯, 陈小军, 等. 自动文本摘要研究综述[J]. 计算机研究与发展, 2021, 58(1): 1-21.
|
|
LI J P, ZHANG C, CHEN X J, et al. Survey on automatic text summarization[J]. Journal of computer research and development, 2021, 58(1): 1-21.
|
| [9] |
LAMPLE G, BALLESTEROS M, SUBRAMANIAN S, et al. Neural architectures for named entity recognition[EB/OL]. arXiv: 1603.01360, 2016.
|
| [10] |
TJONG KIM SANG E F, BUCHHOLZ S. Introduction to the CoNLL-2000 shared task: Chunking[C]// Proceedings of the 2nd Workshop on Learning Language in Logic and the 4th Conference on Computational Natural Language Learning. Morristown, NJ, USA: ACL, 2000: 127.
|
| [11] |
XUE N W. Chinese word segmentation as character tagging[J]// International Journal of Computational Linguistics & Chinese Language Processing (IJCLCLP), 2003, 8(1): 29-48.
|
| [12] |
SOHRAB M G, MIWA M. Deep exhaustive model for nested named entity recognition[C]// Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, Pennsylvania, USA: ACL, 2018: 2843-2849.
|
| [13] |
LEE K, HE L, LEWIS M, et al. End-to-end neural coreference resolution [C]// Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP). Stroudsburg, Pennsylvania, USA:ACL, 2017: 188-197.
|
| [14] |
MARKUS E, ADRIAN U. Span-based joint entity and relation extraction with transformer pre-training[M]// ECAI 2020. Santiago de Compostela, Spain: IOS Press, 2020.
|
| [15] |
JOSHI M, CHEN D Q, LIU Y H, et al. SpanBERT: Improving pre-training by representing and predicting spans[J]. Transactions of the association for computational linguistics, 2020, 8: 64-77.
|
| [16] |
TAN C Q, QIU W, CHEN M S, et al. Boundary enhanced neural span classification for nested named entity recognition[J]. Proceedings of the AAAI conference on artificial intelligence, 2020, 34(5): 9016-9023.
|
| [17] |
YU J T, BOHNET B, POESIO M. Named entity recognition as dependency parsing[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, Pennsylvania, USA: ACL, 2020: 6470-6476.
|
| [18] |
SHEN Y L, MA X Y, TAN Z Q, et al. Locate and label: A two-stage identifier for nested named entity recognition[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. Stroudsburg, Pennsylvania, USA: ACL, 2021: 2782-2794.
|
| [19] |
YUAN Z, TAN C Q, HUANG S F, et al. Fusing heterogeneous factors with triaffine mechanism for nested named entity recognition[C]// Findings of the Association for Computational Linguistics: ACL 2022. Stroudsburg, Pennsylvania, USA: ACL, 2022: 3174-3186.
|
| [20] |
LI J Y, FEI H, LIU J, et al. Unified named entity recognition as word-word relation classification[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Washington, D.C., USA: AAAI, 2022: 10965-10973.
|
| [21] |
CAI Y X, LIU Q, GAN Y L, et al. DiFiNet: Boundary-aware semantic differentiation and filtration network for nested named entity recognition[C]// Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, Pennsylvania, USA: ACL, 2024: 6455-6471.
|
| [22] |
TANG M H, HE Y Q, XU Y X, et al. A boundary offset prediction network for named entity recognition[C]// Findings of the Association for Computational Linguistics: EMNLP 2023. Singapore. Stroudsburg, Pennsylvania, USA: ACL, 2023: 14834-14846.
|
| [23] |
LI F, WANG Z, HUI S C, et al. Modularized interaction network for named entity recognition[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, Pennsylvania, USA: ACL, 2021: 200-209.
|
| [24] |
LI J, SUN A X, MA Y K. Neural named entity boundary detection[J]. IEEE transactions on knowledge and data engineering, 2021, 33(4): 1790-1795.
|
| [25] |
ULYANOV DMITRY, VEDALDI ANDREA, LEMPITSKY VICTOR. Instance normalization: The missing ingredient for fast stylization[EB/OL]. arXiv: 1607.08022, 2017.
|
| [26] |
TIMOTHY DOZAT, MANNING CHRISTOPHER D.. Deep biaffine attention for neural dependency parsing[EB/OL]. arXiv: 1611.01734, 2016.
|
| [27] |
ZHANG Y, YANG J. Chinese NER using lattice LSTM[C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, Pennsylvania, USA: ACL, 2018: 1554-1564.
|
| [28] |
PENG N Y, DREDZE M. Named entity recognition for Chinese social media with jointly trained embeddings[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Stroudsburg, Pennsylvania, USA: ACL, 2015: 548-554.
|
| [29] |
XU L, DONG Q, LIAO Y, et al. CLUENER2020: Fine-grained named entity recognition dataset and benchmark for Chinese[EB/OL]. arXiv: 2001.04351, 2020.
|
| [30] |
JIE Z M, XIE P J, LU W, et al. Better modeling of incomplete annotations for named entity recognition[C]// Proceedings of the 2019 Conference of the North. Stroudsburg, Pennsylvania, USA: ACL, 2019: 729-734.
|
| [31] |
MIWA M, BANSAL M. End-to-end relation extraction using LSTMs on sequences and tree structures[C]// Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, Pennsylvania, USA: ACL, 2016: 1105-1116.
|
| [32] |
LI X N, YAN H, QIU X P, et al. FLAT: Chinese NER using flat-lattice transformer[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, Pennsylvania, USA: ACL, 2020: 6836-6842.
|
| [33] |
MA R T, PENG M L, ZHANG Q, et al. Simplify the usage of lexicon in Chinese NER[C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Stroudsburg, Pennsylvania, USA: ACL, 2020: 5951-5960.
|
| [34] |
WU S, SONG X N, FENG Z H. MECT: Multi-metadata embedding based cross-transformer for Chinese named entity recognition[C]// Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Stroudsburg, Pennsylvania, USA: ACL, 2021: 1529-1539.
|
| [35] |
ZHU E W, LI J P. Boundary smoothing for named entity recognition[C]// Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Stroudsburg, Pennsylvania, USA: ACL, 2022: 7096-7108.
|
 ), 张尧, 李芳
), 张尧, 李芳