



0 引 言
目前,国内外对香菇识别和分类的研究已经取得了一定成果。在早期,由于硬件设备的限制,食用菌的检测主要依赖传统的图像处理算法[5, 6]。随着深度学习和机器视觉技术的快速发展,各类目标检测模型逐渐应用于农作物的识别与分类中,如Faster区域卷积神经网络(Faster Region-Based Convolutional Neural Network, Faster R-CNN)[7]、掩膜区域卷积神经网络(Mask Region-based Convolutional Neural Network, Mask R-CNN[8])、单次多框检测器(Single Shot MultiBox Detector, SSD[9]),以及 YOLO[10-12]系列模型。Satokawa等[13]通过应用形态学变换和Canny边缘检测方法增强图像特征,将香菇分类为开伞或闭伞类型,在测试中达到了95.6%的准确率。Ye等[14]提出了一种专门用于检测香菇小目标的改进YOLOv8模型,通过结合Swin Transformer和可变形卷积在Fungi数据集上取得了98.49%的AP50(Average Precision at IoU=0.50)。Liu等[15]利用通道剪枝优化了YOLOX模型,用于香菇质量分类,达到了99.96%的均值平均精度(Mean Average Precision, mAP),且模型大小减少了一半以上。Deng等[16]开发了一个基于深度学习的无线视觉传感器系统,用于自动化香菇分拣,实际分拣系统达到了98.53%的准确率。Amiruddin等[17]提出了一种基于机器学习的自动化蘑菇分类系统,用于区分蚝菇。该系统通过机器视觉训练、分类扩展和注释,蘑菇识别准确率超过了90%。Wang等[18]提出了一种基于Mask R-CNN的空间通道转换网络用于高效的蘑菇实例分割,该方法结合了Mask R-CNN和自注意力机制,在空间和通道维度提取图像特征,实现了多尺度局部特征融合。尽管上述研究在香菇图像识别、小目标检测或质量分类等方面取得了一定成效,但多数方法主要面向单个食用菌个体或特定品种的分类任务,难以满足工厂化生产环境下对高精度与高鲁棒性检测的实际需求。此外,现有模型的特征提取模块普遍缺乏区分香菇表面与原木背景之间细微纹理差异的能力,且未针对如未成熟香菇等小目标进行专门优化,限制了其在菌棒栽培环境中复杂场景下的检测性能。
针对香菇工厂采收过程中的评价需求,本研究在RT-DETR基础上提出了改进的FSE-DETR模型。相比原模型,FSE-DETR在主干网络中引入了FasterNet模块替代HGNetv2,降低模型参数并减少计算复杂度;在编码器部分,重新设计了跨尺度特征融合模块,构建小目标特征融合网络,使用空间到深度卷积(Space-to-Depth Conv, SPDConv)和跨阶段全核模块(Cross Stage Partial Omni-Kernel Module, CSPOmniKernel)减少细节信息的丢失,保留香菇的细粒度特征;在损失函数上采用高效交并比(Efficient Intersection over Union, EIoU)损失函数,加快模型收敛速度并提高目标定位精度。
1 研究数据


经过统一裁剪和缩放去除无关背景后,这些图像以JPG格式保存,分辨率像素为1 920×1 080,共计800张图像。收集到图像后,使用LabelImg对数据进行标注,共包含四个类别:immature(未成熟香菇)、flower(花香菇)、smooth cap(光帽香菇)和defective(残缺香菇)。香菇的分类依据参考了山东省某香菇生产企业的分级标准,结合香菇的菌盖大小、外观结构和完整性进行人工标注,评价标准如表1所示。具体来说,根据香菇工厂的采摘标准,首先根据香菇的直径进行初步分类。直径小于4 cm的香菇被归类为未成熟香菇,不进行采摘或质量评估。直径大于4 cm的香菇被认为是成熟香菇,符合采摘标准。成熟香菇进一步细分为花菇、光帽香菇和残缺香菇。花菇的菌盖呈圆形或椭圆形,表面有裂纹,形成花状或网状图案。它们需要严格控制空气湿度和光照,营养价值高,售价也较高。光帽香菇也呈圆形或椭圆形,但菌盖光滑无裂纹。这种类型是市场上最常见的香菇,价格适中,工厂产量最高。形状不规则或损坏的香菇被归类为残缺香菇,通常用于制作香菇酱等产品。
表1 香菇评价标准Table 1 Grading standards for shiitake mushrooms |
| 种类 | 标签名称 | 菌盖直径 | 菌盖特征 | 是否采摘 |
|---|---|---|---|---|
| 花香菇 | flower | ≥4 cm | 呈圆形或椭圆形状,且菌盖开裂形成花状或网状图案 | 是 |
| 光帽香菇 | smooth cap | ≥4 cm | 呈圆形或椭圆形状,且表面光滑没有裂纹 | 是 |
| 残缺香菇 | defective | ≥4 cm | 呈不规则形状,或菌盖表面凹陷,或菌盖破损 | 是 |
| 未成熟香菇 | immature | <4 cm | 不予判断 | 否 |
为了保证数据更好地反映香菇工厂内部真实情况,防止模型训练过程中出现过拟合现象,采用了数据增强技术来处理图像[23],添加旋转、翻转、方差为0.06的高斯噪声与椒盐噪声和不同程度的模拟遮挡来扩充数据集,扩充后的数据集共计4 000张图片,并将数据集按照7∶2∶1的比例随机划分为训练集、验证集和测试集。
2 基于改进RT-DETR的菌棒栽培香菇检测方法
2.1 FSE-DETR香菇检测模型
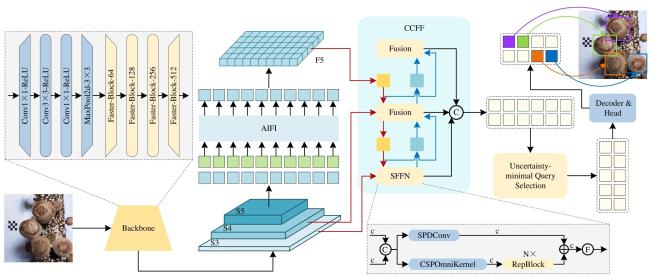
针对香菇工厂采收过程中香菇分布密集、小目标比例高,以及不同等级香菇外形差异等特点,同时为降低模型的计算复杂度并适应实际部署需求,本研究基于RT-DETR设计了一种改进的香菇检测模型——FSE-DETR。该模型主要由主干网络、特征编码网络和解码预测网络三部分组成。
输入一张原始分辨率的香菇菌棒图像,经过缩放和填充操作后,将其转换为适合模型输入的分辨率,并送入FSE-DETR模型进行推理,模型结构如图3所示。在FSE-DETR模型主干网络中使用FasterNet模块,用于提取多尺度特征图。这些特征从高级阶段(S3、S4、S5)中提取,并送入特征编码网络。在特征编码网络中,利用基于注意力的尺度内特征交互模块(Attention-based Intra-scale Feature Interaction, AIFI)和基于CNN的跨尺度特征融合模块(CNN-based Cross-scale Feature Fusion, CCFF),对各个尺度的特征进行交互和融合,将多层次特征转换为图像特征向量,对跨尺度特征融合模块进行重新设计,通过小目标特征融合网络(Small Object Feature Fusion Network, SFFN)中的SPDConv和CSPOmniKernel以增强对小目标特征的处理能力。随后,特征图被输入到解码器中,通过最小不确定性驱动的查询选择机制,从编码网络提取特征作为初始查询。解码过程中引入EIoU损失函数,以提升模型的收敛性和目标定位效果。解码器经过多轮迭代优化,配合辅助预测头,最终生成预测框和置信度评分。
2.2 FasterNet模块
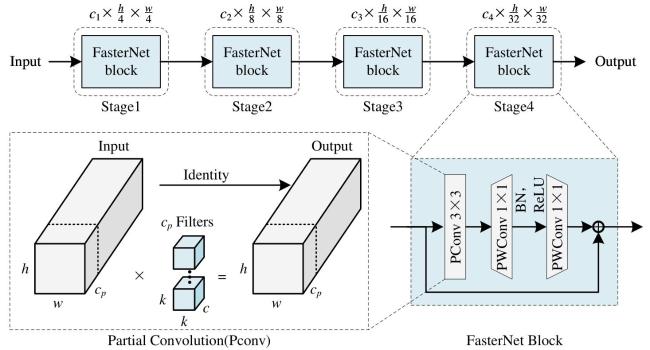
FasterNet所组成的主干网络由四个阶段组成,每个阶段包含一个 FasterNet模块,特征图的通道数量和空间尺寸在各阶段逐步变化,Stage 1输出通道数为 ,特征图空间尺寸为 ,Stage 2输出通道数为 ,特征图空间尺寸变为 ,Stage 3输出通道数为 ,空间尺寸为 ,Stage 4输出通道数为 ,空间尺寸进一步变为 。PConv通过仅对输入特征图的一部分通道进行卷积操作,保留其余通道不变,从而降低冗余计算和内存访问的次数。计算部分卷积时,浮点运算数( )如公式(1) 所示。
式中: 和 为特征图的高度和宽度; 为卷积核的大小; 为参与卷积的通道数量。在PConv之后,紧接着使用PWConv,即1 1的卷积,来有效地整合所有通道的信息。PConv与PWConv的组合的浮点运算数( )计算为公式(2) 。
式中: 表示输出特征图的通道数。FasterNet模块的设计目标是在保证模型精度的前提下,通过高效卷积操作减少计算开销,使得网络更轻量化且适用于资源受限的场景。
2.3 小目标特征融合网络
小目标特征融合网络(Small Object Feature Fusion Network, SFFN)的目的是优化小目标的特征提取与融合,同时保留蘑菇表面的纹理和边缘形状等细粒度特征,从而提升整体检测性能。SFFN主要接收来自P3层的底层特征信息,以充分利用其较高的空间分辨率和丰富的细节信息,捕捉小目标的特征。然而,由于P3层的语义信息较弱,单独依赖该层无法全面表达全局与局部特征。因此,SFFN结合了SPDConv与CSPOmniKernel模块,在保留P3层细粒度特征的同时,通过多尺度特征融合增强全局语义信息的表达能力。这显著提升了对未成熟香菇等小目标的检测精度,并更好地保留了香菇的纹理与边缘细节。
2.3.1 SPDConv空间到深度卷积
在RT-DETR的特征编码网络中,使用基于注意力的尺度内特征交互模块(Attention Based Intra-scale Feature Interaction, AIFI)和基于卷积神经网络的跨尺度特征融合(CNN-based Cross-Scale Feature Fusion, CCFF)对各个尺度的特征进行交互和融合,其中跨尺度特征融合模块使用普通卷积层(Conv)用于特征提取。卷积神经网络已在许多计算机视觉任务中取得了显著成功,然而,由于现有的卷积网络通常使用步幅卷积和池化层,导致了细粒度信息的丢失和特征表示学习效率的下降。因此,通过引入SPDConv[25],网络能够更有效地捕捉小目标的细节特征,改善未成熟香菇的检测表现,如图5所示。

改进后模型SPDConv的主要工作:1)在特征提取阶段,通过在主干网络中引入SPD层,将原始特征图 (尺寸为 )划分为多个子特征图序列。每个子特征图将 以scale的因子进行降采样。当scale=2时,得到四个子特征图f 0,0,f 1,0,f 0,1,f 1,1,其每个形状为S/2,S/2,C 1,SPD通过按比例缩小空间维度,并将这些子特征图在通道维度上进行拼接,生成新的特征图 ,其尺寸为S/scale,S/scale,scale2 C 1。2)在卷积操作中,由传统的步幅卷积转变为非步幅卷积(即步幅为1的卷积层)。与步幅卷积不同,非步幅卷积通过避免跳跃采样,确保所有的细粒度特征信息得以保留。卷积后,特征图的尺寸转换为S/scale,S/scale,C 2,其中 通常小于 。这种卷积方式有效地缩小了特征图的空间维度,同时避免信息丢失,提高了小目标的检测精度。
2.3.2 CSPOmniKernel跨阶段全核模块
CSPOmniKernel首先通过CSP结构将输入特征划分为两部分,其中一部分作为恒等映射分支直接保留,以保持特征的完整性,另一部分经过OmniKernel模块处理,以增强特征的多尺度表示能力。OmniKernel模块包含局部分支、上下文分支和全局分支三部分,如图6所示。
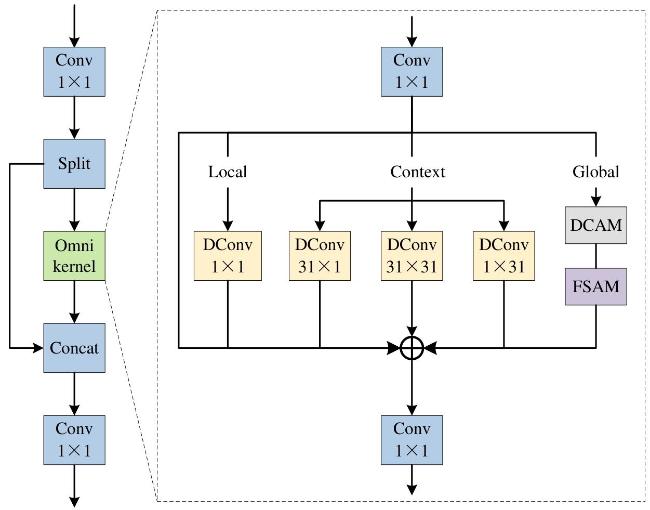
局部分支采用1×1的深度卷积(Depthwise Convolution, DConv),专注于局部信号的调制,提取局部细节和精细特征,以补充上下文和全局分支的不足。DConv对每个输入通道独立卷积,减少了计算量和参数量,提升计算效率。上下文分支采用31×31、1×31和31×1三种卷积核进行并行计算,分别用于捕捉大尺度的空间信息和水平、垂直方向的细节特征。全局分支通过双域通道注意力模块(Dual-domain Channel Attention Module, DCAM)和基于频率的空间注意模块(Frequency-Based Spatial Attention Module, FSAM)来增强全局特征的捕捉能力,如图7所示。
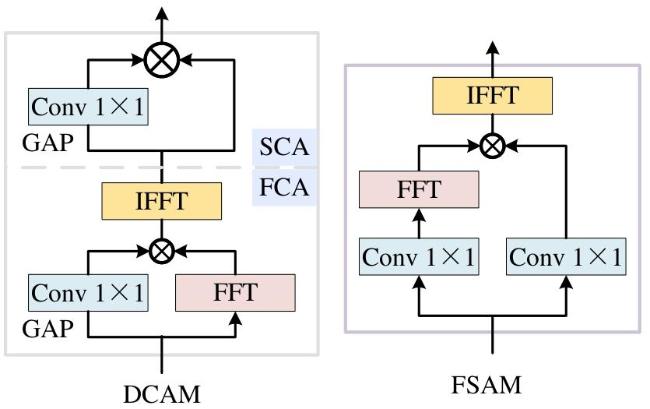
在全局分支中,首先通过DCAM在频域和空间域上对特征进行调制。DCAM由频率通道注意模块(Frequency Channel Attention, FCA)和空间通道注意模块(Spatial Channel Attention, SCA)组成,给定输入特征 ,首先经过1 1卷积操作和全局平均池化(Global Average Pooling, GAP)计算通道全局统计量,然后通过快速傅里叶变换(Fast Fourier Transform, FFT)将特征映射到频域,通过FCA对全局特征进行优化,即 ,具体计算过程如公式(3) 所示。
式中: 和 分别表示FFT及其逆傅里叶变换(Inverse Fast Fourier Transform, IFFT); 为全局平均池化; 为1×1卷积层; 表示逐元素相乘操作。FCA模块通过在频域上调制全局特征,以优化频谱信息。随后,FCA的输出特征经过SCA进一步进行精细化调整,即 ,其过程为公式(4) 。
式中: 表示SCA中使用的1×1卷积核的权重矩阵。SCA通过在通道级别上增强特征,实现更加精细的特征调制。通过DCAM的处理后,输出特征进入基于频率的FSAM进一步进行细粒度的优化,即 。在FSAM中,输入特征首先通过FFT转换至频域,再经过两个并行的1 1卷积操作进行降维和特征提取,随后通过IFFT返回空间域,生成的空间域特征通过交叉空间学习策略实现全局特征的聚合和像素级关系的捕捉,具体计算为公式(5) :
通过FSAM,模型可以集中优化关键频率成分,并结合空间域信息,提升细节特征的提取精度,从而增强空间和通道之间的特征交互,实现更精确的多尺度特征表达。
2.4 损失函数优化
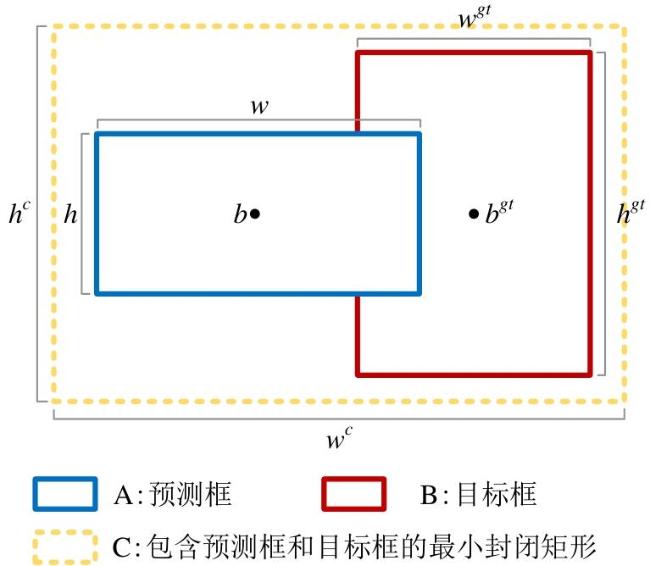
EIoU损失包括三个部分:IoU损失、距离损失( )和高宽损失( )。距离损失通过计算目标框和真实框中心点的欧氏距离,使得模型在定位目标时更加准确。高宽损失则通过分别计算目标边界框和真实边界框的高度和宽度的差异,直接最小化两者之间的差异,从而提高模型的尺寸匹配能力。EIoU的损失函数如公式(6) 所示:
式中: 、 和 分别表示IoU损失、距离损失和高宽损失; 和 分别表示包含预测框和目标框的最小外包矩形的宽度和高度, 、 、 和 分别表示预测框和目标框的宽度和高度。目标框是在数据标注过程中标注的实际位置,而预测框是模型在训练或推理时得出的估计结果。 表示预测框中心点 与目标框中心点 之间的欧氏距离的平方,具体计算方式为公式(7) 。
式中: , 和 , 为两个点的坐标。 和 分别表示预测框和目标框的中心点。
通过引入EIoU损失函数,通过独立优化目标框和真实框的长宽比,并结合IoU损失、中心点距离损失与高宽损失,使模型收敛速度加快,边界框拟合更精准,从而提升RT-DETR在香菇采收评价中的定位精度。
3 结果与分析
3.1 实验设置
本实验采用Win10操作系统,CPU为Intel Core i9-10900k@3.7 GHz,GPU为NVIDIA GeForce RTX 4090,显卡容量4 GB GDDR5;深度学习框架采用PyTorch 2.0.1,Python版本为3.9,CUDA版本为11.8;开发环境使用PyCharm代码集成开发环境,另配合OpenCV用于图像处理。
在实际实验中,为了合理比较,所有模型的超参数设置相同,部分参数设置如下:输入图像尺寸为640×640像素;训练轮次(epochs)设置为200轮;批次大小(batch size)为16;每次训练时并行处理的工作线程数(workers)为8;初始学习率设置为 0.000 1;使用权重衰减自适应矩估计(Adaptive Moment Estimation with Weight Decay, AdamW)作为优化器。
3.2 FSE-DETR模型消融实验结果
本研究设计了8组消融实验,分别使用FasterNet模块、小目标特征融合网络和EIoU损失函数改进RT-DETR网络,所得消融实验结果如表2所示。
表2 FSE-DETR模型消融实验结果Table 2 Ablation experiment results of the FSE-DETR model |
| 试验 | FasterNet | SFFN | EIoU | 准确率/% | 召回率/% | mAP50/% | 模型参数量/M | 浮点运算次数FLOPs/ G |
|---|---|---|---|---|---|---|---|---|
| 1 | 92.8 | 90.8 | 93.3 | 19.8 | 57.0 | |||
| 2 | √ | 92.6 | 91.2 | 93.9 | 15.5 | 51.3 | ||
| 3 | √ | 93.8 | 92.2 | 94.3 | 23.4 | 65.2 | ||
| 4 | √ | 93.1 | 91.1 | 93.7 | 19.8 | 57.0 | ||
| 5 | √ | √ | 94.3 | 92.6 | 94.2 | 19.1 | 57.7 | |
| 6 | √ | √ | 93.7 | 91.7 | 93.5 | 15.5 | 51.3 | |
| 7 | √ | √ | 94.5 | 92.3 | 94.6 | 23.4 | 65.2 | |
| 8 | √ | √ | √ | 95.8 | 93.1 | 95.3 | 19.1 | 53.6 |
在消融实验中,逐步引入FasterNet模块、SFFN和EIoU损失函数,以验证各改进对RT-DETR模型性能的提升效果。引入FasterNet后,模型的mAP50提高了0.6个百分点,同时参数量和FLOPs显著降低,体现出轻量化优势。小目标特征融合网络的加入有效增强小目标特征提取能力,召回率提升至92.2%,mAP50达94.3%。在此基础上引入EIoU损失函数后,mAP50提升至94.6%。最终,综合引入上述三种改进的模型准确率达95.8%,召回率93.1%,mAP50为95.3%,在精度、召回率与模型复杂度之间实现了良好平衡。
3.3 小目标特征融合网络实验结果
为了更好地验证小目标特征融合网络对不同类别香菇实体的检测能力,对光帽香菇、未成熟香菇、花香菇和残缺香菇四个类别的mAP50进行对比分析,以评估各改进方案在不同类别的性能表现,具体对比结果如表3所示。
表3 FSE-DETR模型在不同香菇类别上的平均精度均值对比 ( %)Table 3 Comparison of mean average precision of the FSE-DETR model across different shiitake mushroom categories |
| 类别 | RT-DETR | RT-DETR + SFFN | FSE-DETR |
|---|---|---|---|
| 光帽香菇 | 94.6 | 95.4 | 95.5 |
| 未成熟香菇 | 92.7 | 94.6 | 95.1 |
| 花香菇 | 93.5 | 94.1 | 95.7 |
| 残缺香菇 | 92.4 | 93.3 | 94.9 |
由表3可见,在未成熟香菇的检测中,FSE-DETR的mAP达到95.1%,相比RT-DETR的92.7%提升了2.4个百分点,说明小目标特征融合策略在增强检测能力方面具有较强的有效性。在残缺香菇的检测中,FSE-DETR的mAP为94.9%,相较于RT-DETR的92.4%提升了2.5个百分点,在光帽香菇和花香菇的检测中,FSE-DETR分别达到95.5%和95.7%。总体来看,FSE-DETR通过引入多种结构改进,在不同香菇类别上均实现了检测性能的全面提升。
3.4 不同目标检测模型实验结果对比
为了对比FSE-DETR模型与其他模型的性能,将改进模型与当前主流目标检测模型Faster R-CNN、YOLOv7、YOLOv8m和YOLOv12m进行对比。
由表4可知,FSE-DETR在各项指标上均优于其他模型。其mAP50达到95.3%,高于Faster R-CNN、YOLOv7、YOLOv8m和YOLOv12m,检测精度表现最优。同时,FSE-DETR的参数量为19.1 M,浮点运算次数为53.6 G,在模型规模和计算量上也最为轻量。总体来看,FSE-DETR在检测精度和模型效率之间实现了良好平衡,展现了出色的综合性能。
表4 不同模型在香菇检测中的整体性能对比结果Table 4 Comparison of overall performance of different models in shiitake mushroom detection |
| 模型 | mAP50/% | 模型参数量/M | 浮点运算次数FLOPs/ G |
|---|---|---|---|
| Faster R-CNN | 85.4 | 41.56 | 212.9 |
| YOLOv7 | 92.8 | 37.21 | 105.3 |
| YOLOv8m | 92.3 | 25.90 | 79.3 |
| YOLOv12m | 93.7 | 20.11 | 68.5 |
| FSE-DETR | 95.3 | 19.10 | 53.6 |
3.5 检测结果可视化

 误检的目标
误检的目标  重复识别的目标
重复识别的目标  漏检的目标
漏检的目标由图9可见,FSE-DETR在检测精度方面表现最优,测试样本中未出现漏检、误检或重复识别。对于花香菇与次品香菇这类特征相近的目标,Faster R-CNN存在明显误检和漏检,尤其在菇体密集场景中问题更为突出。FSE-DETR在不同光照条件下的检测结果稳定,三类目标置信度均在0.9以上,而YOLOv8m和YOLOv12m则存在置信度偏低和个别误检、重复识别的情况。
4 结 论
本研究提出了一种改进的香菇采收评价模型——FSE-DETR。该模型在RT-DETR基础上集成了FasterNet Block、SFFN和EIoU损失函数,有效提升了香菇目标的检测精度与多尺度特征表达能力。实验结果表明,FSE-DETR在复杂环境下的检测性能显著优于其他主流目标检测模型,尤其在未成熟香菇等小目标检测任务中表现更加稳定。其中FasterNet Block降低了模型复杂度,SFFN增强了小目标特征提取能力,EIoU损失函数则提升了边界框定位精度并加快模型收敛速度,使FSE-DETR在检测精度、计算效率与模型规模之间实现了良好平衡。
与Faster R-CNN、YOLOv7、YOLOv8m和YOLOv12m等模型相比,FSE-DETR在各项评价指标上均表现出明显优势,其准确率达到95.8%,召回率为93.1%,mAP为95.3%。此外,FSE-DETR在复杂光照、多目标密集和多尺度香菇检测等场景中展现出更强的适应性与稳定性,能够有效满足香菇采收过程中对高精度、高效率和轻量化部署的实际需求。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}