



0 引 言
图像分割的传统方法主要依赖于颜色、边缘和纹理特征,例如颜色阈值法、区域生长法和边缘检测法[5],然而随着机器学习和深度学习技术的发展,研究人员开始采用分类器(如支持向量机、随机森林)结合手工提取的特征来实现分割[6]。在此基础上,语义分割通过像素级分类显著提升了分割精度[7],实例分割则进一步结合目标检测和语义分割的优点,对图像中的每个实例目标进行精确的像素级分割。实例分割分为单阶段和两阶段方法。两阶段方法的代表性算法是掩码区域卷积神经网络(Mask Region-Based Convolutional Neural Network, Mask R-CNN)[8],尽管两阶段方法分割精度较高,但是对计算资源和内存要求较高,模型的运行速度较慢,难以满足实时任务的需求,例如Wang和He[9]通过融合注意力模块对Mask R-CNN进行改进,试验结果表明,模型在遮挡和重叠条件下表现优异,召回率和精确率分别达到了97.1%和95.8%。单阶段方法的代表算法由Redmon等[10]提出,该算法依赖其快速的处理能力已经发展成为最广泛应用的一种方法。Li等[11]提出了一种基于多任务分割网络的遮挡苹果果实三维定位方法,实现了对遮挡水果位置和大小的估计,确定了采摘机器人采摘果实时的接近方向,实验结果表明,该方法相较于传统方法,水果位置的中位数误差和平均误差分别减少了59%和43%。为进一步提升分割精度,研究者们基于自注意力机制的Transformer[12]分割模型展开研究,作为Transformer研究体系的基础框架,Vanilla[13]采用编码器-解码器双模块架构处理分词的输入,每个模块包含多头自注意力层[14]和逐位置的全连接前馈网络[15]两个子层。贾伟宽等[16]提出了一种基于优化Transformer网络的绿色目标果实检测模型,通过引入重采样法扩充样本、结合迁移学习提升训练效率,并构建编码器-解码器结构增强对复杂场景下果实特征的建模能力,实验结果表明,该模型检测绿色苹果的准确率为91.35%。
为增强模型推理实时性,研究人员采用MobileNet[17]和ShuffleNet[18]等架构对果实推理模型开展轻量化研究。通过采用深度可分离卷积、剪枝和量化等技术,减少了模型的计算复杂度。胡广锐等[19]结合高效通道注意力和混洗注意力模块优化主干网络,提出了轻量化模型Lad-YXNet,模型大小减少了18.23%。罗友璐等[20]通过引入多尺度双重注意力机制(Multi-Scale Dual Attention, MSDA)和空间到深度卷积模块(Space-to-Depth Convolution, SPD-Conv)模块,提出了用于苹果叶病害检测的轻量化模型YOLOv8n-SMR,模型的精确率、召回率和mAP50分别达到了83.1%、80.2%和88.2%。
尽管上述苹果采摘机器人识别定位方法取得了积极进展,然而当机器人采用模块化、分布式的系统架构设计[21]时,模型需运行在算力资源受限的平台上,要求模型既要满足果实定位所需的分割精度还需要满足实时系统部署的推理效率。为此,本研究针对现有研究果实分割精度不足和模型推理效率不佳的问题,提出了一种基于YOLOv11n的轻量化实例分割模型SSW-YOLOv11n,结合分组混洗卷积(Group Shuffle Convolution, GSConv)和多样化一次性分组标准跨阶段部分网络(Variety of VoV with Group Standard Cross Stage Partial, VoVGSCSP)模块所形成的Slim-Neck结构、简单参数无关注意力模块(Simple, Parameter-Free Attention Module, SimAM)和智能交并比损失函数(Wise Intersection over Union Loss, Wise-IoU),显著减少模型参数量和计算资源需求,提升在复杂果园环境下的果实分割精度。
1 材料与方法
1.1 图像数据采集与数据集构建
1.1.1 数据采集
本研究利用自研数据采集机器人开展图像数据采集任务,涵盖“嘎啦”和“魔星”两个苹果品种,采集设备和地点如图1所示。

机器人平台搭载两台双目立体视觉深度相机,分别安装于1.3和2.0 m的高度,视野(Field of View, FOV)为69°×42°,最大检测范围为3 m,采集的图像分辨率像素为640×480,宽高比为4∶3。机器人平台以0.5 m/s的速度运动,相机以15 帧/秒(Frame per Second, FPS)的频率采集图像。采集图像时需要涵盖正光、背光和枝叶遮挡等各种情况,确保采集到的苹果图像丰富且完整。通过对采集到的数据进行筛选最终得到3 500张图像作为果实实例分割模型的数据集,如图2所示,其中正光条件下的果实图像1 400张,背光条件下的果实图像1 050张,遮挡条件下的果实图像1 050张。

1.1.2 数据增强
为了增加数据的多样性,丰富模型训练数据集,本研究采用数据增强技术对原始数据集进行扩展。如图3所示,在网络训练前,对苹果图像进行旋转、水平翻转、亮度对比度调整、缩放五项操作的随机结合。经过数据增强得到7 000张图像用于网络训练,将数据集按7∶2∶1的比例分为训练集4 900张,验证集1 400张,测试集700张。

1.1.3 图像数据标注
本研究使用交互式半自动标注软件[21]完成果实目标信息的标注,将果实目标按照采摘难易程度划分为易见、遮挡和风险三类,如图4所示。第一类目标为清晰可见且可达性较好的果实,标记为“易见”,此类果实在机械臂采摘路径上几乎没有或仅有极少量枝叶、钢丝等障碍物的遮挡,果实表面绝大多数是可见清晰的。第二类目标为有遮挡的果实,标记为“遮挡”,此类目标的遮挡率超过50%,但通常仍具备较好的可达性。第三类目标为存在采摘风险的果实,标记为“风险”,此类果实通常位于支撑杆、支撑网等刚性障碍物附近,如遮挡率≥80%或机械臂路径障碍距离≤10 cm,具备较差的可达性,机械臂在采摘此类目标时有损伤采摘手爪和果实的风险。标注后的数据集中包含了4 800个第一类“易见”果实、4 900个第二类“遮挡”果实和1 000个第三类“风险”果实。

1.2 SSW-YOLOv11模型
YOLOv11seg是在YOLO系列模型基础上优化升级的实例分割网络,集成了前几代YOLO模型的优势。根据模型尺寸,YOLOv11seg分为YOLOv11n-seg、YOLOv11s-seg、YOLOv11m-seg、YOLOv11l-seg和YOLOv11x-seg五种,尺寸越大,网络层数和参数计算量也随之增加。本研究基于YOLOv11n-seg模型,优化其网络结构,包括主干网络、颈部网络、检测头和分割头三大部分,以更好适应非结构化自然果园场景下的苹果实例分割任务[22]。
1.2.1 Slim-Neck结构
在YOLOv11n架构中,颈部部分连接骨干网络与分割头,负责特征融合与处理。在苹果实时检测的应用场景中,传统的大型模型难以满足实时性要求,而由大量深度可分离卷积层构建的轻量级模型则难以在保证实时性的同时实现足够的精度。因此,本研究提出了一种基于轻量级卷积技术GSConv的改进方案[23]。GSConv首先对输入进行下采样,再通过深度可分离卷积(DWConv)对下采样结果进行处理,最后将下采样结果与深度卷积结果进行拼接,并进行shuffle操作以输出结果。该方法在减少参数量的同时,保证了特征图在传输至颈部时无需额外变换,减少了冗余与重复计算。基于GSConv使用一次性聚合方法设计跨级网络模块VoVGSCSP,结合GSConv构成了Slim-Neck架构[24]。
1.2.2 SimAM自注意力机制模块
现有的注意力机制多采用额外的子网络生成注意力权值,增大了神经网络的参数量,因此本研究使用了一种自注意力机制SimAM,该注意力机制无需向原始网络添加参数。SimAM作为一种无参数的注意力机制,在无需增加计算开销的前提下,能够对特征图进行显式建模并自动增强关键区域特征。在果园复杂环境中,果实常常被枝叶等物体遮挡,传统特征提取方式往往难以准确聚焦于目标区域。而SimAM通过模拟神经元活跃度对三维特征图进行加权处理,能够在遮挡或光照不均条件下突出果实区域的响应强度,从而提高模型对果实边界与形态的感知能力。
其输入数据大小为C×H×W,通过能量函数,如公式(1) 所示,推断出特征图的3D权重,并将Sigmoid函数归一化后的权重与原始特征图相乘,得到提升特征的输出特征图,从而使模型更关注于重要的部分,提升对目标的检测性能[25]。
式中:et 是第t个神经元的能量值;wt 是权重参数;bt 是偏置参数;y是目标神经元的激活值;xi 是第i个输入特征;M是特征图中的像素总数;λ和μ是正则化参数。 和 由公式(2) 和公式(3) 求解:
式中: 和 是在该通道中除了重要神经元 之外所有神经元的均值和方差,计算如公式(4) 和公式(5) 所示。
1.2.3 Wise-IoU损失函数
如图5所示,Wise-IoU引入动态聚焦机制,根据预测框与目标框的重叠质量自适应调整损失权重。对于重叠质量较低的锚框,显著增强其损失值以强化模型对难以定位目标的学习能力;而对于重叠质量较高的锚框,则适当削弱其损失权重,减轻过度优化所带来的梯度干扰。随后引入距离注意力机制,重点关注预测框与目标框中心点之间的几何距离,通过精确建模中心点位置差异,有效降低位置偏差,尤其在低重叠区域中表现出更强的定位能力[26]。此外,Wise-IoU还设计了权重动态调整机制,根据锚框与目标框之间的距离、尺度比等几何特征动态调节梯度权重,提升收敛速度并缓解传统IoU损失在极端情况下易出现的梯度消失问题,从而增强模型在目标定位任务中的鲁棒性与精度。Wise-IoU计算方法如公式(6) 所示。
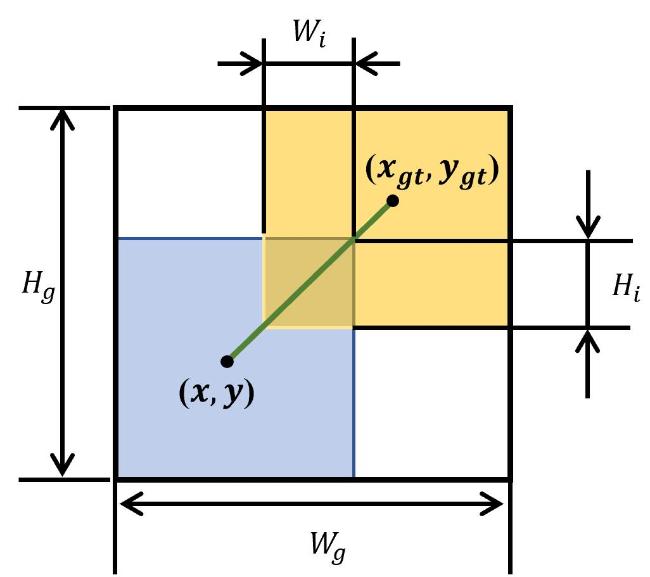
式中: 为离群度; 和 为超参数; 和 为锚框的中心点的横纵坐标值,像素; 和 为目标框的中心点的横纵坐标值,像素; 和 为最小包围框的宽度和高度,像素。
1.2.4 改进后的模型
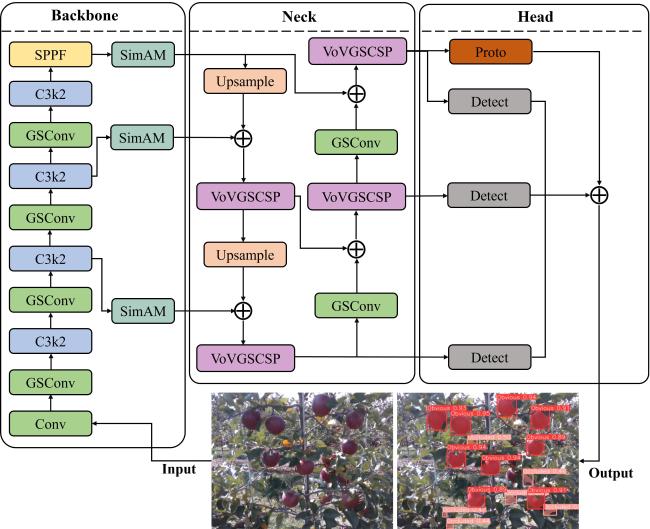
本研究提出一种轻量级的SSW-YOLOv11模型。首先,将原有的颈部网络中的Conv和C3k2分别替换成更轻量化和更高效的GSConv和VoVGSCSP,从而加快特征融合和处理的速度。然后在特征提取骨干网络和颈部网络连接的三个输出端分别增加SimAM自注意力模块,对前向传递层的输出进行处理。最后将原有的损失函数替换为Wise-IoU损失函数,通过结合距离与几何因素,并调整梯度的方式使模型更有效地优化边界框,改进后的模型网络结构如图6所示。
2 结果与分析
2.1 模型训练参数
实验训练平台为Precision-7920-Tower,配置细节如表1所示。
表1 SSW-YOLOv11n轻量化实例分割研究训练平台配置详情Table 1 Training platform configuration details of SSW-YOLOv11n lightweight instance segmentation research |
| 项目 | 配置 |
|---|---|
| 中央处理器 | Intel Xeon(R) Silver 4210 |
| 图形处理器 | NVIDIA GeForce RTX 2080 Ti/PCIe/SSE2 |
| 开发环境 | Python 3.8 |
| 深度学习框架 | CUDA10.2+CUDNN 8.2.0+Pytorch 1.12.0+Torchvision 0.13 |
| 操作系统 | Ubuntu 18.04 |
模型训练过程中的参数选择如下:初始学习率设为0.01,权重衰减率为0.000 5,动量因子设为0.937,并采用前3个epoch的Warmup策略进行学习率调整。使用随机梯度下降法(Stochastic Gradient Descent, SGD)结合动量更新参数,训练轮次为300,批次大小为24,图像输入像素尺寸为640×640,IoU阈值设为0.5,置信度阈值设为0.5。模型训练过程中采用余弦退火调度器来优化学习率。
2.2 模型评价指标
本研究选取精确率(Precision, P)、召回率(Recall, R)、IoU阈值为0.5时的平均精度均值(mean Average Precision@0.5, mAP50)、模型千兆浮点运算量(Giga Floating-Point Operations per Second, GFLOPS)、权重大小作为评估模型性能优劣的指标[27]。GFLOPS表示每秒能够执行的十亿次浮点运算,权重大小表示训练完成的模型权重所占的内存空间。
精确率指的是在所有被预测为苹果的实例中,实际为正确目标的比例,即衡量模型在识别结果中的准确性,由公式(7) 计算。
式中: 表示模型正确的将苹果识别为苹果的数量; 表示模型错误的将非苹果标记为苹果的数量。
召回率指的是在所有真实存在的苹果目标中,模型成功分割出的比例,即衡量模型对目标的检出能力,由公式(8) 计算。
式中: 表示模型错误的将苹果标记为非苹果的数量。
平均精度mAP50指的是IoU阈值为0.50的条件下,模型在不同召回率下的平均精确率,表示模型在特定匹配条件下的整体性能,由公式(9) 和公式(10) 计算。
式中:AP为平均精度; 为精度函数,表示在召回率R条件下对应的精度值;R表示召回率,取值范围为[0,1];mAP50表示在IoU阈值为0.5条件下的平均精度均值;N表示检测类别总数; 表示第i个类别的平均精度。
2.3 消融实验
为验证所提出三项改进措施在提升模型性能方面的有效性,本研究在相同硬件配置和统一数据集条件下设计并实施了系统性的消融实验。以YOLOv11n作为基准模型,分别引入Slim-Neck结构、SimAM自注意力机制和Wise-IoU损失函数,并进一步构建多种组合配置,共计8组实验,具体结果如表2所示。
表2 SSW-YOLOv11n轻量化实例分割研究消融实验结果Table 2 SSW-YOLOv11n lightweight instance segmentation research ablation experiment results |
| 序号 | Slim-Neck | SimAM | Wise-IoU | Box mAP50/% | Mask P/% | Mask R/% | Mask mAP50/% | GFLOPS | 权重大小/MB | 帧率/FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | × | × | × | 74.6 | 72.4 | 72.9 | 74.3 | 10.4 | 5.89 | 25.1 |
| 2 | √ | × | × | 75.1 | 72.5 | 73.4 | 75.1 | 10.0 | 5.72 | 26.5 |
| 3 | × | √ | × | 75.6 | 73.1 | 73.7 | 75.3 | 9.8 | 5.60 | 26.8 |
| 4 | × | × | √ | 74.7 | 71.3 | 71.2 | 74.8 | 10.1 | 5.64 | 25.5 |
| 5 | √ | √ | × | 76.1 | 72.7 | 72.3 | 76.2 | 9.3 | 5.28 | 28.4 |
| 6 | √ | × | √ | 75.5 | 72.2 | 72.5 | 75.5 | 9.7 | 5.05 | 27.9 |
| 7 | × | √ | √ | 75.7 | 72.8 | 72.6 | 75.6 | 9.5 | 4.85 | 27.6 |
| 8 | √ | √ | √ | 76.3 | 73.5 | 73.8 | 76.7 | 9.1 | 4.55 | 29.8 |
|
在基准模型YOLOv11n中,Box mAP50为74.6%,Mask mAP50为74.3%,在精度与速度之间取得了较为平衡的表现。引入Slim-Neck结构后,Box mAP50与Mask mAP50均提升至75.1%,计算复杂度降低3.8%,说明该结构在特征融合效率与模型轻量化方面具有良好效果。仅将SimAM注意力机制加入骨干网络输出端,在不增加参数的情况下实现了Box mAP50和Mask mAP50各提升1个百分点,同时略微降低了模型复杂度,验证了SimAM在精度增强方面的有效性。仅引入Wise-IoU作为回归损失函数后,Box mAP50和Mask mAP50分别提升0.1和0.5个百分点,体现了其在边界框回归优化上的细微贡献。在多模块组合配置中,各改进模块协同作用进一步提升了模型性能。特别是在同时引入Slim-Neck结构与SimAM注意力机制时,Box mAP50和Mask mAP50分别提升至76.1%和76.2%,模型权重减少10.4%,展现出较好的精度效率平衡。当三种改进模块同时集成于YOLOv11n基线模型中时,Box mAP50和Mask mAP50分别提升至76.3%和76.7%,较原始模型分别提升1.7和2.4个百分点;同时模型计算复杂度从10.4 GFLOPs降低到9.1 GFLOPs,降低12.5%,权重从5.89降低到4.55 MB,减少22.8%,帧率提升18.7%,表现出最优的综合性能。
2.4 不同模型对比试验
表3 SSW-YOLOv11n轻量化实例分割研究不同模型对比试验结果Table 3 Comparative experiment results of different models of SSW-YOLOv11n lightweight instance segmentation research |
| 模型 | Box mAP50/% | Mask P/% | Mask R/% | Mask mAP50/% | GFLOPS | 权重大小/MB | 帧率/FPS |
|---|---|---|---|---|---|---|---|
| Mask R-CNN | 43.2 | 42.5 | 54.1 | 53.5 | 245.0 | 205.00 | 24.5 |
| SOLO | 47.2 | 57.2 | 55.3 | 56.4 | 132.0 | 176.00 | 24.6 |
| YOLACT | 44.8 | 57.9 | 42.4 | 55.3 | 79.6 | 143.00 | 24.8 |
| YOLOv11n | 74.6 | 72.4 | 72.9 | 74.3 | 10.4 | 5.89 | 25.1 |
| SSW-YOLOv11n | 76.3 | 73.5 | 73.8 | 76.7 | 9.1 | 4.55 | 29.8 |
Mask R-CNN作为典型的两阶段实例分割算法,在分割精度方面表现良好,但其计算复杂度较高,GFLOPS高达245,推理效率偏低,难以满足采摘机器人对实时性的要求。相较而言,单阶段实例分割模型在推理速度与资源消耗方面具有明显优势。其中,YOLOv11n和本研究提出的SSW-YOLOv11n模型的权重分别为5.89和4.55 MB,均体现出良好的轻量化特性;在分割性能方面,SSW-YOLOv11n模型在Mask精确率、召回率和mAP50上分别达到73.5%、73.8%和76.7%,表现优于其他对比模型。其中,其Mask mAP50指标相较于Mask R-CNN、SOLO、YOLACT和YOLOv11n分别提升了23.2、20.3、21.4和2.4个百分点,展现出显著的分割精度优势。此外,在轻量化性能指标方面,SSW-YOLOv11n的GFLOPS为9.1,权重大小为4.55 MB,均优于所有对比模型,兼顾了高精度与低复杂度的设计目标。总体而言,所提出模型在分割性能和模型效率方面均表现优异,更加符合采摘机器人的实际需求。
2.5 边缘计算平台部署
为了验证SSW-YOLOv11模型在边缘设备上的部署情况并提高模型的检测速度,采用NVIDIA TensorRT对模型进行优化加速,进一步提升改进模型的推理效率。TensorRT是一款面向NVIDIA GPU和Jetson硬件的高性能推理优化工具,支持多种深度学习框架,能够通过层融合、精度优化和内存管理等技术显著降低模型延迟并提高吞吐量。将训练得到的模型权重文件转换为ONNX格式,再序列化模型对象生成engine推理引擎即可得到经过TensorRT加速后的模型,模型在工作站台式电脑与边缘计算平台上的果实推理帧率情况如表4所示。结果表明,所提出的改进模型SSW-YOLOv11n在两类硬件平台上均实现了推理性能的提升。与原始YOLOv11n模型相比,SSW-YOLOv11n在NVIDIA Jetson TX2平台上的推理帧率达到29.8 FPS,提升了18.7%,显著增强了模型在嵌入式设备上的部署效率。
表4 SSW-YOLOv11n在不同设备推理帧率对比Table 4 Comparison of inference frame rates for different devices of SSW-YOLOv11n |
| 模型 | 工作站/ FPS | NVIDIA Jetson TX2/ FPS |
|---|---|---|
| YOLOv11n | 72.5 | 25.1 |
| SSW-YOLOv11n | 88.9 | 29.8 |

3 结 论
本研究针对复杂果园环境下苹果采摘机器人对果实精确识别与分割的实际应用需求,提出了一种基于改进YOLOv11n的轻量化实例分割模型SSW-YOLOv11n。该模型在网络结构上引入GSConv与VoVGSCSP模块构建Slim-Neck结构,提升特征融合效率并降低计算开销,并在骨干网络与颈部网络连接的多尺度输出端加入SimAM自注意力机制,增强模型对目标区域的感知能力,同时采用Wise-IoU损失函数,通过引入中心距离和几何因素动态调节梯度,有效提升边界框定位精度。消融实验验证了三项改进的独立与组合效果,结果表明SSW-YOLOv11n模型在Box mAP50与Mask mAP50上分别较原始YOLOv11n提升了1.7和2.4个百分点,同时GFLOPS降低了12.5%,模型权重减少22.8%。对比实验进一步表明,SSW-YOLOv11n在精度与模型复杂度方面均优于其他实例分割算法,在Mask mAP50方面较Mask R-CNN、SOLO、YOLACT和YOLOv11n分别提高了23.2、20.3、21.4和2.4个百分点。此外,边缘计算平台上模型部署试验结果表明,SSW-YOLOv11n在NVIDIA Jetson TX2上对果实的推理帧率达到了29.8 FPS,相较于YOLOv11n提升了18.7%,显示出了良好的综合性能与在嵌入式设备上部署的潜力,展现了该模型在光照变化和树枝树叶遮挡等复杂环境下对苹果果实的高效分割,为果园机器人采摘提供了坚实的技术基础。未来研究将继续优化模型结构,在保持轻量化的同时进一步提升小目标与密集遮挡场景下的分割性能,同时探索多模态感知信息融合,以增强模型在实际果园采摘环境下的适应性和泛化能力。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}