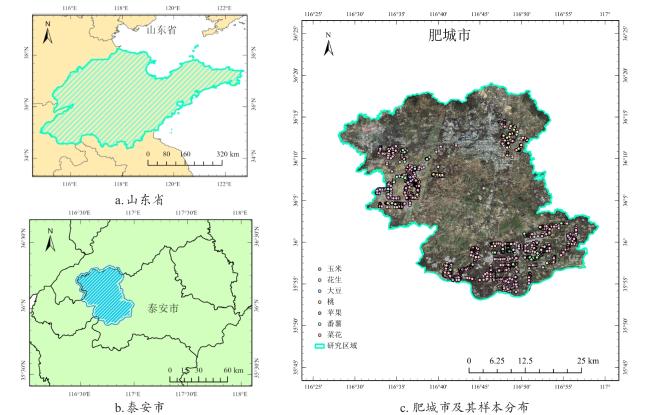
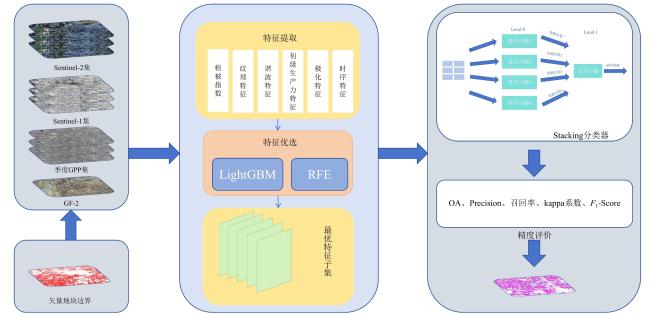
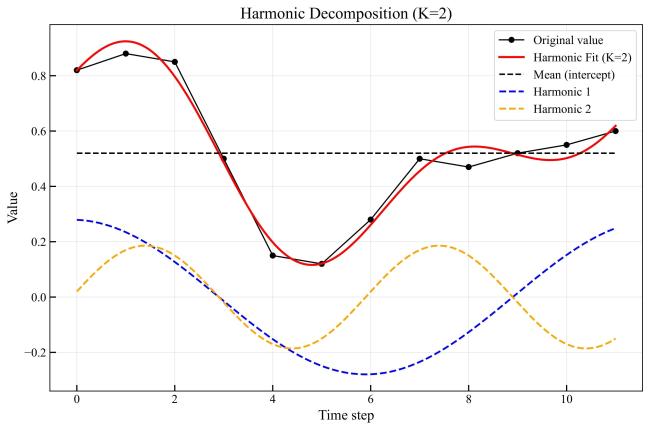
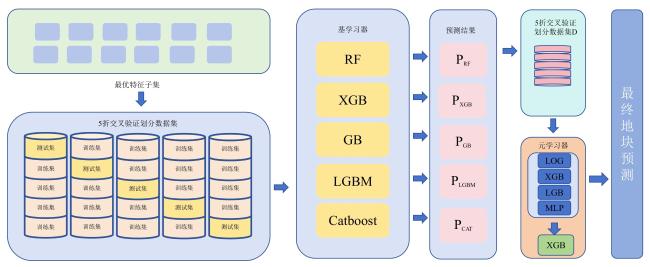
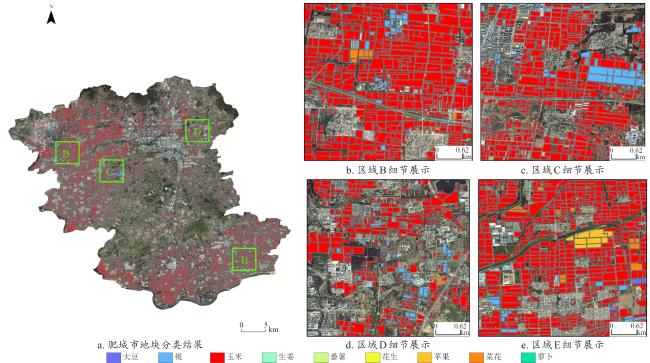
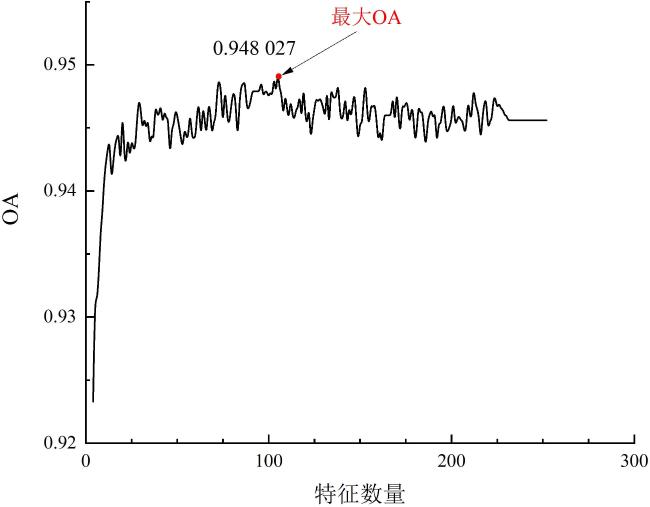
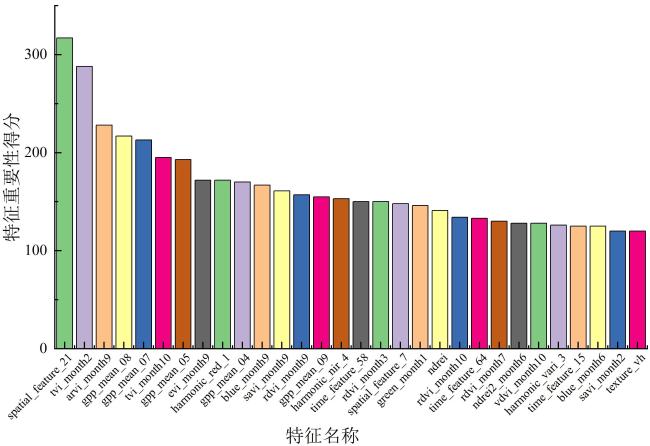
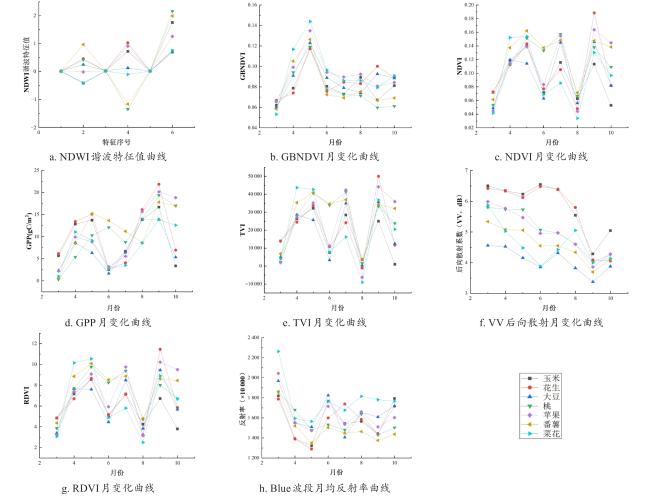
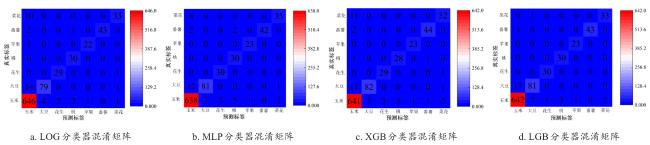
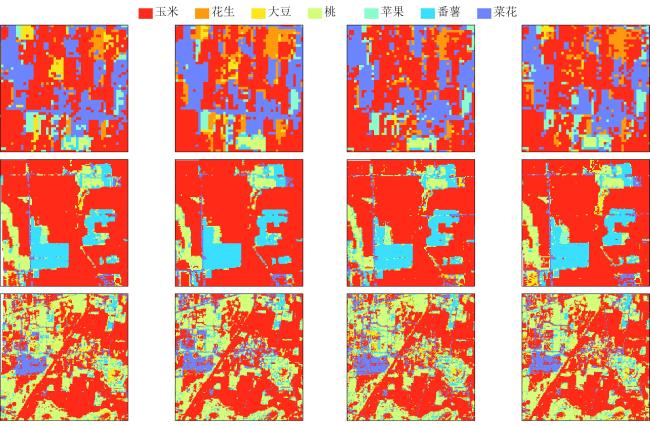
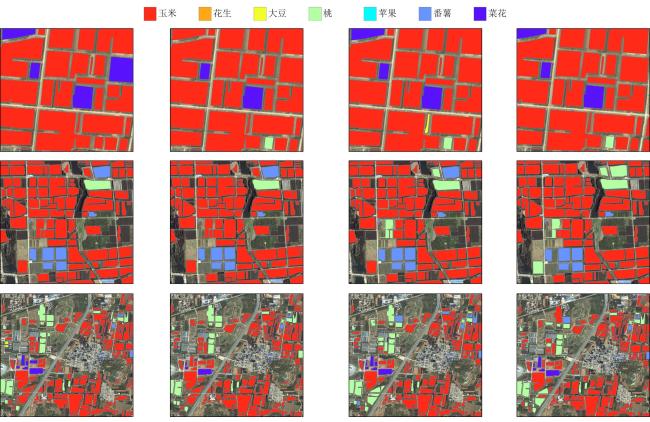
[Objective] With the widespread availability of high-resolution and multi-source remote sensing data, remote sensing-based crop classification has played an increasingly vital role in agricultural monitoring, yield estimation, and land use management. However, traditional pixel-level classification methods often struggle to achieve stable, high-precision classification under conditions of intra-plot heterogeneity, spectral confusion, and noise interference.Therefore, this study aimed to improve parcel-level crop classification accuracy and spatial consistency by constructing a multi-source feature fusion and ensemble learning framework, which exploits complementary spectral, spatial, temporal, and productivity characteristics to enhance robustness and generalization in multi-crop classification tasks. [Methods] To enhance field-level classification accuracy and spatial consistency, a crop classification method integrating field-scale feature extraction, feature selection, and Stacking ensemble learning was proposed and validated. This approach aimed to fully leverage the complementarity of spectral, spatial, and temporal information through feature engineering and model fusion. The study area was located in Feicheng city, Shandong province. The data included multi-temporal Sentinel-2 optical imagery, Sentinel-1 SAR data, Gaofen remote sensing imagery, and parcel vector samples with crop_type attributes. All imagery underwent radiometric and atmospheric correction, projection registration, and cropping during preprocessing to ensure spatial consistency and temporal correspondence across sensors. The dataset was constructed at the field level, comprising 3 200 fields for model training and independent validation. This study systematically constructed four types of meta-features on the plot scale: raw bands and vegetation indices; spatial meta-features, including texture, morphology, and structural indicators calculated from high-resolution imagery to reflect internal spatial heterogeneity; temporal sequence meta-features, extracting vegetation indices, backscatter, and harmonic/temporal statistics from multi-temporal optical and SAR imagery to characterize crop growth cycles; crop primary productivity features to highlight differences in carbon fixation and biomass accumulation among crops. Subsequently, for the high-dimensional, multi-source feature set, a combined strategy of LightGBM and recursive feature elimination (RFE) was employed for feature importance assessment and selection. This retained a subset of features most critical to classification, enhancing model generalization and computational efficiency. Within the classification framework, a Stacking-based ensemble learning model was constructed. Base learners included random forest (RF), eXtreme gradient boosting (XGB), support vector machine (SVM), gradient boosting (GB), categorical boosting (CatBoost), adaptive boosting (ADA), back propagation (BP), K-nearest neighbors (KNN), and light gradient boosting machine (LightGBM). These base models learn and represent plot features from distinct perspectives, fully exploring nonlinear relationships among spectral, spatial, and temporal characteristics. During the meta-learner selection phase, to compare the impact of different feature fusion strategies on classification performance, XGBClassifier, LightGBMClassifier, MLPClassifier, and LogisticRegression were selected as meta-learners for experimental comparison. By contrasting the classification outcomes of different meta-models under the same base model outputs, their contributions to improving feature fusion accuracy and stability differences were analyzed. During model training, hierarchical cross-validation was employed to mitigate bias caused by class imbalance. Overall accuracy (OA), Kappa coefficient, and F1-Score served as primary evaluation metrics, while recall and precision rates for each crop category underwent systematic analysis. [Results and Discussions] The findings indicated that feature selection significantly impacted classification performance. By integrating LightGBM with feature selection strategies, a subset of 102 optimal features was identified. This subset included gross primary production (GPP), spectral features, vegetation indices, textural features, temporal features, and harmonic features. This approach effectively mitigated feature redundancy and multicollinearity issues, enhancing model stability and generalization capability. Among these, GPP-related features and vegetation indices from key growth stages demonstrated high discriminative power in distinguishing crop categories, fully reflecting the close coupling between remote sensing features and crop phenological information. The Stacking ensemble strategy demonstrated outstanding classification performance. Among various meta-learners, the Stacking model with XGBClassifier as the final learner achieved the highest classification accuracy (OA = 95.66%, Kappa = 0.900 6), showcasing exceptional ensemble generalization capability. It performed particularly well in identifying major crops like maize while maintaining good adaptability for less common crops. The method's advantage extended beyond accuracy gains to its comprehensive integration of complementary spectral, temporal, and spatial feature processing capabilities across base learners. The meta-learner adaptively synthesized multi-model outputs, enhancing classification stability and spatial consistency. Compared to traditional pixel-level classification followed by parcel reclassification, direct feature extraction and classification based on vector parcels effectively avoided edge blending and noise interference inherent in pixel-level methods, significantly improving parcel recognition stability and accuracy. Experimental results demonstrated that parcel-level classification outperformed pixel-level strategies in overall accuracy and Kappa coefficient, with superior spatial consistency and robustness in classification outcomes. [Conclusions] The "optimal feature subset + Stacking ensemble learning + parcel-level classification" method developed in this research demonstrates outstanding accuracy and stability in multi-source remote sensing crop identification, providing an efficient and feasible technical pathway for parcel-level classification in complex agricultural landscapes. Future work will integrate high-resolution time-series data with deep learning models to further enhance the method's cross-regional adaptability and crop monitoring capabilities.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}