



0 引 言
作为中国至关重要的经济作物,苹果产业规模举足轻重。2023年,全国苹果种植面积已近193.4万公顷,总产量高达4 960.17万t,这两项关键指标连续多年位居世界首位[1]。在这繁荣景象的背后,产业升级的瓶颈日益凸显。当前果园的采摘环节依然高度依赖人工,相关成本在苹果生产总成本中的占比已超过60%,这不仅大幅侵蚀了产业利润,更成为制约果园生产效率提升与成本控制的核心因素[2]。而在采摘作业的全流程中,机械臂的避障路径规划是决定采摘机器人能否替代人工实现高效作业的核心环节。若无法在复杂果园环境中实现精准、快速的避障与路径规划,机器人不仅会出现采摘失败、损伤果实与枝条的问题,还会因反复调整路径导致作业效率大幅下降,难以满足规模化果园的作业需求。在这一背景下,国内外的苹果采摘机器人迅速发展,在苹果检测和定位[3]、路径规划[4]、机械设计[5]等方面取得了积极进展。其中以具备自主避障能力的采摘机器人为代表的自动化技术,已成为产业转型升级所必需的关键技术支撑。
从产业需求延伸至技术研究层面,机器人从结构化的工业环境迁移至果园这类非结构场景面临着巨大挑战,而机械臂避障路径规划则是其中的核心技术难关。一方面果树形态千差万别,光照条件随时间与天气复杂多变,特别是枝叶随机复杂作业工况下,机器人的自主避障能力成为实现稳定可靠的自主连续作业的关键一环。另一方面,果园环境呈现出传统工业场景中罕见的刚柔混合障碍物特征。即便在矮化密植等相对标准化的现代果园中,虽然密植栽培模式显著改善了机械化作业的可行性,但果实周围的微观作业环境依然极为复杂:支撑铁丝、立柱、粗壮树枝等刚性障碍物与细枝、叶片、嫩梢等柔性障碍物密集分布,形成了刚柔交织的复合遮挡工况[6]。这类工况下,柔性障碍物并非传统意义上的“非接触区域”,而是在一定条件下可以适度推移或穿越的“可穿行区域”。因此,传统路径规划算法所依赖的静态几何建模和固定避障策略已难以适应这种几何边界动态可变的复杂环境,存在规划耗时长、路径生成效率差、工况适应性不佳等问题[7]。
在机械臂避障路径规划的技术迭代进程中,相关解决方案经历了多轮优化与革新。基于快速扩展随机树(Rapidly-exploring Random Tree, RRT)的系列算法[8]凭借其概率完备性优势,率先在该领域得到广泛关注,其改进版本如双向快速扩展随机树(Bidirectional Rapidly-exploring Random Tree, Bi-RRT)、快速扩展随机树星算法(RRT-Star, RRT*)、快速扩展随机树连接算法(Rapidly-exploring Random Tree Connect, RRT-Connect)等已成功部署于荔枝、苹果等多种采摘机器人系统中。尽管如此,这些算法在面对果园高度动态、几何复杂的作业环境时,仍暴露出搜索效率低下和场景泛化能力不足等问题[9]。为应对这些挑战,研究者们积极探索多样化的优化路径:通过融合蚁群、遗传、模拟退火等智能优化算法[10]来增强全局搜索能力。同时,借鉴人工势力场理论[11]实现更加直观高效的路径引导机制,单一算法向混合智能方法的转变正成为该领域的重要发展方向[12]。近年来,深度强化学习(Deep Reinforcement Learning, DRL)技术在路径规划领域的应用逐渐成为研究热点,为解决复杂非结构化环境下的路径规划难题提供了新思路。例如,LI等[13]提出基于深度强化学习的果柄无碰撞抓取方案,该研究构建了基于关键点的番茄果串空间位姿描述模型,改进的经验回放软演员评论家算法(Hindsight Experience Replay - Soft Actor-Critic, HER-SAC)融合启发式策略模型与动态增益模块提升了学习效率。WANG等[14]针对猕猴桃采摘路径规划提出了深度强化学习方案,通过改进基于回报的深度Q网络(Return-Based Deep Q-Network, Re-DQN)算法求解区域遍历顺序,其规划路径较传统算法缩短31.56%,导航时间减少35.72%。LIN等[15]针对番石榴采摘的枝条碰撞问题,融合循环神经网络与深度确定性策略梯度算法,实现快速无碰撞路径规划,仿真中规划耗时仅29 ms、成功率90.90%,田间采摘成功率也显著提升。SUN等[16]在葡萄柔性采摘领域提出人工技能模仿的轨迹规划法,通过动作捕捉获取人工轨迹并优化拟合,有效降低了轨迹偏差,实现果串柔顺采摘。这些研究证实了深度强化学习在路径规划领域的应用潜力,但在果园刚柔混合障碍物的差异化处理方面,仍存在策略泛化能力不足、训练效率偏低等亟待突破的瓶颈。
深度强化学习为机器人应对复杂非结构化环境提供了一种富有前景的范式[17]。该技术通过让机器人在与环境的持续交互和试错中学习并优化自身决策,能够高效地解决机械臂在高维连续空间中的运动规划难题。相较于传统算法,深度强化学习虽然能够显著提升机械臂的定位精度与采摘成功率,有效缩短规划时间与运动路径长度[18]。但纯粹的强化学习也存在其固有的挑战,即在学习初期需要大量盲目探索,导致训练效率低下、收敛速度缓慢。研究者们常引入专家演示来引导其初始策略的形成,通过模仿学习的方式,让机器人先具备一个基础的行为模式,从而大幅加速后续的强化学习收敛过程[19]。如何有效利用专家演示建立起一个高效的初始策略,并在此基础上,通过自主学习实现对复杂果园环境的适应与泛化,最终构建一个稳定可靠的、能够差异化处理刚柔障碍物的决策机制是本研究的重点。为解决这一难题,本研究提出了一种基于专家演示引导的深度强化学习方法,构建了一种刚柔障碍物差异化交互机制,利用人类专家的操作演示数据对策略网络进行预训练,为机器人奠定行之有效的初始避障策略基础。随后,在此基础上采用软演员-评论家(Soft Actor-Critic, SAC)算法,并结合相对熵(Kullback-Leibler, KL)散度正则化约束,在高保真度的仿真环境中进行持续的策略迭代与优化,这一设计在确保学习过程稳定性的同时也能提升策略的泛化能力,以期为果园采摘机器人的自主避障路径规划提供可行的技术方案,推动苹果产业自动化采摘的规模化落地。
1 研究方法
1.1 MuJoCo仿真环境构建与刚柔障碍物建模
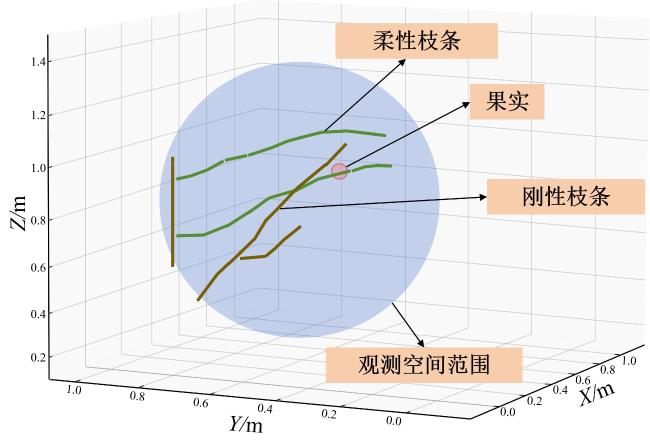
本研究基于MuJoCo物理引擎,构建了一个高保真的果园采摘仿真环境。该环境以一个4自由度机械臂和3指手爪为执行系统,并对果树进行了精细建模。通过刚性树干与基于rope模型的柔性枝条相结合,并精确设置弹性、阻尼等参数,实现了机械臂与枝条接触时逼真的物理形变。这种仿真建模方法为采摘机器人的路径规划和作业控制提供了有效且真实的模拟平台,如图1所示。

在强化学习环境构建时,设计的状态向量 具体包括:机械臂末端执行器当前位置 ,目标果实的位置 ,果实放置位置 ,末端执行器相对于果实的相对位置 ,果实相对于放置点的相对位置 ,选择距离果实最近的50段障碍物及枝条信息 ,长度 及障碍物属性 ,多出的障碍物不计,不足的补零。手爪指尖位置 , , 。抓取状态标志 指示果实是否已被抓住。这些信息可以通过视觉传感器获取,在仿真中直接由仿真环境提供。
机械臂的动作空间采用离散化表示,共包含8个离散动作 。其中,动作0用于控制手爪闭合,动作7用于控制手爪张开;动作1~6分别对应末端执行器沿手爪坐标系3个坐标轴正、负方向的位移。手爪坐标系以其中心位置为原点,姿态与世界坐标系一致。每步移动步长在仿真中设定为0.01 m。通过上述离散化设计,将复杂的连续控制问题转化为有限的离散动作选择问题,有效降低了强化学习算法的求解难度。
为引导机器人高效学习,将采摘任务分解为了3个连续阶段:第1阶段是接近阶段,机械臂移动至果实附近的预抓取点;第2阶段是抓取阶段,对准果实并闭合手爪;第3阶段是放置阶段,将抓取的果实运送至目标位置。仿真环境能够根据末端执行器的位置和手爪状态,自动完成阶段切换与任务成败的判定。将复杂任务分解为有序的子目标策略,极大简化了机器人的策略学习过程,也为奖励函数的设计提供了清晰的结构化依据。
矮化密植标准化果园是规模化种植模式,果树布局规整、有标准化支撑体系,环境中存在两类差异显著的障碍物。刚性障碍物物理形态固定、抗形变能力强,易致设备或果实损坏,包括牵引铁丝、支撑柱、树干、粗枝干等;柔性障碍物物理形态可变形、抗形变能力弱,不易损坏设备,主要包括细枝和树叶。针对矮化密植标准化果园环境中同时存在刚性和柔性障碍物的情况,在仿真环境构建时赋予了刚柔障碍物不同的标签,即已将枝条的刚柔属性传入智能体观测空间,如图2所示。智能体需要根据与不同标签的障碍物交互时的状态变化和奖励获取情况来判断不同属性障碍物的应对方法。观察空间可视化界面中棕色为刚性枝条,绿色为柔性枝条。
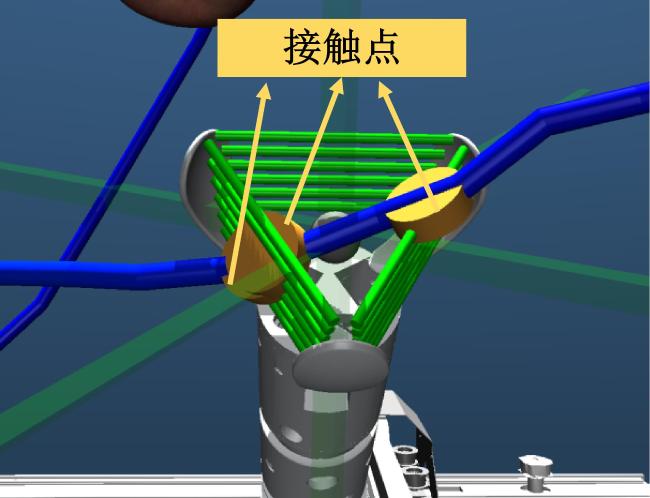
障碍物处理策略是由强化学习策略网络在交互过程中自主学习获得。在环境奖励函数中设计了相应的激励与惩罚信号,鼓励策略采取正确的避障动作。监测机械臂手爪与障碍物的接触情况,如果手爪与刚柔障碍物产生干涉现象,也认定为一次不良的碰撞。在仿真中的模型训练时,设置了碰撞检测体,如图3所示,用于检测枝条是否夹入手指之间。
1.2 专家经验引导的SAC深度强化学习算法
为引导强化学习高效完成3阶段采摘任务并处理障碍物,设计了一个分解的奖励函数,智能体在一轮训练中获得的奖励为三阶段奖励之和,如公式(1) 所示。
式中: 为智能体在一轮动作中获得的总奖励; 为本轮动作的第 阶段所获得的奖励。
在每个阶段,机械臂都应该不断逼近目标位置。每个时间步 计算末端执行器与当前阶段目标的距离变化量及状态来赋予奖励。各阶段奖励计算方法由公式(2) 定义。
式中: 和 分别表示接近、抓取和放置阶段的奖励值; 为对应的奖励系数; 和 分别表示接近、抓取和放置阶段末端执行器距离目标点的距离;t表示离散系统时间步。在末端执行器达到对应阶段的目标时给予奖励:第1阶段成功到达接近点给予1次性奖励 ;第2阶段成功到达果实位置给予一次性奖励 ;第3阶段成功到达放置位置给予一次性奖励 。每检测到1次手爪被障碍物干涉事件,以及末端执行器任意部分与刚性障碍物产生碰撞,给予惩罚 。为鼓励机械臂更快完成任务,对每1步动作都施加时间惩罚 ,即每动作1步都会累积负分,促使其以尽量少的步数完成目标。
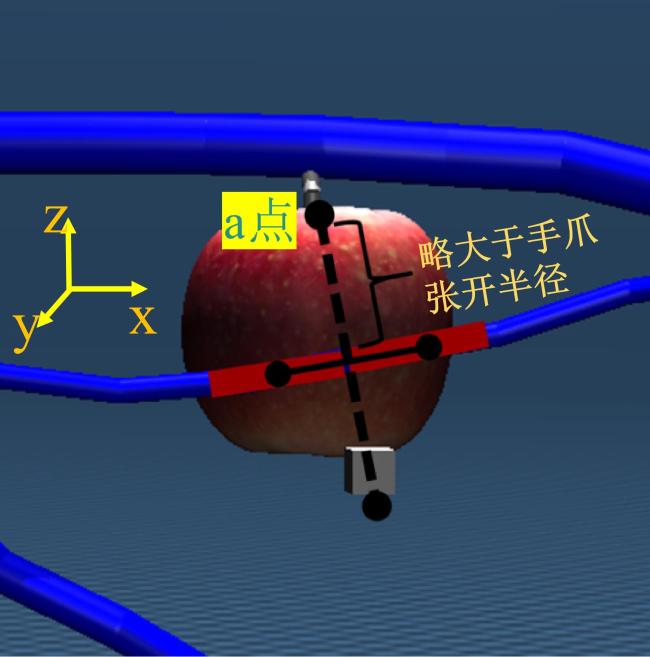
专家演示通过分层设计关键路径点实现标准化轨迹约束,针对柔性枝条遮挡问题设计拨枝引导点,在仿真环境中,先定位距目标果实最近的两段柔性枝条并提取其三维位置坐标,连接两点形成基准线以确定枝条主体走向,在xoz平面内作基准线的垂线,取垂线上与基准线相交点距离略大于手爪半径的上方位置,作为拨枝引导点a点,如图4所示,确保机械臂能以合适的角度拨动枝条,针对果实抓取姿态设计抓取引导点,明确该引导点位于果实位置坐标的z-0.45、y+0.4处,此位置可引导机械臂从预设的方向接近果实,避免机械臂从其他方向接近果实导致果实被碰掉。最后通过控制机械臂沿预设的点位完成采摘任务,同步采集运动过程中的状态动作数据对,形成包含完整动作序列的专家演示数据集,为后续策略网络预训练提供高质量样本。
策略网络采用1个3层全连接神经网络,其输入为425维的状态向量,经过两个各含512个神经元的隐藏层后,输出1个8维向量。通过行为克隆方法,在收集的专家“状态-动作”数据对上进行监督学习,以最小化交叉熵损失的方式模仿专家决策,从而完成对策略网络的有效预训练。
训练过程中,通过对损失引入类别权重来应对演示数据中各动作不平衡的问题,使得稀有动作得到更大的梯度更新权重。训练后策略网络可以复现专家的抓取行为,达到一定水平的初始成功率和奖励。接下来采用HER-SAC算法对策略进行优化微调。算法包括策略网络 和两个Q价值网络 。策略网络初始化为行为克隆得到的参数 ,价值网络随机初始化。让智能体与仿真环境反复交互采样,新策略选择动作与环境产生新的状态转移和奖励,并将这些经验 存储到回放缓冲区中。为提高样本效率,引入HER机制,对每条采摘轨迹进行二次标注以扩充训练样本,额外生成若干“虚拟成功”片段以强化学习信号。每若干步交互后,从缓冲区采样一个小批量经验,用于更新价值网络和策略网络参数。
在策略网络的更新过程中,为了约束策略不要偏离专家演示过远,引入了与行为克隆策略 之间的KL散度正则项,SAC采用最大化策略期望回报和策略熵的加权和。在离散动作情形下,策略更新的目标可表示为公式(3) 。
式中: 为从经验回放缓冲区D中采样的状态s求期望; 为在当前策略 下,给定状态 时采取动作 的概率; 为熵系数; 为 价值网络输出的状态-动作价值。在此基础上加入KL正则项,形成新的策略损失,如公式(4) 所示。
式中: 为正则系数,表示两个离散分布之间的KL散度; 表示当前策略 相对于行为克隆策略 的偏离程度,由公式(5) 定义。
式中:p(a)为当前策略的动作分布 ,q(a)为专家策略的动作分布 ,在强化学习训练开始时保存了行为克隆阶段的策略副本 ,并在每次更新时用其输出概率。
与当前策略概率 计算KL散度。 作为固定参考。最终,策略网络的梯度来自上述 的期望梯度,对应实现上将从两部分累积:一部分是标准SAC策略梯度;另一部分是KL散度对策略参数的梯度,如公式(6) 所示。
式中: 为关于参数 的梯度算子; 为Kullback-Leibler(KL)散度,它是用于衡量两个概率分布之间差异的指标; 为行为克隆策略下采取动作a的概率。
在工程实现中,为降低计算复杂度,首先从经验回放缓冲区中采样一批“状态-动作”样本,用这些样本近似计算当前策略与专家策略的KL散度;然后将该KL值乘以正则化系数 ,加到标准SAC的策略损失中,形成包含奖励优化和专家约束的总损失;最后通过反向传播计算总损失对策略网络参数的梯度,用梯度下降更新参数,确保策略在优化抓果效率的同时,不偏离专家演示的安全避障动作。
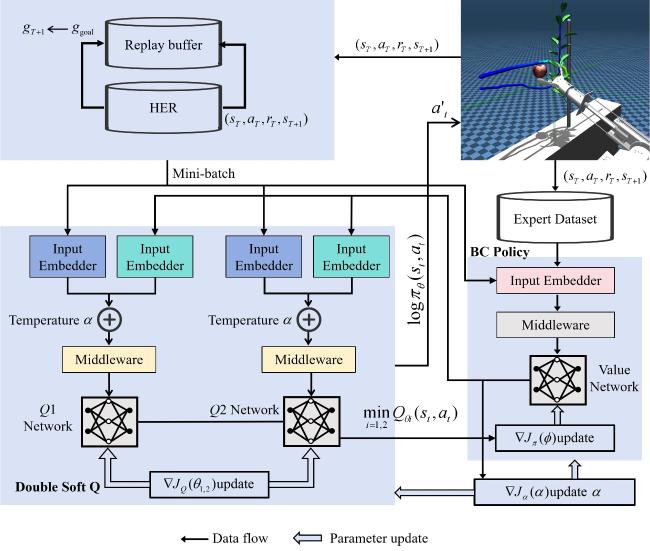
图5给出了整个策略训练体系。整个策略训练体系遵循“先模仿,后强化”的范式。先用脚本专家在仿真中生成演示轨迹,在轨迹生成阶段,通过在一定范围内随机调整刚性枝条与柔性枝条的位置和角度来构建多样化的遮挡场景,以此覆盖简单柔性遮挡、刚柔混合遮挡、刚性遮挡等不同作业工况,且采集的专家数据包含了成功采摘与失败操作的全量轨迹,以保证数据的完整性和多样性,为模型学习故障规避策略提供充足样本。再以此离线预训练一个初始策略网络。将该初始策略部署于强化学习框架中,在每回合随机化的仿真环境下进行在线交互学习。采用SAC算法进行策略更新,并通过引入KL散度正则化项,约束学习过程中的策略与初始专家策略保持一致性,从而确保探索的稳定性和高效性。这种方法有效融合了专家策略的稳健性与强化学习自我优化的潜力,训练收敛后即可固化策略参数用于后续部署。
2 结果与分析
为全面评估本研究方法的性能,采用由仿真到实物的递进式试验验证体系。首先在仿真环境中验证算法有效性,然后部署到实物机器人平台在果园场景开展试验,并分析试验结果。在现场试验数据中,碰撞率的计算基准为:在一组采摘作业流程中,机械臂末端执行器手爪与试验场景内障碍物发生预设判定事件的频次,占总采摘次数的比例。碰撞判定事件具体界定两类场景:手爪与试验场景中的刚性障碍物发生直接接触性碰撞;试验场景中的柔性枝条进入手爪的夹持间隙,导致手爪夹持动作受阻或无法正常完成后续采摘流程干扰事件,如公式(7) 所示。
式中: 为碰撞率;C为碰撞次数;N为总抓取次数,次。
苹果采摘的单轮用时,定义为从机械臂处于随机初始位姿状态下启动动作开始,至完成果实抓取操作并在释放果实至接果框内整个流程所消耗的总时长。任务平均耗时为成功采摘轮次的平均用时,模型抓取轮次不计人工传入枝条位置所用的时间,如公式(8) 所示。
式中: 为平均用时,s; 为单轮成功采摘用时,s;N为总抓取次数,次。
2.1 仿真试验
基于MuJoCo物理引擎构建了机器人果实采摘仿真环境,实现机器人系统与果园环境的动态交互仿真,如图1所示。仿真系统主要包括以下组成部分:机器人移动平台、多自由度机械臂、具有刚性/柔性混合特性的果树模型,以及果实目标物等,其中机器人平台基于课题组自主研发的果园多臂采摘机器人进行建模。为充分模拟真实果园作业环境中枝条姿态和果实分布的随机性特征,采用运动捕捉(Motion Capture, MoCap)技术实现枝条位姿和果实位置的参数化随机生成,有效增强训练数据的多样性和场景覆盖度。图6展示了不同随机化配置下的果实-枝条分布场景。此外,通过对机械臂初始位姿进行同步随机化处理,构建了涵盖多种空间几何关系的“果实-枝条-机械臂”配置组合,为强化学习算法提供丰富的训练样本空间。

为验证专家引导的有效性,本研究设置对比试验,以未引入外部引导的标准SAC算法为基准组,以本研究提出的专家引导SAC算法(Expert - Guided Soft Actor-Critic, EG-SAC)为试验组,在完全相同的训练条件下开展性能比较,其中EG-SAC算法先采用包含600条专家轨迹(约15万步数据)的专家数据集对策略网络进行预训练。
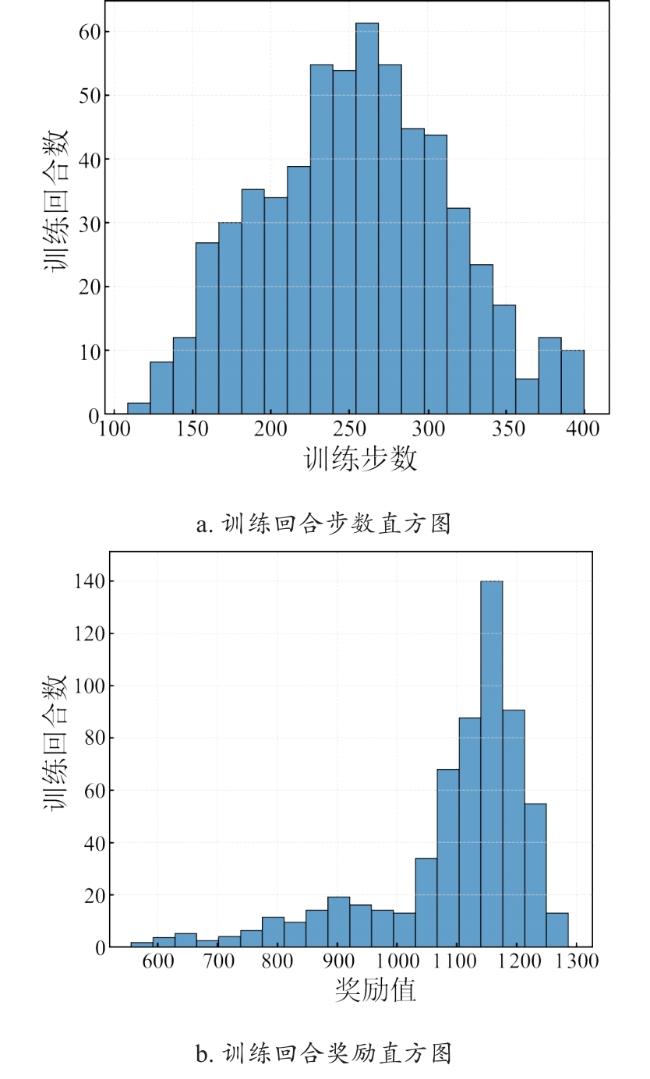
随后与标准SAC算法一同进入SAC阶段训练,且两组算法的SAC阶段训练均设置为1 500轮,每轮最长600步,每步进行1次网络更新,同时两者的超参数设置完全一致,具体超参数取值如表1所示。
表1 SAC/EG-SAC算法统一超参数设置Table 1 Unified hyperparameter settings for SAC/EG-SAC algorithms |
| Parameter | Value |
|---|---|
| Actionsize | 8 |
| Observationsize | 425 |
| Networksize | 512 512 |
| Batchsize | 1 024 |
| Buffersize | 106 |
| Learningrate | 0.001 |
| Trainingsteps | 600 |
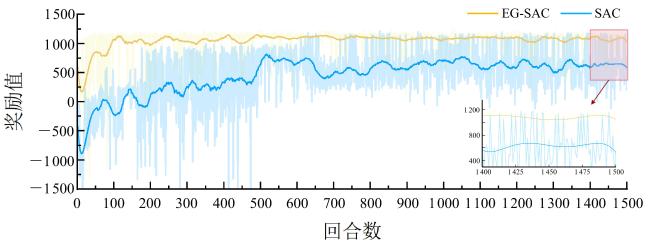
首先进行训练效果对比,通过实时记录并分析两种算法在相同1 500轮训练周期内的累计奖励变化曲线,如图8所示,可观察到显著的性能差异。EG-SAC前期0~150轮次就迅速收敛,奖励值快速升至1 000左右,而标准SAC前期收敛缓慢,回升过程显著滞后。EG-SAC收敛后性能稳定,奖励值波动小,标准SAC始终存在大幅波动,稳定性差。最终收敛水平上,EG-SAC稳定在1 100~1 200的奖励值区间且较为稳定,标准SAC仅维持在400~800,两者性能差距明显。EG-SAC在收敛速度、稳定性及最终性能上均优于标准SAC,收敛效率与鲁棒性更优。经定量计算,EG-SAC算法达到稳定奖励值所需的训练轮次仅为标准SAC的30%左右,训练效率较标准SAC提升75%,最终性能更优。
除了定量结果,本研究还对机械臂的避障行为进行了观察分析。对于柔性障碍本研究方法会驱动机械臂利用手爪将柔性树枝推到一旁。在成功案例中,枝叶往往被压弯让出一条通路,机械臂趁隙伸入完成抓取,如图9所示。

2.2 果园现场试验
2.2.1 苹果采摘执行系统

机械臂末端执行器由3个柔性仿生曲面手指构成。手指内部为刚性支撑结构,表面包裹柔软硅胶,有效避免对果实的损伤,可抓取直径70~100 mm的果实,末端执行器最大载荷5 kg。机器人作业信息感知单元由各作业单元搭载的立体视觉传感器来实现。
试验场景为标准矮化密植果园,如图11所示,果行间距约3.5 m、树高约2.5 m,树间距约1.2 m,树冠厚度为0.5~0.75 m。

系统部署阶段,采摘机器人通过集成的视觉感知系统实现果实目标的检测与三维定位。视觉系统主要包括视觉传感器(Red Green Blue-Depth, RGB-D)和中央处理单元两个核心模块。具体工作流程为:视觉感知系统首先利用RGB-D传感器同步获取目标区域的彩色图像和深度信息;然后采用YOLOv8(You Only Look Once version 8)深度学习模型对RGB图像中的苹果目标进行检测,输出包含目标位置的2D边界框和像素级分割掩码;最后将彩色图像与深度图像进行配准融合生成三维点云,并基于分割掩码提取对应的果实点云区域,从而获得苹果果实的完整三维几何信息。
2.2.2 现场试验场景设计
为验证本研究提出的智能交互策略的有效性,通过矮化密植标准化果树作为物理试验平台,选取3种典型遮挡场景进行试验。每个场景选取20个果实样本,针对果实、枝条等生物样本的固有差异性,按类型归类实现近似控制。对于不易折断且碰撞后不会影响手爪正常动作的枝条按柔性枝条处理,对于会影响正常抓取动作的枝干或铁丝等按刚性障碍物处理。通过对刚柔障碍物进行定性区分来找到符合要求的场景进行试验,共设计了3种场景。
(1)场景一:果实前方有简单柔性遮挡。机械臂需要拨开遮挡的柔性枝条完成采摘。
(2)场景二:果实前方存在柔性枝条遮挡,附近存在刚性枝条。手爪需从避开刚性枝条的方向接近果实,同时拨开柔性枝条进行采摘。
(3)场景三:果实前方存在刚性障碍物遮挡。此时应视情况放弃抓取或绕开刚性枝条进行抓取。
为确保试验对比的公平性,在同一轮对比试验中,所有算法均采用相同的机械臂初始位姿;不同轮次试验则通过随机化初始位姿来验证算法的泛化性能。场景样例细节如图12所示。

2.2.3 采摘规划控制策略
本研究将枝条的刚柔属性及空间位置信息作为系统先验知识处理。具体实现方案为:通过人工标注方式在枝条上选取特征关键点,采用分段折线拟合方法构建枝条的三维空间几何模型,在效率上单株果树关键枝条标注耗时约3 min,后续可通过结合语义分割模型实现枝条刚柔属性的半自动化标注,以提升作业实时性。在模型部署阶段,需要获取训练模型观测空间的必要输入信息:果实位置信息可通过视觉系统直接获取;枝条位置信息则采用手动标注方法实现,即在深度相机视野范围内对目标枝条进行关键点标注,获取枝条的离散空间坐标序列,进而通过几何计算处理得到各枝条段的位置、姿态和长度等几何参数。在完成刚柔属性赋值后,通过坐标系变换将枝条信息统一转换至世界坐标系下,形成完整的环境先验知识库。
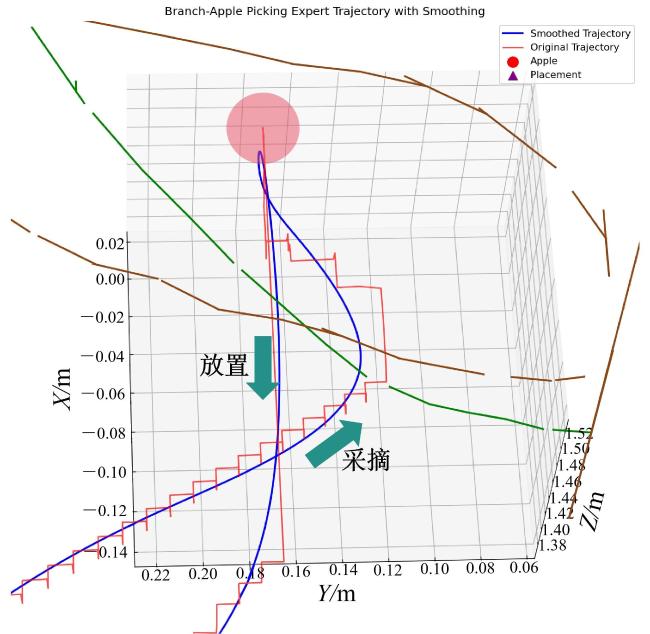
强化学习模型输出的离散动作序列无法直接用于物理控制,会导致执行器抖动和控制精度下降。本研究采用3次样条插值法对轨迹进行平滑处理,确保速度和加速度连续变化,如图13所示。平滑后的轨迹转换为位置序列,通过逆运动学求解获得各关节角度,实现机械臂的平滑控制。
2.2.4 试验结果与分析
为确保采摘机器人操作与试验流程的规范性和可重复性,具体实施步骤如下:首先,将采摘机器人的机械臂调整至随机初始姿态,消除固定初始位置对试验结果的干扰;其次,通过视觉感知系统,采集当前视角下果树的彩色图与深度图,其中彩色图主要用于识别果实,深度图用于计算果实位置以及手动传入目标障碍物信息。机械臂初始位置、果实位置及障碍物分布信息全部采集整合后,将这些信息输入至预先训练收敛的EG-SAC模型,由模型基于环境信息进行自主运动规划与决策,输出适配当前场景的最优动作序列;最后,通过机器人的运动控制模块,将模型输出的动作序列平滑处理后转化为机械臂末端位置的轨迹信息,以此驱动机械臂按规划路径完成避障、靠近、抓取等采摘动作,其中苹果采摘机器人在该流程下的灵巧作业运动过程如图14所示。

针对上述设计的3种场景进行试验记录,通过统计成功率、放弃抓取率和碰撞率等指标进行定量评估。对EG-SAC和RRT方法在3个场景下分别开展20次采摘试验。记录抓果试验中遇到的情况及平均耗时等指标,以此对比两种方法的表现,在成功案例中,EG-SAC平均耗时与RRT方法基本持平。
从单次任务的执行细节来看,EG-SAC方法在各场景下的作业稳定性显著优于RRT方法。在场景一的简单柔性遮挡中,EG-SAC成功抓取16次,出现3次抓到障碍物;而RRT方法仅成功7次,17次出现抓到障碍物的情况。EG-SAC通过学习到拨枝策略主动推开柔性枝条,而RRT仅依赖静态几何路径规划,无法灵活处理枝条,易陷入枝条手爪干涉困境。在场景二的刚柔混合遮挡中,EG-SAC成功12次,3次放弃抓取,无刚性碰撞案例;RRT方法仅成功6次,3次发生刚性碰撞,9次放弃抓取。EG-SAC的差异化避障机制可识别刚性障碍物并规划绕行路径,同时完成柔性枝条拨动,而RRT难以兼顾刚柔障碍物的不同约束,易因路径贴合刚性枝条触发碰撞或安全停机。对于场景三的仅刚性遮挡,EG-SAC成功15次,仅1次刚性碰撞;RRT方法成功8次,但13次发生刚性碰撞。EG-SAC可通过策略决策判断刚性遮挡的可绕行性,而RRT的路径搜索易陷入局部最优,频繁与刚性结构发生接触。
在作业耗时上,EG-SAC各场景平均耗时为12.11~12.62 s,与RRT的11.23~12.18 s基本持平,说明EG-SAC在提升作业鲁棒性的同时,未牺牲作业效率。试验结果如表2所示。
表2 EG-SAC方法与RRT方法性能对比Table 2 Performance comparison between the EG-SAC method and the RRT method |
| 模型 | 场景 | 抓果 次数/次 | 成功 数/次 | 抓空 数/次 | 抓到障碍物数/次 | 抓住后掉落数/次 | 对准抓失败数/次 | 与刚性碰撞数/次 | 放弃抓果数/次 | 平均 耗时/s |
|---|---|---|---|---|---|---|---|---|---|---|
| EG-SAC | 场景一 | 20 | 16 | 1 | 3 | 2 | 1 | 0 | 0 | 12.11 |
| 场景二 | 20 | 12 | 1 | 4 | 2 | 2 | 0 | 3 | 12.24 | |
| 场景三 | 20 | 15 | 0 | 1 | 1 | 0 | 1 | 4 | 12.62 | |
| RRT | 场景一 | 20 | 7 | 1 | 17 | 2 | 6 | 0 | 4 | 11.23 |
| 场景二 | 20 | 6 | 1 | 11 | 2 | 2 | 3 | 9 | 12.18 | |
| 场景三 | 20 | 8 | 2 | 6 | 4 | 1 | 13 | 5 | 11.64 |
试验数据表明,相较于RRT方法,本研究EG-SAC方法在3类典型果园障碍物遮挡工况下,不仅实现了更优的采摘作业成功率,还显著降低了机械臂与障碍物的碰撞风险。从成功率看,EG-SAC在简单柔性遮挡、刚柔混合遮挡、刚性遮挡场景下成功率分别为80%、60%、75%,平均达71.7%;RRT对应场景成功率分别为35%、30%、40%,平均35.0%。EG-SAC综合成功率为其2.05倍。在碰撞率上,EG-SAC平均碰撞率仅为13.3%,RRT则高达81.7%,前者碰撞风险仅为后者1/6。具体统计结果如表3所示。
表3 EG-SAC/RRT方法各场景成功率与碰撞率统计对比Table 3 Statistical comparison of success rates and collision rates of EG-SAC/RRT methods in various scenarios |
| 方法 | 指标类型 | 场景一 | 场景二 | 场景三 | 平均值 |
|---|---|---|---|---|---|
| EG-SAC | 成功率/% | 80 | 60 | 75 | 71.7 |
| 碰撞率/% | 10 | 20 | 10 | 13.3 | |
| RRT | 成功率/% | 35 | 30 | 40 | 35.0 |
| 碰撞率/% | 85 | 70 | 90 | 81.7 |
为明确两种方法在采摘过程中的失效分布与根源,对不同失效类型的出现次数及主要原因进行了统计分析,如表4所示。
表4 EG-SAC/RRT方法失效模式统计分析Table 4 Statistical analysis of failure modes for EG-SAC/RRT methods |
| 失效类型 | EG-SAC出现次数/次 | RRT出现次数/次 | 主要原因分析 |
|---|---|---|---|
| 抓空 | 2 | 4 | 果实定位误差/手爪精度不足 |
| 抓到障碍物 | 8 | 34 | 路径规划不当/拨枝时摩擦力不足拨枝失败 |
| 抓住后掉落 | 5 | 8 | 夹持力控制问题/被障碍物阻挡 |
| 对准抓失败 | 3 | 9 | 连同枝条一起抓到导致抓取失败 |
| 刚性碰撞 | 1 | 16 | 避障策略失效 |
| 放弃抓果 | 7 | 18 | 安全策略触发 |
分析表明,RRT方法的主要失效模式为抓到障碍物,占总失效的42.0%,说明传统路径规划方法在复杂障碍环境下缺乏有效的交互策略,EG-SAC在路径规划与避障策略上更具优势,其失效多为细节控制类问题。
综合分析试验结果表明,EG-SAC方法在单次采摘耗时上与RRT方法基本持平,但考虑成功率差异,从整体作业效率角度分析,EG-SAC有效采摘率为3.49次/min,比RRT方法的1.80次/min提升93.9%,证明了本方法在实际应用中的显著优势。为验证试验结果的统计学意义,对两种方法的成功率进行卡方检验,结果显示 =14.72,P<0.001,表明两种方法在采摘成功率上存在显著差异。不同场景下的性能差异主要源于EG-SAC方法具备更强的障碍物交互能力和智能决策机制,能够有效处理刚柔混合障碍环境。从实际应用角度看,本方法在保证高成功率的同时显著降低了碰撞风险。
3 结 论
本研究基于专家演示的采摘机器人刚柔混合避障方法,提出了刚柔障碍物的差异化处理机制,建立了专家经验驱动的SAC学习框架,EG-SAC专家数据引导使策略网络迅速学习拨枝和抓取的基础能力,规避了传统SAC训练前期因盲目探索导致的无效动作,同时KL散度正则化约束进一步限制了策略更新过程中的偏离程度,实现了收敛速度与稳定性的双重提升,根据训练奖励值曲线得出训练效率提升75%;通过在实物仿真平台及果园采摘机器人的部署,相较于传统RRT方法,综合采摘成功率提高2倍左右,碰撞率降低68%左右。试验结果表明,较高成功率和较低碰撞率主要得益于EG-SAC能够将位于果实附近的柔性枝条拨开,以及面对刚性枝条能够调整姿态进行避让,之后再对准果实,完成抓取。本研究为果园采摘机器人的产业化应用提供了有效的技术解决方案,未来可通过模型优化和硬件加速进一步提升响应速度,对推动农业机器人实用化具有重要意义,所提出的专家引导框架可扩展至其他复杂操作任务。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}