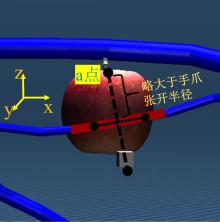
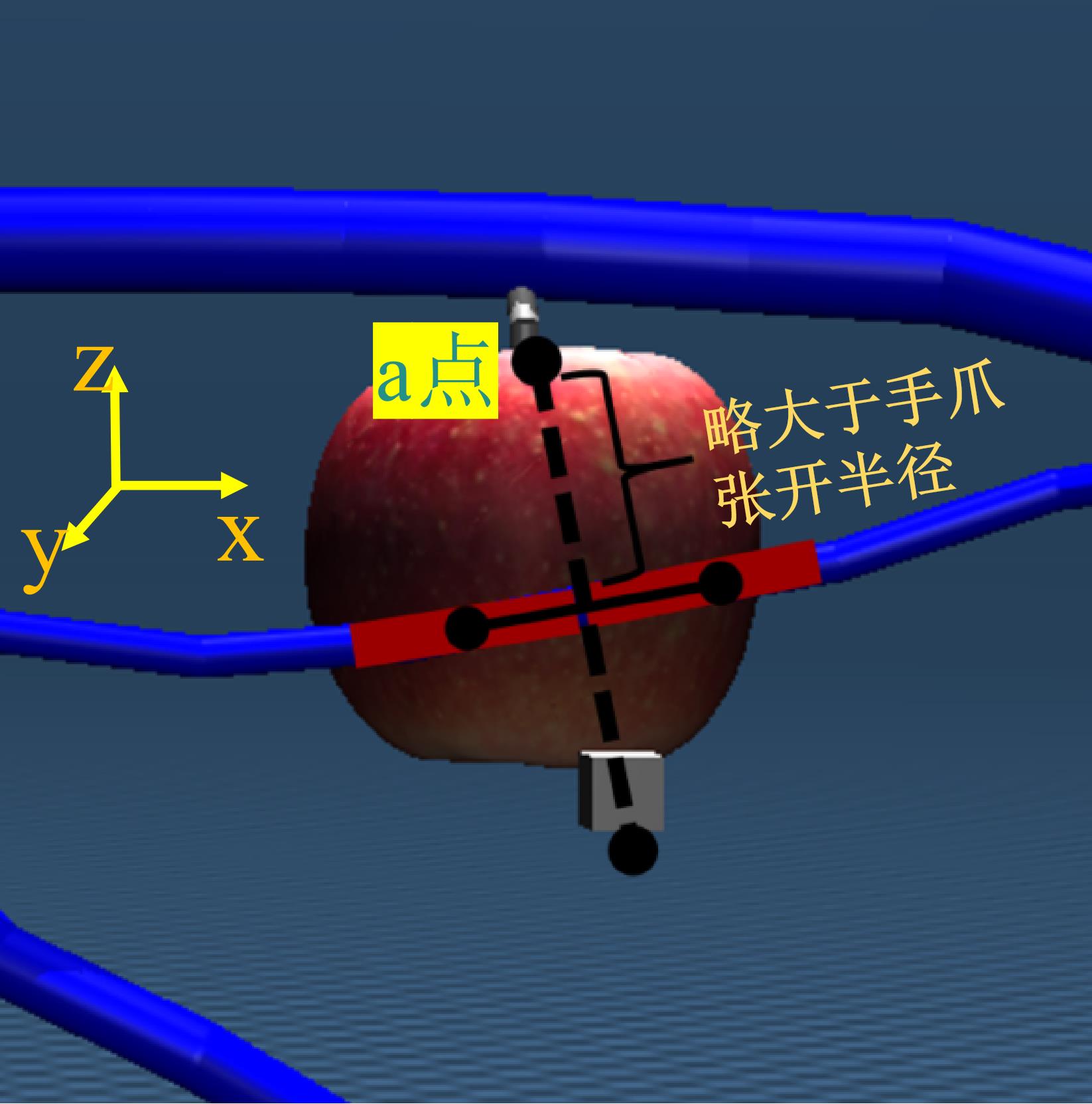
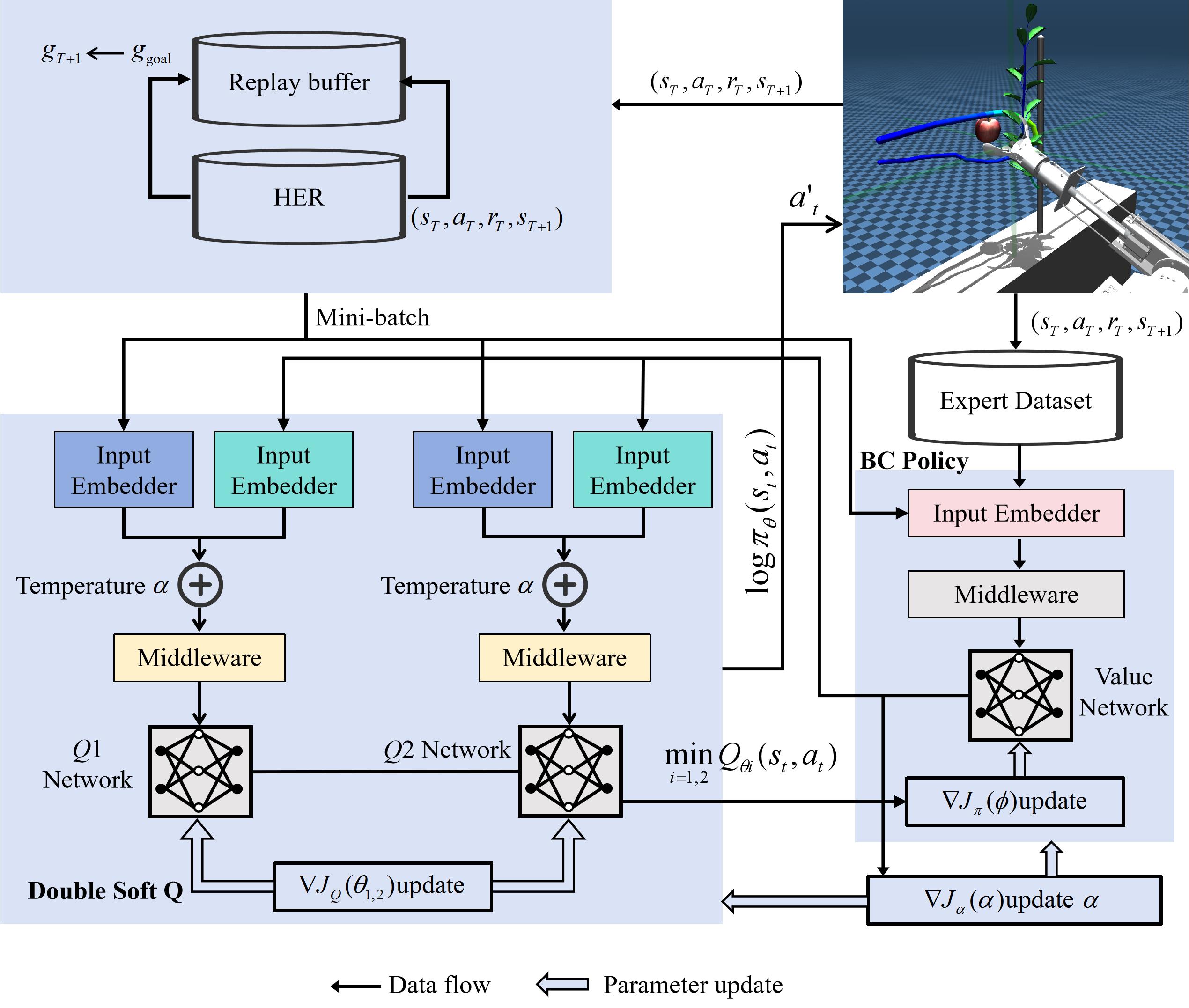
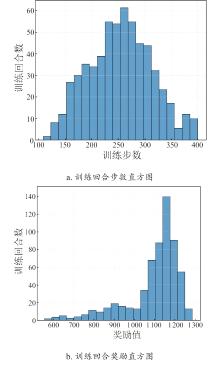
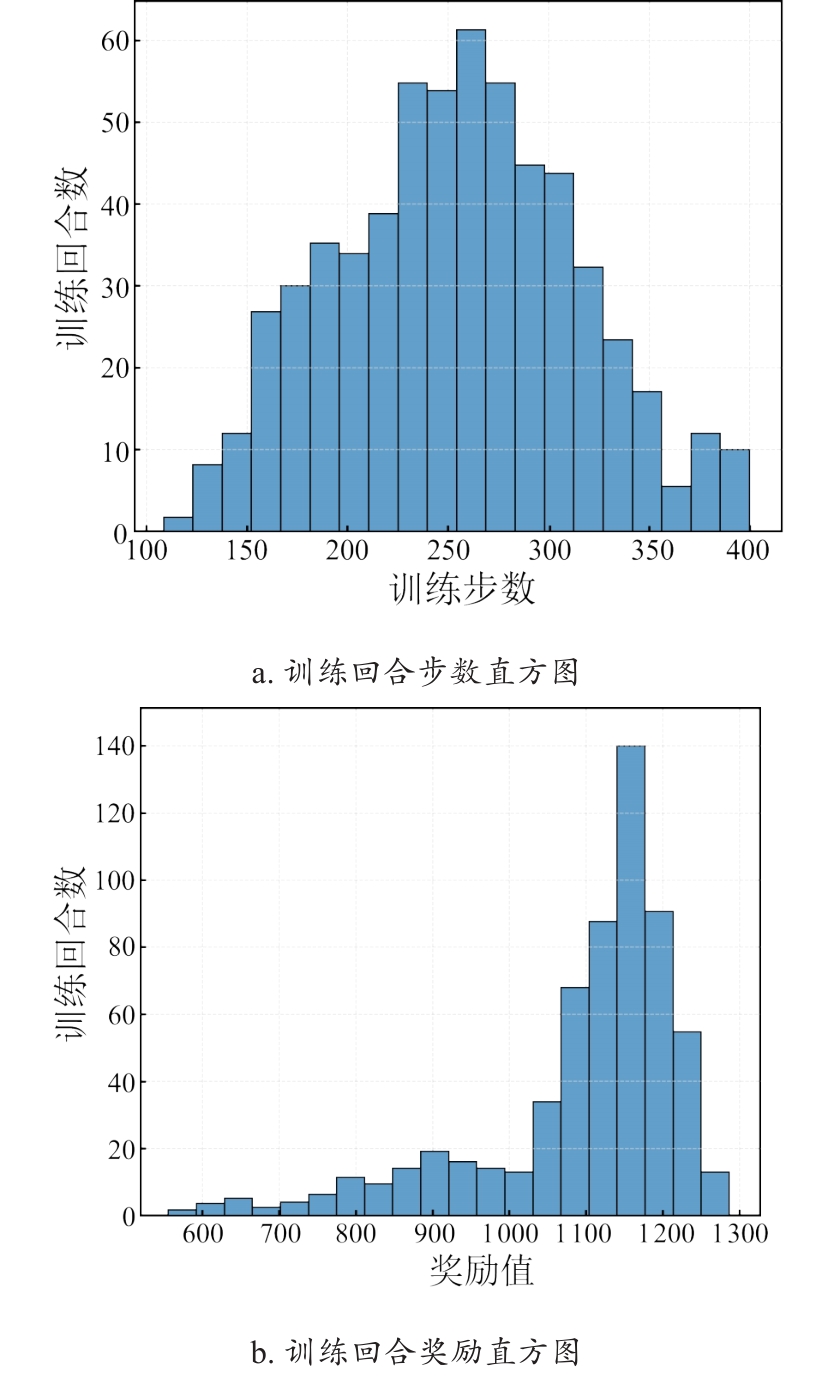
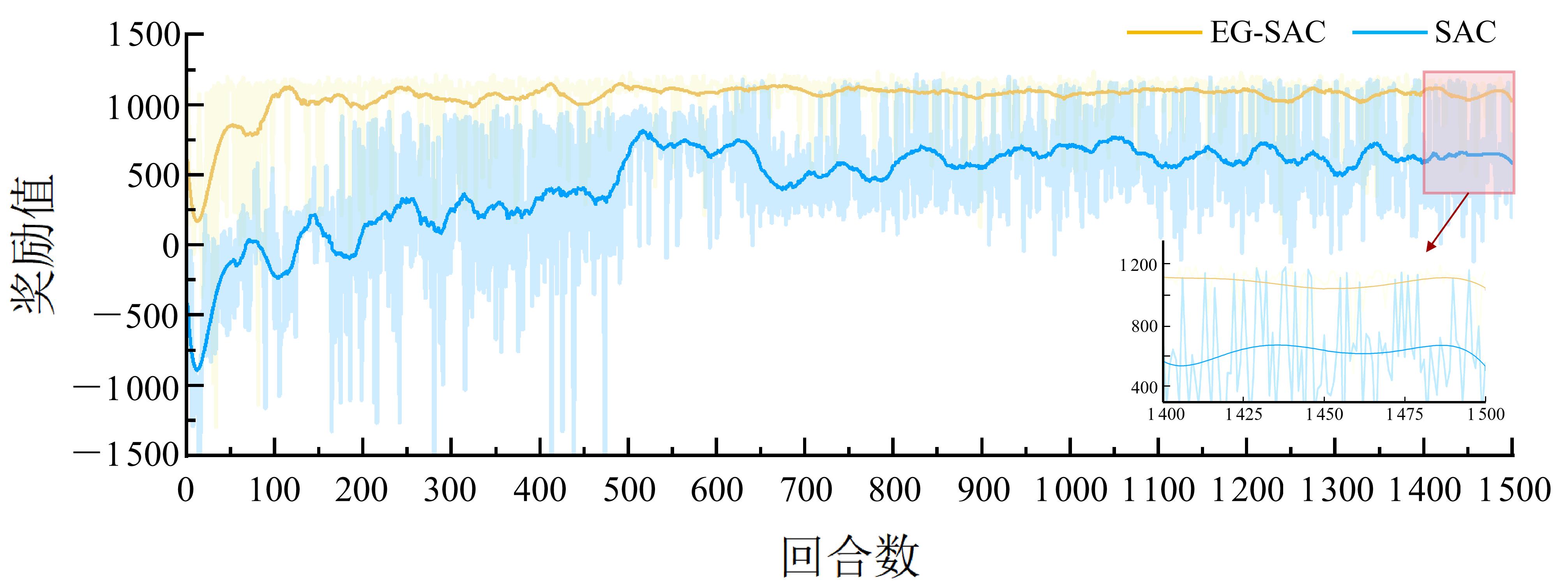
| [1] |
赵春江, 范贝贝, 李瑾, 等. 农业机器人技术进展、挑战与趋势[J]. 智慧农业(中英文), 2023(4): 1-15.
|
|
ZHAO C J, FAN B B, LI J, et al. Agricultural robots: Technology progress, challenges and trends[J]. Smart agriculture, 2023(4): 1-15.
|
| [2] |
JIN Y C, LIU J Z, XU Z J, et al. Development status and trend of agricultural robot technology[J]. International journal of agricultural and biological engineering, 2021, 14(3): 1-19.
|
| [3] |
TANG Y, DANANJAYAN S, HOU C J, et al. A survey on the 5G network and its impact on agriculture: Challenges and opportunities[J]. Computers and electronics in agriculture, 2021, 180: ID 105895.
|
| [4] |
GONGAL A, AMATYA S, KARKEE M, et al. Sensors and systems for fruit detection and localization: A review[J]. Computers and electronics in agriculture, 2015, 116: 8-19.
|
| [5] |
KIM W S, LEE D H, KIM Y J, et al. Path detection for autonomous traveling in orchards using patch-based CNN[J]. Computers and electronics in agriculture, 2020, 175: ID 105620.
|
| [6] |
GUO Z W, FU H, WU J H, et al. Dynamic task planning for multi-arm apple-harvesting robots using LSTM-PPO reinforcement learning algorithm[J]. Agriculture, 2025, 15(6): ID 588.
|
| [7] |
HUA W J, ZHANG Z, ZHANG W Q, et al. Key technologies in apple harvesting robot for standardized orchards: A comprehensive review of innovations, challenges, and future directions[J]. Computers and electronics in agriculture, 2025, 235: ID 110343.
|
| [8] |
CAO X M, ZOU X J, JIA C Y, et al. RRT-based path planning for an intelligent litchi-picking manipulator[J]. Computers and electronics in agriculture, 2019, 156: 105-118.
|
| [9] |
YE L, DUAN J L, YANG Z, et al. Collision-free motion planning for the litchi-picking robot[J]. Computers and electronics in agriculture, 2021, 185: ID 106151.
|
| [10] |
LUO L F, WEN H J, LU Q H, et al. Collision-free path-planning for six-DOF serial harvesting robot based on energy optimal and artificial potential field[J]. Complexity, 2018, 2018: 1-12.
|
| [11] |
ROSTAMI S M H, SANGAIAH A K, WANG J, et al. Obstacle avoidance of mobile robots using modified artificial potential field algorithm[J]. EURASIP journal on wireless communications and networking, 2019, 2019(1): ID 70.
|
| [12] |
BAC C W, ROORDA T, RESHEF R, et al. Analysis of a motion planning problem for sweet-pepper harvesting in a dense obstacle environment[J]. Biosystems engineering, 2016, 146: 85-97.
|
| [13] |
LI Y J, FENG Q C, ZHANG Y F, et al. Peduncle collision-free grasping based on deep reinforcement learning for tomato harvesting robot[J]. Computers and electronics in agriculture, 2024, 216: ID 108488.
|
| [14] |
WANG Y C, HE Z, CAO D D, et al. Coverage path planning for kiwifruit picking robots based on deep reinforcement learning[J]. Computers and electronics in agriculture, 2023, 205: ID 107593.
|
| [15] |
LIN G C, ZHU L X, LI J H, et al. Collision-free path planning for a guava-harvesting robot based on recurrent deep reinforcement learning[J]. Computers and electronics in agriculture, 2021, 188: ID 106350.
|
| [16] |
SUN J H, FENG Q C, ZHANG Y F, et al. Fruit flexible collecting trajectory planning based on manual skill imitation for grape harvesting robot[J]. Computers and electronics in agriculture, 2024, 225: ID 109332.
|
| [17] |
LI T, XIE F, ZHAO Z Q, et al. A multi-arm robot system for efficient apple harvesting: Perception, task plan and control[J]. Computers and electronics in agriculture, 2023, 211: ID 107979.
|
| [18] |
YANDUN F, PARHAR T, SILWAL A, et al. Reaching pruning locations in a vine using a deep reinforcement learning policy[C]// 2021 IEEE International Conference on Robotics and Automation (ICRA). Piscataway, New Jersey, USA:IEEE, 2021: 2400-2406.
|
| [19] |
LIU Y Q, GAO P, ZHENG C G, et al. A deep reinforcement learning strategy combining expert experience guidance for a fruit-picking manipulator[J]. Electronics, 2022, 11(3): ID 311.
|
| [20] |
LI T, XIE F, QIU Q, et al. Multi-arm robot task planning for fruit harvesting using multi-agent reinforcement learning[C]// 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway, New Jersey, USA: IEEE, 2023: 4176-4183.
|
 ), 李涛2(
), 李涛2(