



0 引 言
近年来,移动机器人在设施农业中被广泛应用,实现喷药[10]、采摘[11]、巡检[12]、消毒[13]、运输[14]等自动化作业。这些机器人还具备智能感知能力,能实现环境实时监测与控制,为作物的生产管理提供决策支持[15]。其中,自主定位、地图构建、全局路径规划和自动避障控制是设施农业智能机器人实现自主作业的基础[16, 17],也决定了机器人任务应用的准确性和高效性[18]。自主定位和地图构建通过获取机器人的精确位置和姿态信息,为机器人提供环境先验信息,实现对机器人在全局地图中运动状态的准确把握,为设施场景中的自主导航提供重要的空间参考[19, 20]。全局路径规划和避障控制利用定位信息确定机器人移动的最佳路线,综合考虑距离、转角和障碍物等多方面因素,使机器人能够有效避开障碍物,精准执行各项任务,从而提高作业效率、降低资源浪费[21-23]。设施农业机器人导航关键技术如图1所示。
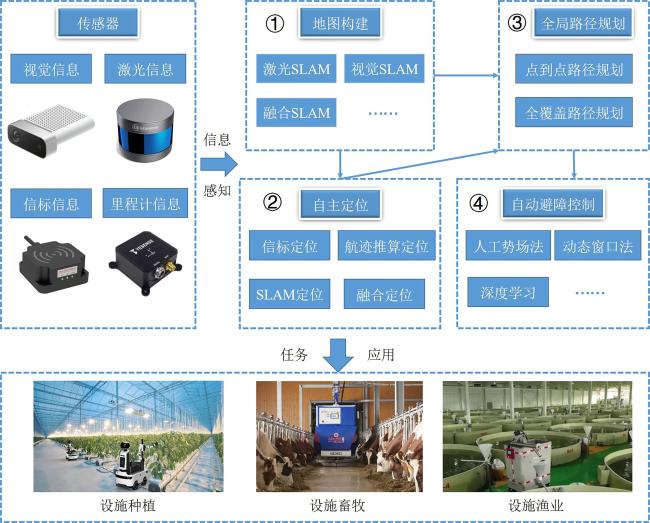
然而,由于信号受限、遮挡严重等因素,设施农业机器人的自主导航面临着多重挑战。因此,本文针对设施农业环境特点,深入分析设施机器人自主导航的关键技术,探讨当前在设施农业场景中应用的自动导航技术所面临的问题与挑战,并展望其未来发展前景。
1 自主定位与地图构建技术
在大田场景中,由于信号遮挡较少,依靠全球定位系统(Global Positioning System, GPS)即可为机器人提供精确的绝对定位。然而,在设施农业中,由于存在遮挡较多,需要其他传感器如射频识别(Radio Frequency Identification, RFID)读写器、车轮编码器、惯性测量单元(Inertial Measurement Unit, IMU)、相机、激光雷达等来实现精确定位,不同传感器特点和适用环境如表1所示。对近年设施农业自主定位和地图构建研究的文献分析[24, 25]发现,机器视觉在定位与地图构建中的应用起步较早,但随着时间推移,即时定位与地图构建(Simultaneous Localization and Mapping, SLAM)、超宽带(Ultra Wide Band, UWB)和深度学习等技术逐渐发挥着越来越重要的作用。从研究地域分布来看,美国、德国等国家的相关研究起步较早且数量较多,而中国的研究数量近年来逐步增加[26, 27]。
表1 设施农业定位常用传感器对比[24]Table 1 Comparison of commonly used sensors for facility agriculture localization |
| 传感器 | 特点 | 适用环境 |
|---|---|---|
| RFID读写器 | 能同时识别多个标签,成本低 | 结构简单、面积不大的环境 |
| 车轮编码器 | 简单可靠,成本低,累积误差大 | 地面平整、干燥的环境 |
| IMU | 无需外部参考,精度较高 | 温度变化不大、磁场稳定的环境 |
| 相机 | 成本较低,提供图像RGB信息 | 纹理信息充足、光照变化小的环境 |
| 激光雷达 | 成本较高,距离信息精度高 | 几何信息充足、空间开阔的环境 |
设施农业智能机器人定位方法主要包括信标定位、惯性定位,以及基于SLAM的定位和融合定位。其中,基于SLAM的定位与融合定位方式逐渐成为设施农业机器人自主定位与地图构建的主流。
1.1 信标定位
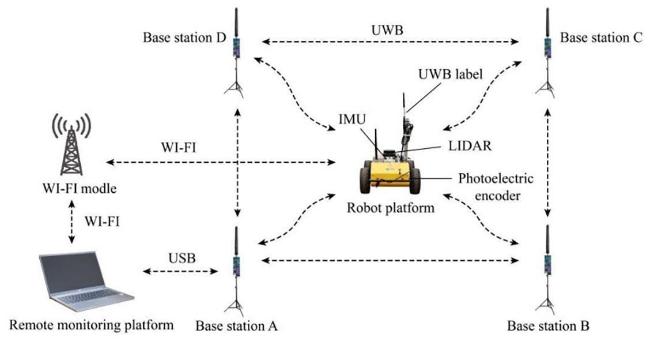
信标定位能够在设施农业中代替GPS为机器人提供全局定位信息,且精度较高,硬件成本较低。但设施环境中的遮挡问题对信标定位构成挑战[31]。部分研究通过与其他传感器融合以提高定位稳定性和精度。毕松等[32]设计了UWB测距值修正模型,并基于扩展卡尔曼滤波器(Extended Kalman Filter, EKF)设计了UWB测距修正值和IMU数据融合方法,有效克服草莓温室内因环境遮挡引起UWB定位精度下降的问题,实现了温室草莓植保机器人作业过程中的可靠定位。将信标定位与深度学习相结合也是提高定位精度与鲁棒性的主要方法。Niu等[33]提出了一种基于残差网络模型ECA-ResNet的测距误差抑制方法,利用深度学习方法学习到不同障碍物遮挡情况下信道冲激响应的变化特征,利用信道冲激响应在不同非视距条件下呈现不同响应状态的特点,预测UWB的测距误差,从而对定位结果进行修正。但深度学习所需的大量数据样本和泛化能力的局限性限制了其在不同设施环境中的大范围应用。Jan等[34]采用UWB技术实现了机器人在室内鸡舍中的高精度定位,并结合视觉引导使其沿饲料盆进行精确移动。该机器人不仅可用于家禽农场的巡查,还能执行清除死鸡和捡拾鸡蛋等任务,其平均定位精度达到40 cm。Feng等[35]在禽畜养殖场的拐角处放置RFID标签与磁钉,记录旋转角度。当消毒喷洒机器人到达时即可按要求转弯,但喷洒路线相对固定。Reshma和Kumar[36]将RFID标签集成至无人机上,实现了高精度的定位功能,在渔场应用中,该系统不仅能够实现精准地投喂,还能确保饲料在笼内的均匀分布,将饲料损失降至最低,此外,该系统具备高度的定制能力,可以扩展应用于其他投入品,如药物、疫苗。这一综合方案显著提升了养殖管理的自动化水平和资源利用效率。
1.2 惯性定位
表3 惯性测量单元类型Table 3 Types of inertial measurement unit |
| 类型 | 测量原件 | 测量参数 |
|---|---|---|
| 三轴IMU | 三轴陀螺仪 | 角速度 |
| 六轴IMU | 三轴陀螺仪、三轴加速度计 | 角速度、线加速度 |
| 九轴IMU | 三轴陀螺仪、三轴加速度计、磁力计 | 角速度、线加速度、朝向 |
通过融合车轮编码器和IMU数据,可以综合两者优势。Qi等[39]利用EKF融合IMU与车轮里程计数据,相比单一传感器提高了畜禽养殖场空气监测机器人的航向角估计准确性。Joffe等[40]针对自动拾取鸡蛋机器人,利用超声波传感器对经EKF融合的车轮里程计与IMU数据进行校正,结果表明,定位精度可达到2 cm。将惯性定位与视觉和激光雷达传感器等其他定位方式多元融合能有效解决累积误差问题[41]。Yan等[24]将视觉惯性里程计、车轮编码器和惯性测量单元的测量集成到EKF中,该定位系统在多种植物茂密的日光温室中展示了良好的精度和鲁棒性。Roldán等[1]将IMU与单线激光雷达传感器相结合,利用EKF整合测量的姿态,并估计环境检测机器人的全局姿态;惯性定位输出频率高,可以提供连续、平滑的位置估计,而视觉或激光雷达可以提供高分辨率、高精度的空间信息,二者结合不仅能提供连续的机器人状态估计,还能在一定时间间隔内利用视觉或激光雷达里程计校正定位偏差。设施渔业场景中,Pribadi等[42]通过将陀螺仪与EKF技术相结合,成功实现了无人船的高精度定位,该研究不仅提高了无人船在复杂环境中的定位精度,而且通过模糊控制策略与蓝牙传输技术,实现渔场的精准投喂。
1.3 基于SLAM技术的定位
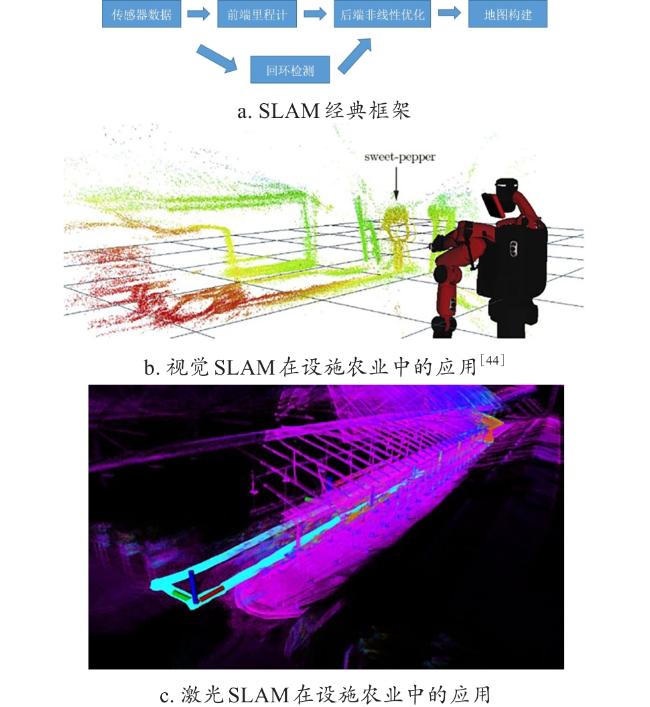
SLAM技术使机器人在未知环境中通过感知建立地图并实时定位其在地图中的位姿。SLAM属于基于特征的传感器定位方式[43]。依据使用的传感器类型分为视觉SLAM、激光SLAM和融合SLAM。经典的SLAM框架由5个部分组成,视觉和激光SLAM在设施环境中都有应用,如图3所示。在SLAM框架中首先利用视觉、激光雷达等传感器获取环境数据,根据数据计算出短时间内的机器人位姿,作为前端的里程计信息。为了降低累积误差,采用滤波或非线性优化方法进行状态估计,得到里程计与全局地图的最优估计。回环检测用于识别是否到达重复场景,若检测到回环即可实现地图和轨迹校正。图3b和图3c展示了视觉与激光SLAM的应用效果。
1.3.1 视觉SLAM
根据是否进行特征提取,视觉SLAM主要分为直接法和基于特征的方法。直接法利用全部像素值进行定位和地图构建,在纹理稀疏或动态场景中表现更好。典型的直接法包括:稠密跟踪与建图(Dense Tracking and Mapping, DTAM)[49]和大规模直接单目SLAM(Large-Scale Direct Monocular SLAM, LSD-SLAM)[50]等。Barth等[44]利用LSD-SLAM重建甜椒三维信息并定位,利用机械臂在温室内实现甜椒采摘。基于特征的方法通过提取和匹配图像中的特征点,估计相机运动和场景的几何结构。该方法速度快、实时性强,但只适用于纹理特征丰富的场景,例如单目SLAM(Monocular SLAM, Mono SLAM)[51]、定向FAST和旋转BRIEF SLAM(Oriented FAST and Rotated BRIEF SLAM, ORB-SLAM)系列[52-54]、实时基于外观建图(Real-Time Appearance-Based Mapping, RTAM)[55]等。Matsuzaki等[56]将基于RGB-D的RTAM算法与语义分割网络相结合,在玫瑰种植温室场景中建立了具有障碍物类型标签的语义地图。语义SLAM不仅考虑环境的几何结构,还关注物体的类别、功能和属性等信息。Krul等[57]在奶牛场谷仓中使用搭载在小型无人机上的单目摄像头比较了LSD-SLAM和ORB-SLAM算法的绝对轨迹和相对姿态误差,结果表明ORB-SLAM的定位精度更高。总体来看,视觉SLAM在设施畜牧和设施渔业中的应用较为有限。在长走廊的禽畜养殖场景中,由于视觉特征的高度重复性和动物的移动性,视觉SLAM面临挑战[58]。目前的改进方法包括开发位姿图优化算法和引入深度学习技术[59-61]。表4对比了不同视觉SLAM算法的特点。
表4 不同视觉SLAM对比Table 4 Comparison of different visual SLAM |
| 类型 | 算法 | 匹配目标 | 实时性 | 定位精度 |
|---|---|---|---|---|
| 直接法 | DTAM | 稠密像素 | 较低 | 高 |
| LSD-SLAM | 稀疏像素 | 中等 | 高 | |
| 基于特征 | Mono SLAM | 单目相机特征点 | 高 | 中等 |
| ORB-SLAM | ORB特征点 | 高 | 高 | |
| RTAM | 模板匹配 | 高 | 中等 |
1.3.2 激光SLAM
激光雷达根据扫描线数可分为单线和多线激光雷达。单线激光雷达通常只能感知单一平面数据,信息获取有限且对安装位置要求高。多线激光雷达可以测量一定范围内的三维数据,但数据量大,依赖更高的计算性能。针对单线激光雷达,季宇寒等[66]融合单线激光雷达与编码器信息,使用Gmapping和分支界定算法建立二维环境地图并搜索最优巡检路线,结合自适应蒙特卡洛定位(Adaptive Monte Carlo Localization, AMCL)算法和PID实现了温室巡检机器人的自动行走。Zhang等[67]研发了一种应用于大规模畜牧场中的巡检系统,采用Gmapping、Hector、Karto三种算法构建畜牧场栅格地图并定位巡检系统,结果表明Karto算法效果最佳。胡勇兵等[68]在工厂化循环水养殖鱼池环境下设计机器人,基于Gmapping算法构建环境栅格地图,采用自AMCL算法实现鱼池清刷机器人精准定位。为了降低多线激光雷达的数据量,Jiang等[2]将三维激光雷达采集的数据滤波为二维激光信息,利用Cartographer算法实现了机器人对日光温室环境的实时定位。还有研究改进Cartographer算法以适应设施环境的复杂性[69]。近年来,随着工控机性能的提升,多线激光雷达LOAM系列在设施场景中的应用逐渐增多[70-72]。表5对比了不同激光SLAM算法的特点。
表5 不同激光SLAM对比Table 5 Comparison of different LiDAR SLAM |
| 类型 | 算法 | 硬件成本 | 实时性 | 定位精度 |
|---|---|---|---|---|
| 单线 | Gmapping | 低 | 中等 | 中等 |
| Cartographer | 低 | 高 | 高 | |
| 多线 | LIO-SAM | 高 | 高 | 高 |
| Lego-LOAM | 中等 | 高 | 高 | |
| Cartographer 3D | 中等 | 高 | 高 |
1.3.3 融合SLAM
目前融合SLAM的传感器包括视觉、激光雷达和惯性传感器等。在融合视觉与激光传感器方面,谢天轩[75]将ORB-SLAM2得到的三维点云图经优化后投影至二维平面,与Cartographer构建的二维激光点云通过融合策略构建信息更丰富的二维栅格地图,帮助植保机器人实现鲁棒、高精度定位。Zhang等[76]设计了一种专在禽畜养殖场中应用的环境监测机器人,该系统采用视觉辅助激光的SLAM方案。采用贝叶斯融合策略,集成激光和视觉ORB-SLAM输出以提高定位准确性和鲁棒性。在与惯性传感器融合方面,Vroegindeweij等[77]通过采用粒子滤波器,将激光雷达、IMU,以及车轮里程计的信息融合应用于拾蛋机器人。该技术显著提升了机器人在大面积鸡舍内的定位精度,定位的平均误差为0.2 m。孙国祥等[78]基于扩展EKF算法融合了轮式里程计和视觉里程计信息实现局部定位,融合激光点云配准算法和AMCL算法实现全局定位,这种方法解决了日光温室内光照变化大、行间距狭窄的问题。
1.4 融合定位
多传感器融合能够有效弥补单一定位的不足,提高设施智能机器人定位的精度和鲁棒性。定位算法根据融合的信息类型和阶段可以分为数据级、特征级和决策级。表6从信息损失、抗干扰能力、实时性和定位精度四个方面对这三种融合方式进行分析。在农业设施场景中,数据级和特征级融合是主流的融合定位方式。数据级融合将不同传感器的原始数据整合,能提供更全面的信息,减少由单一传感器引起的误差。这种方法直接利用原始数据,信息量大,但受限于传感器的精度和同步性。特征级融合则是在传感器提取的特征上进行融合,通过结合不同传感器提取的特征信息提高定位准确性。此方法提高了对环境变化的适应性,但需要精确地特征提取和匹配算法。这两种定位方式信息损失少、精度高,能有效应对设施环境的空间狭小和遮挡问题,确保机器人的作业安全性。例如,SLAM定位通常涉及多传感器融合,如视觉传感器、激光雷达、惯性测量单元和车轮编码器,该方法通过提取环境特征并结合多传感器数据进行定位,属于特征级融合。决策级融合是结果层面的融合,综合考虑不同传感器的定位结果及其可信度,得到最终的定位决策。但需要准确的融合策略和决策规则。高层次决策过程可能未能充分利用各传感器提供的细节信息且易产生累积误差,从而无法达到数据级和特征级融合在处理设施环境时所能提供的精确度。
表6 定位算法数据融合类型Table 6 Data fusion types of localization algorithms |
| 类型 | 信息损失 | 抗干扰能力 | 实时性 | 定位精度 |
|---|---|---|---|---|
| 数据级融合 | 少 | 差 | 低 | 高 |
| 特征级融合 | 中等 | 中等 | 中等 | 中等 |
| 决策级融合 | 多 | 强 | 高 | 低 |
1.5 小结
在设施环境中,障碍物遮挡(设施种植障碍物包括植物、灌溉设备、支撑结构和农业工具,设施养殖障碍物包括动物、饲料和水槽、分隔栏以及清洁设备)、动植物动态变化、可通行空间狭小,以及硬件成本与算力的限制都给机器人的自主定位和地图构建带来了巨大挑战。
信标定位在设施环境中具有良好的精度和实时性,且在设施种植和设施养殖中都展现出广阔的应用前景。然而,设施环境中障碍遮挡会导致信号衰减或多径效应,严重影响定位性能。此外,为了确保信号覆盖,在大面积环境中可能需要布设大量信标基站,显著增加了硬件安装和维护成本。因为水下信标系统的部署和维护成本较高,且在水下环境中信号传播和干扰问题较为复杂。在设施渔业中,信标传感器主要部署在水面和水上机器人中,而在水下的应用受到局限。此外,水下环境的特殊性使得信标技术难以提供稳定的定位精度,尤其是在水体深度变化和水流影响较大的情况下。
惯性定位具有成本低、输出频率高的优势。与信标定位相比,惯性定位无需布置基站,且受外界环境干扰较小。因此,其在设施种植和设施畜牧场景的定位中已经得到了广泛应用。然而,由于惯性定位存在误差随时间累积、漂移等问题,目前多与其他传感器融合使用。与信标定位类似,惯性定位在设施渔业的水下环境应用较少,主要因为水下的运动复杂性和长时间的累积误差使得IMU系统在水下环境中受到的漂移和误差较大,定位精度难以保证。此外,IMU系统对环境变化的适应性较差,导致其在水下深度和水流变化中的表现不稳定。
基于SLAM技术的定位方法具有自主性、实时性和适应性等特点,其在设施种植和设施养殖场景中应用广泛,但也面临挑战。视觉SLAM在光照变化和复杂遮挡下的表现不稳定,机器人任务执行中的抖动可能导致图像模糊,影响算法性能。激光SLAM相对成熟,但存在成本较高、在几何信息匮乏的场景中容易出现退化的问题。总体而言,设施场景的高度重复性导致的纹理、几何信息稀疏,以及场景的动态性都可能会使算法精度和稳定性下降。融合SLAM能有效提升算法的精度和鲁棒性,但也面临硬件成本上升、系统复杂性增加和能耗高的问题。融合定位算法需要实时处理不同来源的数据,这需要高效的算法和大量的计算资源,这些在农业应用中通常是有限的。此外,融合不同传感器数据还需解决传感器之间的同步和数据不一致问题。设施渔业场景中,尤其是在水面和水下机器人中的应用更加有限。水面环境特征单一,SLAM系统难以获取有效的特征点。而水下环境的复杂性高,水流、光线散射和不同的介质特性都显著影响了传感器的数据质量和SLAM系统的性能。此外,水下环境也对传感器提出了更高的要求,大大增加了硬件成本。
以上挑战共同要求在设施农业中开发更加智能和鲁棒性的定位解决方案,以满足实际应用的需求。未来研究可考虑以下方向:第一,在降低成本的同时,提高单个信标的有效信号覆盖范围;改进定位算法,将自主定位与地图构建技术与深度学习方法结合,例如,结合深度学习与信标定位以校正遮挡和环境干扰带来的误差;将语义分割模型与SLAM技术结合,赋予感知物体语义信息和动静态特征。第二,除了提升传感器性能外,通过融合多种传感器(如IMU、视觉传感器、激光雷达等)来提升算法性能,鉴于农业机器人算力有限,应设计轻量级、高效率的融合算法,在有限资源下快速准确地处理传感器数据并生成精确的定位结果。第三,推动低成本高性能传感器和计算硬件的发展,研究适应农业环境的低成本信标方案、新型材料和技术。最后,将自主定位和地图构建与大数据和云计算结合,建立农业环境动态数据库,提升计算能力和数据处理效率。
2 全局路径规划
全局路径规划结合传感器感知信息和上层算法,旨在为设施机器人规划安全高效的运动路线[79]。在设施环境中,通过特定算法设计最佳作业路径,确保机器人安全有效地实现任务目标。近年来,众多全局路径规划研究不断涌现,主要包括点到点局部路径规划和全局遍历路径规划。而根据目标数量不同又分为单目标和多目标路径规划。全局路径规划主要算法如表7所示。相比其他算法,遗传算法和深度学习在全局路径规划中的应用更为广泛,尤其是近年来深度学习的应用显著增多[80, 81]。这些算法能有效处理设施环境中的复杂路径规划问题。此外,全局遍历路径规划算法能确保覆盖设施环境中的所有区域,保证动植物的管理。因此,全局遍历路径规划算法在全局路径规划中占有重要地位。从研究分布来看,中国在该领域的研究成果显著领先于其他国家,这反映了中国对设施农业智能化管理的积极探索。随着深度学习等技术的发展,预计中国的研究将继续向前发展,并在全球范围内产生重要影响[82, 83]。
表7 设施农业场景中的主要全局路径规划算法Table 7 Global path planning algorithms in facility agriculture |
| 算法名称 | 优化目标数量 | 优点 | 缺点 |
|---|---|---|---|
| Dijsktra算法 | 单目标 | 简单,易于实现,能找到最短路径 | 计算效率低,复杂度高 |
| A*算法 | 单目标 | 有效利用启发式信息进行搜索 | 需预先知道目标点位置,不适用于动态环境 |
| 快速扩展随机树(Rapidly-Exploring Random Tree,RRT)算法 | 单目标 | 能够在复杂环境中搜索出连续的路径 | 对高维空间和动态环境的处理能力有限 |
| 蚁群算法 | 多目标 | 具有分布式、自适应和全局搜索能力 | 收敛速度较慢,对问题规模和参数敏感 |
| 遗传算法 | 多目标 | 具有全局搜索和对复杂空间的优秀搜索能力 | 需要适当的编码方式和参数设置,收敛速度较慢 |
| 深度学习算法 | 多目标 | 能够通过学习训练生成高效的路径规划策略 | 训练需要大量的数据和计算资源 |
| 多目标进化算法 | 多目标 | 能够搜索出帕累托前沿的高质量均衡解 | 收敛速度较慢,需要适当的参数设置和运行时间 |
2.1 点到点局部路径规划
点到点局部路径规划是从起始点到目标点的路径规划过程。由于仅涉及起点和终点,这种规划任务简单易行,可以快速确定路径,减少计算复杂度和资源消耗。点到点局部路径规划可分为单目标和多目标路径规划,单目标一般用经典算法实现,而多目标通常用于优化算法。
2.1.1 单目标路径规划
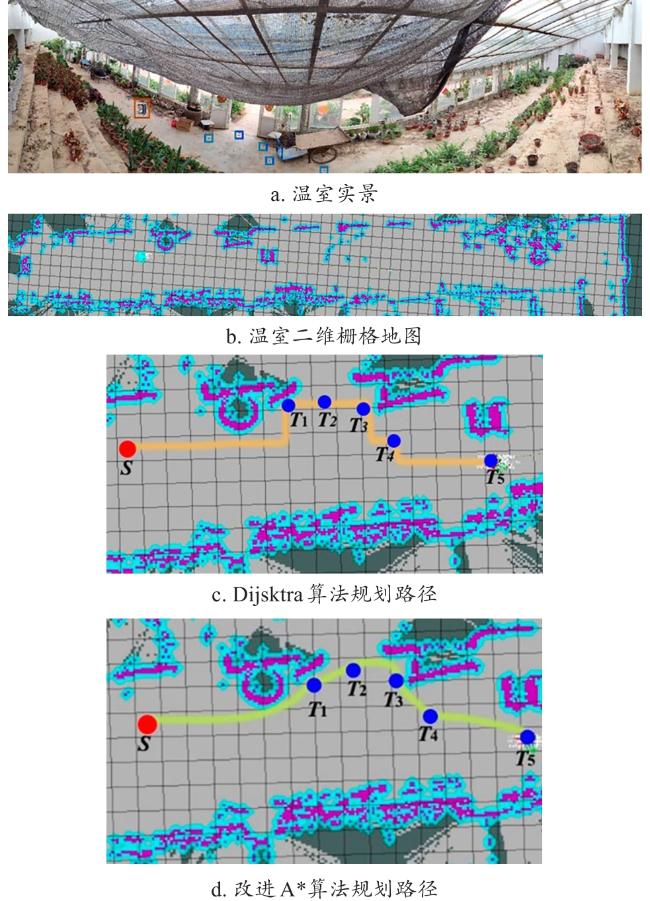
单目标规划只关注一个目标,且路径最短,多采用经典路径规划算法。Dijsktra算法通过逐步扩展最短路径树来寻找起点到所有点的最短路径,是典型的全局最短路径算法[2]。该算法已在任务目标单一、结构简单的设施环境中应用。但通常基于栅格地图实现,需将栅格视为节点,遍历所有可达栅格的最短路径。这使得算法计算复杂度高、内存消耗大,特别在大规模栅格地图中表现不佳,从而限制了其在大面积设施场景中的应用。为了提高算法的灵活性和执行速度,A*算法结合了启发式估计函数和代价函数,使得在搜索过程中能朝目标方向前进。在设施场景中,许多研究者基于A* 及其改进算法进行路径规划。Xu等[84]针对盆栽温室中的路径规划问题,改进传统A*算法,将8邻域扩展到48邻域搜索的同时结合Floyd算法,规划路径的转弯点减少了50%,时间减少了13.53%,距离减少了13.96%,在温室中与Dijsktra算法的规划路径如图4所示。劳彩莲等[85]同样在盆栽温室中结合改进A*算法和动态滑窗算法,改进关键点选取策略并构建最优路径评价函数,最终规划出更平滑、高效的路径。番茄温室移动喷药机器人的路径规划也有类似研究[86]。徐济双等[14]为解决无害处理中心病死动物运输问题,改进A*算法,引入曼哈顿距离法,对启发式函数进行了动态调整,还采用了Bessel函数来优化路径规划,这些改进有效提升了路径规划的效率和精确性。Haotun等[87]提出了改进A*算法的动态路径规划方法,旨在提高饲喂推送机器人在奶牛场中的效率,通过构建网格地图、评估地形成本因子,并根据饲料量动态更新区域成本,机器人能够智能选择最优路径,实验结果验证了该方法能减少运动失控现象并提高饲喂推送效果。
除经典算法外,进化算法在设施环境中的全局路径规划中也有应用。蚁群算法是多点路径规划算法,其分布式协作机制能同时搜索并优化从起点到多个目标点的路径。王红君等[88]提出了一种并行的蚁群算法来解决温室环境中的多点路径规划问题,测试表明该方法可以快速找到距离最短的安全路径。蚁群算法的分布式协作特性不仅能实现多机器人的有效路径规划和协同工作,还提高了效率和路径优化能力。其动态环境的自适应性使其在多机器人场景中能够灵活应对不同情况[89]。然而,蚁群算法可能在设施环境中收敛速度较慢,搜索过程可能受局部最优解影响。此外,算法的参数设置需要针对具体场景做出调整,否则可能会影响路径规划效果。Zhang等[90]以最小能耗为目标,提出了一种基于能耗上限的双交叉算子遗传算法。该算法根据适应度值与能耗上限的关系调整交叉操作,从而在解空间中寻找优化路径。这一方法在家禽智能养殖场的饲喂机器人中进行了验证,显著降低机器人能耗。
单目标路径规划简单易行,专注于优化特定指标,减少计算复杂度和资源消耗。因此,在简单场景中应用单目标算法即可实现规划。然而,单目标路径规划无法考虑环境中的其他因素,需要结合其他算法或策略来解决复杂规划问题。
2.1.2 多目标路径规划
多目标路径规划需要平衡和优化多个目标,如路径最短和转角最小等。RRT算法是经典的规划方法,通过在搜索空间中随机采样并利用最近邻节点与随机采样点间的连线进行扩展,逐步构建从起点到目标点的可行路径。为了实现多目标优化,通常将经典路径规划与优化算法结合使用。丁久阳[91]在原始RRT算法的基础上将最大转角加入了规划目标,把改进RRT与多目标蚁群算法结合实现多目标路径规划。该算法继承了RRT的随机探索和蚁群算法的并行协作特性,使其即使在复杂的设施环境中也能保持规划的高效性。但该算法的稳定性有待提高,容易陷入局部最优。
多目标进化算法是实现多目标路径规划的常用手段,主要包括超体积估计算法[92]、基于网格的多目标进化算法[93]、拐点驱动进化算法[94]和非支配排序遗传算法[95]等。多目标进化算法能灵活应对设施环境中的复杂布局和障碍物,综合考虑多个优化目标,找到均衡且可行的路径方案。Mahmud等[96]针对盆栽温室内的农药喷洒问题,采用非支配排序遗传算法同时优化路径最短和转角最小这两个目标,结果表明,算法能平衡温室内喷药机器人的不同需求。后续还有研究在盆栽温室中测试不同多目标进化算法的性能(图5)。结果表明,超体积估计算法的计算时间稍长但性能最优[97]。Zangina等[98]提出了一种改进的非支配遗传算法用于温室喷药机器人的多目标路径规划,并与原始非支配排序遗传算法进行对比,结果显示改进算法解质量较差,但计算时间显著缩短。虽然多目标进化算法能够有效平衡各目标间的冲突,但对设施环境的实时感知和动态变化处理能力不足,无法充分考虑动植物与障碍的动态变化。Lei等[99]开发了一种多层次导航系统的死鸡拣选机器人,用于在家禽舍内进行病死鸡的自动检测与移除,该机器人使用了一种新的集线器式多目标路径路由方案,专为行列式鸡舍环境设计,考虑了机器人在行进过程中如何最优地访问多个目标点,减少了路径长度和执行时间,提高了任务执行的效率。Li和Zhou[100] 针对大型叠层笼养鸡舍中的巡检任务提出了一种基于拆分法的机器人巡检方案,通过将巡检路段拆分为若干子段,并在每一段应用控制点法优化机器人的运动状态,这种方法考虑了鸡舍建筑参数、传感器响应要求、电池寿命等因素,能够有效应对复杂环境中的干扰问题。

除了上述多目标算法,还有针对特定设施场景设计的路径规划算法。如Yao等[18]提出了OpenPlanner路径规划器,算法在考虑常规碰撞等指标的基础上引入了度量路面平整度和植被密度的成本函数。该规划器在多种复杂温室场景中实现了鲁棒的轨迹规划和状态转换。总体而言,多目标路径规划综合考虑多种因素,通过优化算法和决策模型寻找全局最优解。然而,计算复杂度的增加需要消耗更多时间。同时,考虑各项指标间的权衡关系增加了算法设计和实施的难度。提升算法效率并减少对高性能计算机的依赖是未来的主要研究方向。
2.2 全局遍历路径规划
全局遍历旨在规划覆盖环境中每个可达位置的路径,实现全面探索。这种算法适用于农作物施肥、巡检、采摘,以及动物饲料投喂等任务,能有效减轻作业强度,提高作业效率[101]。全局遍历分为经典算法和基于优化的规划算法。
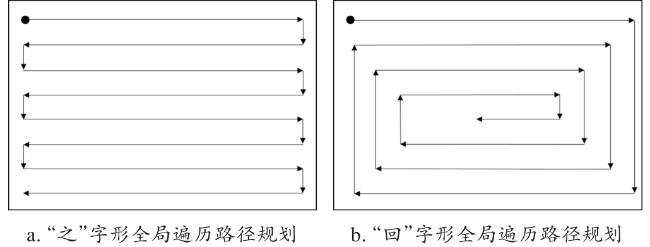
经典全局遍历路径规划算法主要包括“之”字形往复式和“回”字形回行式两种(图6)。往复式路径能够有效覆盖整个设施场景,且易于实现和调整。然而,固定的“之”字形路径可能导致部分区域重复覆盖,每次掉头对设施空间有一定要求。相比之下,回行式全覆盖路径规划算法可以根据设施布局和障碍物位置设计不同形状的路径,减少路径重复,并且路径更加平滑,无需掉头。综合考虑设施环境布局和机器人自主作业要求,往复式路径规划算法在设施环境中更为适用。
由于经典全局遍历规划算法存在灵活性不足、路径重复覆盖等问题,有研究结合传统Dijsktra和A*算法实现单目标全局遍历规划[102]。为实现全局遍历路径生成的自动化,Mazzia等[103]基于深度学习提出一种名为DeepWay的特征学习全卷积模型,该模型可以在占据栅格图中自动生成覆盖作物行的全局路径。在多目标全局遍历路径规划中,有研究改进遗传算法,通过将传统遗传算法的染色体和单点变异扩展为染色体对和多点变异,同时考虑了转弯次数、重复作业面积和能耗等多个目标[104]。Pour等[105]提出了基于树探索的多目标全局遍历路径规划算法,通过相似性检查和最优解选择找到最佳路径,考虑了最大化工作区域,最小化重叠路径、最小化非工作路径长度和行驶时间等多个目标。然而,基于优化算法的全局遍历路径规划通常具有较高的计算复杂度,这会导致实时性下降和延迟响应。此外,一些优化算法对环境信息的准确性和完整性要求较高。Davis等[106]设计了一种混合空中水下机器人系统,用于水产养殖场中的水质监测。该系统结合了无人机和水下测量设备,将提出的路径规划算法与图注意力模型、谷歌线性优化包进行对比,实验结果表明,提出的算法特别适用于大型养殖场。Wang等[107]针对河蟹养殖池塘设计了一种全覆盖轨迹规划方法。基于移动自动喂料船,自动生成反向遍历的喂料轨迹,通过模拟验证,该系统能够满足河蟹池塘自动均匀投喂的要求。Vroegindeweij等[108]设计了用于非均匀重复区域覆盖路径规划的新算法,用于自动化鸡舍地面蛋的收集。该算法基于地面蛋分布概率信息,建立了一个描述鸡蛋潜在分布的空间地图,然后使用动态规划方法规划收集路径,覆盖整个鸡舍地面区域,并频繁访问高潜力的地点。
全局遍历路径规划可以覆盖整个作业区域,提高农业作业的完整性,但在设施场景的应用中面临困难。一方面,复杂多变的设施环境可能导致算法无法充分考虑所有因素,降低路径规划效率和安全性。另一方面,由于设施空间和机器人体积限制,点到点局部路径规划在灵活性和效率上通常优于全局遍历方法。
2.3 小结
设施环境中的智能机器人全局路径规划面临多方面的挑战。第一是实时性。设施机器人需要快速响应环境变化,以确保作业的连续性和有效性,包括快速路径计算和动态环境适应。第二是多目标优化。农业作业具有明确的时间、成本限制和产量目标,机器人路径规划需在路径最短、转角最小、覆盖范围大和重复面积小等多个目标之间取得平衡。第三是环境复杂性。算法需应对复杂的设施农业环境,提高算法在不同设施场景的适应性。第四是作业任务的多样性。机器人需适应不同任务(如巡检、喷洒、采摘、投喂、消毒、运输)的路径规划要求,具备高度灵活性以调整规划策略。这些挑战要求不断改进全局路径规划算法,以提升机器人在设施农业中的应用效果。从应用设施场景角度考虑,点到点局部路径规划主要用于设施种植和设施畜牧。例如,在设施种植中,这种方法常用于自动化播种、施肥等任务,在设施畜牧中则应用于动物喂养和饲料分发。点到点局部路径规划因其计算简单、效率高,适合任务明确、环境相对稳定的场景。在设施渔业中,水下环境的动态性和复杂性使得点到点局部路径规划的适用性降低,因为这种环境需要更复杂的路径调整和实时反馈。全局遍历路径规划则适用于覆盖整个设施环境的任务,如设施种植中的施肥和采摘,设施畜牧中的巡检,而在设施渔业中,也可用于水质监测和喂料。然而,全球遍历路径规划通常计算复杂,适应性和实时性方面存在挑战,特别是在动态环境中。不同场景对路径规划算法的需求不同,因此,在设施种植、设施畜牧和设施渔业中,需要根据具体任务和环境选择合适的路径规划策略。
基于上述挑战,未来的研究方向可以从以下几个方面考虑:首先,针对设施环境特殊性开发特定算法,提升规划算法效率。例如引入启发式思想,采用多层次规划策略和增量式规划方法,以提高规划速度。其次,开发多机器人协作规划算法,研究分布式路径规划和任务分配方法,提升协作效率和作业效果。最后,结合深度学习和强化学习方法,通过大量数据训练,使模型能在不同设施场景和作业任务中自适应地规划路径,将更多复杂因素纳入路径规划目标中,提升算法鲁棒性。
3 自动避障技术
设施农业机器人自动避障技术包括人工势场法、动态窗口法,以及近年来显著增加的深度学习与强化学习方法[113]。这些方法在处理复杂环境中的局部路径规划和避障方面表现出色,能够有效提高机器人操作的效率和安全性。特别是深度学习与强化学习的结合,不仅增强了机器人感知和决策能力,还使其能够自适应环境变化和实时反馈。
3.1 避障决策算法
机器人的自动避障需要能够准确检测障碍物的位置和运动趋势,包括障碍物的静态属性和动态属性,以避免碰撞并保持连续的导航流程。这一挑战要求智能机器人需要具备高度灵敏的传感器系统和先进的算法处理能力,能够快速、准确地感知和应对复杂遮挡的障碍物环境。
3.1.1 人工势场法
人工势场法可用于机器人路径规划和避障,其基本原理是将导航问题转化为虚拟势场中的运动问题。目标位置产生吸引力场,引导机器人;障碍物产生排斥力场,使机器人远离障碍物。机器人在这两个力场的作用下,沿势场梯度下降,最终到达目标。人工势场法具有以下优势:一是实时性强、易于实现,对需频繁移动的农用机器人尤为重要。二是该算法只需计算与障碍物的相对位置,无需复杂的地图构建和路径规划,适合资源有限的农用机器人。三是因受力连续,生成的路径通常较平滑,有助于避免突然方向变化[114]。
目前有研究将人工势场法应用在设施场景中。Tian等[115]针对奶牛场推料机器人提出了一种改进的人工势场法避障策略(图7),该策略通过增加与障碍物的最短距离来优化避障路径,平均时间为0.059 s,标准差为0.007 s。此外,还有研究将人工势场法与粒子群优化算法结合,提出了一种考虑路径预规划和再规划的双层避障路径规划算法,该算法在实现避障控制的同时考虑了温室巡检机器人的稳定性,有效降低机器人侧翻风险[116]。Yang等[117]改进传统人工势场法,通过修改引力场的方向和影响范围、增加虚拟目标和评价函数来解决局部最小值问题,并通过增加重力来解决不可达目标问题。结果表明,改进方法使得设施渔业中的两栖机器鱼能够灵活避障,并准确到达目标点。Zhu等[118]将人工势场法引入双向RRT的启发式函数中,以提高全局路径的扩展效率,并结合全局与局部路径规划解决动态障碍物问题。该算法在静态和动态环境中都能为监测水质及鱼类生物量的水下机器人规划有效路径。
3.1.2 动态窗口法
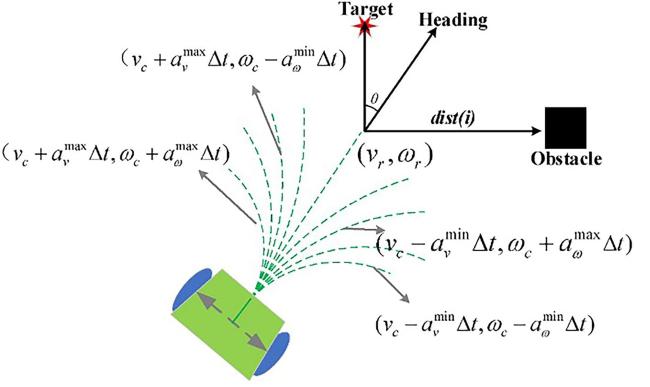
动态窗口法(Dynamic Window Approach, DWA)是一种用于机器人避障和路径规划的在线优化方法,其基本原理是在速度和加速度限制范围内,实时评估并选择最优的运动指令,以避开障碍物并朝目标移动。具体而言,该方法通过在速度空间内搜索可行的速度对,并短时间预测每对速度的轨迹,评估其安全性、可行性和目标导向性[119]。DWA在设施场景中的应用具有诸多优势。第一,其实时性强,能够实时计算最优速度指令,迅速响应环境变化,适合频繁移动和避障的农业机器人。第二,与人工势场法相比,其能避免局部最小值问题。通过在速度空间进行搜索而非位置空间,确保机器人持续向目标移动。此外,DWA灵活性高,能够处理动态障碍物,如移动机械和人,保障安全作业。
在设施环境中,研究通常将DWA与二维激光SLAM算法结合使用。二维激光SLAM算法生成二维栅格地图,而DWA则基于栅格地图进行路径规划。DWA插件已集成至基于ROS的move_base导航包中。Jiang等[2]利用Cartographer算法构建了温室二维栅格地图,并利用DWA实现局部路径规划,最终实现有效避障。此外,还有研究结合了其他优化算法。Wang等[120]提出了一种分布式多移动机器人避障算法,该算法融合了蚁群优化和DWA,通过优先策略协调多机器人系统。结果表明,该算法能够在复杂未知环境中实现高安全性和全局最优的协同避障,为分布式多机器人在设施场景中的应用提供了技术参考(图8)。Zhang等[67]为了提高大规模动物养殖场中检查机器人的检测效率,基于二维栅格地图将A*算法与DWA算法结合。机器人的线性操作误差在0.7%以内,旋转误差在1.1%以内,确保了系统在动物养殖场中的自主导航和避障功能。张金泽等[121]提出了一种改进的双窗口DWA,用于提高无人艇在复杂环境中的避障性能。算法设计了基于船载传感器的感知窗口,进一步优化了由速度窗口和感知窗口组成的双窗口模型。考虑障碍物分布状态和机器人与障碍物之间的距离,提高了路径规划的平滑性和合理性。
3.2 避障感知与决策算法
深度学习是一种基于人工神经网络的机器学习方法,通过构建和训练多层神经网络,从数据中自动提取特征和模式,广泛应用于避障感知与决策。将深度学习用在设施机器人避障控制中有诸多优势。一是,其具备强大的特征提取能力,能够自动从传感器数据中提取复杂的高层次特征,显著提高环境感知和障碍物检测精度,这对于设施农业环境尤为重要。第二,深度学习模型通过大量训练数据自适应地学习不同障碍物的特征和分布,提高了避障策略的泛化能力。
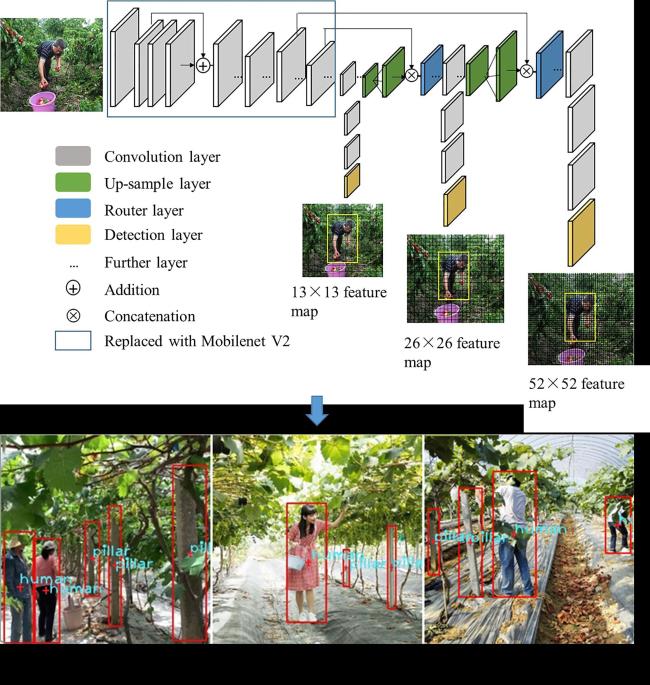
Li等[122]提出了一种基于YOLOv3的轻量化障碍物检测方法,用于精准识别塑料大棚中的典型障碍物。通过引入MobileNetV2网络和高斯模型,重构YOLOv3的损失函数,实验结果表明该方法在检测精度和速度上优于Faster-RCNN、SSD和原始YOLOv3模型(图9)。还有研究将深度学习与强化学习相结合。Yu等[123]构建神经网络模型并将其嵌入到双深度 Q 网络(Deep Q-Network, DQN)架构中,以根据输入状态决定输出动作。同时,定义状态和动作空间,并设计奖励函数以评估和指导模型训练。结果表明,该方法的最短距离、轨迹长度和避障时间的平均值分别为2.37 m、0.53 m和2.7 s。López-Barajas等[124]设计了一种用于鱼场网具检查的水下机器人,通过训练卷积神经网络预测网具与机器人之间的距离,还开发了物体检测算法以识别网具上的孔洞,实验结果表明该平台在网具孔洞检测、距离估计和检查轨迹方面表现出色。
3.3 小结
人工势场法在设施场景中的自动避障应用中具备优势,但也有其局限性。人工势场法易陷入局部最小值,即吸引力和排斥力平衡的位置,这可能导致机器人被困在障碍物之间。为提高其实际应用效果,通常需结合其他算法,如引入随机扰动以避免局部最小值,或结合图搜索算法以提供全局路径规划指导。这种结合能充分发挥人工势场法的实时性,同时克服其固有缺陷。在设施场景方面,人工势场法能够用于设施种植、设施畜牧和设施渔业。设施种植中,人工势场法可用于自动化施肥、除草等任务,而在设施畜牧中,常用于动物喂养和饲料分发。设施渔业中适用于水下机器人的路径规划和避障,尤其是在复杂的水下环境中进行网具检查、鱼群监测等任务。人工势场法能够处理动态障碍物,但需要特别考虑水下传感器的适应性。
DWA也面临一些限制。由于需要在每个控制周期内进行大量轨迹预测和评估,其计算复杂度较高,不利于资源有限的农用机器人。此外,依赖局部规划视野可能导致远距离规划不足,因此需与其他优化算法结合使用以确保路径合理性。最后,DWA的性能高度依赖参数设置,需要根据具体场景进行优化调整,否则可能影响避障效果。DWA能够用于设施种植、设施畜牧和设施渔业的水面环境。在设施种植中,DWA结合激光SLAM算法,适用于机器人执行自动化巡检、喷药等。DWA能够实时响应环境变化,适应温室中快速变化的情况。设施畜牧中适用于自动推料、清扫、检查等任务。DWA可以有效处理动态障碍物。设施渔业中,DWA能够应用于水面无人船,实现渔场的自动化喂食和水质监测。在水下环境中,其面对动态障碍物(如移动鱼群)时可能存在挑战。特别是水下传感器的数据质量和模型决策准确性对于有效避障至关重要。
深度学习算法在设施种植和设施畜牧中应用时能够有效地提升环境感知和障碍物检测的精度,目前主要用于植物识别、动物跟踪和复杂环境中的感知与避障。在设施渔业中也有应用,且能够面对更加复杂的水下环境,用于设施环境避障感知与决策时,也面临一些挑战。首先是对数据的需求量大,训练模型通常需要大量标注数据,尤其是对于多样化的障碍物和环境变化,需要大量数据来保证模型的泛化能力。而在设施农业中,高质量标注数据的获取耗时费力。其次,深度学习训练需要大量计算资源,且实时避障处理需要高效的硬件支持,增加了系统复杂性和成本,这在资源受限的机器人上表现不佳。最后,深度学习模型缺乏解释性,其决策过程难以解释,在设施农业中如果避障决策出现错误,难以追踪和修正,可能增加作业风险。应用在设施渔业中时,水下视觉模糊和动态水流是要克服的挑战。总之,深度学习在设施农业的自动避障中展示了强大潜力。为了充分发挥其优势,需要根据实际避障需求优化数据积累和硬件配置,并结合传统路径规划算法等其他方法,以提高系统的鲁棒性和适应性。
基于上述挑战,未来研究可从以下方面考虑:首先,改进传统避障控制算法。例如动态调整势场参数,增加动态扰动或启发式搜索策略。优化DWA的速度选择策略,结合优化算法来减轻局部规划视野带来的限制,实现更加合理的路径规划。其次,减少数据需求。采用数据增强技术和迁移学习方法,以减少对大量标注数据的依赖。还可以探索无监督学习和半监督学习策略,以便在缺乏高质量数据的情况下提升模型性能。同时,开发适用于资源受限环境的轻量化深度学习模型或边缘计算模型,如移动端神经网络,以减少计算资源需求。最后,建立设施避障技术的标准化测试平台和开放数据集,促进研究人员和企业间的合作,加速技术进步和应用推广。
4 存在的挑战与展望
4.1 存在的挑战
在设施农业中实现智能机器人的自动导航,需要克服环境复杂性、可通行空间狭小、算力与成本限制、缺乏标准化平台与公开数据集以及场景多样化等多方面困难。这些挑战需要行业内各方的跨学科合作与持续创新,以推动智能农业技术的应用与发展。
4.1.1 设施农业环境场景复杂,遮挡严重
设施农业是涵盖设施种植、设施畜牧、设施渔业的农业生产系统,障碍物种类繁多且相互遮挡给对智能机器人的自动导航带来了构成挑战。在设施农业环境中,当机器人受到障碍物遮挡时,可能导致传感器无法完全捕获周围环境全面捕获环境信息,不准确的环境信息会导致定位精度下降和地图构建得不完整。全局路径规划在面对多样化的障碍物布局时,需要能够有效规避遮挡情况,确保选择安全且高效的导航路径以确保导航路径的安全高效。遮挡引起的全局地图不准确也会影响路径规划不准确。
设施种植包括日光温室、连栋温室和塑料大棚等。该环境通常较稳定,主要关注土壤、作物和固定设施中的静态障碍物。在此环境中,精准定位和路径规划是自动导航的关键。信标定位、惯性定位和基于SLAM的定位都在设施种植中广泛应用,但环境复杂性和遮挡问题仍是挑战。多目标路径规划是设施种植的常用算法,特别考虑路径长度、土壤条件和机器人转角等因素。
设施畜牧包含蛋鸡养殖、生猪养殖等。相比之下,设施畜牧环境中的动态因素更为复杂,这对定位系统的动态适应性要求更高。在此环境中,结合信标和惯性定位的技术可以提供更稳定的定位解决方案,但仍需处理动物活动对信号的干扰。路径规划方面,局部路径规划方法如时间弹性带和模型控制预测被广泛应用。这些方法能在动态环境中进行局部优化,避免重新计算全局路径。在自主避障方面,DWA和人工势场法对参数的敏感性和局部最优问题仍需改进。相对而言,强化深度学习技术展现了显著的优势,能够有效应对动态障碍物的挑战。
设施渔业分为水上、水面和水下场景。其中,水下环境对导航技术提出了更高要求。在水下环境中,声呐定位应用广泛。声呐定位提供实时距离信息,但其精度受水流、温度和盐度影响。避障控制方面,模糊控制和强化学习技术是主要应用策略。模糊控制能灵活应对水下障碍物变化,但需经验丰富的规则设计;强化学习则通过智能体自主学习和优化,适应动态和复杂环境,提供高效的避障策略。
4.1.2 设施农业机器人的成本限制
设施农业自动导航面临成本限制的挑战。较低精度的传感器可能降低导航准确性,影响机器人安全和操作效率。算力限制会影响自动导航系统的实时性和响应速度。智能机器人需要处理大量传感器数据并进行实时决策,例如自主定位、地图构建和路径规划。尤其是在设施环境中,算力不足可能导致定位误差累积和地图更新频率降低。因此,机器人系统需要在算法效率和资源利用率之间找到平衡。此外,机器人平台需要具备稳定的机械结构、耐用的电动系统和精准的运动控制能力。然而,高性能的导航平台通常伴随着更高的制造和维护成本。因此,在确保长期稳定性和可靠性的同时,平衡性能与成本是关键。农业生产中,经济效益常是关键考量,高昂的成本可能限制了相关从业人员采用先进的自动导航系统。此外,维护和更新这些系统也需要额外的成本投入,长远来看,这可能使技术的实施和运营成本过高,难以匹配农业生产的经济模型。因此,克服成本挑战是实现设施农业中智能机器人自动导航的关键。
4.1.3 设施农业机器人作业效率低
在设施农业中,单一机器人的作业效率低。这种低效率主要体现在多个方面,包括任务完成速度慢、能源消耗高,以及作业精度不足。首先,许多现有的机器人系统在处理复杂作业任务时,整体作业速度较慢。例如,在巡检、消毒、采摘和喂食等任务中,机器人往往需要较长时间才能完成预定工作,这影响了农业生产的整体效率。其次,机器人在设施环境中的能源消耗较大,尤其是在长时间运行时,这不仅增加了操作成本,也可能影响机器人的持续作业能力。此外,机器人在各种不同的设施环境中作业精度不足也是导致低效率的重要因素。由于环境的动态变化和障碍物的干扰,现有的机器人系统可能无法准确执行预定任务,需要进行多次调整和修正。自动导航算法的鲁棒性不足是导致这种情况的主要因素,这时机器人需要频繁地进行状态监测和调整,但又导致作业进度延缓。
4.1.4 缺乏标准化平台与公开数据集问题
缺乏标准化平台与公开数据集对设施农业智能机器人的自动导航技术构成重大挑战。首先,标准化平台的缺失使得不同厂商和研究团队开发的系统难以兼容。这种情况下,集成不同技术和算法变得复杂,限制了系统的灵活性和互操作性,增加了开发和维护的成本。其次,缺乏公开数据集阻碍了导航算法的开发和优化。有效的自主定位与地图构建、全局路径规划,以及自动避障技术的开发需要大量真实场景的数据支持,这些数据不仅有助于算法的训练和验证,还能够提高算法的鲁棒性和适应性。缺乏公开数据集意味着开发者和研究人员难以获取到足够多样和复杂的场景数据,限制了技术的进步和应用范围。因此,解决缺乏标准化平台与公开数据集的问题对于推动设施农业智能机器人的自动导航技术至关重要。
4.2 展望
随着农业技术的进步和设施农业的普及,智能机器人在农业生产中的应用已成为未来的重要趋势。然而,要实现设施农业中智能机器人的高效自动导航,仍面临多方面挑战。未来研究应以技术创新和跨学科合作为核心,通过多传感器融合技术、先进算法优化、多机器人协同作业和数据标准化与共享平台的建设,来解决这些挑战。这些努力将推动智能农业技术的发展,为农业生产的可持续发展提供新的解决方案和机会。本节将探讨如何通过未来的研究方向和技术创新来应对挑战,推动智能农业机器人导航技术的进步和应用。
4.2.1 开发多传感器融合技术
未来研究应重点发展多传感器融合技术,以提升智能机器人在复杂农业环境中导航的精度和鲁棒性。传统农业机器人通常依赖单一传感器,但在动态、遮挡等复杂情况下可能受限。通过融合多种传感器,能综合不同传感器优势,提升环境感知的全面性和精准性。例如,视觉与激光雷达传感器的融合定位和地图构建可以有效解决纹理或几何信息不足导致的退化,从而应对设施农业中结构高度重复和光照变化大的挑战。未来研究还可探索新型传感器技术,提高在不同环境条件下的感知能力。此外,应用人工智能技术,如深度学习和机器学习算法,能实现智能数据融合和环境模式实时识别,从而更精确地反映设施农业环境的动态变化。
多传感器融合技术的发展将显著提高智能机器人对环境的感知和理解能力,增强自主定位与地图构建的精度,并实现更安全、高效的全局路径规划和自动避障。此外,该技术支持机器人在复杂环境中的实时决策和适应,进而提升设施农业生产的效率和可持续性。
4.2.2 应用与优化先进算法
未来研究应持续推动先进算法在农业机器人自动导航中的应用和优化。自主定位和地图构建的应用,需要针对设施环境的特殊性进行优化。例如在渔业设施中,应用视觉SLAM算法能够在水下环境实现高精度建图与定位。充分利用先进算法的优势,提升机器人在设施农业环境中的导航精度和效率,实现精准农业管理和资源优化。
传统的路径规划和避障算法常依赖于静态地图和预设规则,难以适应环境的动态变化。因此,发展基于深度学习和强化学习的自适应路径规划算法至关重要。这些算法通过分析大量实时数据和环境反馈,学习和优化机器人的行为策略,从而在动态环境中快速调整路径和避障方案。例如,利用深度学习进行环境建模和预测,结合强化学习进行路径规划和决策,将使机器人在复杂的农业设施中实现更智能、更高效的导航操作。
4.2.3 研究与实现多机器人协同作业
随着农业规模的扩大和作业复杂性的增加,单一机器人的效率存在局限性。因此,未来研究应重点关注多机器人协同作业技术的发展。多机器人系统通过协同工作和任务分工,提升农业生产的整体效率和灵活性,减轻单个机器人在繁忙时段的工作负荷,扩大作业范围。例如,研究多机器人之间的通信协议和路径规划算法,以实现任务分配和协调,避免冲突和资源浪费。此外,多机器人协同作业通过数据共享和集成,提高系统的智能化水平,使农业机器人能够更好地适应不同作业需求和环境条件。通过分布式传感和集成控制系统,多机器人系统还能实现对大规模农业设施的全面监控和管理。这种集成和协同作业的方式不仅能提升农业生产效率和生产力,还能减少资源浪费和环境影响。
4.2.4 建设数据标准化与共享平台
建立开放的平台标准和共享数据资源,将有助于促进技术的创新和进步,推动智能机器人在农业领域的广泛应用和可持续发展。未来研究应致力于建立统一的数据标准和共享平台,包括开发通用的数据格式和接口标准,促进不同设备和系统之间的数据互操作性和共享,加速智能农业机器人技术的应用和推广。同时,建立开放的数据共享平台,提供涵盖不同地理位置、作物类型和生长阶段的设施场景数据集,以支持算法的开发、验证和优化。数据标准化和共享将加速算法训练和优化过程,推动智能农业机器人导航技术的广泛应用。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}