



0 引 言
“三北”防护林工程历时46年建设,已有效遏制了西北、华北、东北地区自然生态系统的持续恶化,显著缓解了风沙危害和水土流失,对全球生态修复与保护作出了巨大贡献。然而,随着植树造林规模的不断扩大,植树位点(树坑)作为造林关键环节,其数量统计与质量评估逐渐成为一项复杂且耗时的任务。当前,“三北”地区上万亩植树造林的植树位点(树坑)采用挖掘机作业,数万甚至数十万个树坑常常需要人工标记和现场勘查。这种传统方法费时且劳动强度大,存在错报或漏报情况,难以满足大规模植树项目的管理和质量控制需求[1]。因此,迫切需要一种高效、精准的植树位点检测技术,以适应植树任务逐渐规模化和科学化的发展要求。
植树位点在无人机航拍的图幅中占比小,是一种小目标的检测对象。在目标检测领域,小目标识别已成为一个备受关注的研究领域。李妹燕等[7]提出了一种多模态特征融合策略,通过标记优化分水岭算法实现高光谱图像的粗粒度分割,结合改进型KNN分类器(K-Nearest Neighbors)开展目标区域的精细识别,有效解决了光谱混叠带来的检测模糊性问题。林晓林与孙俊[8]开发的基于决策树DT(Decision Tree)的检测追踪框架展现出显著的环境适应性,在天空背景数据集中达到较高追踪准确率,对地面均匀背景的适应性测试也显示其在光照突变场景中仍保持轨迹连续性。但这些方法在面对复杂场景和高噪声环境时,其性能往往表现出局限性。因此,越来越多的研究开始转向深度学习技术作为解决方案。叶昕怡等[9]提出了一种自适应对比度增强的红外检测算法,通过构建注意力-卷积混合架构实现检测性能的动态平衡。算法通过自注意力分支增强目标全局特征,卷积分支优化空间连续性约束,从而在复杂场景中有效协调检测精度与召回率。深度学习在林木小目标检测中的应用仍相对较少。尽管彭小丹等[10]利用无人机图像和改进LSC-CNN(Locally Sensitive Convolutional Neural Network)模型实现了密集种植苗木的检测和计数。但林两魁等[11]研究发现,深度学习方法在处理高密度目标环境时仍面临挑战。
基于此,本研究结合无人机遥感技术和深度学习,提出了一种复杂背景下的小目标检测模型——YOLOv10-MHSA(You Only Look Once Version 10-Multi-Head Self-Attention),旨在解决“三北”工程内蒙古地区植树位点(树坑)小目标检测的问题。该模型在YOLOv10框架基础上,引入了以下改进:1)增加了小目标检测层,通过增设多尺度检测支路与双向特征交互融合模块,有效解决了小目标特征稀疏性问题,同时增强了特征表达的完整性,能够更加精确地检测无人机图像中小尺寸的植树位点(树坑),降低漏检、误检问题;2)将传统的卷积层替换为可改变卷积层(AKConv),通过引入可变内核机制来提高特征提取的灵活性和适应性。进一步提升模型特征提取的性能和计算效率;3)引入多头自注意力机制,强化特征图的全局和局部信息表达,从而提高模型对复杂背景的适应性;4)优化损失函数,采用改进的Focal-EIOU Loss(Focal Efficient Intersection over Union Loss),提高小目标检测的精度和召回率。
该模型聚焦于“三北”工程内蒙古地区植树位点(树坑)在复杂背景下的小目标检测优化,有效减少和避免了错检漏检问题,以期为中国“三北”工程科学化植树造林提供新思路与方法支持。
1 材料与方法
1.1 研究区介绍
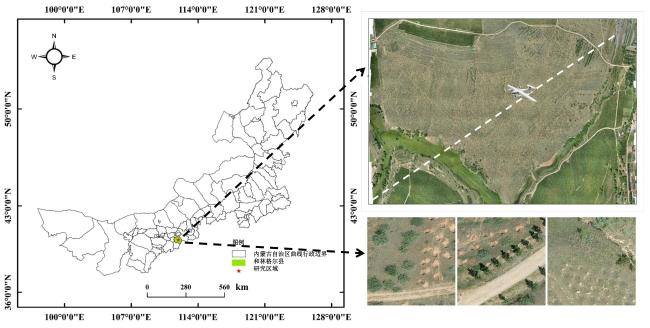
本研究所划定的实验区域涵盖内蒙古中部典型农牧交错带,具体行政区域为呼和浩特市下辖和林格尔县新红村片区,地理坐标位于39°58'~40°41'N,111°26'~112°18'E(图1)。该县总土地面积为3 436.47 km2,丘陵山区占总面积的78%,是中国“三北”工程防护林建设的重要县区。实验区域呈现构造山地、侵蚀丘陵与冲积平原交错分布的立体空间格局,其三级地貌单元共存的特征为研究多尺度地形效应提供了典型地理样本,植树位点(树坑)计数时,传统的人工现场勘察时工作量大、效率低,且容易出错,低空无人机是解决上述难题的最佳选择。
1.2 植树位点图像采集
本研究利用长续航多用途垂直起降固定翼无人机(北京安洲科技有限公司)采集植树位点(树坑)图像。机载相机像素2 600万,空间分辨率高,常用于野外高精度测绘。100~200 m飞行高度下,空载航时达2~3 h,续航里程高达180 km,可拍摄研究区上千公顷面积的植树位点(树坑)图像。无人机航拍于2024年8月1日11∶00—12∶00执行,天气晴朗,风力3级,飞行高度设置为150 m(地面分辨率约为2.56 cm),相机拍照模式为等距间隔拍照,航摄采集采用纵向75%与横向65%的重叠率配置,飞行平台巡航速度控制在20 m/s。图像采集完成后,使用Metashape软件(v2.1.0)对航拍图片进行拼接,生成约1 293 600 m2(880 m×1 470 m)植树位点的数字正射影像图(Digital Orthophoto Map, DOM)。为便于后续研究分析,对图像数据进行预处理,采用640像素的滑动窗口对拼接后的图像进行裁剪,裁剪后图像像素大小为640×640,共获得3 102幅高清RGB图像。
1.3 植树位点数据集扩充及划分
为缓解训练过程中的过拟合风险,研究采用空间-频谱双域增强策略:几何扰动模块实施镜像翻转、任意角度旋转及区域裁剪[12],图像混叠模块集成Mosaic拼接与Mixup合成,在不增加数据规模的前提下显著提升了检测模型的泛化性能。最终,数据集经扩充后共得到6 204幅植树位点(树坑)图像,然后原始数据集经分层抽样处理后,形成训练集(4 343张)、测试集(1 241张)与验证集(620张)7∶2∶1的三元架构,样本配比确保了各子集在目标尺度分布与背景复杂度上的统计一致性。同步采用开源标注平台Labelme对植树位点(树坑)开展标注工作,将构建的数据集应用于模型训练及验证。
1.4 YOLOv10-MHSA检测模型
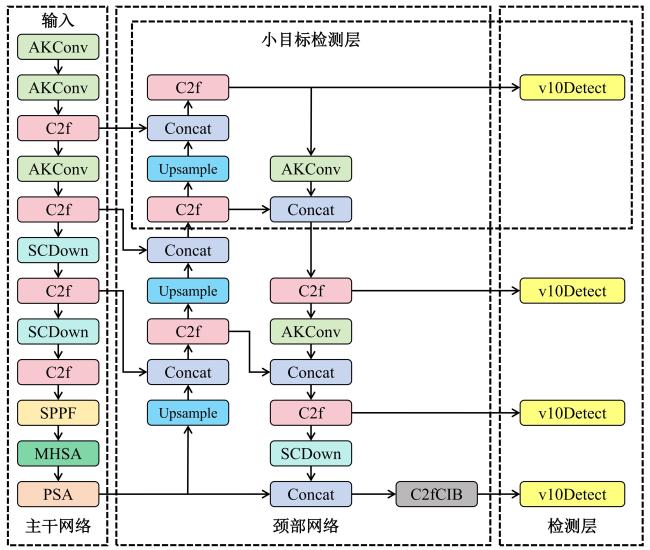
为利用无人机高精度、快速识别“三北”工程内蒙古地区植树位点(树坑),解决遥感图像中微小目标易湮没与多源背景干扰导致的检测精度衰减等问题,本研究针对性设计了YOLOv10-MHSA检测模型,网络结构如图2所示。具体包括小目标检测层添加、可改变卷积层特征提取、多头自注意力机制引入和损失函数优化四部分。
1.4.1 小目标检测层
YOLOv10架构采用多级非对称特征解耦设计,通过构建20×20、40×40及80×80像素的多尺度特征金字塔,实现目标尺度-感知域动态匹配。其中,高分辨率特征映射(80×80像素)对应局部感受域(32×32像素),专注微小目标边界定位;低分辨率特征响应(20×20像素)则扩展至全局感受域(512×512像素),强化大目标的语义表征能力[13]。YOLOv10的特征金字塔最高分辨率为80×80像素,对应8×8像素的局部感知域,导致目标检测下限被锁定在80×80像素。这种高降维倍率的空间压缩策略,可能引发高频特征湮没效应,造成微小目标的边界细节丢失[14],使得深层特征图难以有效捕捉小目标。本研究中植树位点通常在整幅航拍图像中占据较少比例,平均像素占原图总像素的0.592%,传统的检测层难以捕捉这些小目标的特征。因此,YOLOv10在小目标检测时需要进行针对性改进。
如图2所示,改进架构在P2特征传播路径中设置高维特征输出节点,构建160×160像素分辨率的检测支路。通过并行检测头与双向融合层的协同设计,在主干网络中形成浅层特征输出通道,有效提升了小目标检测的特征保真度与边界解析能力。具体而言,特征融合架构采用两阶段交互机制:第一阶段将P5层80×80特征与上采样支路进行跨模态融合,经C2f模块生成深层语义增强特征;第二阶段通过与P3层空间特征的级联处理,构建160×160像素分辨率的融合特征层,同步提升小目标的语义判别性与边界定位精度。最后,这些特征经过C2f处理后,传递至Head中的额外解耦头(Decoupled Head)。解耦检测头架构通过跨层路由机制,将C2f模块输出的深层特征沿下采样路径反向补偿至20×20、40×40及80×80像素三个特征层,形成多尺度特征空间的正交传播通道,有效提升了小目标检测的语义-空间联合判别能力。
检测头架构通过集成辅助解耦支路,实现了深层特征向低分辨率层的跨尺度传播,可以扩大植树位点(树坑)的检测范围和检测精度[15]。该改进在无人机图像中增强了对小尺寸植树位点(树坑)的上下文感知能力,通过多尺度特征交互机制有效抑制了复杂背景下的误检与漏检现象。虽然改进架构相较基础网络引入了额外的计算负载,但这一改进显著增强了模型对小目标特征的捕捉能力,从而大幅提升了其在和林格尔县植树位点数据集中检测小目标的能力。
1.4.2 基于可改变卷积层的特征提取
YOLOv10网络中卷积层(Conv)是特征提取的核心组件。为了进一步提升模型的性能,本研究提出将传统的卷积层替换为可改变卷积层AKConv,它是一种新型的卷积操作,通过引入可变内核机制来提高特征提取的灵活性和适应性[16]。不同于传统的卷积操作,可改变卷积层不固定使用一个预定义的卷积核,而是通过一个可调整的内核生成网络来动态生成适应输入特征图的特征卷积核,具体结构见图3。此过程中,AKConv不仅仅关注卷积核在输入特征图上滑动的常规模式,还会根据输入特征图的内容和背景的复杂性动态调整卷积核的权重,通过在卷积计算过程中引入自适应采样偏移量,实现了特征提取的针对性增强,从而提升模型对目标显著区域的解析能力。
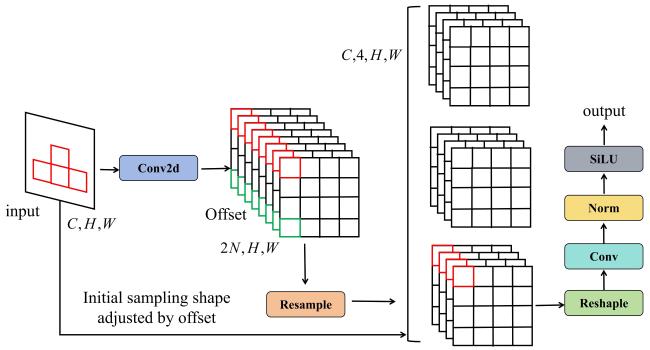
本研究改进的YOLOv10网络中,传统的卷积层被AKConv层所替代。传统的固定尺寸卷积核在处理不同尺度和形状的目标时效果有限。AKConv能够根据目标的自适应调整,使得模型在处理植树位点(树坑)这类不规则形状或不同大小的目标时更具灵活性和鲁棒性。这种替换在网络的每一个卷积层中进行,包括但不限于主干与颈部网络中的所有卷积层。
AKConv通过1个小型的生成网络动态生成卷积核。这个生成网络根据输入特征图的上下文信息生成多个不同的卷积核。生成的卷积核反映了特征图中各区域的重要性,能够根据每个位置的特征分布进行调整,从而增强关键特征的表达。假设使用的卷积核尺寸为3×3,经过调整后的卷积核会对输入特征图进行加权卷积操作。具体地,通过将生成的卷积核应用于输入特征图,AKConv生成的输出特征图能够更加准确地捕捉输入特征图中的重要信息。这种方法确保了特征提取的灵活性和适应性,从而提高了模型的精度。
AKConv的引入显著提升了模型的性能。在标准数据集上,使用AKConv的YOLOv10相较于传统卷积方法,在处理小目标和复杂背景的任务中表现更为突出,且通过动态调整卷积核,模型能够更有效地捕捉不同形状植树位点(树坑)的特征,提高目标检测精度。
1.4.3 多头自注意力机制
由于研究区包括丘陵和洼地、灌木与杂草、裸土沙地等多变的地形与地物,这些复杂背景可能导致植树位点(树坑)的精准识别模型检测效率降低[19]。为解决这一问题,引入多头自注意力机制可以帮助模型更好地关注图像中植树位点(树坑)信息,同时抑制无关的背景特征,从而在复杂背景下实现更好的小目标检测效果。
在YOLOv10网络中,主干网络与Neck层之间的连接不仅在特征提取和融合过程中发挥着重要作用,而且直接决定了模型在多尺度特征处理中的能力[20]。为突破YOLOv10对小目标特征表达的局限性,本研究在SPPF(Spatial Pyramid Pooling Fusion)与PSA(Pyramid Squeeze Attention)模块间构建多头自注意力(Multi-Head Self-Attention, MHSA)特征增强层,通过多头注意力机制实现跨尺度特征的非局部建模与信息补偿,形成具有全局感知能力的改进架构。这一位置的选择是基于MHSA模块在特征提取阶段优化全局信息表示的能力。MHSA模块通过多头自注意力机制,能够在特征图的不同位置之间建立有效的联系,捕捉全局和局部信息的复杂关系,从而增强特征的表达力和区分度[21]。在SPPF之后加入MHSA模块,确保特征在经过空间金字塔池化的初步处理后,模型能够对重要信息进行加权处理[22],优化主干网络对复杂背景和小目标的捕捉能力。
如图4所示,MHSA模块通过PatchEmbed嵌片编码单元将原始特征 映射转换为线性序列输入 ,其中原始特征图的分辨率为 , 为通道数, 为每个图像块的尺寸,而 为图像块数量,对应MHSA模块的输入序列有效长度。该模块位于网络主干结构的底层层级,针对输入特征图(80,80)的分辨率特性,本研究将图像块尺寸设为(2,2),最终生成1 600个嵌片向量。为保留空间拓扑信息,特征序列注入位置编码后,经多头线性变换生成查询、键、值矩阵—— 、 和 ,采用线性映射方法将特征矩阵h次分别投影至 、 和 维度以实现多头注意力机制的并行运算,计算方法如公式(1) 所示。
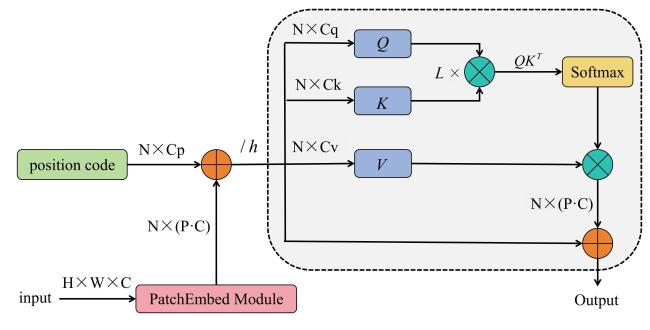
本研究中MHSA采用8头并行架构,各注意力头共享 = = = =256维特征通道配置,通过多路径线性投影实现了特征空间的非局部建模。
通过捕捉全局信息,MHSA可以减少模型对植树位点(树坑)的漏检和误检。自注意力机制通过建模特征间的全局依赖关系,使模型具备对关键区域的动态感知能力,减少背景噪声的干扰,使得模型在处理不同场景和光照条件下的植树位点(树坑)时更具鲁棒性。
1.4.4 损失函数优化
在YOLO模型中,损失函数是多任务损失(Multi-Task Loss),它同时考虑了对象的定位和分类两个任务,这意味着损失函数不仅需要衡量预测边界框与真实边界框之间的差异,还需要衡量预测类别概率与真实类别概率之间的差异。回归损失函数的结构如图5所示,YOLOv10采用CIOU Loss用于计算边界框的重叠损失。CIOU Loss在处理纵横比时虽然有一定优势,但在描述相对值方面存在模糊,并且未能有效解决数据集中样本的不平衡问题[23]。值得注意的是,在梯度反向传播过程中,CIOU损失函数对锚框与目标边界框的空间嵌套关系建模存在计算误差,这可能导致优化过程中的梯度扰动[24],可能导致检测性能受到影响。
由于植树位点(树坑)是无人机图像中的小目标,传统的损失函数对小目标的权重不够高,导致模型很难平衡检测精度和召回率。为解决该问题,本研究将CIOU Loss替换为Focal-EIOU Loss。Focal-EIOU Loss是一种改进的边界框回归损失函数,旨在提升目标检测模型的精度和收敛速度[25]。其损失函数框架融合焦点损失(Focal Loss)与改进型边界框回归损失(EIOU Loss),其中EIOU Loss是在CIOU Loss基础上引入三重惩罚项构建的增强型目标定位损失,以解决传统回归损失函数在处理复杂场景中的不足。
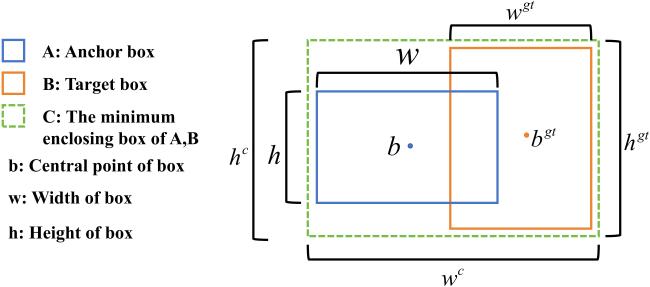
测量两个任意形状(体积)之间相似性的IOU损失L IOU如公式(2) 所示,其中,A为Anchor box,B为Target box。
L IOU具有非负性、对称性、三角形不等式和尺度不敏感性等良好的性质,已被证明是一个度量标准。然而,它有两个主要的缺点:如果两个box没有任何交集,IOU将始终为零,这不能正确反映这两个box之间的紧密程度[26]。且IOU Loss的收敛速度较慢。为了解决上述问题,本研究引入了一个更有效的IOU损失函数,即EIOU损失L EIOU,其定义如公式(3) 所示。
式中: 和 分别表示两个检测框的最小外接矩形的宽高参数。EIOU损失函数包含三要素:交并比优化、中心距约束及宽高差异建模。通过联合最小化目标框与Anchor的尺度偏差,该方法加速了模型收敛并优化了边界框回归精度。
在实际模型训练过程中,存在样本分布不均衡现象。由于目标物在图像中的低密度分布,优质预测样本(低误差)数量显著低于离群样本,这种比例失调可能影响模型优化方向。最新研究表明,离群值会产生过大的梯度,对训练过程有损害[27]。基于上述缺陷,定位回归机制中优先优化高置信度锚框的参数估计对目标检测性能提升具有重要意义,本研究引入新的损失函数,即Focal-EIOU损失L Focal-EIOU,如公式(4) 所示。
式中: 为控制异常值抑制程度的参数,经过训练过程中的参数优化,最终确定为0.5。
复合损失函数Focal-EIOU通过双路径优化策略:Focal-Loss动态压缩离群样本的梯度主导权,EIOU Loss构建宽高联合约束,共同缓解边界框回归中的样本分布偏态与尺度差异问题。改进的损失函数帮助模型减少了对植树位点(树坑)的漏检,同时减少了误检,提高了整体检测性能。
1.4.5 模型评价指标
模型评估体系包含精确率(P)、召回率(R)、平均精度(AP)及帧率(FPS)。P与R的权衡性通过AP联合量化,其中AP@0.5为IOU阈值为0.5时的检测精度,AP@0.5:0.95则是0.05步长下IOU阈值序列的精度均值。FPS作为计算效率指标,直接体现算法的实时检测能力。各指标的计算方法如公式(5)~公式(7) 所示。
式中:P反映正类判别中的真阳性占比,即模型对植树位点(树坑)的阳性识别中,实际目标样本与总预测的比率。R表征阳性识别对基准正样本的覆盖度,模型输出的真阳性样本占数据集中实际目标的比率。真正例(TP)指实际正类样本被准确判定的统计数值,假正例(FP)表示实际负类样本被错误归类为阳性类别的计数结果,假反例(FN)代表实际正类样本未能被识别而遗漏的数目。
2 结果与讨论
2.1 实验设置
实验平台采用Intel i7-9750H处理器(2.60 GHz)与NVIDIA RTX 1660Ti显卡(6 GB显存),系统内存配置为16 GB DDR4。软件环境部署于64位Windows 10系统,基于Python 3.9语言与CUDA 10.2加速库,在PyTorch 1.10.1框架中完成模型训练任务。
实验参数配置如下:训练阶段图像输入尺寸(Image_Size)设定为640×640像素,基础学习率(Learning_Rate)初始化为0.01,模型采用随机初始化策略,批量大小(Batch_size)配置为16,训练周期(Epochs)设定为200次。在帧率评估环节,保持图像空间维度为640×640,批量处理单元配置为16。
2.2 不同YOLOv10基准模型对比实验
YOLOv10包含n、s、m、b、l、x六种不同大小的模型,通过深度与宽度的协同缩放策略,在检测精度、推理延迟及资源占用维度形成差异化特性,为边缘计算、嵌入式部署等场景提供多梯度优化范式。其中,YOLOv10l为大型版本,精度更高,但计算资源增加;YOLOv10x为超大型版本,可实现最高精度和性能。YOLOv10x与YOLOv10l因参数冗余与推理延迟过高,无法满足无人机边缘计算的轻量化部署需求。因此本研究对YOLOv10n至YOLOv10b四类架构进行网络层级、通道维度、检测指标及参数规模的多维分析(表1),评估其在资源受限场景的适配性。
表1 YOLOv10模型检测植树位点实验结果Table 1 Dectection results of tree planting locations based on YOLOv10 models |
| 模型名称 | 网络深度 | 网络宽度 | AP@0.5 | AP@0.5:0.95 | P/% | R/% | 参数量/M |
|---|---|---|---|---|---|---|---|
| YOLOv10n | 0.33 | 0.25 | 0.921 | 0.761 | 0.923 | 0.876 | 5.3 |
| YOLOv10s | 0.33 | 0.50 | 0.933 | 0.796 | 0.938 | 0.881 | 11.2 |
| YOLOv10m | 0.67 | 0.75 | 0.939 | 0.846 | 0.947 | 0.886 | 31.3 |
| YOLOv10b | 1.00 | 1.00 | 0.951 | 0.854 | 0.956 | 0.894 | 56.8 |
表1实验数据表明,网络层级深度与通道宽度的扩展显著提升了检测精度(AP@0.5从0.921至0.951),但模型参数量同步增加至56.8 MB)。YOLOv10n作为最小参数规模的轻量化架构,其AP@0.5达到0.921,虽低于YOLOv10b的0.951,但参数量仅为后者的1/10。YOLOv10b的参数膨胀导致推理时间增加,难以满足无人机边缘计算的实时性约束。因此,综合参数量、检测精度与改进可行性,本研究选择YOLOv10n作为基线模型:其轻量化特性适配嵌入式部署,且通过架构改进(如特征补偿与多尺度增强)可进一步优化检测性能,从而在资源受限场景下实现高精度与高效率的平衡。
基于YOLOv10n架构的检测结果可视化如图6所示。本研究经大量测试验证,当目标对象密集排列或部分区域被遮蔽时,模型易出现目标遗漏或错误识别现象。在高密度聚集区域,当周边伴生植被(如杂草或低矮植物)干扰较强时,YOLOv10n算法准确率明显下降;而当目标对象因邻近物体遮挡导致主体区域不可见时,基础模型常出现相邻目标合并识别的情况,此类识别偏差会大幅削弱检测准确率。
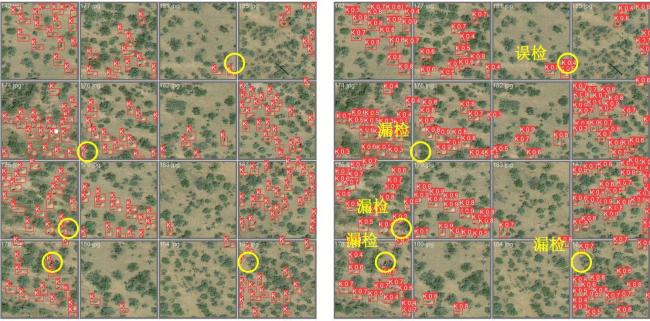
进一步,如图6复杂背景下,模型对大多数标注区域实现了有效识别,验证了其在噪声干扰环境下的识别精度和环境适应能力,证明了该模型可作为后续研究的基准架构。但测试发现,在目标密集分布区域易出现目标遗漏与错误识别,高斯噪声干扰下存在边界误判现象,且当目标被遮挡时出现定位偏差。针对上述识别缺陷,本研究通过网络架构优化、特征增强策略等技术手段,对YOLOv10n基准模型进行改进,重点提升其在高密度分布和遮挡场景下的目标定位能力,构建具有更优检测性能的植树位点识别模型。
2.3 多模态注意力模块效能比较测试
为验证文中引入的MHSA模块的有效性,量化评估不同注意力机制对模型性能参数及推理效率的影响。测试在统一配置的软硬件平台上实施,基于统一植树位点(树坑)数据集,以YOLOv10n为基准架构,在相同网络层级分别植入SA(Spatial Attention Mechanism)、EMSA(Efficient Multi-Scale Attention echanism)和MHSA三种注意力机制进行验证,实验结果如表2所示。
表2 不同注意力机制检测植树位点结果Table 2 Experimental results of tree planting locations detection for different attention mechanisms |
| 模型名称 | AP@0.5 | AP@0.5:0.95 | P | R | FPS/(f/s) |
|---|---|---|---|---|---|
| YOLOv10n | 0.921 | 0.761 | 0.923 | 0.876 | 134 |
| +SA | 0.925 | 0.752 | 0.931 | 0.887 | 132 |
| +EMSA | 0.931 | 0.763 | 0.942 | 0.854 | 126 |
| +MHSA | 0.934 | 0.774 | 0.938 | 0.886 | 130 |
表2实验数据表明,集成多类注意力模块后所有模型的AP@0.5均实现增长,其中MHSA的增益最大(ΔAP@0.5 =1.3%),同时AP@0.5:0.95指标同步提升。SA注意力机制模块使AP@0.5下降0.4%,而EMSA在精确率方面虽然提升显著(2.1%),但召回率R出现衰减。分析显示,除EMSA外,其余模块均实现了P与R的协同优化,其中MHSA在R指标上提升1.1%,表明其更擅长捕捉全局正样本。尽管注意力机制引入使帧率出现递减,但所有模型仍保持实时性,三者间的计算延迟差异小于8%,符合边缘计算部署需求。
进一步实验分析发现,MHSA机制在YOLOv10n中的集成对帧率影响有限,但显著增强了植树位点(树坑)的检测精度。这种改进归因于多头自注意力对特征空间的显著性增强,使模型更聚焦于目标判别性区域。改进后的架构在保持轻量化特性的同时,优化了小目标特征提取的完整性,验证了添加注意力机制策略在实时检测中的有效性。
2.4 不同损失函数性能对比
表3 植树位点识别不同IOU损失函数实验结果Table 3 Experimental results of tree planting locations detection for different IOU loss functions |
| 损失函数 | AP@0.5 | AP@0.5:0.95 | P | R | FPS/(f/s) |
|---|---|---|---|---|---|
| CIOU | 0.921 | 0.761 | 0.923 | 0.876 | 134 |
| SIOU | 0.921 | 0.757 | 0.932 | 0.892 | 132 |
| EIOU | 0.928 | 0.762 | 0.941 | 0.871 | 124 |
| Focal-EIOU | 0.931 | 0.776 | 0.938 | 0.885 | 128 |
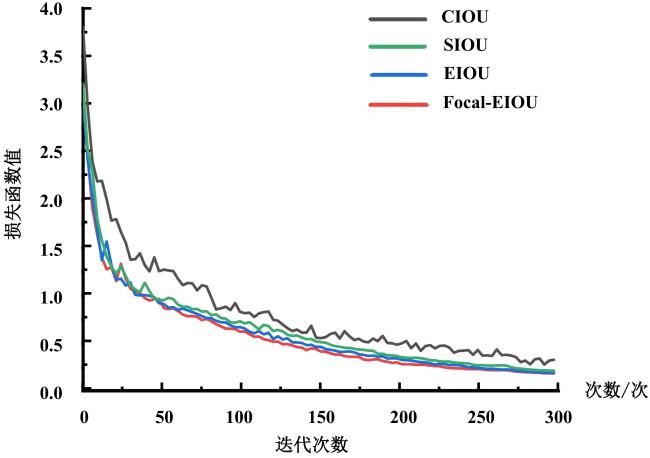
由表3可知,当采用SIOU回归函数时,平均精度AP维持基准水平0.921;而应用EIOU和Focal-EIOU函数后,AP指标分别优化至0.928和0.931,较基准模型提升0.007和0.010。上述变化可表明,改进型目标函数在边界框回归任务中展现出更优的性能,相较原始损失函数,其AP@0.5与AP@0.5:0.95分别提高了0.01与0.015。从图7的损失曲线分析可得,Focal-EIOU在边界框回归损失与总损失的传播过程中展现出更优的梯度稳定性。与CIOU、SIOU及EIOU三种传统损失函数相比,Focal-EIOU不仅实现了更快收敛,还达到更低的损失水平。这种改进归因于Focal权重的动态分配机制,即当模型预测出现偏差时,Focal权重会根据预测置信度放大梯度影响;而在高置信度预测阶段,权重则自动衰减以降低冗余样本的干扰。通过这种非线性梯度调节策略,Focal-EIOU有效缓解了漏检与错检的矛盾。综上,该损失函数在优化过程中优先补偿了漏检样本的特征响应,同时抑制了错检样本的梯度传播,最终在边界框定位精度与误检率间形成帕累托最优。这种设计使模型在保持小目标检测完整性的同时,显著提升了复杂背景下的判别鲁棒性。
2.5 消融实验
为了验证本研究改进的算法模块有效性,本研究以原始模型YOLOv10n为基线模型,并以P、R、AP@0.5、AP@0.5:0.95作为评价指标,通过多个改进模块不同的组合方式开展了消融实验,具体分析各个改进模块对YOLOv10n基线模型性能的影响,以及各模块组合后在YOLOv10-MHSA模型中的检测效果。消融实验结果如表4所示。
表4 植树位点检测消融实验Table 4 Ablation experiments for tree planting locations detection |
| 模型名称 | AP@0.5 | AP@0.5:0.95 | P | R | FPS/(f/s) |
|---|---|---|---|---|---|
| YOLOv10n | 0.921 | 0.761 | 0.923 | 0.876 | 134 |
| +小目标检测层 | 0.941 | 0.768 | 0.932 | 0.882 | 119 |
| + AKConv | 0.946 | 0.784 | 0.937 | 0.897 | 124 |
| +MHSA | 0.934 | 0.774 | 0.938 | 0.886 | 130 |
| + Focal-EIOU Loss | 0.931 | 0.776 | 0.938 | 0.885 | 128 |
| YOLOv10-MHSA | 0.982 | 0.837 | 0.961 | 0.921 | 109 |
|
由表4可知,在YOLOv10n模型中集成小目标感知模块后,AP@0.5指标实现了2.2%的提升,AP@0.5:0.95增长0.9%,同时精确率P与召回率R均呈现正向偏移。该改进验证了多尺度特征交互机制对无人机检测植树位点(树坑)这类微小目标的检测增益。当引入MHSA注意力模块时,AP@0.5与AP@0.5:0.95分别提升1.4%和1.7%,P与R对应改善1.6%和1.1%,表明MHSA机制能有效强化关键区域特征交互,提升模型检测鲁棒性。采用Focal-EIOU Loss准则替代原始方案后,AP@0.5与AP@0.5:0.95指标分别改善1.1%和2.0%,R同步优化,证明该损失函数在几何约束建模方面具有更强的边界框回归能力,有效提升了检测精度。
进一步,YOLOv10-MHSA架构通上述合改进策略,相较于YOLOv10n基准模型,在AP@0.5指标取得6.6%的提升,AP@0.5:0.95增幅达10.0%,同时P和R分别优化4.1%和5.1%,充分证明该模型架构通过模块化改进策略的协同作用,在植树位点(树坑)检测场景中展现出更强的检测性能。
综上,实验通过模块化验证确认了多尺度特征增强、MHSA机制集成,以及损失函数重构等优化方案的技术有效性。各改进组件在独立验证中均表现出检测性能的增强特性,当多策略协同应用时检测效能则呈现叠加效应。所构建的YOLOv10-MHSA检测架构在AP@0.5和AP@0.5:0.95指标上分别达到96.1%和92.1%,证实了其在无人机遥感检测植树位点(树坑)识别场景中具备显著的优势。
2.6 不同检测模型对比分析
由于无人机拍摄的植树位点(树坑)目标较小且真实环境中常常存在密集分布与复杂背景的情况,本研究设计了YOLOv10-MHSA结构网络,用来强化小目标复杂背景下识别效果较差的情况。为验证文中提出的YOLOv10-MHSA的性能,将其与YOLO系列、SSD及Faster R-CNN等主流模型进行对比分析。所有对比实验在统一训练条件下完成,基于相同数据集评估检测效率与精度差异,结果见表5。
表5 不同模型检测植树位点结果对比Table 5 Comparison of different models for detecting tree planting locations |
| 模型名称 | 评价指标 | ||||
|---|---|---|---|---|---|
| AP@0.5 | AP@0.5:0.95 | P | R | FPS/(f/s) | |
| YOLOv5s | 0.897 | 0.698 | 0.841 | 0.812 | 138 |
| YOLOv8n | 0.915 | 0.734 | 0.867 | 0.795 | 121 |
| YOLOv10n | 0.921 | 0.761 | 0.923 | 0.876 | 134 |
| SSD | 0.784 | 0.624 | 0.792 | 0.743 | 67 |
| Faster-R-CNN | 0.837 | 0.703 | 0.823 | 0.802 | 58 |
| YOLOv10-MHSA | 0.982 | 0.837 | 0.961 | 0.921 | 109 |
表5结果显示,YOLOv10n在核心检测指标上均优于同系列其他架构。尽管其检测帧率(FPS)相较YOLOv5s略有下降,但延迟差异在可接受区间,仍满足实时检测需求。作为YOLOv10系列的轻量化版本,该模型通过结构精简与复杂度优化,在保持检测性能的同时显著降低了计算资源占用,验证了其在资源受限场景下的适配性。
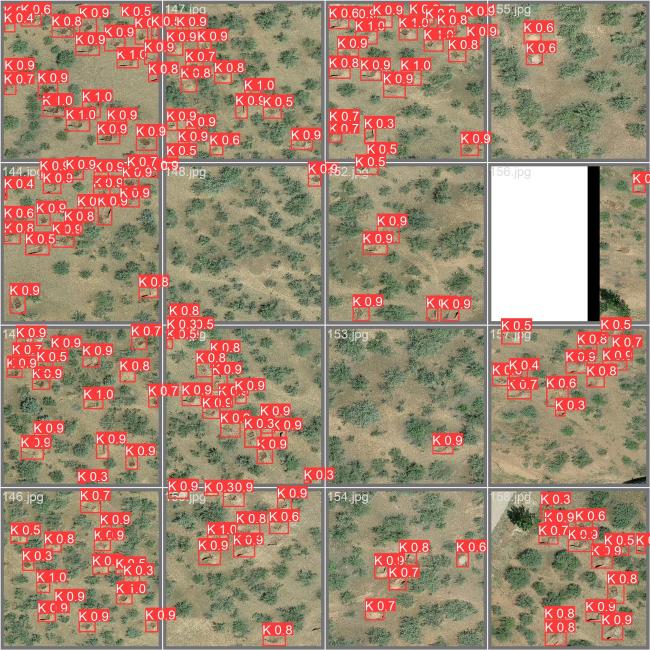
YOLOv10n在系统性评估后,因其检测性能与模型压缩比的均衡特性被选定为改进基准模型。改进后的YOLOv10-MHSA架构在维持实时推理能力的前提下,检测精度实现关键性突破,较基线模型提升9.5%。图8展示了YOLOv10-MHSA在测试集上的检测效果。
2.7 模型鲁棒性验证
本研究通过图像化验证方法评估了改进模型在多变背景与光照变化环境中的检测性能。基于数据集中典型干扰场景构建测试样本集,系统对比YOLOv10与YOLOv10-MHSA改进架构在低照度环境、强阴影干扰等典型场景下的目标识别差异,重点验证了多尺度特征增强策略对环境扰动的适应能力。
如图9所示,植树位点(树坑)处于复杂背景时,背景中的杂物和干扰使得检测任务变得更加具有挑战性。在这些复杂背景条件下,原模型在区域边缘及植树位点(树坑)分布密集的地方容易发生一定程度的漏检现象。例如,在背景中混杂的树枝和石块会干扰植树位点(树坑)的检测,导致原模型在这些区域的检测性能下降。相比之下,改进后的YOLOv10-MHSA模型能够更好地识别这些复杂背景下的植树位点(树坑)目标,并且在相同目标的检测中表现出更高的置信度。这表明,改进后的模型在处理复杂背景干扰问题时具有更高的检测精度和鲁棒性。


3 结 论
本研究针对“三北”防护林区内蒙古和林格尔县的植树位点(树坑)检测需求,设计了一种面向无人机遥感精准检测的优化框架,构建了基于YOLOv10架构的多尺度增强方案。改进策略包含:在特征传播路径中嵌入多分辨率检测支路,集成可变域卷积(AKConv)与多头自注意力机制(MHSA),并融合Focal-EIOU损失函数优化特征映射。实验结果表明,该架构在保持检测精度的前提下,显著提升对复杂遥感场景中微小目标的定位鲁棒性,尤其在目标高密度重叠区域展现出更强的特征解耦能力。所提方法为“三北”防护林区稀疏草原的无人机航拍图像处理提供了轻量化检测框架,同时为荒漠化治理中的植被恢复工程提供了相关技术支撑。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}