



0 引 言
文本语义相似性计算通常采用基于特征工程方法,利用向量空间模型(Vector Space Model,VSM)、TF-IDF(Term Frequency-Inverse Document Frequency)和词袋模型等方法提取特征,然后利用余弦相似度、编辑距离、曼哈顿距离等度量方法计算语义相似度。深度学习算法在文本相似性计算任务中得到广泛应用。该方法一般依托孪生神经网络架构,利用多种神经网络提取文本整体语义特征,然后在匹配层进行相似度计算。Wang等[4]提出了由表示层、匹配层和聚合层三部分组成的双边多视角匹配模型(Bilateral Multi-Perspective Matching, BiMPM),使用双向长短期记忆网络(Bidirectional Long Short-Term Memory, BiLSTM)构建表示层,并提取从句子P到句子Q和从句子Q到句子P的双向匹配关系,以便全面捕捉句子间的交互信息。Chen等[5]提出的ESIM(Enhanced Sequential Inference Model)模型在BiLSTM的基础上引入了注意力机制,实现了句子间的局部信息建模,有助于捕捉句子间的关键信息。Wang等[6]在循环神经网络(Recurrent Neural Network,RNN)隐藏表示层之前引入注意力机制,解决了注意力机制偏移问题。Pang等[7]将文本匹配问题建模为图像识别问题,构建一个单词级别的匹配矩阵,其元素表示单词间的相似性,利用卷积神经网络逐层捕捉深层次语义关系,提高语义相似计算的正确率。但基于深度学习的语义相似性计算效果高度依赖数据集规模和数据质量,并且对于语义关系更加复杂、知识更加丰富的专业领域而言,仍存在语义特征提取不够精准等问题。预训练模型可将外部知识引入到语义匹配任务中,以弥补短文本语义特征不足问题[8]。BERT(Bidirectional Encoder Representations from Transformers)[9]通过在大规模语料库上的预训练,提取了丰富的语言特征和语义关系,在迁移学习策略下,这些预训练模型可以被迁移到专业领域的语义特征提取任务中,通过少量的专业领域数据进行微调(fine-tuning),即可更加精准地提取语料特征,适应任务需求。研究人员针对文本语义相似度计算任务将迁移学习策略与BERT模型相结合开展了系列研究工作[10, 11]。SBERT(Sentence BERT)[12]模型利用孪生神经网络结构,将句子向量化并经过平均池化层处理后,根据余弦相似度衡量语义相似度。Ryu等[13]提出的ALBERT(A Lite BERT)模型,对BERT结构进行轻量化设计,实现了训练和预测时间的显著优化。Li等[14]提出了一种自我集成的ALBERT模型,该模型通过数据增强技术扩大了数据集的规模,并结合半监督学习方法提高了模型的学习效率。Bai等[15]提出的Syntax-BERT利用语法树从语法角度改进了Transformer模型,为预训练模型改进提供了新思路。近年来,基于通用大语言模型的方法也被应用在文本语义相似度计算研究中,Yang[16]利用一种自定义的GPT(Generative Pre-Trained Transformer)获取文本向量表示,并利用多种策略计算文本的相似度。Xu等[17]提出了GPT-4与“all-mpnet-base-v2”相结合的基于推理的相似度计算模型,该模型根据文本结构化信息和文本蕴含知识的关联程度计算文本语义相似性。大模型强大的语义理解能力和上下文感知能力可提高语义相似度计算的精准度,但大模型存在对计算资源和硬件设备需求高、计算效率低等问题影响了其应用,此外,针对特定领域的适应性仍有待进一步验证。
王郝日钦等[18]提出一种基于注意力机制的语义相似性计算模型,有效地解决在不同农业生产场景下一词多义问题。Zhou等[19]通过挖掘文本多源信息解决词语边界识别困难和文本特征信息不足的问题,解决病虫害领域的问句匹配问题。王奥等[20]融合BiLSTM和自注意力机制,从向量值、方向和元素等角度进行语义相似比对。刘志超等[21]将孪生网络与BiLSTM模型相结合计算水稻文本语义相似度。目前,农业领域语义相似度计算仍处于起步阶段。农业领域文本蕴含丰富农业知识、专有名词多,语义关系复杂,特别是网络农业问答社区积累的短文本数据,语义信息少、上下文语境有限、容易出现一词多义或语义模糊的情况,进一步加大了相似度计算的难度。为了解决农业领域数据规模有限的问题,迁移学习方法被广泛应用,其有效性在病虫害识别[22, 23],目标检测[24, 25]等研究中得到了验证,并在文本挖掘研究进行初步探索[26]。相关研究为迁移学习方法应用于农业短文本语义相似度计算提供了可行性依据和参考。本研究基于迁移学习方法,依托孪生网络结构,分别从数据增强、深度语义特征增强两个层面开展研究,提出一种面向农业短文本的语义相似度计算模型CWPT-TSBERT。
1 数据预处理
1.1 数据来源
本研究数据来源于“中国农技推广”(https://njtg.nercita.org.cn/user/index.shtml)问答平台,包括病虫草害、动物疫病、土壤肥料等多个主题领域,具备较高的专业性、准确性和实用性。由于网络上用户问答数据规范性较差,存在语法结构的混乱、表述不清或用词不当等问题,通过自动化脚本初步检测和剔除明显的错别字和语法错误,并采取人工校验方式,对表述模糊及专业术语使用不当的问句进行了严格筛选和修正,有效去除噪声数据。
1.2 农业语义相似性数据集的构建
首先采取多人次人工标注方式对从2022年到2024年采集的农业短文本数据进行分组,共组成19 968组问句对。为了保证模型的泛化性,组对时确保每一组问句对均来自相同领域。如果两个问句在语义上相同或相近,则被标注为1;反之,则标注为0。在本数据集中,标注为1的句子对共计9 221条,占总数据集的46.18%;标注为0的句子对共计10 747条,占总数据集的53.82%。其次采取交叉验证方式,保证数据标注的准确性与可靠性,最后按照8∶1∶1的比例将数据集划分为训练集、验证集、测试集三个部分,各部分之间无交叉重复数据,其中训练集设置为16 000对,验证集1 984对,测试集1 984对。数据集的部分样例如表1所示,可以看出农业短文本中存在例如“癌肿病”“尿素”等专有名词,这些词语是农业短文本中的核心词语,涉及特定的农业生产问题,但在通用语境中并不常见,导致其语义特征稀疏性高,难以识别。
表1 农业短文本相似度计算研究数据集样例Table 1 Agricultural short text similarity calculation research dataset example |
| 编号 | 问句1 | 问句2 | 真实标签 |
|---|---|---|---|
| 1 | 土豆癌肿病的症状有哪些? | 土豆癌肿病有什么症状? | 1 |
| 2 | 牡丹缺钾症防治方法有哪些? | 杜鹃缺钾症防治方法有哪些? | 0 |
| 3 | 防治夏季玉米钻心虫危害,危害症状是什么? | 如何防治夏季玉米钻心虫危害? | 0 |
| 4 | 种植土豆应该选择什么样的土地种植? | 应该选择什么样的种植土豆土地种植? | 1 |
| 5 | 柑橘幼树能不能追施尿素肥料吗? | 柑橘幼树如何施尿素肥料呢? | 0 |
| 6 | 请问各位老师这是什么虫,它正在取食樱桃树叶,该如何防治? | 各位老师,正在取食樱桃树叶的虫子是什么,该如何防治这种虫子? | 1 |
| 7 | 客源市场对休闲观光农业有什么影响? | 休闲观光农业有哪些影响因素? | 0 |
2 研究方法
2.1 农业短文本语义相似度计算模型
CWPT-TSBERT模型由语义增强层、嵌入层、池化层和相似性度量层四个主要部分组成,整体结构如图1所示,其中在语义增强层提出了一种基于子词单元的中文分词方法(Chinese-Based Wordpiece Tokenization, CWPT),将汉字进一步拆分为更细粒度的子单元,最大限度丰富短文本语义特征,提升模型对复杂中文词汇及汉字结构的理解能力。在嵌入层根据迁移学习策略,利用SBERT提取农业短文本特征提取,首先面向通用领域数据捕捉中文文本的语义特征,经微调训练后,生成更适合农业短文本的语义特征向量表示。池化层利用了平均池化策略将高维度的中文短文本语义向量映射到低维度的向量空间。相似性度量层采用了余弦相似度计算方法衡量两个输出短文本语义特征向量之间的相似性,并将计算结果输入到损失函数中,用于指导模型训练,优化模型参数,提高相似度计算的准确率。

2.1.1 孪生网络结构
孪生网络由左右两侧结构完全相同且参数共享的神经网络组成,具有结构复杂度低、训练效率高等优点,具体结构如图2所示。该网络架构通过共享参数的方式有效减少计算资源的消耗,并确保输入文本在相同的特征空间中进行对比。利用孪生网络两侧结构相同的特点,首先利用SBERT生成固定维度的句子特征向量,将原始农业文本映射到新特征空间,得到对应的语义特征向量。然后利用孪生网络共享参数的结构特点,确保左右两侧输入的农业文本在相同特征空间中进行对比,减少计算资源消耗。
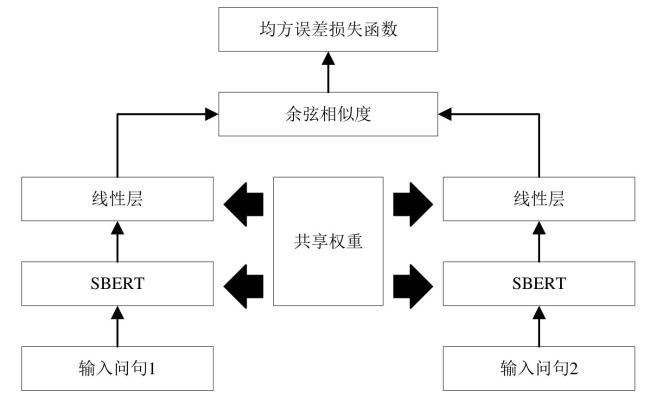
最后利用余弦相似度作为比对策略衡量这些语义特征向量之间的相似程度,并利用均方误差损失函数(Mean Squared Error, MSE)衡量预测值与真实值的差异,指导模型训练,优化模型参数,从而提高农业文本语义相似度计算的准确率。MSELoss计算预测值和真实值之间差的平方和的均值的计算如公式(1) 所示。
式中: 为样本的总数,个; 为第i个样本的真实值; 为第i个样本的预测值。
2.1.2 迁移学习训练策略
在文本语义相似性计算任务中需要海量标注数据集作为支撑,然而目前在农业领域缺少大规模、高质量语义相似性标注数据集,直接影响了语义相似性计算的正确率。为了提高模型性能,模型首先利用迁移学习策略在通用领域文本中对模型进行预训练,提取语义特征,然后将学习到的语义特征复制到农业领域中,并在农业领域语义相似度数据集进行微调训练,通过寻找通用领域和农业领域之间的语义关联关系,以便将源域的知识有效迁移到农业领域中,其流程如图3所示。

模型首先利用SBERT在大规模通用文本语义相似度计算数据集LCQMC[27](Large-Scale Chinese Question Matching Corpus)进行训练,得到了学习到基础性、普遍性语义规则的TSBERT。LCQMC数据集提供了大量中文短文本匹配对,其中训练集238 766条,验证集为8 802条,测试集12 500条,部分样例如表2所示。将TSBERT在LCQMC数据集上学习到的基础语义知识和模型的参数权重迁移至农业领域进行微调训练得到TSBERT-AGRI,标注AGRI后缀的表示该模型在农业短文本数据集上进行微调。其增强了模型的泛化能力,提高农业领域语义相似性计算准确性和效率。
表2 迁移学习LCQMC样例Table 2 Transfer learning LCQMC examples |
| 文本1 | 文本2 | 真实标签 |
|---|---|---|
| 什么是议价? | 什么是议价权? | 0 |
| 石家庄天气如何? | 石家庄天气怎样? | 1 |
| 同乐是什么意思? | 与君同乐什么意思? | 0 |
| 羽绒服怎么干洗啊? | 怎样干洗羽绒服? | 1 |
2.1.3 基于WPT的中文语义增强
基于子词单元的分词方法WPT(Wordpiece Tokenizer)将词汇拆分成更小的、可重用的片段,能够高效处理不同长度的词汇,即使对于未登录词,也可以通过子词组合的方式进行表示,进一步丰富语义特征表达,有效提高模型的泛化能力。例如,单词“unhappiness”可以被拆分为更小的子词,如“un”“happiness”,或者进一步拆分为“un”“happi”“ness”。
在基于BERT的文本语义相似性计算模型中,分词通常采用基于字符的方式。与英文不同,汉字本身已经是中文文本的最小语义单元,无法进一步分解。因此,每个汉字作为一个独立的Token 进入模型进行处理。然而,这种方法忽视了汉字的内部复杂结构以及字形结构在语义中的关联性,导致了模型提取的字向量缺少字形结构方面的属性。为了更全面捕捉汉字的语义特征,提出了一种基于WPT思想的改进分词方法CWPT。CWPT方法将汉字进一步拆分为偏旁部首和字形构件,这种拆分方式不仅保留了汉字作为基本语义单位的独立性,同时也涵盖了汉字的内部结构信息和语义关系。CWPT主要分词流程如图4所示。

CWPT首先对输入文本执行逐字遍历操作。借助针对汉字结构网站实施的数据爬虫技术,获取每个汉字拆分后的结构信息,并将其添加至原始文本末尾,以此作为拆分处理后的输入。关于CWPT方法的文本拆分样例如表3所示。
表3 农业短文本拆分样例Table 3 Agricultural short text segmentation examples |
| 原文本 | 拆分后的文本 |
|---|---|
| 西瓜栽培 | 西瓜栽培土木戈咅 |
CWPT对文本进行拆分处理后,利用SBERT编码层中的多头自注意力模块提取汉字与其偏旁部首以及字形结构之间的关系,具体结构如图5所示。

自注意力机制能够更加精准地捕捉汉字各个构件之间的相互依赖性和语义关联关系。通过多头自注意力机制在嵌入维度上进一步对文本语义进行分解,有效学习不同文字内部的依赖关系,从而提升模型对中文文本的理解能力。自注意力机制在处理汉字复杂结构时,能够更好地体现汉字构件的相互作用,增强模型的整体表现力。计算过程如公式(2)~公式(4) 所示,通过公式(2) 可计算得出输入矩阵在自注意力机制下的输出,在此过程中,查询矩阵 Q 、键矩阵 K 和值矩阵 V 均源自同一输入。公式(3) 引入多头注意力机制以对输出进行拼接处理,并与矩阵 A 0相乘从而获取最终结果。公式(4) 则为每个注意力头的输出函数表达式。
式中:softmax为激活函数;dk 为 K 向量维度; A 为权重矩阵; Q 、 K 、 V 分别为查询、键、值的矩阵;headi 为多注意力头。
2.2 试验设计
2.2.1 试验环境及参数设置
试验使用的基于标准层数的SBERT包含12层Transformer编码层,注意力头的数量为12,字向量维度为768,batch_size设置为8,具体试验环境配置见表4。
表4 试验配置环境Table 4 Experimental configuration environment |
| 试验环境 | 环境配置 |
|---|---|
| 操作系统 | Windows 11 22H2 |
| 内存 | DDR4 32 GB 3200 MHz |
| CPU | AMD RYZEN 5 5600X 3.7 GHz |
| GPU | NVIDIA RTX 4060 8 G |
| Python | 3.9 |
| Pytorch | 2.2.0 |
2.2.2 评价指标
在语义相似性计算任务中,利用正确率(Accuracy)、精确率(Precision)、召回率(Recall)、F 1值、皮尔逊相关系数(Pearson, r)和斯皮尔曼相关系数(Spearman, )衡量模型性能。其中,正确率是指模型在相似度预测中正确样本数与总预测样本数之比,反映了模型在整体预测中的准确程度。该评价指标将为模型的效果提供严谨的量化评估,确保其在实际应用中的可靠性和有效性,如公式(5) 所示。
式中:TP为问句对实际为相似且模型预测的结果为相似的数量;TN为问句对实际为不相似且模型预测的结果为不相似的数量;FN为问句对实际为相似但模型预测的结果为不相似的数量;FP为问句对实际为不相似但模型预测的结果为相似的数量。
精确率指的是模型在预测为相似的样本中,真正相似的样本数占总预测为相似样本数的比例,体现了模型在判断相似性时的精准度,如公式(6) 所示。
召回率是指真正为相似的样本中被模型预测为相似的样本数与总真正为相似的样本数之比,反映了模型在找出所有真正为相似的样本时的能力,如公式(7) 所示。
F 1值是精确率与召回率的调和平均数,用于衡量模型在精确率和召回率之间的平衡表现,确保模型在两者间实现最佳折中,如公式(8) 所示。
皮尔逊相关系数用于评估模型输出的语义相似度与人工标注的相似度之间的线性相关性,如公式(9) 所示。
式中: , 分别为两个变量的第i个观测值; , 分别为两个变量的均值; 为观测值的总数。
斯皮尔曼相关系数用于评估模型预测的语义相似度与人工标注的相似度之间的排序一致性,能够捕捉到非线性但单调的关系,如公式(10) 所示。
式中: 为每对观测值的等级差。
3 结果与讨论
3.1 模型训练效果
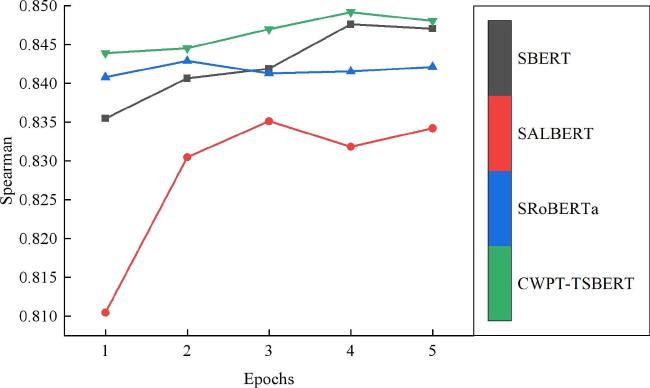
CWPT-TSBERT在农业短文本数据集上训练的皮尔逊相关系数和斯皮尔曼相关系数的趋势,以及与SBERT、SALBERT、SRoBERTa(Sentence RoBERTa)三种语义相似度计算模型比对情况如图6和图7所示。分析各个模型的皮尔逊系数发现,CWPT-TSBERT模型在第1个训练周期的皮尔逊相关系数为0.925 1,这一数值已经接近其他对比模型的最高值,大幅高于其他比对模型,并且在第4个训练周期时达到最大值为0.932 0,比第二名的SBERT高了0.001 5。分析各个模型的斯皮尔曼系数发现,CWPT-TSBERT模型的斯皮尔曼相关系数在第1个训练周期为0.843 9,为最高值,证明了CWPT-TSBERT模型在初始状态下就具有较强的相关性。CWPT-TSBERT模型的相关系数在训练过程中表现出平滑的增长趋势,且没有出现显著的回落或波动。这种平滑性反映了模型在处理数据时的稳健性和泛化性,能够有效适应不同迭代轮次的训练。CWPT-TSBERT模型的皮尔逊和斯皮尔曼相关系数保持持续上升趋势,证明了该模型不仅能够学习训练数据中的特征,还能将其有效应用于新领域的数据。

3.2 模型性能分析
CWPT-TSBERT模型将与基于循环神经网络的MaLSTM(Manhattan Long Short-Term Memory)[28]、BiLSTM[29]、BiLSTM_Self-attention[30],基于卷积神经网络的TextCNN(Convolutional Neural Networks)[31]、TextCNN_Attention[32],以及基于预训练模型的RoBERTa(Robustly Optimized BERT Pretraining Approach)[33]、ALBERT、BERT、SRoBERTa、SBERT_OFT、SALBERT(Sentence ALBERT)、SBERT等共12种模型进行对比,其中BiLSTM_Self-attention在BiLSTM的基础上融合了自注意力机制模块;TextCNN_Attention在TextCNN的基础上融合了注意力机制;RoBERTa、ALBERT、BERT直接利用预训练模型输出的语义特征向量进行相似度计算;SBERT_OFT(Sentence BERT only Output-layer Fine Tuning)、SALBERT、SBERT等均为基于迁移学习微调策略的模型,其中SBERT_OFT仅对输出层进行微调。
CWPT-TSBERT模型与比对模型在语义相似度计算任务中的试验结果详见表5,其正确率、精确率、召回率和F 1值分别达到了97.18%、96.93%、97.14%和97.04%。CWPT-TSBERT在各项指标上均大幅领先于其他比对模型,与SBERT相比,CWPT-TSBERT在正确率、精确率、召回率和F 1值上分别提高了0.76、0.64、0.95和0.80个百分点,充分展示了其在语义相似度计算任务中的领先优势。此外,基于微调的SBERT_OFT、SALBERT和SBERT模型在所有四项评价指标上均超过了94.07%,与未经微调的BERT和ALBERT等相比正确率的提升尤为显著,至少提高了6.19个百分点,表明了预训练模型通过微调后在下游的语义相似度计算任务中的性能可以获得明显改善;基于注意力机制的TextCNN_Attention和BiLSTM_Self-Attention模型在各项指标上均超过了91%,表明了通过引入注意力机制,有助于提高模型在捕捉文本重要特征方面的能力。传统模型如MaLSTM、BiLSTM和TextCNN的各项指标,除BiLSTM的精确率外,均低于90%。
表5 农业短文本相似度计算研究试验模型结果比对Table 5 Agricultural short text similarity calculation research experimental model results comparison |
| 试验模型 | 正确率/% | 精确率/% | 召回率/% | F 1值/% | |
|---|---|---|---|---|---|
| 传统神经网络模型 | MaLSTM | 85.79 | 88.31 | 80.83 | 84.40 |
| BiLSTM | 87.85 | 91.60 | 81.99 | 86.53 | |
| TextCNN | 89.01 | 88.54 | 88.35 | 88.44 | |
| 基于注意力机制模型 | TextCNN_Attention | 91.99 | 91.79 | 91.42 | 91.56 |
| BiLSTM_Self-Attention | 92.49 | 91.89 | 92.37 | 92.13 | |
| 基于预训练模型 | RoBERTa | 71.42 | 69.14 | 72.14 | 70.61 |
| ALBERT | 84.78 | 83.51 | 84.75 | 84.12 | |
| BERT | 88.16 | 87.67 | 87.39 | 87.53 | |
| 基于微调机制模型 | SRoBERTa | 78.73 | 77.65 | 77.65 | 77.65 |
| SBERT_OFT | 94.35 | 94.07 | 94.07 | 94.07 | |
| SALBERT | 95.16 | 95.11 | 94.70 | 94.90 | |
| SBERT | 96.42 | 96.29 | 96.19 | 96.24 | |
| CWPT-TSBERT | 97.18 | 96.93 | 97.14 | 97.04 | |
3.3 综合消融实验比对
为了进一步验证CWPT-TSBERT各组成部分的有效性,分别拆除迁移学习优化模块和CWPT优化模块,然后重新评估模型在语义匹配任务中的表现。此外,将这些优化模块分别应用于基于ALBERT、RoBERTa、BERT模型中,以验证其泛化性,具体结果如表6所示,其中TSALBERT、TSRoBERTa、TSBERT均为消去CWPT优化模块后的模型。而SALBERT、SRoBERTa、SBERT则为同时消去CWPT优化模块及迁移学习模块后的模型。
表6 CWPT-TSBERT综合消融实验结果比对Table 6 Comparison of CWPT-TSBERT comprehensive ablation experiment results |
| 试验模型 | 正确率/% | 精确率/% | 召回率/% | F 1值/% |
|---|---|---|---|---|
| ALBERT | 84.78 | 83.51 | 84.75 | 84.12 |
| SALBERT-AGRI | 95.16 | 95.11 | 94.70 | 94.90 |
| TSALBERT-AGRI | 95.82 | 95.46 | 95.76 | 95.61 |
| CWPT-TSALBERT | 95.87 | 95.46 | 95.87 | 95.67 |
| RoBERTa | 71.42 | 69.14 | 72.14 | 70.61 |
| SRoBERTa-AGRI | 78.73 | 77.65 | 77.65 | 77.65 |
| TSRoBERTa-AGRI | 94.15 | 93.67 | 94.07 | 93.87 |
| CWPT-TSRoBERTa | 95.92 | 95.76 | 95.66 | 95.71 |
| BERT | 88.16 | 87.67 | 87.39 | 87.53 |
| SBERT-AGRI | 96.42 | 96.29 | 96.19 | 96.24 |
| TSBERT-AGRI | 97.08 | 96.93 | 96.93 | 96.93 |
| CWPT-TSBERT | 97.18 | 96.93 | 97.14 | 97.04 |
从结果可以看到的是ALBERT、RoBERTa、BERT这三种预训练模型在经过微调后都得到了提升,证明了模型的微调在特定领域中的重要性。本研究提出的迁移学习模块,以及字形特征模块使得模型的性能得到了进一步的提升,其中基于LCQMC的迁移学习为模型性能带来的提升最为明显,使模型的正确率至少提升了0.66个百分点,证明了其针对中文农业短文本数据质量差和数量少的问题的有效性。
CWPT模块对汉字字形结构的注意力权重热力图如图8所示。其中,“西”与“瓜”“栽”与“培”之间的注意力权重深度尤为突出,表明这些汉字之间具有极强的关联性。此外,“栽”与“土”“培”与“土”之间也呈现出较高的注意力权重深度,进一步验证了汉字偏旁部首在表征汉字属性方面的重要性,增强了汉字在向量空间中的语义表示。此外,图中“栽”字拆分后的部分——“土”“木”“戈”这三部分之间也展现出了明显的注意力权重深度,验证了汉字字形结构内部同样存在复杂的关联性。

为了进一步验证基于LCQMC数据集的迁移学习策略对小规模农业短文本数据集的适用性,试验将训练集的规模分别调减至4 000对和8 000对,同时保持测试集规模不变仍为1 984对,并以正确率作为模型性能的衡量指标。各模型在不同规模训练集下的具体试验结果如表7所示。
表7 CWPT-TSBERT在不同规模数据集试验结果正确率比对 (Fig. 7 Comparison of CWPT-TSBERT accuracy on datasets of different scales) |
| 试验模型 | 训练数据集规模 | |||||
|---|---|---|---|---|---|---|
| 4 000对/% | ΔACC | 8 000对/% | ΔACC | 16 000对/% | ΔACC | |
| SALBERT | 92.04 | / | 93.55 | / | 95.16 | / |
| TSALBERT | 94.41 | +2.37 | 95.36 | +1.81 | 95.82 | +0.66 |
| CWPT-TSALBERT | 94.46 | +0.05 | 95.41 | +0.05 | 95.87 | +0.05 |
| SRoBERTa | 71.17 | / | 72.83 | / | 78.73 | / |
| TSRoBERTa | 93.04 | +21.87 | 93.20 | +20.37 | 94.15 | +15.42 |
| CWPT-TSRoBERTa | 95.75 | +2.71 | 95.82 | +2.62 | 95.92 | +1.77 |
| SBERT | 95.41 | / | 95.77 | / | 96.42 | / |
| TSBERT | 95.82 | +0.41 | 96.17 | +0.40 | 97.08 | +0.66 |
| CWPT-TSBERT | 96.47 | +0.65 | 96.57 | +0.40 | 97.18 | +0.10 |
|
经分析可知,CWPT-TSBERT模型在小规模农业短文本数据集中性能优势明显,在不同规模训练集中均取得了最高的正确率。基于迁移学习策略的TSBERT、TSALBERT和TSRoBERTa模型的正确率始终保持在93%以上,明显高于SBERT、SALBERT和SRoBERTa模型,特别是对SRoBERTa模型的提升效果显著。当训练集规模减少时,所有模型的正确率均呈现下降趋势,但基于迁移学习策略的模型由于学习了通用领域语义特征,所受影响较小,下降幅度明显小于未进行迁移学习训练的模型,同时,CWPT模块在小规模数据集上对模型的进一步提升更为明显。这一结果表明,利用迁移学习策略在大规模通用领域数据集学习通用语义特征,再利用基于汉字字形的CWPT模块能够使得模型学习到汉字的内部结构信息,最后利用小规模农业领域数据集进行微调训练可大幅提升语义相似度计算的正确率,是解决农业领域标注数据集匮乏问题的有效方法之一。
4 结 论
鉴于当前农业领域短文本语义相似度计算模型存在特征提取不够全面,以及高质量标注数据集匮乏等问题,构建了农业短文本问句对的数据集,并提出一种面向农业短文本的语义相似度计算模型CWPT-TSBERT。该模型融合了迁移学习策略与BERT预训练模型,在农业短文本语义相似性计算任务中,展现出较强的性能,其正确率高达97.18%,精确率达96.93%,召回率达97.14%,F 1值为97.04%,相较于其他对比模型优势明显。
中文汉字拆分模块CWPT能够将汉字拆解为字形部件,大幅增强了字向量的语义信息表达效能,丰富了语义特征表达方式,提高了文本相似性计算的正确率,证实了汉字独特的字形结构在语义信息表达进程中具有至关重要的作用。通过借助通用领域学习的语义特征,将语义相似性计算的正确率至少提升了0.66个百分点,验证了迁移学习策略及微调机制可解决农业文本数据标注难度大、资源消耗多等问题。此外,对多个试验模型、针对不同规模的试验数据施加相同的学习策略后,各模型的正确率均呈现出明显的提升态势,证明了迁移学习与微调机制在新领域学习中能够切实有效地利用已有知识与经验,提高学习效果,为相关领域的模型优化提供了借鉴与参考范例。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}