Smart Agriculture ›› 2025, Vol. 7 ›› Issue (1): 33-43.doi: 10.12133/j.smartag.SA202410026
• Topic--Intelligent Agricultural Knowledge Services and Smart Unmanned Farms (Part 2) • Previous Articles Next Articles
JIN Ning1, GUO Yufeng1,2, HAN Xiaodong1, MIAO Yisheng2,3, WU Huarui2,3( )
)
Received:2024-10-25
Online:2025-01-30
Foundation items:National Key Research and Development Program of China(2024YFD200803-3); Basic Research Project of Education Department of Liaoning Province(LJKQZ20222458); Liaoning Province Science and Technology Plan Joint Plan(2024-MSLH-399)
About author:JIN Ning, E-mail: jinning21@126.com
corresponding author:
CLC Number:
JIN Ning, GUO Yufeng, HAN Xiaodong, MIAO Yisheng, WU Huarui. Method for Calculating Semantic Similarity of Short Agricultural Texts Based on Transfer Learning[J]. Smart Agriculture, 2025, 7(1): 33-43.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.smartag.net.cn/EN/10.12133/j.smartag.SA202410026
Table 1
Agricultural short text similarity calculation research dataset example
| 编号 | 问句1 | 问句2 | 真实标签 |
|---|---|---|---|
| 1 | 土豆癌肿病的症状有哪些? | 土豆癌肿病有什么症状? | 1 |
| 2 | 牡丹缺钾症防治方法有哪些? | 杜鹃缺钾症防治方法有哪些? | 0 |
| 3 | 防治夏季玉米钻心虫危害,危害症状是什么? | 如何防治夏季玉米钻心虫危害? | 0 |
| 4 | 种植土豆应该选择什么样的土地种植? | 应该选择什么样的种植土豆土地种植? | 1 |
| 5 | 柑橘幼树能不能追施尿素肥料吗? | 柑橘幼树如何施尿素肥料呢? | 0 |
| 6 | 请问各位老师这是什么虫,它正在取食樱桃树叶,该如何防治? | 各位老师,正在取食樱桃树叶的虫子是什么,该如何防治这种虫子? | 1 |
| 7 | 客源市场对休闲观光农业有什么影响? | 休闲观光农业有哪些影响因素? | 0 |
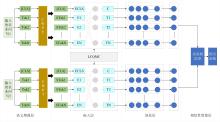
Fig. 1
Semantic similarity computation model architecture diagram

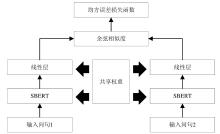
Fig. 2
Siamese network architecture diagram
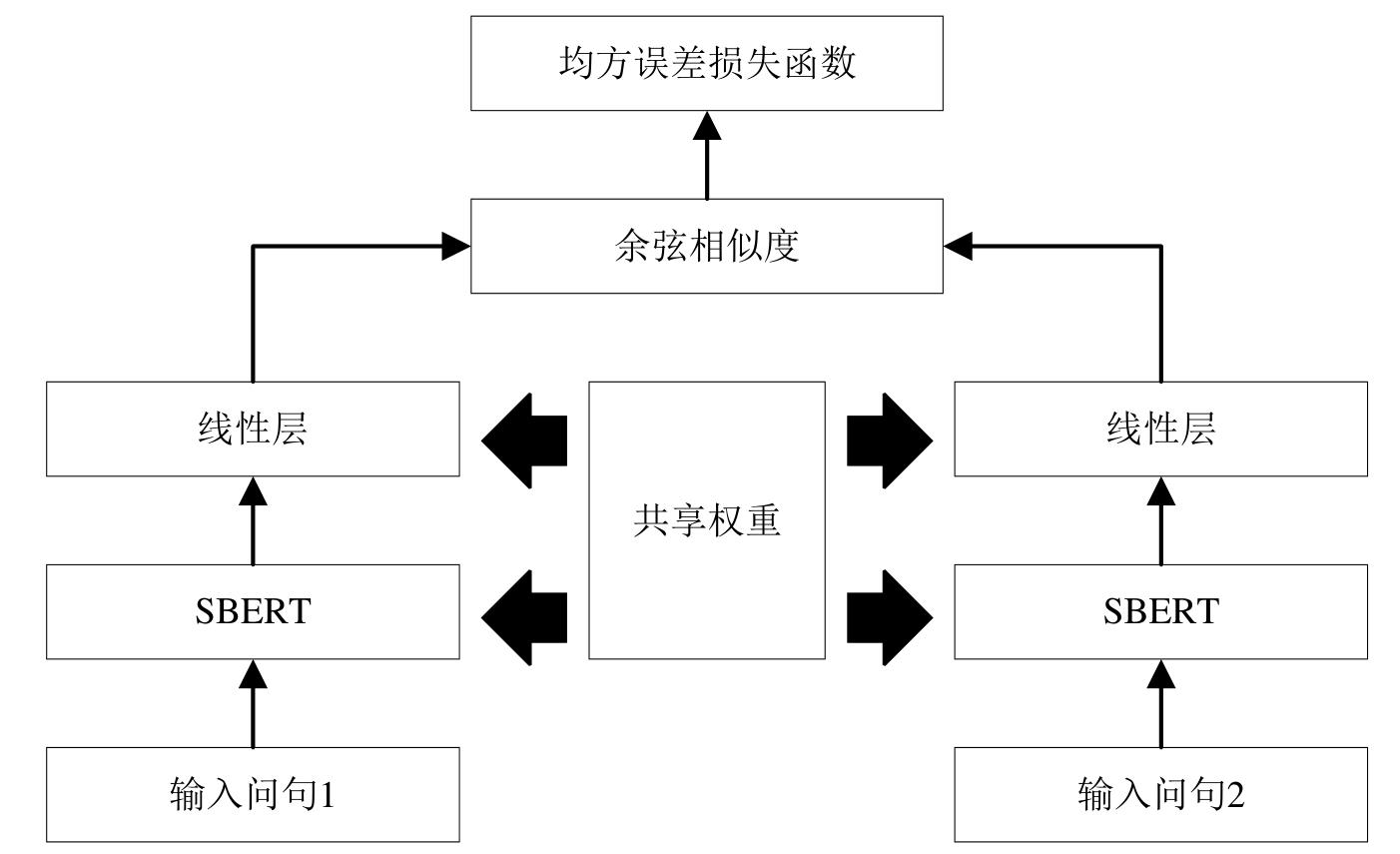
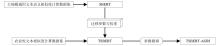
Fig. 3
Transfer learning process flowchart
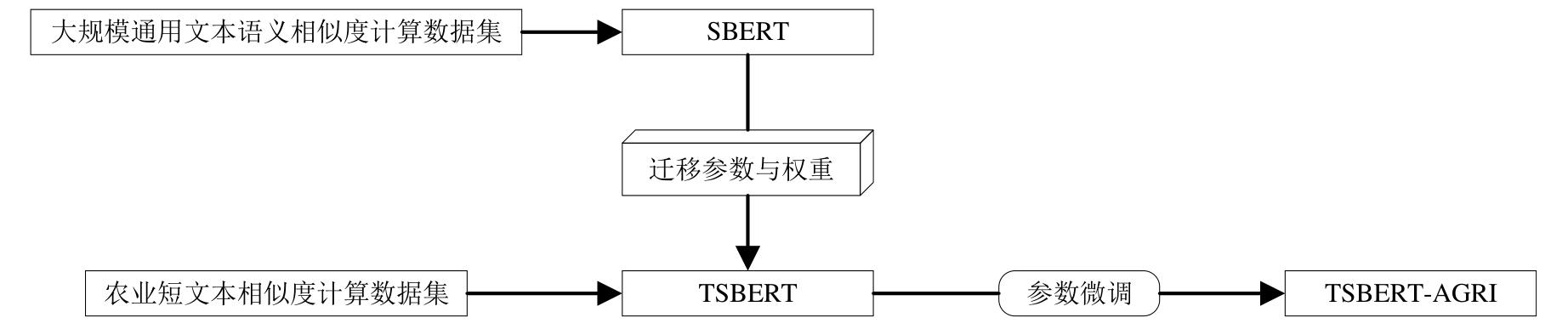
Table 2
Transfer learning LCQMC examples
| 文本1 | 文本2 | 真实标签 |
|---|---|---|
| 什么是议价? | 什么是议价权? | 0 |
| 石家庄天气如何? | 石家庄天气怎样? | 1 |
| 同乐是什么意思? | 与君同乐什么意思? | 0 |
| 羽绒服怎么干洗啊? | 怎样干洗羽绒服? | 1 |
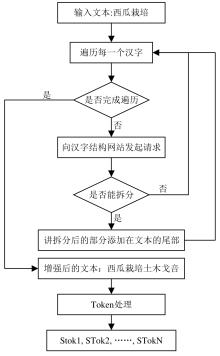
Fig. 4
The process structure diagram of CWPT
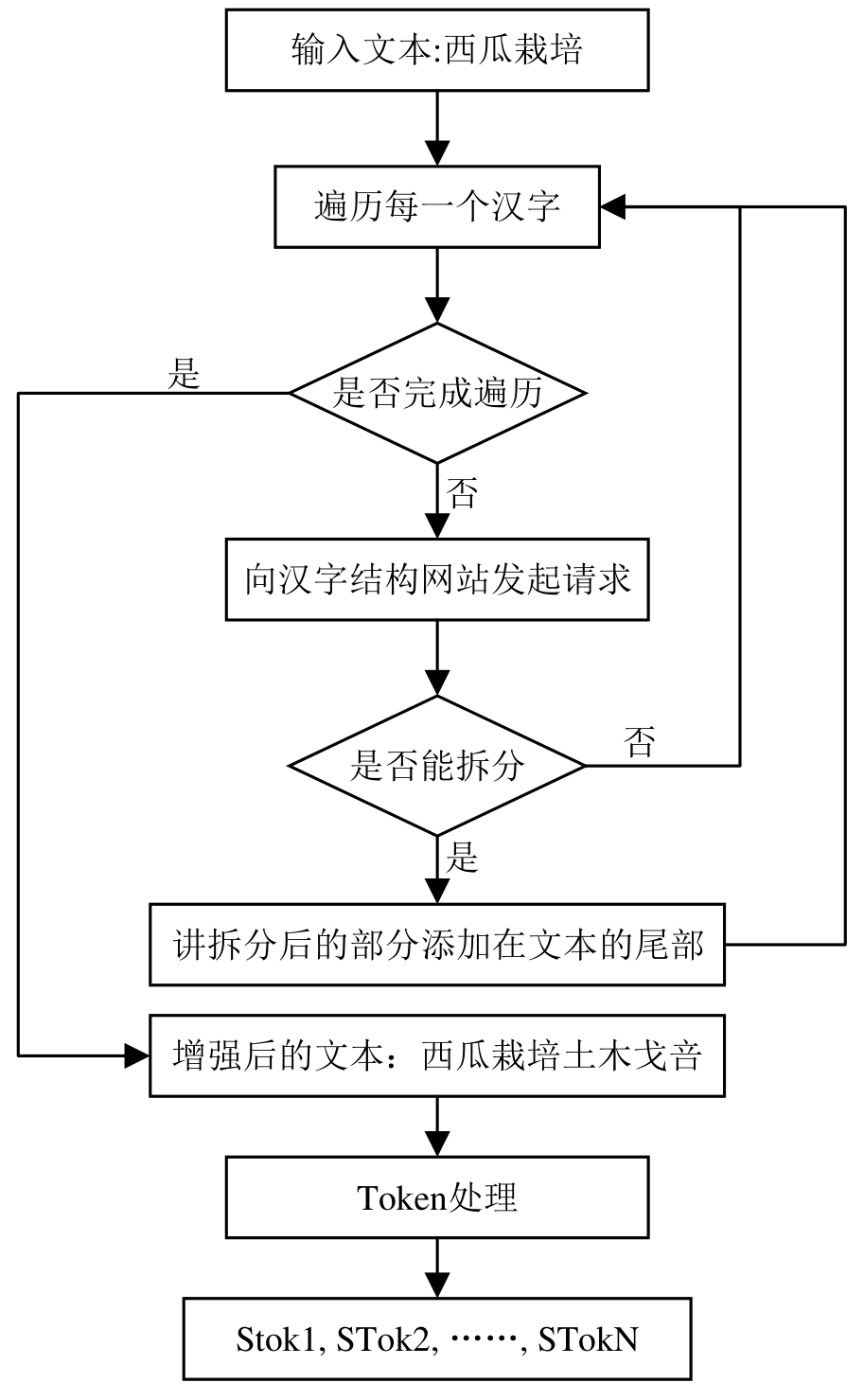
Table 3
Agricultural short text segmentation examples
| 原文本 | 拆分后的文本 |
|---|---|
| 西瓜栽培 | 西瓜栽培土木戈咅 |
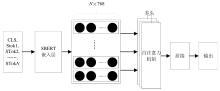
Fig. 5
Schematic of self-attention
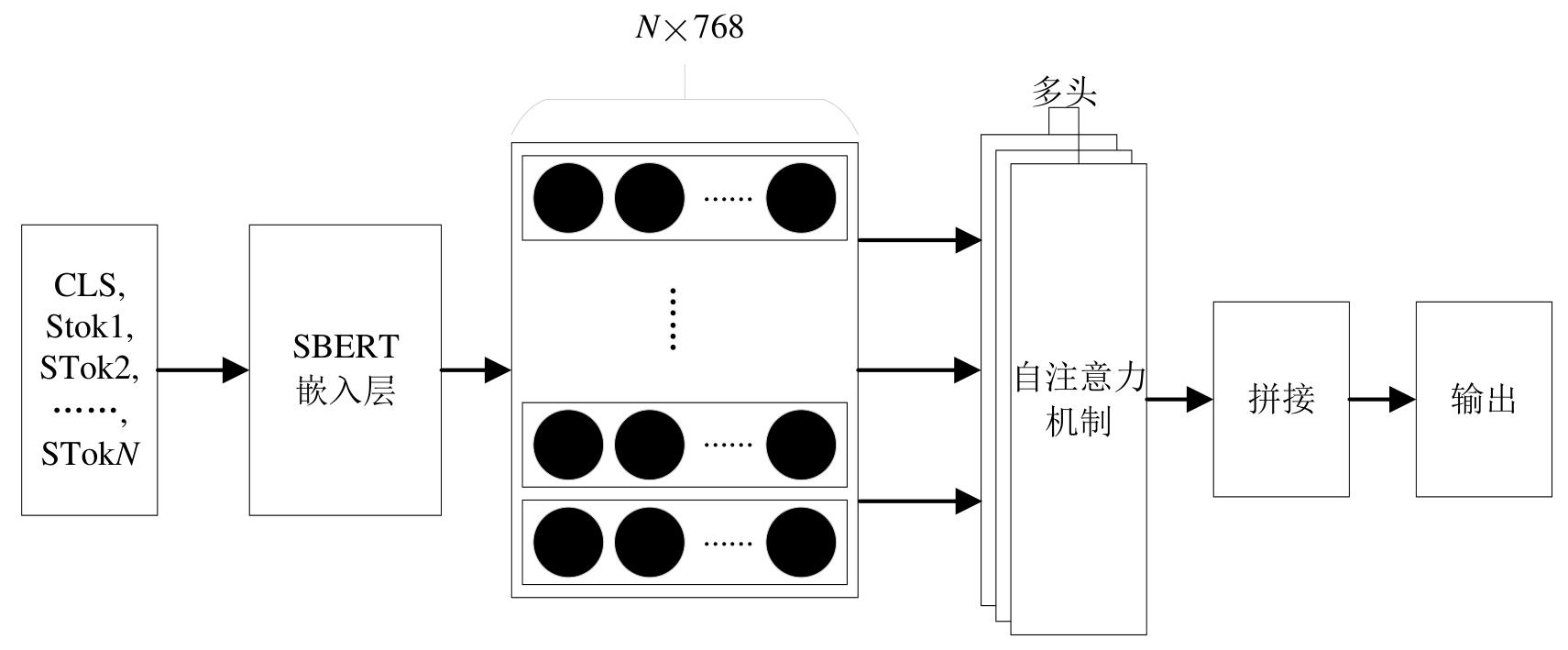
Table 4
Experimental configuration environment
| 试验环境 | 环境配置 |
|---|---|
| 操作系统 | Windows 11 22H2 |
| 内存 | DDR4 32 GB 3200 MHz |
| CPU | AMD RYZEN 5 5600X 3.7 GHz |
| GPU | NVIDIA RTX 4060 8 G |
| Python | 3.9 |
| Pytorch | 2.2.0 |
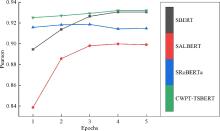
Fig. 5
Comparison of model Pearson correlation coefficients
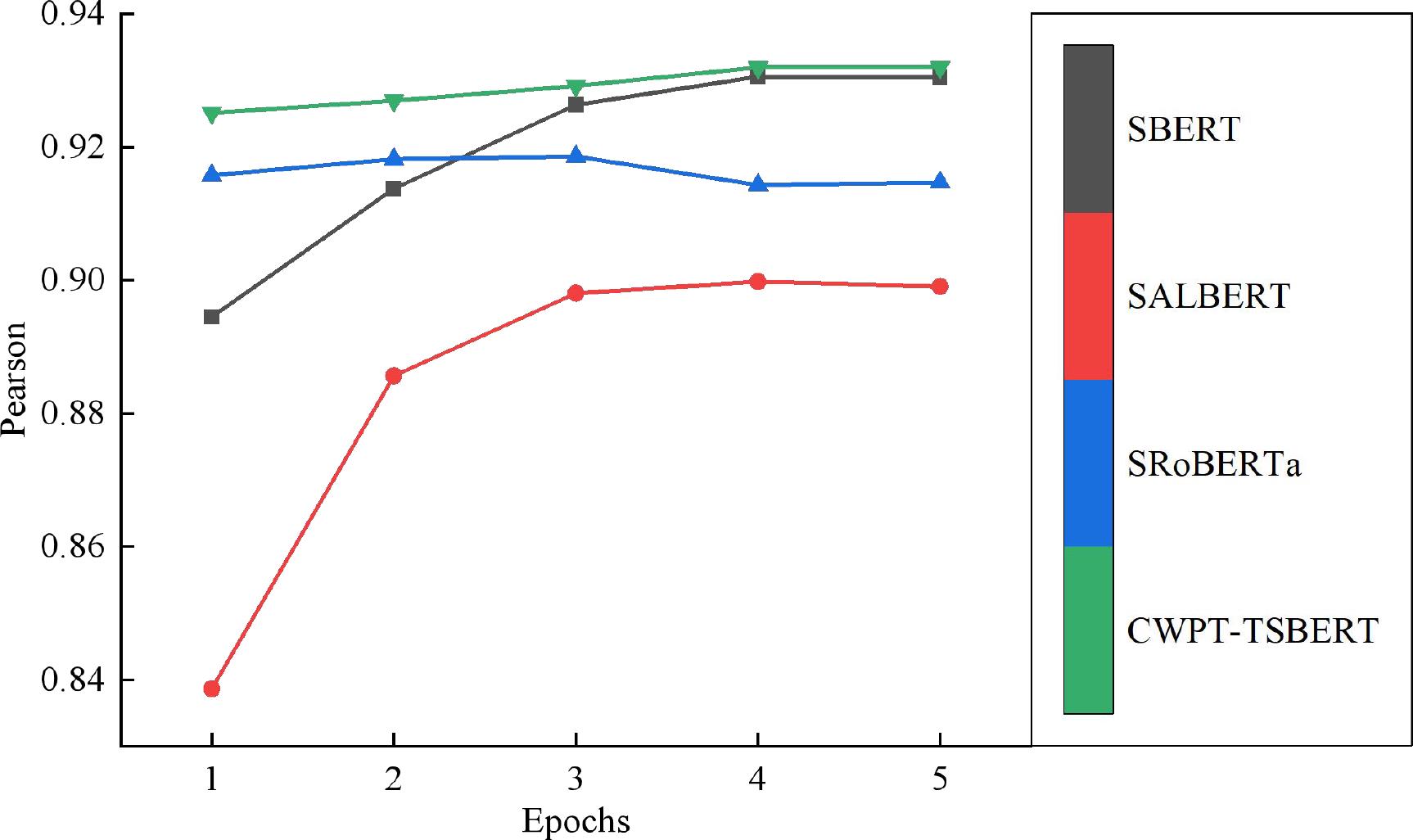
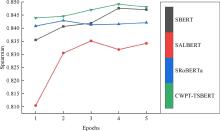
Fig. 7
Comparison of model Spearman correlation coefficients
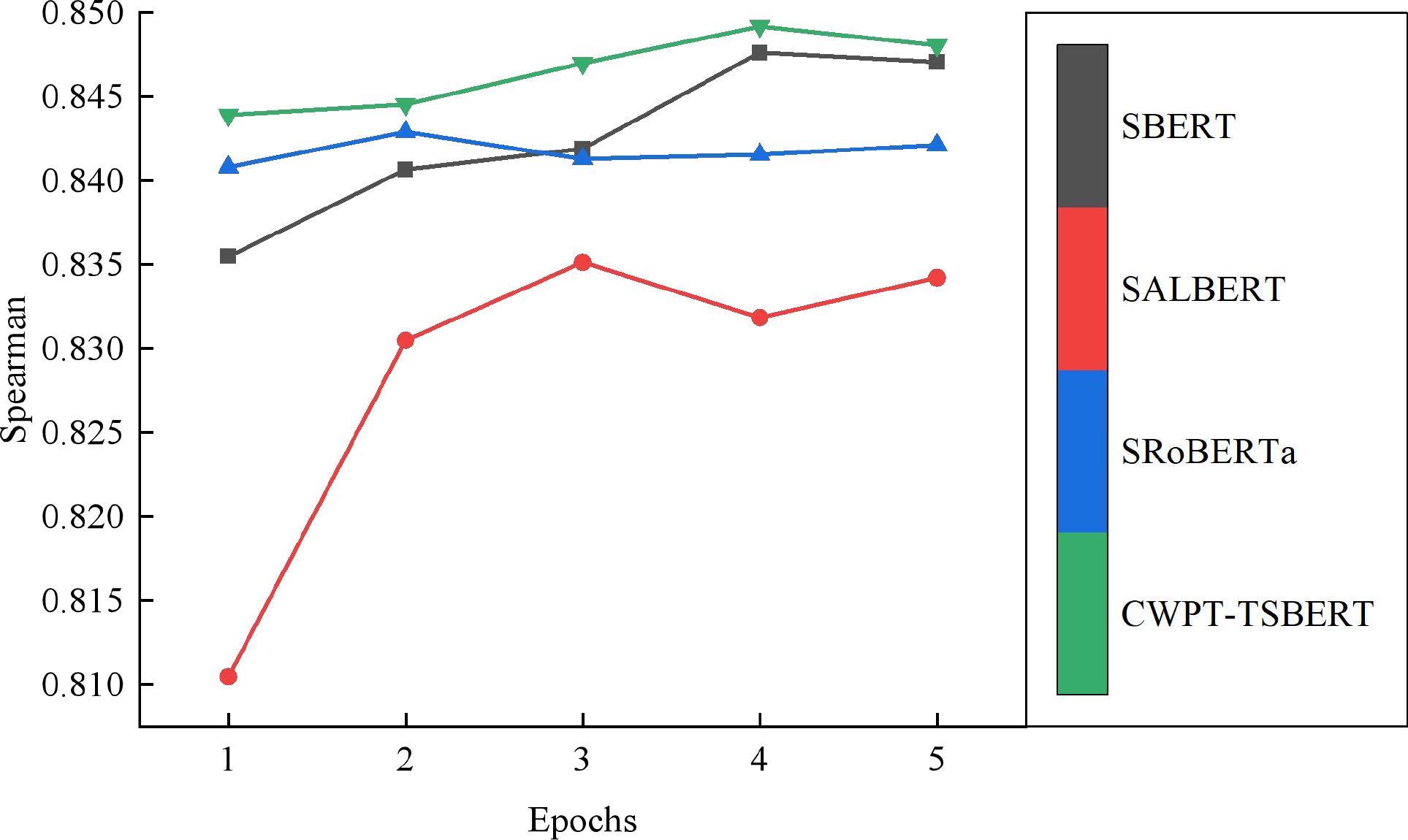
Table 5
Agricultural short text similarity calculation research experimental model results comparison
| 试验模型 | 正确率/% | 精确率/% | 召回率/% | F 1值/% | |
|---|---|---|---|---|---|
| 传统神经网络模型 | MaLSTM | 85.79 | 88.31 | 80.83 | 84.40 |
| BiLSTM | 87.85 | 91.60 | 81.99 | 86.53 | |
| TextCNN | 89.01 | 88.54 | 88.35 | 88.44 | |
| 基于注意力机制模型 | TextCNN_Attention | 91.99 | 91.79 | 91.42 | 91.56 |
| BiLSTM_Self-Attention | 92.49 | 91.89 | 92.37 | 92.13 | |
| 基于预训练模型 | RoBERTa | 71.42 | 69.14 | 72.14 | 70.61 |
| ALBERT | 84.78 | 83.51 | 84.75 | 84.12 | |
| BERT | 88.16 | 87.67 | 87.39 | 87.53 | |
| 基于微调机制模型 | SRoBERTa | 78.73 | 77.65 | 77.65 | 77.65 |
| SBERT_OFT | 94.35 | 94.07 | 94.07 | 94.07 | |
| SALBERT | 95.16 | 95.11 | 94.70 | 94.90 | |
| SBERT | 96.42 | 96.29 | 96.19 | 96.24 | |
| CWPT-TSBERT | 97.18 | 96.93 | 97.14 | 97.04 | |
Table 6
Comparison of CWPT-TSBERT comprehensive ablation experiment results
| 试验模型 | 正确率/% | 精确率/% | 召回率/% | F 1值/% |
|---|---|---|---|---|
| ALBERT | 84.78 | 83.51 | 84.75 | 84.12 |
| SALBERT-AGRI | 95.16 | 95.11 | 94.70 | 94.90 |
| TSALBERT-AGRI | 95.82 | 95.46 | 95.76 | 95.61 |
| CWPT-TSALBERT | 95.87 | 95.46 | 95.87 | 95.67 |
| RoBERTa | 71.42 | 69.14 | 72.14 | 70.61 |
| SRoBERTa-AGRI | 78.73 | 77.65 | 77.65 | 77.65 |
| TSRoBERTa-AGRI | 94.15 | 93.67 | 94.07 | 93.87 |
| CWPT-TSRoBERTa | 95.92 | 95.76 | 95.66 | 95.71 |
| BERT | 88.16 | 87.67 | 87.39 | 87.53 |
| SBERT-AGRI | 96.42 | 96.29 | 96.19 | 96.24 |
| TSBERT-AGRI | 97.08 | 96.93 | 96.93 | 96.93 |
| CWPT-TSBERT | 97.18 | 96.93 | 97.14 | 97.04 |
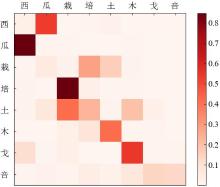
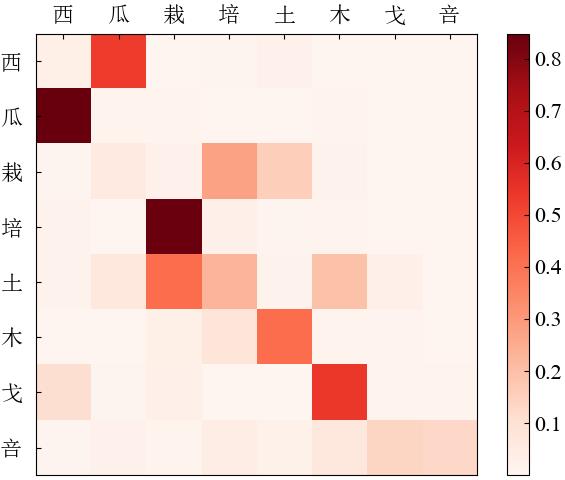
Fig. 8
Glycolic structure attention weight heat map
| 试验模型 | 训练数据集规模 | |||||
|---|---|---|---|---|---|---|
| 4 000对/% | ΔACC | 8 000对/% | ΔACC | 16 000对/% | ΔACC | |
| SALBERT | 92.04 | / | 93.55 | / | 95.16 | / |
| TSALBERT | 94.41 | +2.37 | 95.36 | +1.81 | 95.82 | +0.66 |
| CWPT-TSALBERT | 94.46 | +0.05 | 95.41 | +0.05 | 95.87 | +0.05 |
| SRoBERTa | 71.17 | / | 72.83 | / | 78.73 | / |
| TSRoBERTa | 93.04 | +21.87 | 93.20 | +20.37 | 94.15 | +15.42 |
| CWPT-TSRoBERTa | 95.75 | +2.71 | 95.82 | +2.62 | 95.92 | +1.77 |
| SBERT | 95.41 | / | 95.77 | / | 96.42 | / |
| TSBERT | 95.82 | +0.41 | 96.17 | +0.40 | 97.08 | +0.66 |
| CWPT-TSBERT | 96.47 | +0.65 | 96.57 | +0.40 | 97.18 | +0.10 |
| 1 |
中国农技推广信息平台[DB/OL]. [2023-10-20].
|
| 2 |
饶海笛. 基于语义的作物病虫害多模态知识问答方法研究[D]. 合肥: 安徽农业大学, 2023.
|
|
|
|
| 3 |
徐传丽, 周世杰, 吴春江. 深度学习中文本相似度计算研究综述[J]. 计算机应用与软件, 2024, 41(11): 1-14.
|
|
|
|
| 4 |
|
| 5 |
|
| 6 |
|
| 7 |
|
| 8 |
庞亮, 兰艳艳, 徐君, 等. 深度文本匹配综述[J]. 计算机学报, 2017, 40(4): 985-1003.
|
|
|
|
| 9 |
|
| 10 |
代翔, 孙海春, 牛硕, 等. 融合互注意力机制与BERT的中文问答匹配技术研究[J]. 信息网络安全, 2021, 21(12): 102-108.
|
|
|
|
| 11 |
马新宇, 范意兴, 郭嘉丰, 等. 关于短文本匹配的泛化性和迁移性的研究分析[J]. 计算机研究与发展, 2022, 59(1): 118-126.
|
|
|
|
| 12 |
|
| 13 |
|
| 14 |
|
| 15 |
|
| 16 |
|
| 17 |
|
| 18 |
王郝日钦, 王晓敏, 缪祎晟, 等. 基于BERT-Attention-DenseBiGRU的农业问答社区问句相似度匹配[J]. 农业机械学报, 2022, 53(1): 244-252.
|
|
|
|
| 19 |
|
| 20 |
王奥, 吴华瑞, 朱华吉. 基于特征增强的多方位农业问句语义匹配[J]. 西南大学学报(自然科学版), 2023, 45(6): 201-210.
|
|
|
|
| 21 |
刘志超, 王晓敏, 吴华瑞, 等. 基于BiLSTM-CNN的水稻问句相似度匹配方法研究[J]. 中国农机化学报, 2022, 43(12): 125-132.
|
|
|
|
| 22 |
张莉, 杨明辉, 孙嘉成. 基于注意力机制和迁移学习的小样本茶叶病害识别[J]. 中国农机化学报, 2024, 45(10): 262-268.
|
|
|
|
| 23 |
张国忠, 吕紫薇, 刘浩蓬, 等. 基于改进DenseNet和迁移学习的荷叶病虫害识别模型[J]. 农业工程学报, 2023, 39(8): 188-196.
|
|
|
|
| 24 |
|
| 25 |
|
| 26 |
|
| 27 |
|
| 28 |
|
| 29 |
|
| 30 |
|
| 31 |
|
| 32 |
|
| 33 |
|
| [1] | XU Wenwen, YU Kejian, DAI Zexu, WU Yunzhi. A Transfer Learning-Based Multimodal Model for Grape Detection and Counting [J]. Smart Agriculture, 2025, 7(4): 174-186. |
| [2] | HU Lingyan, GUO Ruiya, GUO Zhanjun, XU Guohui, GAI Rongli, WANG Zumin, ZHANG Yumeng, JU Bowen, NIE Xiaoyu. U-Net Greenhouse Sweet Cherry Image Segmentation Method Integrating PDE Plant Temporal Image Contrastive Learning and GCN Skip Connections [J]. Smart Agriculture, 2025, 7(3): 131-142. |
| [3] | YAN Congkuan, ZHU Dequan, MENG Fankai, YANG Yuqing, TANG Qixing, ZHANG Aifang, LIAO Juan. Rice Leaf Disease Image Enhancement Based on Improved CycleGAN [J]. Smart Agriculture, 2024, 6(6): 96-108. |
| [4] | GUO Wang, YANG Yusen, WU Huarui, ZHU Huaji, MIAO Yisheng, GU Jingqiu. Big Models in Agriculture: Key Technologies, Application and Future Directions [J]. Smart Agriculture, 2024, 6(2): 1-13. |
| [5] | ZHANG Gan, YAN Haifeng, HU Gensheng, ZHANG Dongyan, CHENG Tao, PAN Zhenggao, XU Haifeng, SHEN Shuhao, ZHU Keyu. Identification Method of Wheat Field Lodging Area Based on Deep Learning Semantic Segmentation and Transfer Learning [J]. Smart Agriculture, 2023, 5(3): 75-85. |
| [6] | TANG Hui, WANG Ming, YU Qiushi, ZHANG Jiaxi, LIU Liantao, WANG Nan. Root Image Segmentation Method Based on Improved UNet and Transfer Learning [J]. Smart Agriculture, 2023, 5(3): 96-109. |
| [7] | WANG Yapeng, CAO Shanshan, LI Quansheng, SUN Wei. Desert Plant Recognition Method Under Natural Background Incorporating Transfer Learning and Ensemble Learning [J]. Smart Agriculture, 2023, 5(2): 93-103. |
| [8] | ZHU Haipeng, ZHANG Yu'an, LI Huanhuan, WANG Jianwen, YANG Yingkui, SONG Rende. Classification and Recognition Method for Yak Meat Parts Based on Improved Residual Network Model [J]. Smart Agriculture, 2023, 5(2): 115-125. |
| [9] | PAN Chenlu, ZHANG Zhenghua, GUI Wenhao, MA Jiajun, YAN Chenxi, ZHANG Xiaomin. Rice Disease and Pest Recognition Method Integrating ECA Mechanism and DenseNet201 [J]. Smart Agriculture, 2023, 5(2): 45-55. |
| [10] | ZHANG Wenjing, JIANG Zezhong, QIN Lifeng. Identifying Multiple Apple Leaf Diseases Based on the Improved CBAM-ResNet18 Model Under Weak Supervision [J]. Smart Agriculture, 2023, 5(1): 111-121. |
| [11] | ZHAO Ruixue, YANG Chenxue, ZHENG Jianhua, LI Jiao, WANG Jian. Agricultural Intelligent Knowledge Service: Overview and Future Perspectives [J]. Smart Agriculture, 2022, 4(4): 105-125. |
| [12] | ZHANG Zhibo, ZHAO Xining, GAO Xiaodong, ZHANG Li, YANG Menghao. Accurate Extraction of Apple Orchard on the Loess Plateau Based on Improved Linknet Network [J]. Smart Agriculture, 2022, 4(3): 95-107. |
| [13] | CHEN Zhanqi, ZHANG Yu'an, WANG Wenzhi, LI Dan, HE Jie, SONG Rende. Multiscale Feature Fusion Yak Face Recognition Algorithm Based on Transfer Learning [J]. Smart Agriculture, 2022, 4(2): 77-85. |
| [14] | ZHOU Qiaoli, MA Li, CAO Liying, YU Helong. Identification of Tomato Leaf Diseases Based on Improved Lightweight Convolutional Neural Networks MobileNetV3 [J]. Smart Agriculture, 2022, 4(1): 47-56. |
| [15] | WEI Jing, WANG Yuting, YUAN Huizhu, ZHANG Menglei, WANG Zhenying. Identification and Morphological Analysis of Adult Spodoptera Frugiperda and Its Close Related Species Using Deep Learning [J]. Smart Agriculture, 2020, 2(3): 75-85. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||







