



0 引 言
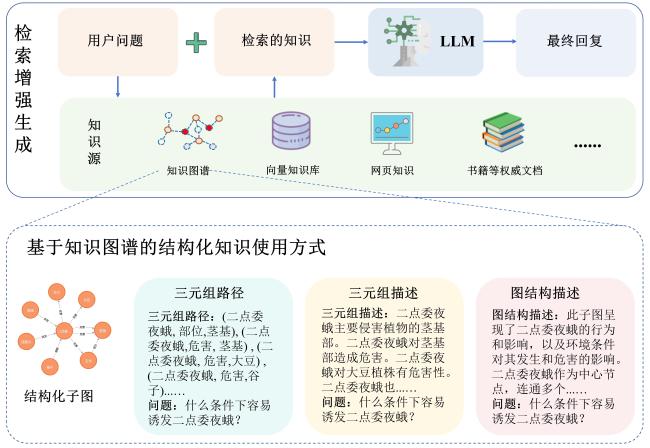

1 材料与方法
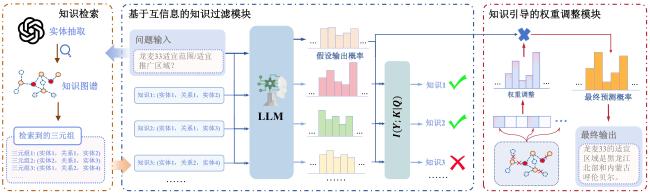
1.1 基于知识支撑的农业大语言模型目标函数优化
1.2 基于信息熵的知识过滤
1.2.1 知识路径检索

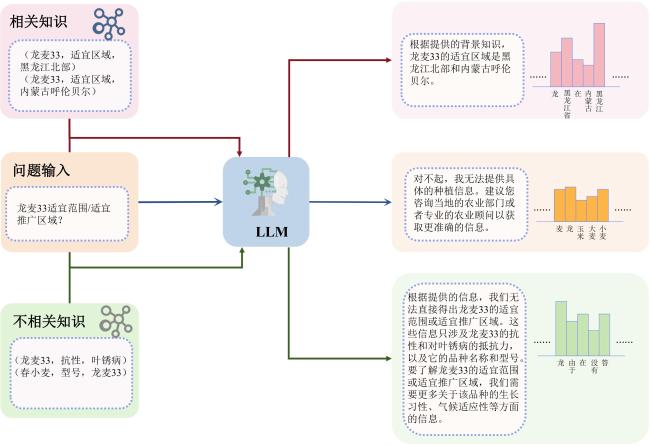
1.2.2 知识相关性对模型的影响
1.2.3 基于信息熵和语义计算的双重知识过滤
1.3 知识图谱引导的词表分布调整
2 结果与讨论
2.1 模型实现数据基础
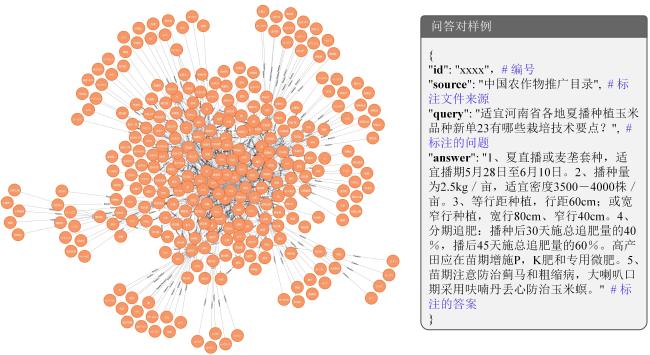
表1 农业测试数据统计表Table 1 Agricultural test data statistics table |
| 数据类型 | 数据统计 |
|---|---|
| # 问答对 | 2 664.00 |
| # 问答对中的词总量 | 491 566.00 |
| # 每个问答对的平均词数量 | 184.52 |
| # 问题涉及的词总量 | 195 592.00 |
| # 每个问题涉及的平均词数量 | 73.42 |
| # 答案涉及的词总量 | 295 974.00 |
| # 每个答案涉及的平均词数量 | 111.10 |
2.2 基础模型
表2 基线模型训练Token数和Tranformer层数统计表Table 2 Baseline model training token count and transformer layer statistics table |
| 模型 | 训练Token数/T | Transformer层数 |
|---|---|---|
| Baichuan2-7B-Chat | 2.6 | 32 |
| Baichuan2-13B-Chat | 2.6 | 40 |
| ChatGLM3-6B | 1.4 | 28 |
| Qwen1.5-7B-Chat | 3.0 | 32 |
| Qwen1.5-14B-Chat | 3.0 | 40 |
2.3 文本生成评估标准
2.4 模型生成结果整体对比
2.4.1 自动评估
表3 模型生成结果整体对比Table 3 Overall comparison of model-generated results |
| Backbone | Model | GOOGLE BLEU | BLEU | ROUGE | BertScore/% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BLEU_1 | BLEU_2 | BLEU_3 | BLEU_4 | Mean_BLEU | ROUGE_1 | ROUGE_2 | ROUGE_3 | ||||
| GPT-4o | Base | 0.196 9 | 0.075 2 | 0.044 4 | 0.031 9 | 0.024 4 | 0.044 0 | 0.139 8 | 0.000 0 | 0.139 8 | 53.39 |
| Baichuan-7B | Base | 0.642 9 | 0.788 6 | 0.420 3 | 0.288 6 | 0.212 1 | 0.427 4 | 0.167 0 | 0.000 0 | 0.167 0 | 53.19 |
| KGLLM(Ours) | 1.918 0 | 3.482 2 | 2.255 1 | 1.703 9 | 1.304 8 | 2.186 5 | 2.572 6 | 0.271 0 | 2.572 6 | 64.53 | |
| Baichuan-13B | Base | 0.731 7 | 1.083 8 | 0.605 7 | 0.424 1 | 0.313 4 | 0.606 8 | 0.229 3 | 0.000 0 | 0.229 3 | 55.81 |
| KGLLM(Ours) | 1.276 7 | 5.844 3 | 3.900 5 | 2.796 0 | 2.043 1 | 3.646 0 | 5.608 0 | 0.132 5 | 5.608 0 | 64.37 | |
| ChatGLM3-6B | Base | 0.464 2 | 0.322 2 | 0.169 4 | 0.114 4 | 0.081 8 | 0.171 9 | 0.124 5 | 0.000 0 | 0.124 5 | 52.43 |
| KGLLM(Ours) | 2.608 6 | 4.105 5 | 2.386 5 | 1.716 7 | 1.281 6 | 2.372 6 | 2.166 8 | 0.151 8 | 2.166 8 | 64.03 | |
| Qwen1.5-7B | Base | 0.198 5 | 0.040 5 | 0.021 4 | 0.014 2 | 0.009 9 | 0.021 5 | 0.118 0 | 0.000 0 | 0.118 0 | 51.07 |
| KGLLM(Ours) | 1.441 9 | 3.154 4 | 1.923 2 | 1.420 7 | 1.084 7 | 1.895 8 | 1.192 9 | 0.039 1 | 1.192 9 | 61.41 | |
| Qwen1.5-14B | Base | 0.343 1 | 0.031 1 | 0.018 4 | 0.013 4 | 0.009 9 | 0.018 2 | 0.131 2 | 0.000 0 | 0.131 2 | 51.63 |
| KGLLM(Ours) | 1.806 5 | 5.206 8 | 3.195 7 | 2.267 7 | 1.652 1 | 3.080 6 | 3.234 0 | 0.028 2 | 3.234 0 | 61.85 | |
| Average | Base | 0.476 1 | 0.453 2 | 0.247 0 | 0.170 9 | 0.125 4 | 0.249 2 | 0.154 0 | 0.000 0 | 0.154 0 | 52.83 |
| KGLLM(Ours) | 1.810 3 ⬆1.613 4 | 4.358 6 ⬆4.283 4 | 2.732 2 ⬆2.687 8 | 1.981 0 ⬆1.949 1 | 1.473 3 ⬆1.448 9 | 2.636 3 ⬆2.592 3 | 2.954 9 ⬆2.815 1 | 0.124 5 ⬆0.124 5 | 2.954 9 ⬆2.815 1 | 63.23 ⬆9.84 | |
|

2.4.2 人工评估
表4 人工评估的测试问题样例Table 4 Manually evaluated test question samples |
| 问题 | 要求适宜天津地区夏播种植……三元复合肥0.150—0.225 t/hm2,拔节期重施一次氮肥。回答满足要求的玉米品种? |
|---|---|
| Base | 天津地区适宜夏播种植的玉米品种较多,我从生育期、产量、抗病性等方面进行了对比,为你推荐几个品种: ……我最推荐联创825…… |
| GPT-4o | 根据天津地区的气候条件和夏播要求,适合该地区的玉米品种应具备以下特点: ……生育期短:由于是夏播,生育期较短的品种可……郑单958: 该品种生育期适中,适合夏播,具有较好的耐热性和抗病性,能够在高密度种植下稳定高产 |
| KGLLM(Ours) | 宽诚15 |
| 问题 | 海科玉3适宜范围/适宜推广区域? |
| Base | “海科玉3”是一款具体的产品,但没有足够的信息来确定它的确切类型或用途(可能是某种农业作物品种、化工产品等)。因此,我无法直接提供其适宜的推广区域。……如果你能提供更多关于“海科玉3”的信息,例如它是哪种产品,我可以给出更具体的答案。建议你查询相关资料或联系生产者以获取最准确的信息 |
| GPT-4o | “海科玉3”是由……3具有以下适宜推广区域: 华北地区……黄淮海……西北部分地区…… |
| KGLLM(Ours) | 适宜在东华北中早熟春玉米类型区的黑龙江省第二积温带,吉林省延边州、白山市的部分地区,通化市、吉林市的东部,内蒙古中东部的呼伦贝尔市扎兰屯市南部、兴安盟中北部、通辽市扎鲁特旗中部、赤峰市中北部、乌兰察布市前山、呼和浩特市北部、包头市北部早熟区种植 |
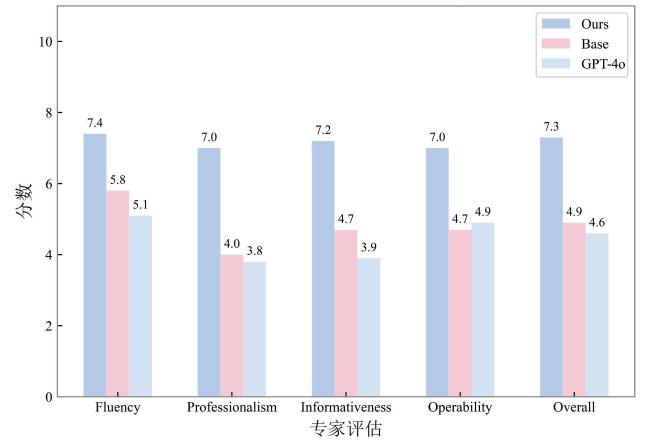
2.5 消融实验
2.5.1 组件消融
表5 分别对基于信息熵的知识过滤及知识图谱显式解码约束进行组件消融实验结果Table 5 Ablation results for knowledge filtering based on information entropy and explicit decoding constraints of knowledge graphs |
| Backbone | Model | GOOGLE BLEU | BLEU | ROUGE | BertScore/% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BLEU_1 | BLEU_2 | BLEU_3 | BLEU_4 | Mean_BLEU | ROUGE_1 | ROUGE_2 | ROUGE_3 | ||||
| Baichuan-7b | KGLLM(Ours) | 1.918 0 | 3.482 2 | 2.255 1 | 1.703 9 | 1.304 8 | 2.186 5 | 2.572 6 | 0.271 0 | 2.572 6 | 64.53 |
| wo MutualI | 1.680 3 | 3.557 7 | 2.158 0 | 1.570 5 | 1.181 4 | 2.116 9 | 2.158 8 | 0.121 1 | 2.158 8 | 62.23 | |
| wo EConstraint | 1.723 2 | 3.323 5 | 2.210 5 | 1.665 5 | 1.259 8 | 2.114 8 | 2.941 2 | 0.176 5 | 2.941 2 | 64.20 | |
| Baichuan-13b | KGLLM(Ours) | 1.276 7 | 5.844 3 | 3.900 5 | 2.796 0 | 2.043 1 | 3.646 0 | 5.608 0 | 0.132 5 | 5.608 0 | 64.37 |
| wo MutualI | 1.488 8 | 5.467 1 | 3.529 7 | 2.483 8 | 1.776 4 | 3.314 3 | 4.753 6 | 0.093 1 | 4.753 6 | 62.42 | |
| wo EConstraint | 1.835 7 | 5.556 7 | 3.643 6 | 2.620 7 | 1.933 2 | 3.438 5 | 5.219 8 | 0.239 6 | 5.219 8 | 63.95 | |
| ChatGLM3-6B | KGLLM(Ours) | 2.608 6 | 4.105 5 | 2.386 5 | 1.716 7 | 1.281 6 | 2.372 6 | 2.166 8 | 0.151 8 | 2.166 8 | 64.03 |
| wo MutualI | 2.480 6 | 3.211 9 | 1.967 7 | 1.484 3 | 1.155 4 | 1.954 8 | 1.996 9 | 0.209 9 | 1.996 9 | 62.65 | |
| wo EConstraint | 2.709 3 | 3.813 5 | 2.211 3 | 1.608 4 | 1.217 0 | 2.212 6 | 2.031 6 | 0.122 0 | 2.031 6 | 63.98 | |
| Qwen1.5-7B | KGLLM(Ours) | 1.441 9 | 3.154 4 | 1.923 2 | 1.420 7 | 1.084 7 | 1.895 8 | 1.192 9 | 0.039 1 | 1.192 9 | 61.41 |
| wo MutualI | 1.294 6 | 2.869 4 | 1.638 0 | 1.164 8 | 0.863 8 | 1.634 0 | 1.053 3 | 0.022 0 | 1.053 3 | 60.06 | |
| wo EConstraint | 1.157 5 | 2.665 4 | 1.616 2 | 1.180 0 | 0.888 7 | 1.587 6 | 1.383 8 | 0.060 2 | 1.383 8 | 60.20 | |
| Qwen1.5-14B | KGLLM(Ours) | 1.806 5 | 5.206 8 | 3.195 7 | 2.267 7 | 1.652 1 | 3.080 6 | 3.234 0 | 0.028 2 | 3.234 0 | 61.85 |
| wo MutualI | 1.700 9 | 4.782 2 | 2.845 6 | 2.010 9 | 1.473 4 | 2.778 0 | 2.630 2 | 0.017 0 | 2.630 2 | 61.11 | |
| wo EConstraint | 1.461 7 | 4.807 3 | 3.016 7 | 2.196 3 | 1.635 1 | 2.913 8 | 2.562 3 | 0.051 0 | 2.562 3 | 61.51 | |
| Average | KGLLM(Ours) | 1.810 3 | 4.358 6 | 2.732 2 | 1.981 0 | 1.473 3 | 2.636 3 | 2.954 9 | 0.124 5 | 2.954 9 | 63.24 |
| wo MutualI | 1.729 0 ⬇0.081 3 | 3.977 7 ⬇0.381 0 | 2.427 8 ⬇0.304 4 | 1.742 9 ⬇0.238 1 | 1.290 1 ⬇0.183 2 | 2.359 6 ⬇0.276 7 | 2.518 6 ⬇0.436 4 | 0.092 6 ⬇0.031 9 | 2.518 6 ⬇0.436 3 | 61.69 ⬇1.54 | |
| wo EConstraint | 1.777 5 ⬇0.032 9 | 4.033 3 ⬇0.325 4 | 2.539 7 ⬇0.192 5 | 1.854 2 ⬇0.126 8 | 1.386 8 ⬇0.086 5 | 2.453 5 ⬇0.182 8 | 2.827 7 ⬇0.127 1 | 0.129 8 ⬇-0.005 3 | 2.827 7 ⬇0.127 1 | 62.77 ⬇0.47 | |
|
2.5.2 知识相关的重要性
表6 证据检索中不同知识选择筛选方法对比Table 6 Comparison of different knowledge selection and filtering methods in evidence retrieval |
| Backbone | Model | GOOGLE BLEU | BLEU | ROUGE | BertScore/% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BLEU_1 | BLEU_2 | BLEU_3 | BLEU_4 | Mean_BLEU | ROUGE_1 | ROUGE_2 | ROUGE_3 | ||||
| Baichuan-7b | KGLLM(Ours) | 1.918 0 | 3.482 2 | 2.255 1 | 1.703 9 | 1.304 8 | 2.186 5 | 2.572 6 | 0.271 0 | 2.572 6 | 64.53 |
| Semantic only | 1.680 3 | 3.557 7 | 2.158 0 | 1.570 5 | 1.181 4 | 2.116 9 | 2.158 8 | 0.121 1 | 2.158 8 | 62.23 | |
| Random | 1.481 3 | 3.331 1 | 1.994 3 | 1.458 4 | 1.107 9 | 1.972 9 | 1.885 9 | 0.105 2 | 1.885 9 | 62.23 | |
| Baichuan-13b | KGLLM(Ours) | 1.276 7 | 5.844 3 | 3.900 5 | 2.796 0 | 2.043 1 | 3.646 0 | 5.608 0 | 0.132 5 | 5.608 0 | 64.37 |
| Semantic only | 1.488 8 | 5.467 1 | 3.529 7 | 2.483 8 | 1.776 4 | 3.314 3 | 4.753 6 | 0.093 1 | 4.753 6 | 62.42 | |
| Random | 1.535 9 | 5.253 2 | 3.318 5 | 2.326 3 | 1.670 7 | 3.142 2 | 4.550 1 | 0.114 2 | 4.550 1 | 62.05 | |
| ChatGLM3-6B | KGLLM(Ours) | 2.608 6 | 4.105 5 | 2.386 5 | 1.716 7 | 1.281 6 | 2.372 6 | 2.166 8 | 0.151 8 | 2.166 8 | 64.03 |
| Semantic only | 2.480 6 | 3.211 9 | 1.967 7 | 1.484 3 | 1.155 4 | 1.954 8 | 1.996 9 | 0.209 9 | 1.996 9 | 62.65 | |
| Random | 1.797 8 | 2.459 6 | 1.530 4 | 1.167 3 | 0.905 8 | 1.515 8 | 1.728 9 | 0.119 6 | 1.728 9 | 62.59 | |
| Qwen1.5-7B | KGLLM(Ours) | 1.441 9 | 3.154 4 | 1.923 2 | 1.420 7 | 1.084 7 | 1.895 8 | 1.192 9 | 0.039 1 | 1.192 9 | 61.41 |
| Semantic only | 1.294 6 | 2.869 4 | 1.638 0 | 1.164 8 | 0.863 8 | 1.634 0 | 1.053 3 | 0.022 0 | 1.053 3 | 60.06 | |
| Random | 1.250 1 | 2.939 5 | 1.649 4 | 1.167 6 | 0.865 2 | 1.655 4 | 0.889 7 | 0.002 2 | 0.889 7 | 59.84 | |
| Qwen1.5-14B | KGLLM(Ours) | 1.806 5 | 5.206 8 | 3.195 7 | 2.267 7 | 1.652 1 | 3.080 6 | 3.234 0 | 0.028 2 | 3.234 0 | 61.85 |
| Semantic only | 1.700 9 | 4.782 2 | 2.845 6 | 2.010 9 | 1.473 4 | 2.778 0 | 2.630 2 | 0.017 0 | 2.630 2 | 61.11 | |
| Random | 1.973 3 | 4.038 2 | 2.470 8 | 1.823 0 | 1.380 6 | 2.428 2 | 1.640 9 | 0.050 3 | 1.640 9 | 61.66 | |
| Average | KGLLM(Ours) | 1.810 3 | 4.358 6 | 2.732 2 | 1.981 0 | 1.473 3 | 2.636 3 | 2.954 9 | 0.124 5 | 2.954 9 | 63.24 |
| Semantic only | 1.729 0 ⬇0.081 3 | 3.977 7 ⬇0.381 0 | 2.427 8 ⬇0.304 4 | 1.742 9 ⬇0.238 1 | 1.290 1 ⬇0.183 2 | 2.359 6 ⬇0.276 7 | 2.518 6 ⬇0.436 4 | 0.092 6 ⬇0.031 9 | 2.518 6 ⬇0.436 3 | 61.69 ⬇1.54 | |
| Random | 1.607 7 ⬇0.202 7 | 3.604 3 ⬇0.754 3 | 2.192 7 ⬇0.539 5 | 1.588 5 ⬇0.392 5 | 1.186 0 ⬇0.287 2 | 2.142 9 ⬇0.493 4 | 2.139 1 ⬇0.815 8 | 0.078 3 ⬇0.046 2 | 2.139 1 ⬇0.815 8 | 61.67 ⬇1.56 | |
|
表 7 基于信息熵进行知识筛选样例Table 7 Knowledge filtering samples based on information entropy |
| 问题: 稻瘟病可以发生在水稻的各个生育期,根据发生时期和部位不同,可分为苗瘟、叶瘟、叶枕瘟、节瘟、穗瘟、穗颈瘟、枝梗瘟和谷粒瘟,其中穗颈瘟和枝梗瘟有什么症状? |
|---|
| 检索路径:[{'relation': '症状', 'source': '水稻', 'target': '拔节期症状'}, {'relation': '症状', 'source': '苗瘟', 'target': '水稻3叶期以前'}, {'relation': '症状', 'source': '苗瘟', 'target': '芽和芽鞘上出现水渍状斑点'}, {'relation': '症状', 'source': '苗瘟', 'target': '病苗基部变黑褐色'}, {'relation': '症状', 'source': '苗瘟', 'target': '上部呈黄褐色或淡红色'}, {'relation': '症状', 'source': '苗瘟', 'target': '病苗严重时枯死'}, {'relation': '症状', 'source': '苗瘟', 'target': '潮湿时病部可长出灰绿色霉层'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '叶耳易感病'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '初为污绿色病斑'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '向叶环、叶舌、叶鞘及叶片不规则扩展'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '最后病斑灰白色至灰褐色'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '潮湿时长出灰绿色霉层'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '病叶早期枯死'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '容易引起穗颈瘟'}, {'relation': '症状', 'source': '节瘟', 'target': '主要发生在穗颈下第一、二节上'}, {'relation': '症状', 'source': '节瘟', 'target': '初为褐色或黑褐色小点'}, {'relation': '症状', 'source': '节瘟', 'target': '环状扩大至整个节部'}, {'relation': '症状', 'source': '节瘟', 'target': '潮湿时节上生出灰绿色霉层'}, {'relation': '症状', 'source': '节瘟', 'target': '易折断'}, {'relation': '症状', 'source': '节瘟', 'target': '亦可造成白穗'}, {'relation': '症状', 'source': '穗颈瘟', 'target': '浅褐色小点'}, {'relation': '症状', 'source': '穗颈瘟', 'target': '黄白色、褐色或黑色斑点'}, {'relation': '症状', 'source': '穗颈瘟', 'target': '全白穗'}, {'relation': '症状', 'source': '枝梗瘟', 'target': '浅褐色小点'}, {'relation': '症状', 'source': '枝梗瘟', 'target': '黄白色、褐色或黑色病斑'}, {'relation': '症状', 'source': '枝梗瘟', 'target': '发病迟谷粒不充实'}, {'relation': '症状', 'source': '谷粒瘟', 'target': '发生在谷壳和护颖上'}, {'relation': '症状', 'source': '谷粒瘟', 'target': '发病早的谷壳上病斑大而呈椭圆形,中部灰白色'}, {'relation': '症状', 'source': '谷粒瘟', 'target': '可延及整个谷粒,造成暗灰色或灰白色的瘪谷'}, {'relation': '症状', 'source': '谷粒瘟', 'target': '发病迟的则为椭圆形或不规则形的褐色斑点'}, {'relation': '症状', 'source': '谷粒瘟', 'target': '严重时,谷粒不饱满,米粒变黑'}, {'relation': '症状类型', 'source': '叶瘟', 'target': '白点型'}, {'relation': '症状类型', 'source': '叶瘟', 'target': '急性型'}, {'relation': '症状类型', 'source': '叶瘟', 'target': '慢性型'}, {'relation': '症状类型', 'source': '叶瘟', 'target': '褐点型'}] |
| 信息熵过滤路径:[{'relation': '症状', 'source': '水稻', 'target': '拔节期症状'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '向叶环、叶舌、叶鞘及叶片不规则扩展'}, {'relation': '症状', 'source': '枝梗瘟', 'target': '黄白色、褐色或黑色病斑'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '初为污绿色病斑'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '病叶早期枯死'}, {'relation': '症状', 'source': '节瘟', 'target': '初为褐色或黑褐色小点'}, {'relation': '症状', 'source': '苗瘟', 'target': '上部呈黄褐色或淡红色'}, {'relation': '症状', 'source': '苗瘟', 'target': '水稻3叶期以前'}, {'relation': '症状', 'source': '苗瘟', 'target': '病苗严重时枯死'}, {'relation': '症状', 'source': '苗瘟', 'target': '病苗基部变黑褐色'}, {'relation': '症状类型', 'source': '叶瘟', 'target': '褐点型'}, {'relation': '症状类型', 'source': '叶瘟', 'target': '白点型'}, {'relation': '症状', 'source': '枝梗瘟', 'target': '浅褐色小点'}, {'relation': '症状', 'source': '苗瘟', 'target': '芽和芽鞘上出现水渍状斑点'}, {'relation': '症状类型', 'source': '叶瘟', 'target': '慢性型'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '最后病斑灰白色至灰褐色'}, {'relation': '症状类型', 'source': '叶瘟', 'target': '急性型'}, {'relation': '症状', 'source': '叶枕瘟', 'target': '潮湿时长出灰绿色霉层'}, { 'relation': '症状', 'source': '穗颈瘟', 'target': '黄白色、褐色或黑色斑点'}, {'relation': '症状', 'source': '苗瘟', 'target': '潮湿时病部可长出灰绿色霉层'}] |
|
2.5.3 合理知识约束的重要性
表8 基于不同知识约束的模型生成结果Table 8 Model-generated results under different knowledge constraints |
| Backbone | Model | GOOGLE BLEU | BLEU | ROUGE | BertScore/% | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| BLEU_1 | BLEU_2 | BLEU_3 | BLEU_4 | Mean_BLEU | ROUGE_1 | ROUGE_2 | ROUGE_3 | ||||
| Baichuan-7b | KGLLM(Ours) | 1.918 0 | 3.482 2 | 2.255 1 | 1.703 9 | 1.304 8 | 2.186 5 | 2.572 6 | 0.271 0 | 2.572 6 | 64.53 |
| Path Discription | 1.723 2 | 3.323 5 | 2.210 5 | 1.665 5 | 1.259 8 | 2.114 8 | 2.941 2 | 0.176 5 | 2.941 2 | 64.20 | |
| Hard Constraint | 0.759 7 | 1.052 9 | 0.558 2 | 0.387 1 | 0.283 8 | 0.570 5 | 0.160 0 | 0.000 0 | 0.160 0 | 54.46 | |
| Baichuan-13b | KGLLM(Ours) | 1.276 7 | 5.844 3 | 3.900 5 | 2.796 0 | 2.043 1 | 3.646 0 | 5.608 0 | 0.132 5 | 5.608 0 | 64.37 |
| Path Discription | 1.835 7 | 5.556 7 | 3.643 6 | 2.620 7 | 1.933 2 | 3.438 5 | 5.219 8 | 0.239 6 | 5.219 8 | 63.95 | |
| Hard Constraint | 0.609 2 | 1.043 3 | 0.597 4 | 0.423 6 | 0.316 2 | 0.595 1 | 0.287 1 | 0.000 0 | 0.287 1 | 55.82 | |
| ChatGLM3-6B | KGLLM(Ours) | 2.608 6 | 4.105 5 | 2.386 5 | 1.716 7 | 1.281 6 | 2.372 6 | 2.166 8 | 0.151 8 | 2.166 8 | 64.03 |
| Path Discription | 2.709 3 | 3.813 5 | 2.211 3 | 1.608 4 | 1.217 0 | 2.212 6 | 2.031 6 | 0.122 0 | 2.031 6 | 63.98 | |
| Hard Constraint | 0.379 8 | 0.549 3 | 0.285 3 | 0.187 9 | 0.130 4 | 0.288 2 | 0.138 5 | 0.000 0 | 0.138 5 | 51.03 | |
| Qwen1.5-7B | KGLLM(Ours) | 1.441 9 | 3.154 4 | 1.923 2 | 1.420 7 | 1.084 7 | 1.895 8 | 1.192 9 | 0.039 1 | 1.192 9 | 61.41 |
| Path Discription | 1.157 5 | 2.665 4 | 1.616 2 | 1.180 0 | 0.888 7 | 1.587 6 | 1.383 8 | 0.060 2 | 1.383 8 | 60.20 | |
| Hard Constraint | 0.843 3 | 1.948 5 | 1.044 7 | 0.724 3 | 0.531 6 | 1.062 3 | 0.109 9 | 0.000 0 | 0.109 9 | 58.44 | |
| Qwen1.5-14B | KGLLM(Ours) | 1.806 5 | 5.206 8 | 3.195 7 | 2.267 7 | 1.652 1 | 3.080 6 | 3.234 0 | 0.028 2 | 3.234 0 | 61.85 |
| Path Discription | 1.461 7 | 4.807 3 | 3.016 7 | 2.196 3 | 1.635 1 | 2.913 8 | 2.562 3 | 0.051 0 | 2.562 3 | 61.51 | |
| Hard Constraint | 0.956 2 | 2.129 2 | 1.274 2 | 0.946 5 | 0.721 2 | 1.267 8 | 0.174 1 | 0.000 0 | 0.174 1 | 60.01 | |
| Average | KGLLM(Ours) | 1.810 3 | 4.358 6 | 2.732 2 | 1.981 0 | 1.473 3 | 2.636 3 | 2.954 9 | 0.124 5 | 2.954 9 | 6324 |
| Path Discription | 1.777 5 ⬇0.032 9 | 4.033 3 ⬇0.325 4 | 2.539 7 ⬇0.192 5 | 1.854 2 ⬇0.126 8 | 1.386 8 ⬇0.086 5 | 2.453 5 ⬇0.182 8 | 2.827 7 ⬇0.127 1 | 0.129 8 ⬇-0.005 3 | 2.827 7 ⬇0.127 1 | 62.77 ⬇0.47 | |
| Hard Constraint | 0.709 6 ⬇1.100 7 | 1.344 6 ⬇3.014 0 | 0.752 0 ⬇1.980 2 | 0.533 9 ⬇1.447 1 | 0.396 6 ⬇1.076 6 | 0.756 8 ⬇1.879 5 | 0.173 9 ⬇2.781 0 | 0.000 0 ⬇0.124 5 | 0.173 9 ⬇2.781 0 | 55.95 ⬇7.28 | |
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}