



0 引 言
大豆需求预测方法通常有经验估计与趋势推算[4]、自回归差分移动平均模型(Autoregressive Integrated Moving Average Model, ARIMA)[2]、灰色预测[5]等经典时间序列方法,需求系统联立方程[6]、供求均衡联立方程[7]等结构方程模型方法,系统动力学方法[8],以及营养目标需求方法[9]等。这些方法的核心都是从历史数据中挖掘出影响大豆需求的某些随机变量随时间不断变化趋势的规律,并利用其对未来数据做出估计[10]。近年来,一些学者利用机器学习方法[11]或混合模型集成学习方法[12-14]对大豆供需及影响大豆需求的价格等进行了时间序列预测研究。然而,这些方法存在数据维度与多变量交互特征挖掘能力受限、多维动态因素耦合下的非线性关系捕捉能力不足、模型可解释性与领域适配性面临挑战的局限,难以有效支撑中国大豆需求的精准预测和可解释性分析。
Vaswani等[15]引入自注意力机制(Self-attention),提出了Transformer神经网络架构,最初在自然语言处理(Natural Language Processing, NLP)领域表现突出,后逐步引入时间序列预测,但存在方法可解释性局限[16]。时间融合Transformers(Temporal Fusion Transformers, TFT)是一种改进架构的Transformer模型[17],融合了Transformer的注意力机制与门控循环单元(Gated Recurrent Unit, GRU)/长短期记忆网络(Long Short-Term Memory, LSTM)的时间序列建模能力,同时引入门控机制、变量选择网络和分位数预测等创新组件,形成兼具高精度与可解释性的多步时间序列预测。目前,国内外学者已将TFT引入到医疗[18]、旅游[19]、电力[20]、电商[21]、宏观经济[22]、农产品价格[23]等领域开展预测应用研究。相关研究结果表明,TFT作为一种强大的时间序列预测工具,具有多模态数据处理能力和较好的可解释性。为了解决不同领域的实践应用问题,许多研究注重将TFT与领域知识深度结合,聚焦于模型架构轻量化、超参数优化、损失函数增强、多模型混合集成等方向开展TFT模型优化研究。Li等[24]将小时负荷的原始单变量时间序列重建为不同小时点的多个每日负荷时间序列,并将TFT中的LSTM替换为GRU,降低模型复杂度并提高长期依赖学习效率。曾宇容等[25]利用差分进化算法优化TFT参数,实验表明百度“疫情”指数对玉米期货价格影响显著,模型可解释性输出识别出生猪价格、国际油价为关键滞后变量。Mazen等[26]在提出的GRU-TFT模型中引入了DILATE(Distortion Loss Including Shape and Time)损失函数,专门用于训练所提出的多步非平稳时间序列预测。Qi等[27]融合了TFT与DeepAR概率预测模型,通过多目标优化算法(Multi-objective Salp Swarm Algorithm, MSSA)确定最优融合参数,提升了金融时间序列的点预测与区间预测性能。Tao[28]提出了一种集GRU、ARIMA和TFT的混合网络模型,通过对不同数据集的实验结果分析,证明了该混合模型在提高预测精度和理解复杂交通模式方面具有显著优势。Ho和Hung[29]提出了一种基于完全集成经验模态分解(Complete Ensemble Empirical Mode Decomposition, CEEMD)与TFT的多变量金融时间序列预测框架,较一般TFT模型精度提升达33.72%。
然而,现有TFT模型方法研究未见在大豆等农产品需求预测中的应用,且大豆需求受多维度变量影响,变量间存在非线性因果关系和时变依赖,在需求的短中长期综合分析时,可能出现长期趋势被短期噪声淹没或短期波动被长期模型忽略的问题。此外,TFT模型特征交互层的静态结构难以动态捕捉影响大豆需求的突发政策或事件驱动的特征关联变化,而多头注意力机制因难以自适应区分不同时间步的关键信息导致重要特征关系挖掘不充分和预测偏差。针对上述问题,本研究提出了一种基于多层动态特征交互(Multi-layer Dynamic Feature Interaction, MDFI)与自适应注意力权重优化(Adaptive Attention Weight Optimization, AAWO)改进的MA-TFT(Improved TFT Model Based on MDFI and AAWO)模型,并引入SHAP(SHapley Additive exPlanations)模型解释工具,在构建中国大豆需求分析数据集基础上,通过模型训练、对比实验、消融实验及可解释性分析,验证了MA-TFT模型的可靠性,最后利用MA-TFT模型预测了2025—2034年中国大豆需求量。研究成果为解决现有大豆需求预测方法精度不足、可解释性不强等实际问题提供了解决思路,也为其他农产品时间序列预测的方法优化与应用提供了参考和借鉴。
1 数据来源与预处理
1.1 数据来源
本研究按照适配TFT模型的多维度、长序列、大规模的数据训练需求原则,构建了涵盖消费、生产、贸易、库存、市场、经济与政策、国际7个维度的中国大豆需求分析数据集,包含1980—2024年4 652个相关指标,数据频度包括年度、季度、月度、周度和日度(表1)。数据主要来源于相关政府部门(美国农业部等)、国际组织(联合国粮农组织等)、研究机构(国家粮油信息中心等)、市场机构(美国芝加哥期货交易所等)、信息咨询企业(布瑞克农信科技集团等),以及Web of Science、CNKI等数据库。此外,为了量化研究养殖规模、中国大豆政策、贸易环境风险对大豆需求的影响,本研究还收集整理了生猪、牛、羊、家禽、水产品的饲料转化率(Feed Conversion Ratio, FCR),以及各类养殖产品饲料中的豆粕占比,构建了养殖规模影响指数;收集筛选了北大法宝法律法规数据库,以及相关政府网站2 492个与大豆相关的政策文件文本,构建了中国大豆政策力度指数;收集了如地缘政治风险指数(Geopolitical Risk Index, GPR)[30]、经济政策不确定性指数(Economic Policy Uncertainty Index, EPU)[31]等相关研究数据,构建了中国大豆进口贸易风险指数,支撑模型时间序列分析预测。
表1 中国大豆需求分析数据集指标Table 1 Indicators in the China's soybean demand analysis dataset |
| 数据维度 | 指标简述 |
|---|---|
| 消费 | 中国大豆国内消费量、中国豆油消费量、中国豆粕消费量等923个指标 |
| 生产 | 中国大豆产量,主产区分县平均温度、养殖规模影响指数等2 427个指标 |
| 贸易 | 中国大豆进口量、中国豆油进口量、中国豆粕进口量等77个指标 |
| 库存 | 中国大豆期初库存、中国大豆期末库存、进口大豆港口库存等101个指标 |
| 市场 | 国产大豆收购价格、大商所豆二连续收盘价、进口大豆完税成本等63个指标 |
| 经济与政策 | 中国居民人均可支配收入、中国城镇化率、中国大豆政策力度指数等472个指标 |
| 国际 | 全球大豆产量、芝加哥期货交易所(Chicago Board of Trade, CBOT)大豆期货连续收盘价格、中国大豆进口贸易风险指数等589个指标 |
|
1.2 数据预处理
本研究使用的大豆需求分析数据集数据来源多样,维度高、时间跨度长,存在缺失值、异常值和数据对齐等问题。为了提高数据质量、增强特征有效性,提升模型预测能力,对数据集进行了数据清洗、数据转换和数据增强处理。
1.2.1 数据清洗
1)一阶线性插值。对于小尺度、孤立式缺失(连续缺失1~2期),采用一阶线性插值处理,保留原始序列的趋势和局部波动。计算方法如公式(1) 所示。
式中: 为插值后的数据; 为缺失点相邻的有效观测值;t为缺失值所在时间点。
2)KNN(K-nearest Neighbor)均值填充。对于较大范围缺失或分段缺失(连续缺失超过2期),采用基于KNN的空间相似性进行均值填充。计算方法如公式(2) 所示。
式中: 为KNN均值填充结果; 为原始数据中与样本 最相似的 个邻居样本值; 表示样本 的 个最近邻集合。
3)异常值校正。首先,使用3σ原则检测对每个特征计算全样本均值 与标准差 ,若 ,则判定 为异常。然后,利用局部中位数替换方法对异常值进行校正,将异常值替换为其前后各3期中位数,以保证替换值对整体分布影响最小,同时平滑局部波动,避免极端值对模型梯度产生影响。
1.2.2 数据转换
1)市场年度与自然年度对齐。美国农业部、国家粮油信息中心等机构的分国别大豆供需平衡表数据一般采用市场年度作为统计周期,如中国市场年度为10月至次年9月,这种差异导致单一自然年度内(1—12月)存在跨市场年度的数据重叠现象。为消除统计口径差异,假设市场年度内月度数据呈线性分布[32],市场年度产量全部归属于该市场年度起始所对应的自然年度,进出口量和消费量按照比例分配法进行转换测算,其中消费量还参考相关行业分析报告进行进一步修正,期初库存和期末库存采用线性插值进行测算。具体计算如公式(3)~公式(7) 所示。
式中: 为t自然年度产量,万吨; 为市场年度产量,万吨; 为t自然年度的进口量/出口量,万吨; 和 为市场年度的进口量和出口量 ; 两个部分累计进出口量占比; 为t自然年度的消费量 ; 、 为市场年度的消费量,万吨; 分别为t自然年度的期初库存、期末库存 ; 、 分别为市场年度的期初库存、期末库存,万吨。
2)多频数据对齐。先利用插值扩展将年频数据扩展为月频或周频,计算方法如公式(8) 所示,再利用滚动降采样对高频(周、日)数据进行移动平均,以月度或周度频率降采样,使用窗口大小与目标时段一致的简单平均或加权平均。
式中: 为目标频率(如月度)第 时刻的插值数据; 和 分别为年度数据中最接近插值点左右两端的观测值; 为时间索引;mod( )表示取模运算。
3)归一化。利用Min-Max进行归一化处理,将所有输入特征缩放至[0,1],计算方法如公式(9) 所示。
式中: 为归一化后的特征值; 为原始特征值; 与 分别为该特征的最大值与最小值。
4)Z-score标准化。对气象条件类数据(温度、降水、日照)作Z-score变换处理,计算方法如公式(10) 所示。
式中: 为标准化后的特征值; 为原始特征值; 与 分别为该特征在样本中的均值与标准差。
1.2.3 数据增强
为解决关键数据指标(如豆粕需求、进口价格等)历史数据样本稀疏、时序断裂问题,引入条件生成对抗网络(Conditional Generative Adversarial Network, CGAN)生成符合实际条件的合成数据扩充训练集。首先建立包括生成器和判别器的CGAN模型,生成器根据历史窗口和静态变量生成伪样本,判别器用于判断数据真实性,继而设计损失函数开展对抗训练,生成对应的时间序列。生成器、判别器及损失函数计算如公式(11)~公式(13) 所示。
式中: 为生成的伪样本; ( )为生成器,其输入包括历史窗口 与静态协变量 ; 为生成器的参数集合;D( )为判别器; 为Sigmoid函数; ( )为特征提取网络; 为判别器参数; 为生成对抗网络的损失函数,优化目标为提升生成样本与真实样本的分布一致性; 为服从经验分布 真实样本; 为服从经验分布 的噪声变量。
1.2.4 数据特征工程
在处理多维度时序数据时,数据特征工程能够显著提高预测精度[33]。为避免特征过多导致“维度灾难”与“共线性问题”,本研究在模型特征构建时采用了“因子融合”与“逻辑归类”方法,对预处理后的大豆需求分析数据集进行了进一步的特征工程处理。具体过程如下:首先,设置历史窗口长度为12个月,目的是有效捕捉大豆需求数据中的年度季节性变化与政策周期性效应;其次,采用递归特征消除(Recursive Feature Elimination, RFE)方法从4 652个原始特征中筛选出27个特征;最后,采用主成分分析(Principal Component Analysis, PCA)对经RFE筛选后的27个特征进行进一步的特征降维,最终选定20个最具解释力的特征指标,包括中国大豆产量、大豆政策力度指数、居民收入水平、饲用需求(筛选组合)、替代品价格(筛选组合)等。实验通过历史窗口滚动切片方法实现,滚动步长为1个月,预测窗口为单月。经过上述处理步骤,特征工程最终形成了兼具精简性和解释能力的输入数据集,有效支持模型的后续训练和优化。
2 模型构建与训练优化策略
2.1 中国大豆需求预测TFT模型架构
TFT是一种结合了Transformer时序建模能力和循环神经网络动态特征捕捉能力的深度学习预测模型,适合处理多变量、长序列、非线性预测问题。TFT模型主要包括输入嵌入与特征转换、门控残差网络(Gated Residual Network, GRN)、变量选择网络(Variable Selection Networks, VSN)、多头注意力机制(Multi-Head Attention, MHA)、输出与预测模块5部分结构。利用TFT开展中国大豆需求预测的模型架构如图1所示。
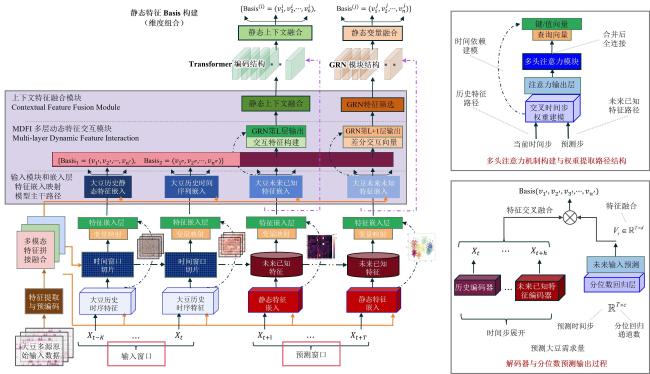
1)输入嵌入与特征转换。将静态元数据(不随时间变化,如主产区名称等)、时变的过去输入(过去时间步可观测的变量,如大豆历史消费量、大豆价格等)和已知未来输入(未来时间步可观测的变量,如经济预测目标、全球大豆预测产量等)的高维、多类型数据映射到统一的特征空间,进行标准化处理。
2)GRN。由输入变换层、门控线性单元(Gated Linear Unit, GLU)和残差连接3部分组成,通过输入变换层将当前层输入与静态上下文向量融合,通过GLU的门控机制动态选择对大豆需求预测有贡献的特征,抑制无关噪声,通过残差连接保留关键信息,缓解深层网络的梯度消失问题,提升训练稳定性。输入变换层、GLU和残差连接计算如公式(14)~公式(16) 所示。
式中: 为第l层GRN输入,如大豆价格、进口量等动态特征编码向量; 为静态上下文向量,包含种植面积等信息; 分别为输入特征和静态上下文的权重矩阵;ELU( )和ReLU( )为激活函数; 为Sigmoid函数,输出0~1的门控权重; 为元素级乘法,用于门控特征变换后的结果; 为残差连接后输入下一GRN层的结果; 为经过门控筛选后的特征向量。
3)VSN。用于根据不同输入特征对预测目标的贡献度,动态地为每个变量分配注意力权重。该模块对静态特征和动态特征分别进行门控注意力机制建模,解决了大豆需求预测中多变量(如大豆价格、大豆进口量、政策力度、替代品价格等)的冗余与噪声问题。其注意力计算如公式(17) 所示。
式中: 为第 个输入变量的嵌入向量; 为静态上下文表示; 为对应特征的重要性注意力权重; 为可训练参数; 为拼接操作;通过 对各变量权重进行归一化,最终获得融合后的表示 。
4)MHA。用于捕捉大豆需求的长期趋势和跨周期依赖,通过多个注意力头实现特征级别的信息融合。计算如公式(18) 和公式(19) 所示。
式中: 、 、 分别为查询(Query)、键(Key)、值(Value)矩阵, 、 、 和 是不同注意力头的可训练参数。
5)输出与预测模块。为增强预测区间的可信度与不确定性建模能力,本研究采用分位数回归(Quantile Regression)方式构建输出层,其目标是对不同置信水平 下的大豆需求进行估计,生成完整的预测分布。输出值表示未来T个时间步的 分位数预测结果,刻画出预测区间的上下边界。输出损失函数计算如公式(20) 所示。
式中: 为真实值; 为预测值; 为分位数水平(分别取0.1、0.5、0.9)。
2.2 改进的中国大豆需求预测MA-TFT模型
TFT模型中,单层GRN仅能捕捉低阶特征交互(如一阶或二阶线性关系),而中国大豆需求预测涉及多源动态影响因素(如价格波动、政策调控、国际贸易、气候变化等),其复杂非线性关系往往需要更高阶特征组合的支持,单层GRN无法显示建模此类高阶特征交互,导致模型对复杂因果关系的表达能力受限。此外,TFT的多头注意力机制对特征权重的分配缺乏动态调节能力,而大豆需求预测任务中,不同特征的重要性可能随时间或外部环境变化(如突发性政策干预或极端天气事件),传统静态注意力机制难以自适应调整特征敏感性,易导致对关键信号的捕捉不足或噪声干扰过载。针对此问题,本研究在TFT模型基础上,引入MDFI和AAWO策略,构建改进TFT的MA-TFT模型,通过逐层堆叠GRN模块与残差连接,使模型自动学习特征间的高阶非线性依赖,通过引入可学习的特征缩放参数,动态增强关键特征的注意力分布,同时抑制冗余或低相关性特征,从而提升对大豆需求预测多因素耦合作用机制的建模能力,以及模型对时序动态性与事件驱动型模式的捕获精度。MA-TFT模型架构如图2所示。
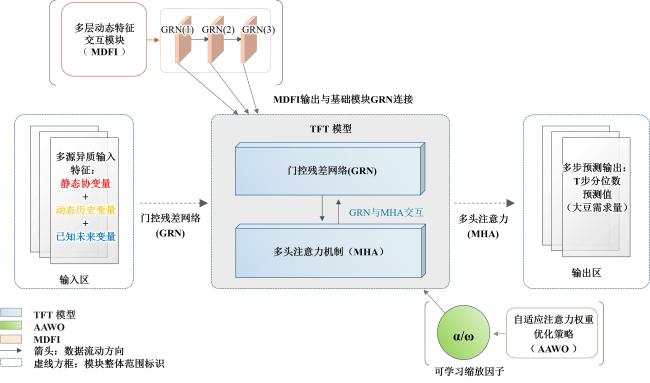
2.2.1 多层动态特征交互
为增强模型对复杂变量间非线性交互关系的建模能力,本研究在TFT原有单层GRN模块的基础上,引入MDFI模块,通过GRN的逐层堆叠,模型可自动生成从二阶(特征交叉)到高阶(如三阶及以上)的特征组合,无须依赖人工设计交互项,充分挖掘“饲料-价格”“政策-供给”等复合驱动关系。残差连接缓解了深层网络梯度消失问题,允许模型在增加层数的同时保持训练稳定性,确保高阶特征交互的有效更新。此外,不同层级GRN可分别学习局部与全局特征表示,底层捕捉短期波动(如月度库存变化),高层整合长期趋势(如年度政策规划),增强模型对多时间尺度规律的解耦能力。处理方法如公式(21) 所示。
式中: 为第 时刻的静态特征嵌入; 为跨维拼接; 为第 层GRN模块输出的特征表示; 为GRN层数。
2.2.2 自适应注意力权重优化
多头注意力机制能够有效捕获农业系统中的复杂时间依赖关系[34]。为了增强模型对关键特征在不同时点的重要性识别,本研究在多头注意力之前加入自适应权重调整因子,使得模型能够依据输入数据的上下文环境,自主强化关键特征的注意力权重,对低信息量特征施加权重惩罚,减少其参与注意力计算的干扰,从而抑制过拟合风险。该策略能够在分析大豆需求预测相关的政策、贸易或气候突变因素时,自主放大或抑制对应特征的注意力分配,从而进一步提升时序模式与事件响应的差异化建模能力。处理方法如公式(22) 所示。
式中: 为自适应调整后的注意力输出; 为自适应权重因子; 为原注意力矩阵; 为上下文时间窗口表示; 为前L步历史隐藏状态; 和 为可训练参数; 为Sigmoid函数。
2.2.3 损失函数
模型的训练目标是最小化预测值与实际值之间的差异。本研究采用多步预测任务中广泛使用的分位数损失函数(Quantile Loss),以捕捉预测区间的不确定性,表达如公式(23) 所示。
式中: 为第 个样本在时刻 的真实值 为预测值; 为分位数(以常用分位数0.1、0.5、0.9分别表示下限、中位和上限预测); 为样本数,个; 为预测步长。
2.2.4 模型训练策略
本研究采用自适应矩估计优化算法(Adam)结合梯度裁剪(Gradient Clipping)作为模型训练策略,旨在提升模型收敛效率并保障训练稳定性。具体而言,Adam优化器通过自适应调整参数学习率,缓解特征稀疏性(如政策突变或极端气候事件)导致的梯度方向偏差问题;梯度裁剪则通过约束梯度范数,抑制大豆需求时序数据中长程依赖和外部协变量(如国际市场波动)引发的梯度爆炸风险。Adam参数更新如公式组(24)所示。
式中: 和 分别为一阶与二阶动量项,分别表示当前梯度与历史梯度的指数加权平均、当前梯度平方与历史梯度平方的指数加权平均; 与 为其衰减率(默认值0.9和0.999); 为损失函数关于参数 的梯度; 与 为偏差修正项; 初始学习率,设为0.001; 为数值稳定性常数,取值1 。在大豆需求预测中,Adam通过动态调整各参数(如库存、价格权重)的更新幅度,有效适应数据中异质性特征(如政策影响的突发性)的差异化学习需求。
梯度裁剪在反向传播过程中对梯度张量进行截断,防止其范数超过预设阈值,数学表达如公式(25) 所示。
式中:C为梯度裁剪阈值,设定为1.0; 为梯度张量。在大豆需求预测中,TFT模型因编码多源数据可能产生高维非平稳梯度,梯度裁剪通过强制约束参数更新步长,避免模型陷入局部震荡或发散,尤其在外生变量(如大豆进口贸易风险)与内生变量(库存时序)高度耦合时显著提升训练稳定性。
2.2.5 贝叶斯超参调优方法
为了在高维超参数空间内快速高效地找到最优超参数组合,本研究采用贝叶斯优化(Bayesian Optimization)方法进行超参数优化。基本流程包括:首先,选择高斯过程(Gaussian Process, GP)作为代理模型,用以估计损失函数空间的分布特征;其次,选择Expected Improvement(EI)作为采集函数,通过预测每次超参数组合对模型表现提升的期望值来指导下一次的采样位置;最后,进行50次迭代,以验证集上的MAPE最小为优化目标。具体通过高斯过程构建代理模型的先验假设与核函数形式,分别如公式(26) 和公式(27) 所示。
式中: 为目标损失函数; , 为高斯过程模型; 为均值函数,反映在所有超参数组合 上模型性能的整体趋势; 为核函数,衡量任意两个超参组合 与x'在输入空间的相似性。本研究选择径向基核函数(RBF Kernel)作为 ; 为核函数的尺度超参数,用于控制核的光滑程度。
2.2.6 模型性能评价指标
为科学严谨地评价模型预测性能,本研究使用均方误差(Mean Squared Error, MSE)、均方根误差(Root Mean Squared Error, RMSE)、平均绝对百分比误差(Mean Absolute Percentage Error, MAPE)和决定系数(Coefficient of Determination, R 2)作为性能评价指标,MSE、RMSE值越小,模型预测越准确;MAPE越小,模型相对误差越小;R 2越接近1,模型整体拟合程度越高。
3 实验设计与结果分析
3.1 实验环境设计
本研究开展的各项实验均在专业高性能计算环境中进行。具体硬件配置为:Intel Core i9-13900K CPU,主频3.0 GHz,搭载64 GB RAM,使用NVIDIA RTX 4090 GPU,显存容量为24 GB。软件环境包括:Ubuntu 22.04操作系统,编程语言为Python 3.10,深度学习框架采用PyTorch 2.1.2(支持CUDA 11.8),并使用scikit-learn 1.3、pandas 2.2、matplotlib 3.8、seaborn 0.12、shap 0.43等工具库。实验的编程和运行平台为PyCharm 2023.3专业版,其中CUDA加速技术主要应用于数据增强处理以及SHAP特征解释力的可视化分析。
3.2 模型训练
本研究利用滚动窗口方式构建模型训练集、验证集与测试集。其中训练集为中国大豆需求分析数据集中的1980—2021年数据,验证集为2022—2023年数据,测试集为2024年数据。模型训练采用分位数损失函数(Quantile Loss)进行优化,以实现对需求预测区间的精准建模。模型在训练过程中使用Early Stopping策略防止过拟合,若验证损失在连续10个epoch内无明显下降则提前终止训练。根据上文提出的模型训练策略提升模型训练稳定性,最终获取的最优超参数组合为:批量大小(Batch Size)设为128,最大训练epoch为100,GRU隐藏层神经元数量为256,嵌入维度(Embedding Dimension)为64,GRU隐藏层数量为2层,初始学习率为0.001,dropout概率为0.2。训练结果表明,该超参数组合在验证集上获得最优的MAPE性能表现。此外,实验对所有模型均进行了5折交叉验证,确保模型性能具有稳健性与可重复性。
3.3 性能对比实验
为评价本研究提出的MA-TFT模型预测性能,分别选取经典时间序列模型ARIMA(1,1,1)、深度学习模型LSTM、TFT以及MA-TFT在同一训练集中开展训练预测,利用验证集实验对比不同模型的预测结果。模型性能对比实验结果如表2所示。
表2 ARIMA(1,1,1)、LSTM、TFT及MA-TFT模型性能对比实验结果Table 2 Experimental results of performance comparison among ARIMA (1,1,1), LSTM, TFT and MA-TFT models |
| 模型类型 | MSE | MAPE/% | R 2 |
|---|---|---|---|
| ARIMA(1,1,1) | 0.135 | 12.80 | 0.72 |
| LSTM | 0.078 | 6.40 | 0.83 |
| TFT | 0.051 | 6.10 | 0.86 |
| MA-TFT | 0.036 | 5.89 | 0.91 |
实验结果显示,不同预测模型的性能存在差异。在MSE、MAPE和R 2这3项评价指标中,MA-TFT模型均展现出最优的预测能力。具体而言,其MSE值为0.036,较基准模型TFT(0.051)、LSTM(0.078)和ARIMA(1,1,1)(0.135)分别降低了29.4%、53.8%和73.3%;在MAPE指标上,MA-TFT以5.89%的误差率优于TFT(6.10%)、LSTM(6.40%)及ARIMA(1,1,1)(12.80%),表明其具有更高的预测精度。此外,MA-TFT的R²达到0.91,高于对比模型TFT(0.86)、LSTM(0.83)、ARIMA(1,1,1)(0.72),验证了该模型对大豆需求相关时间序列变异特征更强的解释力。实验结果表明,改进TFT的MA-TFT模型在复杂时序模式捕捉和长期依赖关系建模方面具有较为明显的优势,能够有效提升预测性能。
3.4 消融实验分析
为了验证MDFI与AAWO策略对MA-TFT模型的协同优化作用,本研究以TFT为基准模型,分别对MDFI与AAWO进行了消融实验,并与MA-TFT预测性能进行对比。实验结果如表3所示。
表3 MA-TFT模型中MDFI与AAWO模块消融实验结果Table 3 Results of ablation experiments on MDFI and AAWO modules in the MA-TFT model |
| 模型类型 | RMSE | MAPE/% | 提升效果/% |
|---|---|---|---|
| TFT | 0.087 | 6.10 | — |
| TFT+MDFI | 0.078 | 6.03 | 1.147 |
| TFT+AAWO | 0.072 | 5.95 | 2.459 |
| MA-TFT | 0.068 | 5.89 | 3.443 |
|
实验结果显示,基准模型TFT的RMSE和MAPE分别为0.087和6.1%。当单独引入MDFI模块后,模型(TFT+MDFI)的RMSE降至0.078(相对降低10.34%),MAPE下降至6.03%,预测性能提升1.147%,表明引入多层动态特征交互有效增强了模型的表征能力。而采用AAWO策略的模型(TFT+AAWO)取得更显著改进,其RMSE(0.072)和MAPE(5.95%)分别较基准模型降低17.24%和2.46%,显示出自适应注意力权重优化对时序特征选择的关键作用。同时集成MDFI与AAWO的完整MA-TFT模型达到最优性能,RMSE(0.068)和MAPE(5.89%)较基准模型累计降低21.84%和3.44%,证实两个模块具有互补性协同效应。消融实验结果充分表明,MDFI通过捕捉多维特征的非线性关系,与AAWO的时序注意力优化机制形成双重驱动,共同提升了模型捕捉特征间复杂关系的能力。4个模型消融实验的预测精度对比及误差对比如图3所示。
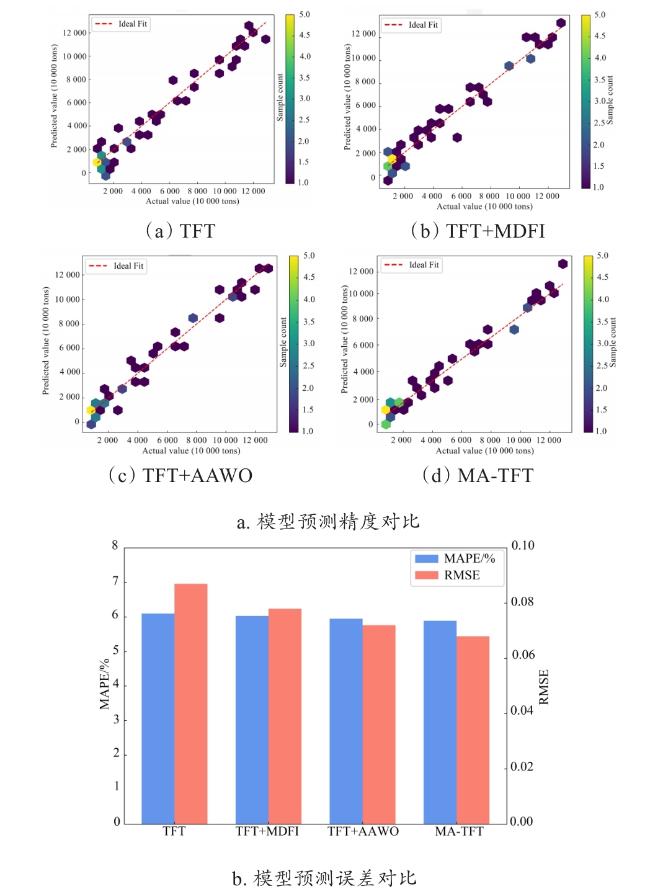
a. 模型预测精度对比
3.5 可解释性分析
为进一步提高MA-TFT模型对中国大豆需求预测结果的可解释性与可信度,本研究采用SHAP对测试集具体分析影响中国大豆需求的关键特征变量。SHAP是一种基于合作博弈论(Cooperative Game Theory)中Shapley值(Shapley Value)的模型解释工具,旨在将机器学习模型的预测结果分解为每个特征的贡献值,实现对模型预测过程的透明化解释。
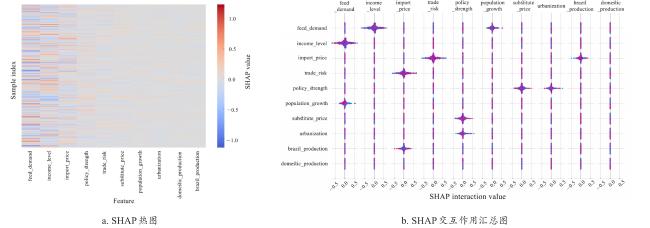
图4展示了影响中国大豆需求的10个关键特征变量,以及各特征变量对MA-TFT模型预测的正负向作用。由图4可见,饲料需求、收入水平构成主导驱动变量,其高特征值(红色密集区,SHAP值>0.5)构成显著正向驱动因子,反映养殖业扩张对豆粕的刚性依赖及收入弹性效应;中国大豆政策力度指数(SHAP值为0.09)、中国大豆进口贸易风险指数(SHAP值为0.06)影响力相对有限;大豆进口价格、中国大豆进口贸易风险指数、替代品价格、巴西大豆产量的特征值增长会抑制大豆需求量增加;特征贡献强度梯度显著(SHAP值域为-1.0~1.0),且主驱动因子分布集中,表明MA-TFT模型对影响大豆需求关键特征变量的解释稳定性较高。
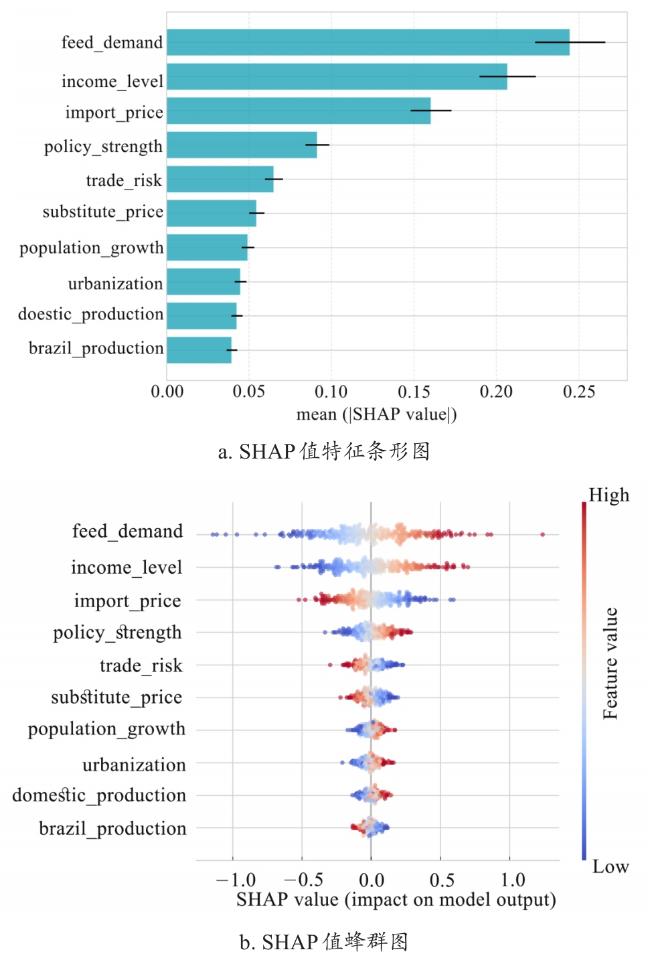
图5揭示了不同样本下影响中国大豆需求的关键特征变量的特征值贡献及其交互效应。饲料需求与收入水平红色叠加,呈现“收入增长(红色)→饲料需求(红蓝交替,正贡献区域与收入红色重叠)→大豆需求增长”的传导路径,形成“消费升级-饲料传导”的需求驱动机制,两者协同增强大豆需求,表明收入提升驱动畜牧业规模化发展,饲料需求刚性增长,直接拉动大豆作为饲料原料的需求;城镇化率与人口增长率虽影响幅度相对较小,但SHAP值正向聚集特征显著,揭示长期结构性因素的作用;大豆进口价格与中国大豆进口贸易风险指数呈负向交互(SHAP值为-0.5),表明大豆进口贸易风险上升时,进口价格波动加剧,企业倾向减少进口或调整库存策略,导致需求对价格的敏感度下降,反映市场不确定性对大豆需求预测的扰动。
3.6 预测结果分析
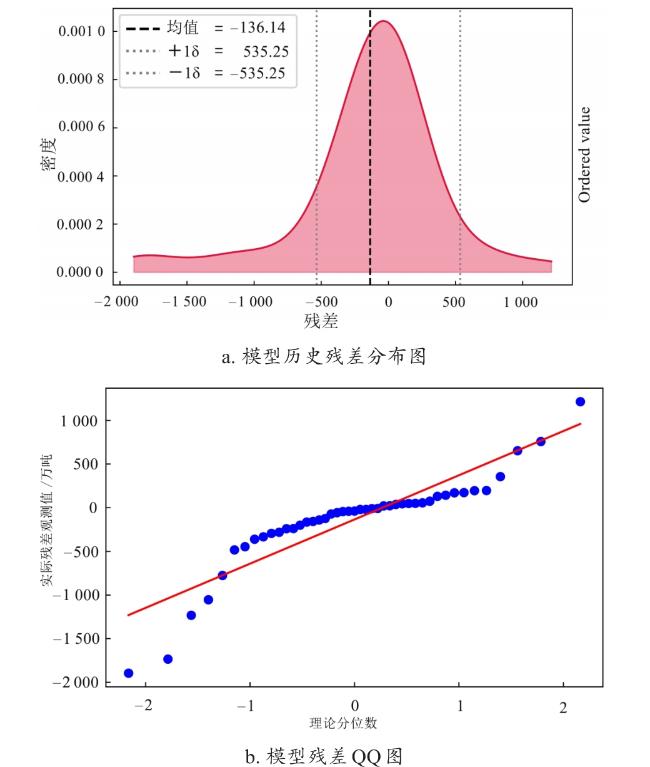
3.6.1 模型预测误差分析
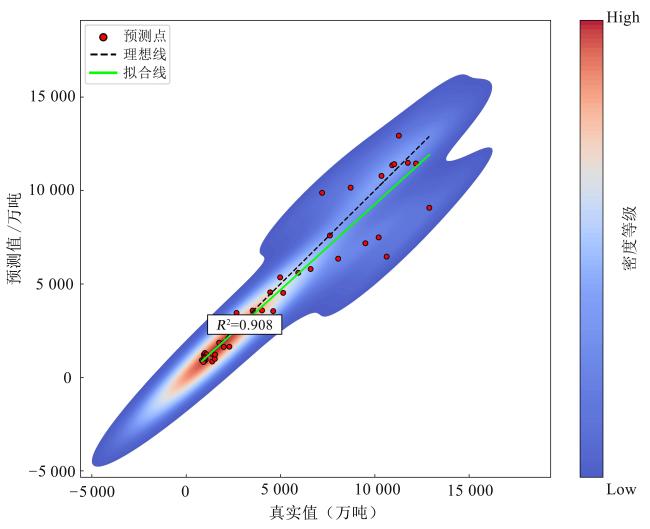
图6 基于MA-TFT模型的中国大豆需求历史预测值与真实值2D密度图Fig. 6 2D density plot of historical predicted values and actual values of China's soybean demand based on the MA-TFT model |
3.6.2 未来10年中国大豆需求预测结果
农业农村部农产品市场分析预警团队每年发布中国农业展望报告,其中分品种供需平衡表具有现实参考价值。本研究利用构建的MA-TFT模型对2025—2034年中国大豆需求量进行了预测,并与《中国农业展望报告(2025—2034)》的预测结果进行了对比,如图8所示。
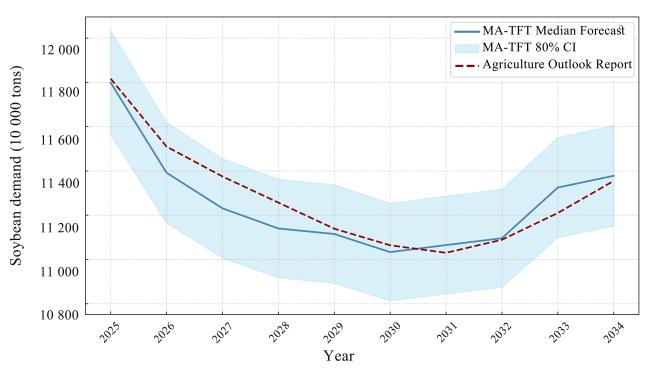
对未来10年中国大豆需求量的预测结果分析可见,当置信水平为80%时,MA-TFT模型与《中国农业展望报告(2025—2034)》预测趋势基本一致,即预测前期需求量总体下降,后期略有回升,基本稳定在1.12亿吨左右。二者年度预测结果存在 的误差,这是因为模型所用数据来源和数据量不同所致。预计2025年中国大豆需求量11 799万吨,2030年需求量11 033万吨,2034年需求量11 378万吨,未来10年年均减少1.0%。
4 结论与展望
本研究将深度学习的TFT模型应用到中国大豆需求预测中,针对TFT特征交互层难以动态捕捉影响大豆需求的突发政策或事件驱动的特征关联变化、多头注意力机制对时间尺度的区分能力较弱的问题,提出了一种基于MDFI与AAWO改进的MA-TFT模型,并在构建的包含1980—2024年4 652个相关指标的中国大豆需求分析数据集上进行了方法的实验和分析,得出以下结论。
1)不同预测模型性能对比实验显示,与ARIMA(1,1,1)、LSTM,以及TFT预测相比,MA-TFT模型的MSE(0.036)、MAPE(5.89%)均显著较低,R 2(0.91)高于对比模型,表明改进的MA-TFT模型能够有效提升预测性能。
2)消融实验显示,分别引入MDFI及AAWO的TFT模型RMSE和MAPE均有所降低,MA-TFT模型的RMSE(0.068)和MAPE(5.89%)较基准模型TFT分别降低21.84%和3.44%,证实两个模块具有协同效应,表明改进的MA-TFT模型能够较好捕捉特征间复杂关系。
3)SHAP工具可解释性分析显示,MA-TFT模型对影响中国大豆需求关键特征变量的解释稳定性较高。
4)对中国大豆需求预测结果显示,MA-TFT模型能够较好地对中国大豆的历史需求量进行拟合和预测,2025—2034年中国大豆需求量总体下降,2025、2030、2034年需求量分别达到11 799万吨、11 033万吨和11 378万吨。
基于改进TFT的中国大豆需求预测方法研究为玉米、小麦等其他农产品的供需预测提供了参考,丰富了农业经济预测领域的方法论体系。尽管MDFI与AAWO分别对MA-TFT模型预测精度均有不同程度提升,但由于两者均作用于特征交互与注意力机制,其改进方向具有一定重叠性,因此组合后整体提升略低于两者加和,这一结果验证了两个改进模块互补性的同时,也为MA-TFT模型未来进一步改进和优化提供了方向。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}