



0 引 言
1 研究方法
1.1 整体框架
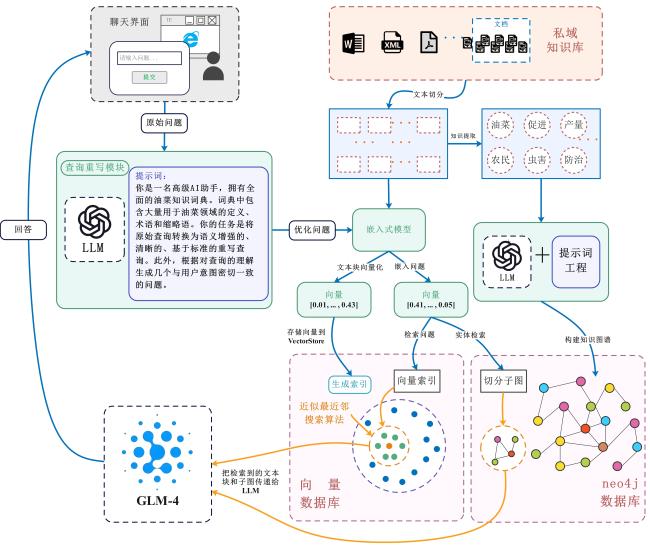
1.2 查询重写模块设计
1.3 双通道知识检索层设计
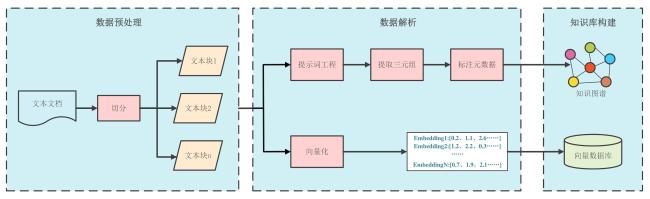
图2 知识图谱构建与文本向量化数据处理流程Fig. 2 Data processing pipeline for knowledge graph construction and text vectorization |
表1 油菜领域实体关系提取提示词设计Table 1 Design of prompt words for entity-relation extraction in rapeseed domain |
| ## 角色 你是知识图谱专家,可以根据用户输入提取三元组。 ## 技能:三元组提取 根据用户输入的要求,结合知识库{油菜育种栽培学}中的文本信息,将知识库中存在的三元组信息全部抽取。三元组信息包括实体(例如:白菜型油菜、菜籽油、蚤跳甲等)、关系(例如:属于、来自、方法等),并严格按照样式输出。 输出结构如下: {"实体":"油菜","关系":"发生病害","病害名称":"根肿病"} {"实体":"油菜根肿病","关系":"防治方法","措施":"轮作"} {"实体":"油菜","关系":"产量影响因素","因素":"土壤酸碱度"} ## 约束 1. 严格按照定义的本体结构抽取三元组 2. 你只负责信息抽取,不需要回答任何问题 |
1.4 知识生成层设计
1.5 实验数据集
表2 油菜知识问答对Table 2 Rapeseed knowledge question and answer pair |
| 问题 | 回答 | 备注 |
|---|---|---|
| 软腐病的主要病症是什么? | 软腐病(Pectobacterium carotovorum)的主要病症是在油菜近地面的茎上呈现水渍状软腐,并伴有恶臭味。该病害主要由细菌通过虫口或植物孔口侵入传播,或由虫体带菌传染。防治措施包括使用药剂防治病昆虫、采用畦栽方式降低田间湿度,以及施用充分腐熟的肥料以避免带入病原体 | 草害 |
| 油菜病毒病的主要传染途径是什么? | 油菜病毒病的主要传染途径是通过蚜虫传病。具体来说,蚜虫大发生往往会引起病毒的流行。此外,芜菁花叶病毒(Turnip mosaic virus, TuMV)是中国油菜区引起油菜病毒病的主要病毒类型,其传播主要依赖于蚜虫的媒介作用。因此,蚜虫是油菜病毒病传播的关键因素 | 草害 |
| 油菜在轮作复种中具有哪些重要作用? | 根据参考内容,油菜在轮作复种中具有以下重要作用:1)培肥地力:油菜能够改善土壤肥力,有助于维持和提升土壤的养分含量;2)改善土壤微生物群落结构:油菜的种植可以促进土壤中有益微生物的生长和多样性,从而优化土壤的生态环境。这些作用使得油菜在农业轮作系统中具有重要的生态和经济价值 | 油菜栽培 |
| 近年来冬油菜种植区域北移的原因是什么? | 近年来冬油菜种植区域北移的主要原因是强抗寒的白菜型冬油菜的选育成功。这一育种突破使得冬油菜能够适应更寒冷的气候条件,从而将其种植范围向北扩展至北纬48°地区。这一进展显著扩大了冬油菜的潜在种植区域,突破了以往的气候限制 | 种植制度 |
1.6 评估指标
1.7 实验设置与对比方法
1.7.1 实验环境
1.7.2 基线方法对比分析
2 实验结果与分析
表3 油菜领域数据集ReG-RAG与5种方法的对比实验结果Table 3 Comparative experimental results of ReG-RAG and five methods on the rapeseed domain dataset |
| RAG方法 | Context_precision | Context_recall | Faithfulness | Answer_relevancy |
|---|---|---|---|---|
| RAG-fusion | 0.800 0 | 0.633 3 | 0.814 3 | 0.970 8 |
| Decomposition | 0.800 0 | 0.700 0 | 0.941 7 | 0.774 0 |
| Step back | 0.650 0 | 0.566 7 | 0.850 0 | 0.960 4 |
| HyDE | 0.812 2 | 0.665 7 | 0.726 3 | 0.934 6 |
| Multi query | 0.790 0 | 0.800 0 | 0.855 0 | 0.968 1 |
| ReG-RAG | 0.904 2 | 0.842 1 | 0.988 6 | 0.986 9 |
表4 WikiEval数据集ReG-RAG与5种方法的对比实验结果Table 4 Comparative experimental results of ReG-RAG and five methods on the WikiEval dataset |
| RAG方法 | Context_precision | Context_recall | Faithfulness | Answer_relevancy |
|---|---|---|---|---|
| RAG-fusion | 0.802 1 | 0.783 3 | 0.915 0 | 0.890 2 |
| Decomposition | 0.810 5 | 0.775 0 | 0.800 0 | 0.902 5 |
| Step back | 0.750 0 | 0.500 0 | 0.763 3 | 0.862 5 |
| HyDE | 0.834 2 | 0.812 5 | 0.874 5 | 0.915 6 |
| Multi query | 0.800 0 | 0.782 3 | 0.925 6 | 0.918 6 |
| ReG-RAG | 0.862 0 | 0.838 7 | 0.969 4 | 0.942 1 |
表5 ReG-RAG、LightRAG与RAG-Fusio问题回复案例对比Table 5 Case comparison of question responses among ReG-RAG, lightRAG, and RAG-Fusion |
| 问题 | ReG-RAG | LightRAG | RAG-Fusion |
|---|---|---|---|
| 哪些类型的油菜种质资源在油菜育种中具有重要价值? | 在油菜育种中具有重要价值的种质资源主要包括以下类型:甘蓝型油菜(Brassica oleracea L.),分布于地中海沿岸及西欧部分地区,是二倍体祖先种之一,栽培与野生资源丰富,广泛用于蔬菜和饲料。白菜型油菜(Brassica campestris L.或Brassica rapa L.),分布最广,可能是最早被驯化的芸薹属物种,早在6 000~7 000年前中国即已利用,油用与蔬用资源丰富。黑芥(Brassica nigra Koch),主要分布于地中海及中亚、中东地区,作为调味品和药物使用,富含优异抗病基因,对抗病育种价值突出。除主要物种外,地方品种在长期驯化过程中形成,如朱砂红、太仓四月黄、织金黑油菜等,表现出早熟、结实性强或果室多等特性。选育品种则通过遗传学原理与技术创制,如波兰春性甘蓝型品种“布诺洛夫斯基”具有低硫苷特性,饲用品种“李霍”含低芥酸基因,成为全球品质育种的重要基因源。这些种质资源为油菜育种提供了丰富的遗传多样性,支撑高产、优质、抗病与抗逆新品种的培育 | 在油菜育种中,具有以下类型的种质资源具有重要价值。1)地方品种:这些品种经过长期选育,适应特定环境和栽培系统,具有独特的遗传特性和适应性。它们对于保持油菜遗传多样性、提高抗逆性和适应性具有重要意义。2)野生种:野生油菜品种携带基因,对疾病和害虫具有抵抗力,是油菜种质创新的关键材料。3)特殊遗传材料:这些材料具有特殊的遗传特性,如抗病性、抗逆性等,对于培育新品种和改良现有品种具有重要价值。4)引进品种:从国外引入的油菜品种可能具有新的遗传特性和适应性,可以丰富油菜种质资源。5)优异种质资源:这些种质资源具有遗传多样性、适应性强等特点,是培育新品种的重要基础。6)种质资源收集保护:通过收集和保护油菜种质资源,可以保存宝贵的遗传信息,为未来的育种工作提供基础 | 在油菜育种中,以下类型的油菜种质资源具有重要价值。白菜型油菜:具有较强的适应性,能在多种土壤和气候条件下生长。生育期短,适合早熟栽培。含油量较高,种子千粒重和含油量均较高。甘蓝型油菜:优质化、杂交化程度高,是当前油菜种植的主要类型。特早熟甘蓝型油菜杂交种的育成和推广,提高了产量和品质。对光照和温度的适应性较强,有利于在不同地区种植。芥菜型油菜:具有较强的抗逆性,如耐旱、耐盐碱等。分枝性强,产量潜力大。种子含油量较高,且蛋白质含量丰富 |
| 跳甲在油菜上主要发生的时间是什么时候? | 跳甲在油菜上主要发生的时间是在油菜苗期,尤其是春油菜受害最重,冬油菜受害相对较轻。具体来说,当油菜初现子叶时,跳甲就可能开始为害,与生长点一起被吃掉,导致幼苗成片枯死。幼虫也会危害幼苗根部,使地上部变黄萎蔫而死。成虫具有驱绿性,在油菜抽薹开花以后,成虫会为害花蕾和幼嫩角果,晚熟品种受害较重。因此,跳甲在油菜苗期至抽薹开花期都可能发生,但以苗期最为严重 | 根据知识库信息,跳甲在油菜上的主要发生时间如下:苗期为主要危害期,跳甲是油菜苗期的重要害虫,特别是春油菜区受害较重,冬油菜区受害相对较轻。当油菜初现子叶时,跳甲就可能开始为害,吃掉子叶和生长点,导致幼苗成片枯死。成虫活动时间在油菜抽薹开花以后,成虫会为害花蕾和幼嫩角果,晚熟品种受害较重春油菜区跳甲成虫活动期通常在春季播种后出苗期间。越冬与防治时间春油菜区常用秋耕、冬凌、深翻、冬灌等措施来消灭越冬成虫或幼虫。播种时采用防虫种衣剂进行种子包衣可以有效预防跳甲危害。虫害发生时需及时进行药剂防治跳甲。1年发生代数因地区而异,寒冷地区较少,温暖地区较多,但其主要危害期集中在油菜苗期,特别是春油菜区的早期生长阶段 | 根据文档内容,跳甲类害虫在油菜上的发生时间如下:黄曲条跳甲以成虫或幼虫形态越冬,主要在春季油菜抽薹开花以后为害。成虫具有驱绿性,在油菜开花期为害花蕾和幼嫩角果,晚熟品种受害较重。油菜蚤跳甲以成虫越冬,1年发生1~2代。主要在春季油菜花蕾期危害,成虫取食花器和产卵于花蕾内为害,形成典型的“秃梗”症状。跳甲类害虫主要以成虫或幼虫越冬,春季是它们的主要危害期,特别是在油菜花蕾期。春油菜区通过秋耕、冬凌、深翻、冬灌等措施可以消灭越冬的跳甲虫态,减少春季虫口基数 |
| 高温胁迫会对油菜的哪些生理过程产生影响? | 根据给定的内容,高温胁迫会对油菜的以下生理过程产生影响。1) 细胞膜系统:高温会导致油菜细胞膜系统被破坏,造成电解质外渗,细胞内大量活性氧积累。2)叶片功能:叶片变黄萎缩、气孔关闭、光合作用减弱。3)水分代谢:严重时会导致植物脱水死亡。4)籽粒发育:当气温达到28 ℃左右时,角果壳光合作用受阻。当日平均气温在24~25 ℃时,籽粒灌浆过程会被中止。5)整体生长:高温胁迫(通常伴随低湿和一定风力的大气干旱现象)会严重影响油菜的正常生长发育。这些影响涵盖了从细胞层面到器官层面再到整体植株的生理过程,包括膜系统稳定性、光合作用、水分平衡以及生殖发育等关键生理功能 | 高温胁迫会对油菜的多个生理过程产生显著的负面影响,主要包括以下几个方面:细胞结构与功能:高温胁迫会导致油菜细胞膜系统被破坏,引起电解质外渗,同时造成细胞内大量活性氧积累。这些变化会严重干扰细胞正常的生理功能,严重时可导致植物脱水死亡。光合作用:高温胁迫会显著影响油菜的光合作用过程,表现为气孔关闭和光合作用减弱。当气温达到28 ℃左右时,角果壳的光合作用会受到阻碍;当日平均气温在24~25 ℃时,籽粒灌浆过程会被中止。生长与发育:在油菜籽粒发育形成期,高温会影响正常的生长和发育过程。研究表明,高温胁迫会导致油菜株高和生物量积累随之降低,影响最终的产量和品质。应对措施:生产上可以通过营造防护林带改善农田小气候,加强农田基本建设,合理布局种植区域,以及适当喷施植物生长调节剂等措施来缓解高温胁迫对油菜的不利影响 | 细胞结构影响:高温会导致油菜细胞膜系统被破坏、电解质外渗、细胞内大量活性氧积累,这些变化直接破坏了细胞的基本结构和功能完整性。光合作用影响:高温胁迫会使叶片变黄萎缩、气孔关闭,进而导致光合作用显著减弱。在油菜籽粒发育形成期,当气温达到28 ℃左右,角果壳的光合作用会受到阻碍,严重影响能量转换效率。灌浆过程影响:当日平均气温达到24~25 ℃时,油菜籽粒灌浆过程会被中止,这直接影响了油菜的产量形成,因为籽粒灌浆是决定最终产量的关键阶段。生长发育影响:严重的高温胁迫会导致植物脱水死亡,使整个植株无法完成正常的生长发育周期,最终导致产量大幅下降。这些生理变化表明,高温胁迫通过破坏细胞结构、抑制光合作用、阻碍籽粒灌浆等多重机制,对油菜的生长发育和产量造成严重影响 |





{kind=link}
{kind=link}
{kind=link}
{kind=link}