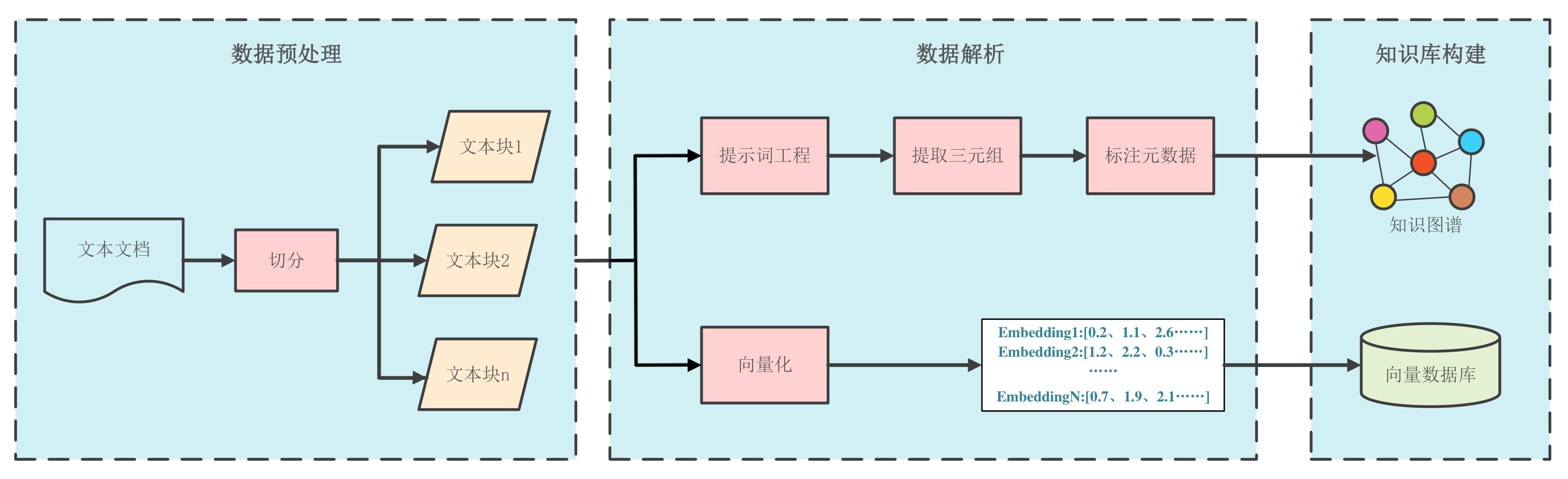
| [1] |
王婷, 王娜, 崔运鹏, 等. 基于人工智能大模型技术的果蔬农技知识智能问答系统[J]. 智慧农业(中英文), 2023, 5(4): 105-116.
|
|
WANG T, WANG N, CUI Y P, et al. Agricultural technology knowledge intelligent question-answering system based on large language model[J]. Smart agriculture, 2023, 5(4): 105-116.
|
| [2] |
殷艳, 尹亮, 张学昆, 等. 我国油菜产业高质量发展现状和对策[J]. 中国农业科技导报, 2021, 23(8): 1-7.
|
|
YIN Y, YIN L, ZHANG X K, et al. Status and countermeasure of the high-quality development of rapeseed industry in China[J]. Journal of agricultural science and technology, 2021, 23(8): 1-7.
|
| [3] |
TZACHOR A, DEVARE M, RICHARDS C, et al. Large language models and agricultural extension services[J]. Nature food, 2023, 4(11): 941-948.
|
| [4] |
CHOWDHERY A, NARANG S, DEVLIN J, et al. PaLM: Scaling language modeling with pathways[J]. Journal of machine learning research, 2023, 24(1): 11324-11436.
|
| [5] |
TOUVRON H, LAVRIL T, IZACARD G, et al. LLaMA: Open and efficient foundation language models[EB/OL]. arXiv: 2302.13971, 2023.
|
| [6] |
OPENAI, ACHIAM J, ADLER S, et al. GPT-4 technical report[EB/OL]. arXiv: 2303.08774, 2023.
|
| [7] |
LEWIS P, PEREZ E, PIKTUS A, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks[EB/OL]. arXiv: 2005.11401, 2020.
|
| [8] |
文森, 钱力, 胡懋地, 等. 基于大语言模型的问答技术研究进展综述[J]. 数据分析与知识发现, 2024, 8(6): 16-29.
|
|
WEN S, QIAN L, HU M D, et al. Review of research progress on question-answering techniques based on large language models[J]. Data analysis and knowledge discovery, 2024, 8(6): 16-29.
|
| [9] |
IZACARD G, GRAVE E. Leveraging passage retrieval with generative models for open domain question answering[EB/OL]. arXiv: 2007.01282, 2020.
|
| [10] |
Guu K, Lee K, Tung Z, et al. Retrieval-Augmented Language Model Pre-Training[C] // Proceedings of the 37th International Conference on Machine Learning. New York, USA: PMLR, 2020: 3929–3938.
|
| [11] |
吴璇, 付涛. 检索增强生成技术研究综述[J/OL]. 计算机工程与应用. (2025-06-11)[2025-06-21].
|
|
WU X, FU T. Comprehensive review of retrieval-augmented generation[J/OL]. Computer engineering and applications. (2025-06-11) [2025-06-21].
|
| [12] |
SONG M Y, ZHENG M. A survey of query optimization in large language models[EB/OL]. arXiv: 2412.17558, 2024.
|
| [13] |
张鹤译, 王鑫, 韩立帆, 等. 大语言模型融合知识图谱的问答系统研究[J]. 计算机科学与探索, 2023, 17(10): 2377-2388.
|
|
ZHANG H Y, WANG X, HAN L F, et al. Research on question answering system of large language model fusion knowledge map[J]. Journal of frontiers of computer science technology, 2023, 17(10): 2377-2388.
|
| [14] |
LIANG L, BO Z P, GUI Z K, et al. KAG: Boosting LLMs in professional domains via knowledge augmented generation[C]// Proceedings of the ACM on Web Conference 2025. New York, USA: ACM, 2025: 334-343.
|
| [15] |
GLM T,:, ZENG A H, et al. ChatGLM: A family of large language models from GLM-130B to GLM-4 all tools[EB/OL]. arXiv: 2406.12793, 2024.
|
| [16] |
RAFFEL C, SHAZEER N, ROBERTS A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of machine learning research, 2020, 21(1): 5485-5551.
|
| [17] |
李冬梅, 罗斯斯, 张小平, 等. 命名实体识别方法研究综述[J]. 计算机科学与探索, 2022, 16(9): 1954-1968.
|
|
LI D M, LUO S S, ZHANG X P, et al. Review on named entity recognition[J]. Journal of frontiers of computer science technology, 2022, 16(9): 1954-1968.
|
| [18] |
GUO Z R, XIA L H, YU Y H, et al. LightRAG: Simple and fast retrieval-augmented generation[EB/OL]. arXiv: 2410.05779, 2024.
|
| [19] |
杨文跃, 于千城, 王启明, 等. 葡萄酒领域知识多路径检索增强生成方法优化研究[J/OL]. 计算机工程与应. (2025-04-17)[2025-06-21].
|
|
YANG W Y, YU Q C, WANG Q M, et al. Optimization research on multi-path retrieval-augmented generation method for wine domain knowledge[J/OL]. Computer engineering and applications. (2025-04-17) [2025-06-21].
|
| [20] |
ES S, JAMES J, ESPINOSA ANKE L, et al. RAGAs: Automated evaluation of retrieval augmented generation[C]// Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations. St. Julians, Malta. Stroudsburg, PA, USA: ACL, 2024: 150-158.
|
| [21] |
DOUZE M, GUZHVA A, DENG C Q, et al. The faiss library[EB/OL]. arXiv: 2401.08281, 2024.
|
| [22] |
Rackauckas Z. RAG-Fusion: a New Take on Retrieval-Augmented Generation[EB/OL]. arXiv: 2402.03367v1, 2024.
|
| [23] |
ZHOU D, SCHÄRLI N, HOU L, et al. Least-to-most prompting enables complex reasoning in large language models[EB/OL]. arXiv: 2205.10625, 2022.
|
| [24] |
ZHENG H S, MISHRA S, CHEN X Y, et al. Take a step back: Evoking reasoning via abstraction in large language models[EB/OL]. arXiv: 2310.06117, 2023.
|
| [25] |
GAO L Y, MA X G, LIN J, et al. Precise zero-shot dense retrieval without relevance labels[C]// Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada. Stroudsburg, PA, USA: ACL, 2023: 1762-1777.
|
 )
)