



0 引 言
大豆是重要的粮食作物,不仅对满足全球日益增长的食物需求至关重要,还对全球经济产生深远的影响[1]。目前,统计数据表明大豆的种植面积约占全球耕地面积的6%,进一步凸显出其在农业生产中的重要地位[2]。然而,随着全球气候变化、土地利用变化等问题的加剧,确保大豆生产的可持续性变得愈发困难[3]。大豆的空间分布和种植状况对于制定有效的农业政策、优化种植结构和提高生产效率至关重要。传统的实地调查方法虽然有效,但其成本高、耗时长、效率低,制约了其在宏观尺度监测中的应用[4]。自20世纪90年代末以来,遥感技术的发展使得大豆种植的监测和制图得到了极大的改善[5]。通过卫星图像、无人机拍摄等遥感手段,可以实现对大豆种植面积和生长状况的实时监测。这些信息不仅可以用于农业管理决策,也可为科研和政策制定提供数据支持。
目前,传统的作物遥感制图方法主要分为3种:阈值法、深度学习法和机器学习法。阈值法利用遥感影像中不同作物在灰度、颜色或其他特征上的差异,通过设定一个或多个阈值来识别目标作物。例如,王利民等[6]基于Rapideye数据构建了棉花特征光谱指数,并以分类精度最大化为依据,确定4 650为最优识别阈值,最终实现了88.80%的总体分类精度和0.75的Kappa系数。Chen等[7]提出了一种结合绿度和水分含量的综合指数,用于大豆种植区识别。通过多次实验验证,最终确定0.17为最佳阈值,基于该指数的大豆识别平均精度为88.30%,Kappa系数为0.77。传统机器学习,如支持向量机(Support Vector Machines, SVM)、随机森林(Random Forest, RF),通过融合多维特征(如红边波段、时序植被指数)提升分类性能。例如,梁继等[8]基于高分六号卫星影像,采用SVM分类算法评估了红边特征对作物分类的影响。研究发现,在不同的样本分割方案下,红边植被指数和红边波段的参与显著提高了作物的识别精度,证实了红边特征在大豆识别中具有重要作用。黄双燕等[9]基于机器学习方法,采用时间序列Sentinel 2A遥感数据提取农作物分类信息,通过引入地块基元和红边特征,探讨不同分类特征组合对机器学习分类精度的影响。结果表明,RF算法集成光谱和植被指数等多维向量可以有效提高农作物分类精度。深度学习方法通过模拟人脑神经网络的多层结构实现对复杂特征的自动提取与组合。这种特性使其在遥感影像分类领域展现出一定优势[10]。在农作物识别方面,屈炀等[11]基于Landsat8 OLI时序数据,计算归一化植被指数(Normalized Difference Vegetation Index, NDVI)、增强型植被指数(Enhanced Vegetation Index, EVI)、比值植被指数(Ratio Vegetation Index, RVI)和三角植被指数(Triangular Vegetation Index, TVI)等植被指数,构建时序特征集,并采用一维卷积神经网络(One-Dimensional Con‐Volutional Neural Networks, 1D-CNN)模型对美国加州帝国郡作物进行分类,最终实现85%以上的总体分类精度。魏永康等[12]考查了飞行高度、特征选择等因素对小麦倒伏无人机遥感分类的影响,发现SVM分类器精度高、泛化性好,Boruta-Shap 优化特征集可降维提效。二者结合能提升分类精度与稳定性,为生产应用提供参考。
阈值法、传统机器学习法和深度学习法在精度、效率与适用性上各具特点,但均存在显著局限性:阈值法因实现简便、计算量小,在早期遥感影像和目标检测任务中被广泛采用,但其阈值设置依赖人为经验,难以适应光谱异质性带来的“同物异谱”与“同谱异物”问题,泛化能力不足[13]。传统机器学习方法(如SVM、RF等)在分类精度和特征利用方面较阈值法更具优势,但需要人工提取特征,训练复杂度较高,并且在跨区域、跨年度数据迁移时稳定性不足[14]。深度学习方法通过端到端的特征自动学习,在高维复杂数据上通常表现出最高的精度,尤其适合大规模遥感与图像识别任务,但模型结构复杂、计算资源需求大,同时存在“黑箱”特性和可解释性不足的问题,因此在实际应用中仍面临一定限制[15]。针对上述问题,本研究提出一种兼顾效率、轻量化设计,以及可解释性的大豆遥感提取方法。二元Logistic模型作为一种经典的机器学习统计分析方法,通过建立自变量与因变量之间的非线性逻辑关系,能够有效分析多个因素对二分类结果的影响程度,已在医学诊断[16]、森林火险评估[17]等领域得到广泛的应用。
美国大豆是全球大豆贸易核心供给来源,其种植面积、产量及生长动态的精准监测,是保障全球粮食贸易稳定、提升市场供需预判能力的关键支撑。二元Logistic模型在二分类任务中分类精度高、解释性强,美国大豆主产区种植集中、田块规整,为遥感作物识别提供理想应用场景。中国是全球最大的大豆进口国,大豆自给能力提升对国家粮食安全意义重大。东北地区是中国大豆种植规模最大、产量最高的核心产区,虽受小农经营模式影响,地块破碎度与美国主产区有差异,但大豆生长核心物候特征、光谱响应规律与美国大豆高度相似,为跨区域技术借鉴提供可行性基础。本研究选取美国大豆主产区6个典型区域(2021—2023年)为对象,通过多时序遥感影像数据处理,系统提取植被指数、波段反射率等光谱特征变量,构建基于二元Logistic模型的高精度大豆遥感识别模型。将该模型应用于上述6个区域2021—2023年大豆种植空间分布制图,验证模型在不同年份、不同地块条件下的适应性与稳定性,为作物遥感制图提供一种透明、轻量且适应性强的技术路径。该方案同时可为中国东北大豆产区遥感识别提供技术参考,通过针对性调整模型参数适配破碎地块场景,有望提升中国东北大豆种植面积监测精度,以期为大豆产业规划、产量预估及粮食安全决策提供科学支撑。
1 研究区概况及数据源
1.1 研究区概况
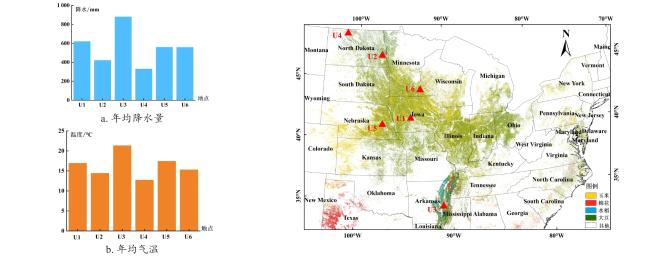
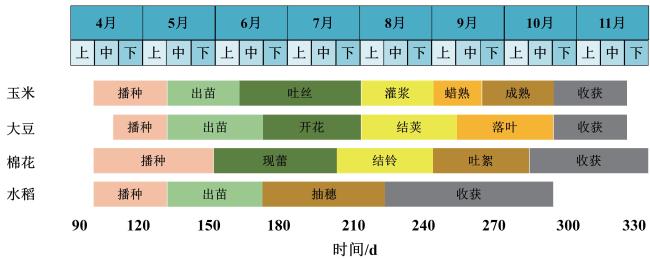
本研究在美国境内选取了6个典型区域作为研究对象:艾奥瓦州的Dallas(U1)、北达科他州的Cass(U2)、阿肯色州的Phillips(U3)、北达科他州的Renville(U4)、内布拉斯加州的Bulter(U5),以及Dodge(U6)。这些样区覆盖美国中西部主要农业带,包含了玉米-大豆轮作、大豆-小麦轮作等多种模式,且涵盖了多种气候类型(图1)。具体而言,U1位于爱荷华州核心农业带,该区域属于湿润大陆性气候,夏季降水充沛,主要实行玉米-大豆轮作制度。U2和U3代表典型大陆性气候区(年降水量356~559 mm),主要种植大豆、春小麦和玉米。U4样区属于温带气候,四季较为分明,年降水量1 220 mm左右,主要作物有大豆、玉米、棉花和水稻等。U5和U6处于半干旱气候带,主要作物有大豆、玉米、高粱和冬小麦。上述样区设置确保了研究样本在气候条件、降水模式、温度特征及种植制度等方面具有充分的代表性和对比性,为后续研究提供了可靠的数据基础。6个典型区域内主要作物物候历如图2所示。
1.2 数据源
1.2.1 Sentinel-2影像
本研究使用了2021—2023年的云量小于10%的大豆最佳识别窗口内的Sentinel-2 L2A级数据,该数据经过辐射定标和大气校正处理,所有影像均从Google Earth Engine(GEE)平台下载。其中,2022年Dallas县的影像用作建模数据,而其他影像作为模型输入直接用于大豆种植区域提取。对于部分区域因影像质量导致的覆盖不全问题,本研究采用最佳时间窗口内的多期影像镶嵌进行处理。各区域使用的具体影像信息详见表1。
表1 2021—2023年构建大豆遥感识别模型在各个地点使用的Sentinel-2数据Table 1 Sentinel-2 data used for soybean remote sensing identification model across various locations from 2021 to 2023 |
| 地点 | 影像日期 | 影像数量/景 |
|---|---|---|
| 2021年8月24日 | 4 | |
| Dallas | 2022年9月13日 | 4 |
| 2023年8月22日 | 4 | |
| 2021年8月23日 | 4 | |
| Cass | 2022年8月30日 | 4 |
| 2023年8月25日 | 4 | |
| 2021年9月7日 | 4 | |
| Phillips | 2022年9月12日 | 4 |
| 2023年8月18日、8月21日 | 6 | |
| 2021年8月16日 | 4 | |
| Renville | 2022年8月14日 | 4 |
| 2023年8月29日 | 4 | |
| 2021年9月6日、9月9日 | 4 | |
| Bulter | 2022年8月30日 | 2 |
| 2023年8月22日、8月30日 | 4 | |
| 2021年9月16日、9月18日 | 8 | |
| Dodge | 2022年9月3日 | 4 |
| 2023年9月1日、9月3日 | 6 |
1.2.2 样本数据
本研究采用的样本数据来自美国农业部(United States Department of Agriculture, USDA)国家农业统计局(National Agricultural Statistics Service,NASS)每年发布的农田数据层(Cropland Data Layer, CDL)。CDL数据自1997年起连续发布,涵盖100多种农作物类型[20]。该数据包含作物类型层、分类置信度层和耕地范围层3个核心数据层。CDL是作物制图研究中的高质量参考数据,广泛应用于各类作物制图研究。
样本数据获取与处理的具体方法如下:基于CDL作物分类数据,首先利用QGIS(Quantum Geographic Information System)的栅格转面工具将大豆、玉米和棉花等主要作物区域转换为矢量面数据。为建立二分类体系,将所有非大豆作物统一归类为“非大豆”类别。在采样过程中,采用分层随机抽样方法分别从大豆种植区和非大豆区域提取样本点,并设置30 m的最小采样间距以确保样本间的空间独立性。样本集按7∶3的比例划分为训练样本和验证样本两部分,前者用于模型构建,后者用于精度验证。2022年本研究在各个地点所使用的样本数量如表2所示,为提高样本质量,所有采样点均通过人工复核,剔除存在明显分类错误的样本。该方法有效保证了样本数据的代表性和可靠性,为后续建模分析奠定了坚实基础。
表2 2022年构建大豆遥感识别模型在各地点所使用的样本数量Table 2 Number of samples used at each location for constructing the soybean remote sensing identification model in 2022 |
| 地点 | 训练样本/个 | 验证样本/个 | ||
|---|---|---|---|---|
| 大豆 | 非大豆 | 大豆 | 非大豆 | |
| Dallas | 10 500 | 15 225 | 4 466 | 6 463 |
| Cass | 48 300 | 62 999 | 20 645 | 26 870 |
| Phillips | 16 612 | 11 550 | 8 919 | 4 916 |
| Renville | 7 800 | 46 199 | 3 271 | 19 629 |
| Bulter | 12 600 | 17 850 | 5 337 | 7 551 |
| Dodge | 9 450 | 15 748 | 3 980 | 6 586 |
2 研究方法
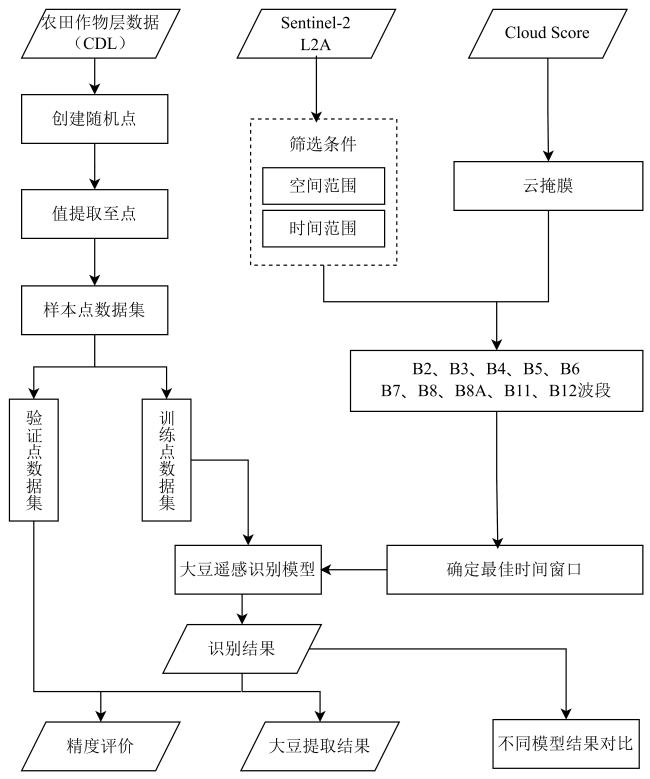
图3为本研究的具体技术流程,主要包括样本数据集制作、大豆识别最佳时间窗口确定、构建大豆遥感识别模型、结果对比及精度评价4个步骤。
2.1 大豆识别最佳时间窗口的确定
大豆和玉米在美国主要种植区的生长周期存在高度重叠,给分类识别带来显著挑战。具体来说,大豆和玉米通常在4月中旬—5月初同期播种,6月底—7月同步进入关键生长期(大豆开花期/玉米拔节期),7—8月经历生殖生长期(大豆结荚期/玉米灌浆期),并于10月同期成熟收获。前人研究表明,大豆结荚期的冠层光谱特征具有显著特异性,是遥感识别的最佳时间窗口[21]。此阶段大豆与玉米的光谱响应形成明显差异。
为了更加细致地确定大豆的最佳识别窗口,本研究基于CDL数据,随机选取多个大豆、玉米、棉花、水稻作物的像元作为样本,利用Google Earth Engine平台绘制了2022年5—10月各个作物的时间序列光谱反射率曲线(图4),同时使用JM(Jffries-Matusita)距离作为定量指标来分析大豆与其他作物在不同特征上的可分性,从而确定大豆识别最佳时间窗口。JM距离的计算如公式(1) 所示。
式中: 和 为两种不同的作物类型; 和 为条件概率密度,即第 、 个像元属于第 、 类别的几率。JM距离的取值范围为0~2,两种作物的光谱差异越大,JM距离的值越大,说明两者的可分性越大。
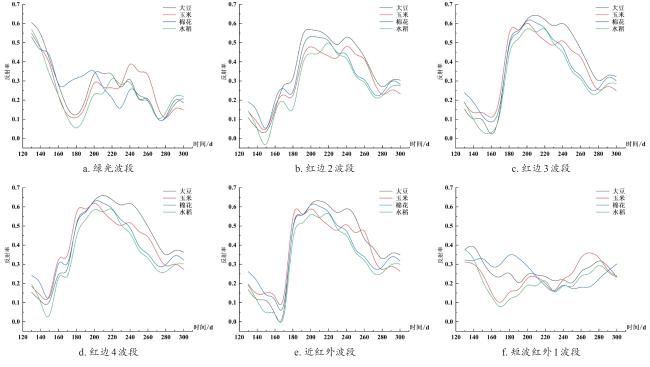
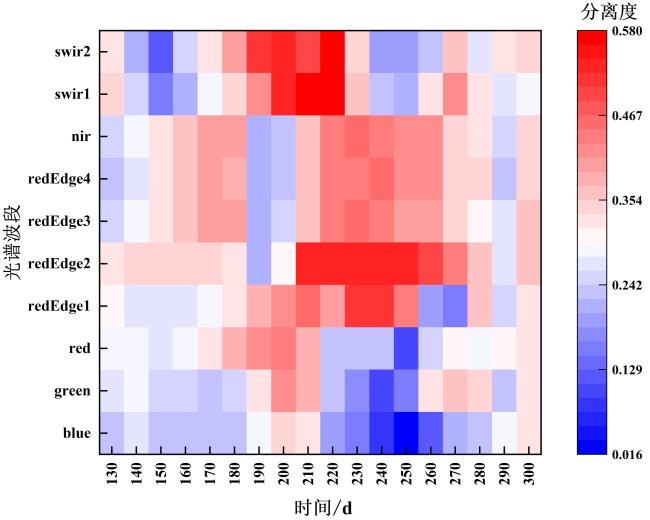
如图4所示,大豆与其他3种作物光谱曲线的主要差异出现在7月中旬—8月下旬左右,大豆和其他同期作物的反射率从180 d开始增加,在210 d时达到峰值,然后开始缓慢下降。在170~210 d,大豆在近红外(图4e)、红边波段(图4b~d)的反射率近似线性持续上升;大豆的反射率在210 d左右达到峰值,此时大豆和同期作物的光谱差异达到最大。大豆在绿色波段(图4a)的200~220 d的反射率高于其他作物的反射率,在RE2(图4b)波段的170~260 d的反射率高于其他作物,在SWIR1波段(图4f)的210~240 d的反射率高于其他作物,在NIR波段(图4e)的210~260 d的反射率高于其他作物。结合前人的研究和作物物候历,大豆与其同期作物的光谱差异在大豆生长季的结荚期(8月上旬—9月上旬左右)达到最大。图5为大豆与其他作物在哨兵2的10个波段下第130~300 d的分离度结果图。由图5可以看出,红边波段、近红外波段和短波红外波段的分离度表现优于其他波段,同时大多数波段在210~260 d的分离度高于其他时间段。基于光谱曲线和JM距离的结果,本研究所选地点第210 d(7月下旬)~第260 d(9月中旬)被确定为将大豆与其他作物分离开的最佳时间窗口。
2.2 Logistic模型
Logistic模型被用于描述二分类变量(因变量为0和1)和1个或多个自变量之间的关系。其表达式如公式(2) 所示。
式中:P(Y=1)为对于给定的 相应个体选择1的概率; 为Logistic累计概率密度函数。 通过Logistic函数被转换为概率。为了将概率与线性关系直接关联,对公式(2) 取对数变换,得到公式(3) 。
式中: 为某个像元属于大豆的概率; 为协变量个数; , ,…, 为各个自变量的Logistic模型相关系数; , ,…, 为自变量。Logistic模型的优势是把[0,1]区间上的概率问题转化为实数轴上一个事件发生的机会。本研究基于2022年Dallas(U1)县的Sentinel-2影像和大豆样本建立大豆遥感识别模型,最后将其推广应用到不同年份及区域。
2.3 精度评价指标
本研究采用用户精度(User's Accuracy, UA)、生产者精度(Producer's Accuracy, PA)、总体精度(Overall Accuracy, OA)和Kappa系数进行大豆分类结果评价。UA表示分类结果中某一类别的像元或样本中有多少是真实属于该类的,反映分类结果的可靠性,即某一类中有多少比例是被正确分类的,体现的是错分情况。PA表示某一个实际地物类别被正确分类的比例,反映分类结果中该类别被识别的完整性,即某一类中有多少比例被正确分出,体现的是漏分情况。OA指正确分类的样本数占总样本数的比例,是衡量整体分类精度的指标。Kappa系数通过比较分类结果与随机分类结果的一致性,衡量分类结果的可靠性。其计算分别如公式(4)~公式(7) 所示。
式中: 为混淆矩阵中第 行第 列的观测值; 、 分别为第 行第 列的边际总和; 为正确分类的像素总数; 等于OA; 为每一类实际样本数和每一类的预测样本数的乘积和与总样本数 的平方的比值。
3 结果与分析
3.1 模型构建结果
本研究通过二元Logistic回归模型,基于Sentinel-2影像的各个波段,构建了大豆种植区识别模型。模型的线性预测值(Logit值)记为Z,其公式如公式(8) 所示。ROC曲线下的面积为0.89,远超过0.50,说明该大豆遥感识别模型的拟合效果较好。模型参数中,x 1、x 2、x 3对应的系数为负(分别是-4.02、-1.91和-1.74),表明在其他波段值不变的情况下,红、绿、蓝这3个波段的值增大,会使得Z值减小,进而降低该区域被识别为大豆种植区域的概率。x 4~x 10对应的系数为正,这些变量对应的波段分别为红边、近红外和短波红外。上述波段特征与大豆的光谱特征相关性较强,在大豆种植区域识别中起到关键作用。
式中:xi 为Sentinel-2的各个波段(不包括B1和B8A波段)。
为了更好地评估上述构建的大豆遥感识别模型的有效性及其分类的优势,本研究在美国大豆主产区的6个区域进行了为期3年(2021—2023年)的大豆分类制图实验,并将最终的实验结果与SVM的分类结果和CDL进行比较。
3.2 大豆分类结果
2022年大豆制图结果分布图如图6所示,可以看出,在U1、U5和U6等典型农业区,本研究构建的模型可以准确识别出大面积连续分布的大豆田;在U2和U3等受人类活动干扰较强的区域,该模型也有效捕捉了因居民地、道路分割导致的不规则分布特征;对于U4大豆种植比例较低的区域,该模型同样可以准确识别零散分布的田块。相比SVM的分类结果,大豆遥感识别模型的结果与CDL呈现更高的一致性。
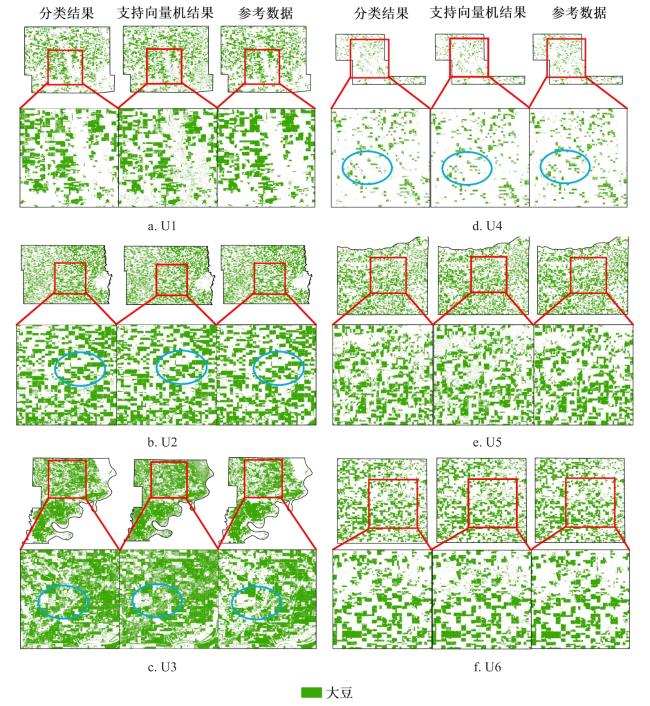
表3为2022年各个地点的混淆矩阵,根据混淆矩阵可以看出,本研究所构建的分类模型在大豆识别方面总体表现较为优越,但在不同区域间仍呈现一定差异性。多数区域中,大豆类别的生产者精度与用户精度均保持在较高水平,表明模型具备较强的大豆识别能力。然而,U4与U5区域的大豆识别存在不同程度的漏分和过度预测现象,这可能与这些区域大豆与其他作物的光谱或空间特征相似性较高有关。相较而言,U6区域表现最佳,大豆与非大豆类别的分类精度均较高,且Kappa系数在所有区域中最高,说明该区域的分类结果与真实情况具有较好的一致性,模型在此区域的稳定性和可靠性更强。总体而言,模型在大豆识别上具有较高潜力。
表3 2022年各个地点大豆遥感识别模型结果的混淆矩阵Table 3 Confusion matrix for soybean remote sensing identification models across locations in 2022 |
| 地点 | 类别 | 非大豆 | 大豆 | 总量 | 用户精度 |
|---|---|---|---|---|---|
| U1 | 非大豆 | 6 081 | 680 | 6 761 | 0.89 |
| 大豆 | 382 | 3 786 | 4 168 | 0.90 | |
| 总量 | 6 463 | 4 466 | 10 929 | — | |
| 生产者精度 | 0.94 | 0.85 | — | — | |
| 总体精度 | 0.90 | ||||
| Kappa | 0.79 | ||||
| U2 | 非大豆 | 24 751 | 2 887 | 27 638 | 0.89 |
| 大豆 | 2 119 | 17 758 | 19 877 | 0.89 | |
| 总量 | 26 870 | 20 645 | 47 515 | — | |
| 生产者精度 | 0.92 | 0.86 | — | — | |
| 总体精度 | 0.89 | ||||
| Kappa | 0.78 | ||||
| U3 | 非大豆 | 3 775 | 1 901 | 5 676 | 0.66 |
| 大豆 | 1 141 | 7 018 | 8 159 | 0.86 | |
| 总量 | 4 916 | 8 919 | 13 835 | — | |
| 生产者精度 | 0.76 | 0.78 | — | — | |
| 总体精度 | 0.78 | ||||
| Kappa | 0.70 | ||||
| U4 | 非大豆 | 19 087 | 933 | 20 020 | 0.95 |
| 大豆 | 542 | 2 338 | 2 880 | 0.81 | |
| 总量 | 19 629 | 3 271 | 22 900 | — | |
| 生产者精度 | 0.97 | 0.71 | — | — | |
| 总体精度 | 0.93 | ||||
| Kappa | 0.72 | ||||
| U5 | 非大豆 | 6 868 | 947 | 7 815 | 0.87 |
| 大豆 | 683 | 4 390 | 5 073 | 0.86 | |
| 总量 | 7 551 | 5 337 | 12 888 | — | |
| 生产者精度 | 0.90 | 0.82 | — | — | |
| 总体精度 | 0.87 | ||||
| Kappa | 0.73 | ||||
| U6 | 非大豆 | 6 202 | 326 | 6 528 | 0.95 |
| 大豆 | 384 | 3 654 | 4 038 | 0.90 | |
| 总量 | 6 586 | 3 980 | 10 566 | — | |
| 生产者精度 | 0.94 | 0.91 | — | — | |
| 总体精度 | 0.93 | ||||
| Kappa | 0.85 | ||||
|
局部放大对比进一步表明,尽管大豆遥感识别模型的结果在田块边缘等复杂区域(如蓝色圆圈标示处)存在少量错分现象,但识别结果与CDL在空间分布格局上保持高度一致。定量分析表明,大豆遥感识别模型在U1~U6区域的总体精度分别为0.90、0.89、0.78、0.93、0.87和0.93,Kappa系数分别为0.79、0.78、0.70、0.72、0.73和0.85;2022年所有区域的平均精度和平均Kappa分别为0.88和0.76,SVM的结果在U1~U6区域的总体精度分别为0.89、0.85、0.76、0.90、0.82、0.89,Kappa系数分别为0.78、0.70、0.50、0.62、0.62、0.77,2022年大豆遥感识别模型的平均总体精度和平均Kappa系数分别比SVM的结果高0.03和0.1,大豆遥感识别模型在所有区域的表现都优于SVM。以上结果充分证明了二元Logistic模型在大豆种植区提取中具有较好的适应性和可靠性,能够有效处理不同景观格局下的分类任务。
3.3 模型多年稳定性和可移植性测试结果
为了更好地评估大豆遥感识别模型在多年间的性能,本研究基于验证样本和模型识别结果构建混淆矩阵,对2021—2023年6个研究区的大豆识别精度进行了系统评估。表4和表5分别为2021年和2023年各个区域的混淆矩阵,综合2021年和2023年的混淆矩阵结果来看,本研究所使用的模型在整体上均表现出较高的精度与可靠性,大多数区域的生产者精度和用户精度均在0.85以上,说明大豆与非大豆的识别总体准确。但在两个年份中均存在区域间差异:部分区域(2023年的U2、U3、U5)分类精度偏低,尤其是在大豆类别上存在一定的漏分与误判,导致Kappa系数相对较低;而其他区域(如2021年大部分地区及2023年的U1、U4、U6)分类结果表现稳定,精度和一致性均较高。
表4 2021年大豆遥感识别模型结果的混淆矩阵Table 4 Confusion matrix for soybean remote sensing identification models in 2021 |
| 地点 | 类别 | 非大豆 | 大豆 | 总量 | 用户精度 |
|---|---|---|---|---|---|
| U1 | 非大豆 | 4 082 | 572 | 4 654 | 0.87 |
| 大豆 | 412 | 3 921 | 4 333 | 0.90 | |
| 总量 | 4 494 | 4 493 | 8 987 | — | |
| 生产者精度 | 0.90 | 0.87 | — | — | |
| 总体精度 | 0.89 | ||||
| Kappa | 0.78 | ||||
| U2 | 非大豆 | 19 609 | 2 992 | 22 601 | 0.86 |
| 大豆 | 2 891 | 17 258 | 20 149 | 0.85 | |
| 总量 | 22 500 | 20 250 | 42 750 | — | |
| 生产者精度 | 0.87 | 0.85 | — | — | |
| 总体精度 | 0.86 | ||||
| Kappa | 0.72 | ||||
| U3 | 非大豆 | 3 548 | 1 234 | 4 782 | 0.74 |
| 大豆 | 947 | 6 387 | 7 334 | 0.87 | |
| 总量 | 4 495 | 7 621 | 12 116 | — | |
| 生产者精度 | 0.78 | 0.83 | — | — | |
| 总体精度 | 0.82 | ||||
| Kappa | 0.68 | ||||
| U4 | 非大豆 | 21 856 | 1 436 | 23 292 | 0.93 |
| 大豆 | 2 444 | 12 064 | 14 508 | 0.83 | |
| 总量 | 24 300 | 13 500 | 37 800 | — | |
| 生产者精度 | 0.89 | 0.89 | — | — | |
| 总体精度 | 0.89 | ||||
| Kappa | 0.78 | ||||
| U5 | 非大豆 | 7 026 | 744 | 7 770 | 0.90 |
| 大豆 | 522 | 4 597 | 5 119 | 0.89 | |
| 总量 | 7 548 | 5 341 | 12 889 | — | |
| 生产者精度 | 0.93 | 0.86 | — | — | |
| 总体精度 | 0.90 | ||||
| Kappa | 0.79 | ||||
| U6 | 非大豆 | 5 372 | 451 | 5 823 | 0.92 |
| 大豆 | 276 | 3 910 | 4 186 | 0.93 | |
| 总量 | 5 648 | 4 361 | 10 009 | — | |
| 生产者精度 | 0.95 | 0.89 | — | — | |
| 总体精度 | 0.92 | ||||
| Kappa | 0.85 | ||||
|
表5 2023年大豆遥感识别模型的混淆矩阵Table 5 Confusion matrix for soybean remote sensing identification models in 2023 |
| 地点 | 类别 | 非大豆 | 大豆 | 总量 | 用户精度 |
|---|---|---|---|---|---|
| U1 | 非大豆 | 5 525 | 367 | 5 892 | 0.93 |
| 大豆 | 260 | 3 957 | 4 217 | 0.93 | |
| 总量 | 5 785 | 4 324 | 10 109 | — | |
| 生产者精度 | 0.95 | 0.91 | — | — | |
| 总体精度 | 0.93 | ||||
| Kappa | 0.87 | ||||
| U2 | 非大豆 | 20 954 | 3 204 | 24 158 | 0.86 |
| 大豆 | 2 806 | 16 099 | 18 905 | 0.85 | |
| 总量 | 23 760 | 19 303 | 43 063 | — | |
| 生产者精度 | 0.88 | 0.83 | — | — | |
| 总体精度 | 0.86 | ||||
| Kappa | 0.71 | ||||
| U3 | 非大豆 | 3 348 | 1 203 | 4 551 | 0.73 |
| 大豆 | 1 116 | 5 927 | 7 043 | 0.84 | |
| 总量 | 4 464 | 7 130 | 11 594 | — | |
| 生产者精度 | 0.75 | 0.83 | — | — | |
| 总体精度 | 0.80 | ||||
| Kappa | 0.71 | ||||
| U4 | 非大豆 | 15 932 | 1 516 | 17 448 | 0.91 |
| 大豆 | 1 022 | 2 269 | 3 291 | 0.68 | |
| 总量 | 16 954 | 3 785 | 20 739 | — | |
| 生产者精度 | 0.93 | 0.59 | — | — | |
| 总体精度 | 0.87 | ||||
| Kappa | 0.76 | ||||
| U5 | 非大豆 | 6 405 | 914 | 7 319 | 0.87 |
| 大豆 | 701 | 3 990 | 4 691 | 0.85 | |
| 总量 | 7 106 | 4 904 | 12 010 | — | |
| 生产者精度 | 0.90 | 0.81 | — | — | |
| 总体精度 | 0.86 | ||||
| Kappa | 0.77 | ||||
| U6 | 非大豆 | 5 358 | 534 | 5 892 | 0.90 |
| 大豆 | 397 | 3 142 | 3 539 | 0.88 | |
| 总量 | 5 755 | 3 676 | 9 431 | — | |
| 生产者精度 | 0.93 | 0.85 | — | — | |
| 总体精度 | 0.89 | ||||
| Kappa | 0.79 | ||||
|
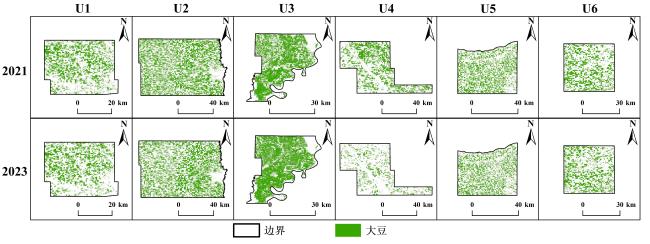
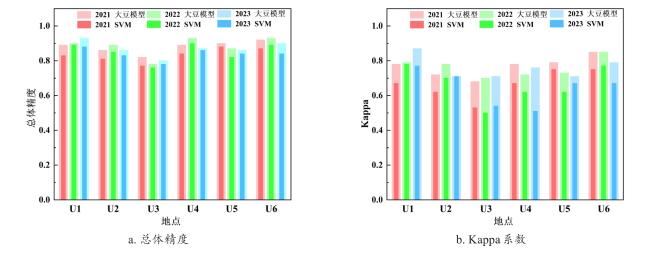
图7为2021年和2023年大豆识别模型的制图结果。图8为2021—2023年大豆识别模型和SVM的总体精度、Kappa系数对比。制图结果表明,2021年大豆遥感识别模型的结果在各区域Kappa系数为0.68~0.85(U1=0.78、U2=0.72、U3=0.68、U4=0.78、U5=0.79、U6=0.85),总体精度为0.82~0.92(U1=0.89、U2=0.86、U3=0.82、U4=0.89、U5=0.90、U6=0.92);2022年模型在各区域Kappa系数为0.70~0.85(U1=0.79、U2=0.78、U3=0.70、U4=0.72、U5=0.73、U6=0.85),总体精度为0.78~0.93(U1=0.90、U2=0.89、U3=0.78、U4=0.93、U5=0.87、U6=0.93);2023年模型在各区域Kappa系数为0.71~0.87(U1=0.87、U2=0.71、U3=0.71、U4=0.76、U5=0.77、U6=0.79),总体精度为0.80~0.93(U1=0.93、U2=0.86、U3=0.80、U4=0.87、U5=0.86、U6=0.89)(图7)。2021—2023年大豆遥感识别模型和SVM的总体精度和Kappa系数对比显示,大豆遥感识别模型的准确性在多个年份相对稳定,具体来看,模型结果在2021—2023年的平均总体精度为0.87(>0.85),平均Kappa系数为0.76(为0.68~0.85)。SVM的结果在2021—2023年的平均总体精度为0.84,平均Kappa为0.65,相较而言,大豆遥感识别模型的平均精度更高,同时大豆遥感识别模型的总体精度和Kappa系数的标准差更小,充分说明其在年际间的稳定性更强。
4 讨论与结论
4.1 讨论
本研究使用Sentinel-2影像,通过大豆光谱时间序列曲线确定大豆识别最佳时间窗口,通过构建遥感大豆识别模型,对美国大豆主产区的6个典型区域的大豆田进行了识别。结果表明,大豆田识别的最佳时间窗口为一年中的210~260 d,遥感大豆识别模型在跨区域和跨年度应用中均表现出良好的稳定性和可移植性。该模型优势主要体现在3个方面:一是轻量化设计优势显著,仅依赖少量参数(模型系数)的优化即可实现跨区域和跨年度的快速应用,显著降低了对大规模训练样本和复杂计算的依赖,计算效率显著高于机器学习方法。二是物理可解释性极强,各光谱波段的贡献度可量化解释。模型的判别依据建立在大豆生育期光谱特征的物理机理之上,各光谱波段在不同生长期的反射率可通过数值大小清晰量化解析,使模型的分类过程具有明确的物理意义和透明性,这不仅有助于理解模型的判别逻辑,也为后续在其他作物识别或多源数据融合中的应用提供了理论支撑。本研究所构建的模型系数的正负和大小反映了对应光谱波段对大豆遥感识别的贡献度,红、绿、蓝波段对应的系数分别为-4.02、-1.91、-1.74,说明这3个波段对大豆遥感识别的贡献度为负,这些波段的反射值越大,反而不利于大豆种植区的识别。其余波段对应的系数为正,当其他波段值不变时,这些波段的反射值增大可以使区域被识别为大豆种植区的概率上升。三是二分类场景性能优异,对于“大豆/非大豆”这种明确的二分类场景,其性能与复杂模型相当。
4.2 结论
本研究通过Google Earth Engine中的Sentinel-2卫星影像,构建了大豆种植区遥感识别模型,系统评估了该模型在美国主要大豆产区的应用效果。研究结果表明,基于光谱时间序列曲线和JM距离确定的大豆关键生长期(210~260 d)能有效捕捉大豆冠层的光谱特征变化,为遥感识别提供了最佳时间窗口。模型在6个典型区域的验证结果显示,2022年在U2~U6区域及模型构建的U1区域均表现出较高的Kappa值和精度,在其余年份也具有良好的精度表现,其在2021—2023年具有较好的空间适应性(Kappa系数为0.68~0.85)和时间稳定性(3年平均OA>0.85),证实了该模型在作物二分类问题中的实用价值。本研究建立的方法体系为农业遥感监测提供了一种高效、可解释的技术方案。
虽然本研究取得了较好的效果,但也存在一定的局限性。首先,从数据层面来说,考虑本次研究使用的Sentinel-2遥感影像的分辨率和光谱特征数量的限制,一个像元可能包含不同种作物类别,难以识别混合像元的真实类别,从而导致“椒盐现象”和边界模糊。此外,在样本选择上,由于CDL数据本身精度的影响,以及缺少实测数据的支持,在一定程度上影响了分类样本的准确性。最后,从模型层面来说,本研究建立的大豆识别模型基于像元独立预测,忽略了地块的空间连续性(如农田边界、种植结构)和领域关系(如相邻地块作物类型的合理性),容易产生孤立噪点。同时模型仅在美国中西部主要农业带进行了验证,该区域在气候条件、田块规模和种植制度方面具有一定代表性,但并不能涵盖全球大豆主产区的多样性背景。不同区域在气候带、土壤类型、遥感观测条件,以及大豆与其他作物的光谱差异方面可能存在差异,这些因素都会对模型的识别精度和适用性产生影响。因此,未来的工作可通过在不同气候区和种植体系中进行跨区域验证,或结合迁移学习与域适应方法提高模型在多区域条件下的鲁棒性,从而进一步提升其在全球尺度上的推广潜力。同时可考虑融合Sentinel-1 SAR数据提升多云地区监测能力,引入面向对象分类方法改善边界精度,结合U-Net等深度学习模型实现端到端的特征学习。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}