



0 引 言
辣椒是世界上发展前景良好的重要经济作物,可作为食用蔬菜,也可制成辣酱和其他食物的调味品。由于全球气温持续上升,高温高湿的气候条件对辣椒种植构成了严峻挑战。在这种条件下,蓟马容易暴发,且被蓟马啃食的叶片也容易被辣椒花叶病毒与黄单胞杆菌属的细菌入侵,最后导致叶片黄化并生成病斑,这些病害会导致辣椒叶片早衰脱落,显著影响辣椒的商品品质,甚至造成植株成片枯死、产量下降[1]。细菌性叶斑病与烟草花叶病毒引起的叶片黄化病在田间环境下容易混淆,识别困难。因此,及时准确地检测染病的辣椒植株对于提高辣椒产量和质量、控制农药的使用量和成本具有重要意义。
基于传统机器学习的方法通常依赖人工特征提取操作,需从叶片图像中提取颜色、纹理、形状等关键特征,再借助支持向量机(Support Vector Machine, SVM)、随机森林或K近邻等分类器实现病害识别[5]。针对柑橘病虫害检测问题,SHARIF等[6]提出的多SVM集成分类模型表现出色,识别准确率可达97%,优于传统方法。EBRAHIMI等[7]提出了一种结合移动机器人与SVM算法的智能检测方案,适用于温室草莓病虫害的识别任务。然而,传统机器学习方法存在明显的局限性:其一,特征提取工程高度依赖人工经验与先验知识,无法实现端到端的特征自动学习;其二,手工设计的特征表达能力有限,难以有效表征叶片病虫害在植株不同生长阶段的细微病理变化。此外,在辣椒叶片病虫害的实际识别中,人工方式也面临准确率与效率的双重挑战:识别方面,相似病症易混淆;效率方面,单人日均检测量仅500株,与规模化基地(如10万株/地块)的检测需求严重不匹配。
深度学习技术以人工神经网络[8]为理论基础,其层次化的网络结构能够对文本、音频和图像等多源数据进行多尺度特征提取,通过从低阶感知特征到高阶语义特征的渐进式学习,展现出优异的表征学习能力,在目标检测领域得到了广泛应用。石天怡等[9]针对传统苹果叶片病害分类方法精准性差的问题,提出一种基于改进ConvNeXt的苹果叶片分类算法CALDNet,识别叶片病害的精确率与原始ConvNeXt模型相比提高了4.63%。魏天宇等[10]融合双向特征金字塔网络,改进YOLOv5s的深层特征融合架构,提升检测精度,算法模型能够在白天强光、傍晚弱光的环境下提高对辣椒的检测精度。王震鲁等[11]提出一种基于改进YOLOv5辣椒目标检测模型,该模型能够有效识别被遮挡的辣椒,平均检测准确率达到91%。邹玮和岳延滨团队[12]创新性地将YOLOv2检测框架与ResNet50深度卷积网络相融合,开发了一种新型混合模型,可实现辣椒叶片蚜虫的高效分类与精确定位,系统的识别准确率高达96.49%。李佳松等[13]提出一种C-ResNet-50算法模型以改善在复杂自然背景下对马铃薯叶片病虫害的识别效果,识别马铃薯叶片病虫害的平均准确率达90.83%,较原始模型提升了1.84%。对比邹玮等[12](YOLOv2 模型,样本量2 619 张)、李佳松等[13](C-ResNet-50,样本量1 080张),本研究数据集规模是同类研究的2~4倍,样本代表性更强。
现有研究虽然在模型架构和检测方法方面取得了一定进展,但存在两个关键局限性。首先,这些方法未能充分考虑边缘设备的计算资源约束。其次,基于深度学习的辣椒叶片病害与虫害检测仍面临若干技术挑战,具体表现为:1)特征提取不充分。由于辣椒叶片病虫害在形态学和色彩学上具有高度多样性,加之复杂的自然环境下光照变化、叶片遮挡及背景噪声等因素的干扰,使得现有模型难以获取充分且鲁棒的特征表示,容易忽视目标物体的边缘信息,亟需开发更具判别力的深层细粒度特征提取方法。2)较小的辣椒叶片病斑不容易被检测。叶片病斑形状较小容易受作物生长的复杂环境干扰,在算法模型的训练过程中容易忽略对小目标提取的重要性,以及复杂的自然环境导致错误检测的异常样本对模型的影响。
YOLOv12相比YOLOv5与YOLOv2来说具有更高的检测精度、更快的推理速度与更强的泛化能力,因此本研究在YOLOv12s的基础上进行改进,提出辣椒叶片病害与虫害轻量化检测算法,保证一定检测精度的情况下,缩小模型以便部署在算力紧张的设备上。将YOLOv12s的骨干网络替换为改进的MobileNetV4,该网络采用轻量级架构设计,进一步优化参数量,在保持精度的同时显著降低每秒浮点运算次数(Floating Point Operations per Second, FLOPs),适合资源受限的设备。为解决关键特征(边缘、小病灶)提取精度不足,模型易忽略目标边缘信息,以及模型对小目标物体特征的忽略问题,提出了多维频域互补注意力机制模块,该模块能够抑制无关信息,同时能提取局部和全局特征以提高检测精度,增强网络多尺度特征融合的能力。最后,提出残差聚合门控卷积模块,该模块通过多个高阶空间交互,捕捉特征之间的复杂关系,从而增强特征融合的效果。
上述改进使模型在精度与理论计算量上取得了良好平衡。但核心问题是理论上的轻量化是否等同于部署上的高效率。为回答这一问题,并验证本模型在真实农业场景中的部署效率,本研究还进行了算法部署实验。
1 实验材料
1.1 辣椒叶片病虫害数据采集
数据采集地点为甘肃省天水市甘谷县辣椒种植核心区(新兴镇康家滩村、安远镇王马村和大像山镇杨场村),覆盖3个典型种植地块,土壤类型为黄绵土,种植方式为露地垄作;辣椒品种为当地主栽品种“甘谷尖辣椒”(Capsicum annuum L. var. conoides(Mill.)Irish),3月份到5月份,辣椒植株处于以营养生长为主的时期,同时也是病害高发期;采集日期为2024年3月15日—5月20日,每日采集时段为9∶00—11∶00(光照强度5 000~8 000 lux,避免晨露)、15∶00—17∶00(光照强度6 000~9 000 lux,避免强光过曝);采集设备为小米14 Pro手机,后置主摄5 000万像素,焦距50 mm,光圈f/1.7,手动对焦至叶片表面,分辨率像素为4 000×3 000。采集到的叶片种类如图1所示,图1a为被蓟马侵染的叶片、图1b为烟草花叶病毒黄化病叶片、图1c为健康叶片、图1d为细菌性叶斑病叶片。

1.2 辣椒叶片病虫害数据集构建

表1 辣椒叶片病虫害数据集Table 1 Dataset of leaf diseases and pests of peppers |
| 辣椒叶片病虫害类别 | 训练集样本数量/张 | 测试集样本数量/张 | 验证集样本数量/张 | 样本总数量/张 |
|---|---|---|---|---|
| 健康叶片 | 2 193 | 95 | 223 | 2 511 |
| 细菌性叶斑病叶片 | 2 283 | 96 | 186 | 2 565 |
| 烟草花叶病毒黄化花叶病叶片 | 2 076 | 102 | 175 | 2 353 |
| 被蓟马侵染叶片 | 2 127 | 129 | 232 | 2 488 |
为解决训练集样本量不足导致的模型泛化能力弱,以及部分病害类别样本分布不均导致的模型偏向性问题,对原始训练集进行数据增强与数据平衡处理[14],具体策略如下。
采用5类针对性数据增强方法扩充训练集,所有增强操作仅作用于训练集,验证集与测试集保持原始状态以确保评估客观性,具体参数设置如下。
① 随机旋转。旋转角度范围0°~360°,旋转步长15°,应用概率0.8。
② 缩放变换。缩放比例范围0.8~1.2倍,应用概率 0.7。
③ 水平翻转。沿图像水平中轴线翻转,应用概率 0.5。
④ 高斯噪声。添加方差为0.01的高斯噪声,模拟自然环境下的图像噪声干扰,应用概率0.3。
⑤ 亮度调整。亮度系数范围0.7~1.3倍,应用概率 0.6。
通过上述增强策略,训练集样本总量从原始的 8 679张扩充至17 358 张,有效丰富了样本的形态、光照与噪声多样性,降低模型过拟合风险。
从表1可知,原始训练集中烟草花叶病毒黄化病(Mosaic)类别样本量最少(2 076张),与样本量最多的细菌性叶斑病(Xanthomonas)2 283张相差207张,类别间样本差异可能导致模型对小众类别的检测精度偏低。为解决该问题,本研究采用“过采样+合成少数类过采样技术(Synthetic Minority Over-sampling Technique, SMOTE)”的组合策略平衡数据:对Mosaic类原始样本进行随机过采样,补充100张重复样本;基于SMOTE,通过计算Mosaic类样本的特征相似度,合成124张新样本,确保合成样本与原始样本特征分布一致。
处理后,各类别训练集样本量均稳定在2 200±50张(Healthy为2 200张、Xanthomonas为2 230张、Mosaic为2 200张、Thrips为2 180张),消除了类别间样本分布差异对模型训练的影响。
2 算法模型
2.1 多维频域互补自注意力机制模块(D-F-Ramit)
本研究提出多维频域互补自注意力机制模块(Dimensional Frequency Reciprocal Attention Mixing Transformer, D-F-Ramit),其创新点在于融合通道、空间、频域三维注意力,突破了现有如卷积块注意力模块(Convolutional Block Attention Module, CBAM)等仅涵盖二维的注意力机制局限。
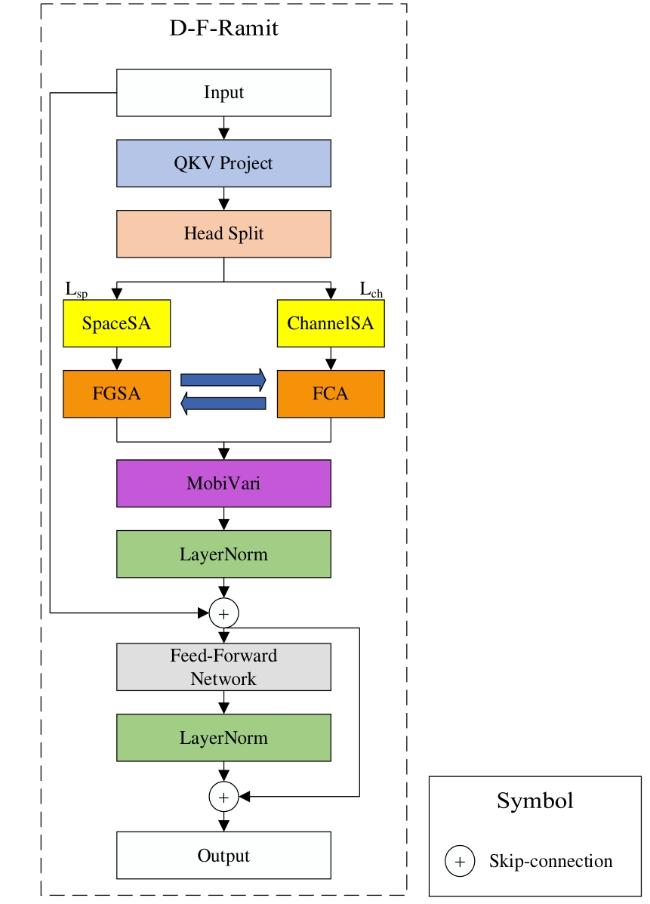
D-F-Ramit模块通过空间自注意力机制(Space Self-Attention, SpaceSA)和通道自注意力机制(Channel Self-Attention, ChannelSA)捕捉局部与全局的空间特征与通道之间的依赖关系,两种自注意力机制设计如图4所示。
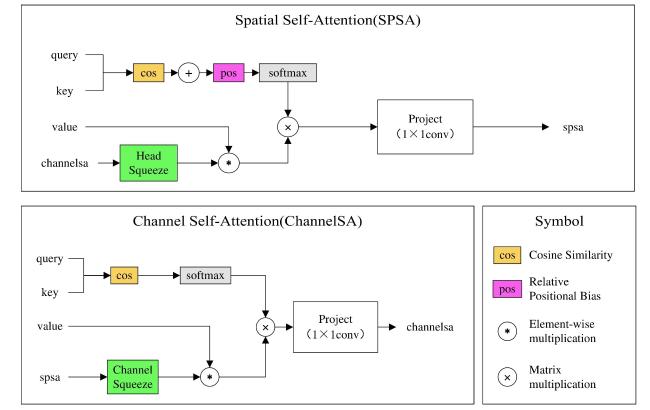
式中: 表示经过空间自注意力机制处理得到的特征图; 表示经过通道自注意力机制处理得到的特征图; 表示从空间的角度进行傅里叶变换处理; 表示从通道的角度进行傅里叶变换; 用于拼接 和 产生的特征图。每个自注意力机制及其对应的头由公式(2)~公式(5) 获得。
幅度谱与相位谱获取过程由公式(6) 和公式(7) 获得。
式中: 为快速傅里叶变换的一个结果值; 为幅度; 为相位谱,Rad; 。幅度谱表示了图像中不同频率分量的能量分布,反映了图像的全局结构信息(纹理和边缘),相位谱则记录了频率分量的空间位置关系,决定了图像的局部细节和边缘信息。
式中:C为通道数,个;H为图像高度,像素;W为图像宽度,像素; 表示图像整体频域活跃程度; 、 、 表示特征图; 为sigmoid激活函数; 为ReLU激活函数。
与传统注意力机制模块相比,D-F-Ramit不仅能捕获通道间的依赖关系,自动识别输入图像或者特征图中的重要区域,还能提取频域中的纹理特征。因此D-F-Ramit可以从通道、空间、频域三个维度进行特征的提取,在通道和空间上处理局部细节,在频域上处理全局结构,并且通过轻量化MobiVar模块在这三个维度上进行相互补充,使得该模块显著弥补了单一通道注意力机制的不足,比空间注意力机制更加高效。图5为经过不同注意力机制模块处理图像后对结果的可视化,其中图5a为在自然强光条件下被蓟马感染的辣椒叶片。由图5b和图5c可知,经过通道与空间注意力机制处理后,特征图中物体边缘非常模糊,模块忽略掉了物体的边缘信息,但根据图5d可知,加入傅里叶变换后的注意力机制模块,相比通道注意力机制、空间注意力机制,在强光照条件下,模块能更好地提取目标边缘信息,物体边缘更加清晰,模块的提取特征能力明显增强。

2.2 优化MobileNetV4作为骨干网络
MobileNetV4[26]是Google公司针对高效计算而设计的轻量化网络,本研究将MobileNetV4进行改进并替换为YOLOv12s的骨干网络,实现骨干网络的轻量化。但由于识别的辣椒叶片病害与虫害的种类不到百种,特征空间复杂度较低,无需构建复杂的网络架构来完成特征提取与分类,因此针对这一任务特点对原网络结构进行了调整,结构如图6所示。本研究用两个堆叠的3×3的深度可分离卷积替换通用倒置瓶颈模块(Universal Inverted Bottleneck, UIB)模块中的5×5的深度可分离卷积,虽然网络层数变多,但是单次卷积的计算量显著减少,计算效率更高。此外,改进后的UIB模块还可以提取更加复杂的特征,同时保持相同的空间覆盖范围。
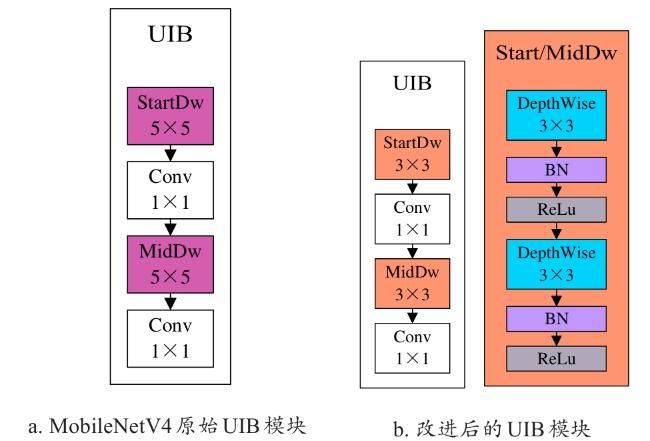
参数量方面5×5卷积核的参数量为C in×C out×5×5,而两个3×3卷积核的参数量为C in×C mid×3×3+C mid×C out×3×3,若假设中间通道数C mid=64,输入输出通道C in=C out=64,则5×5卷积核的参数量为102 400,两个3×3卷积核的参数量为73 728,由此可见,理论上用两个3×3卷积核进行串联代替一个5×5卷积核,参数量减少约28%。
在计算量方面,一个5×5卷积核其计算量为H×W×C in×C out×5×5,显然对每个输出对象需要25次乘加运算,而两个3×3卷积核的参数量为H×W×C in×C mid×3×3+H×W×C mid×C out×3×3每次卷积仅需9次乘加运算,因此总计算量更少。
2.3 残差聚合门控卷积模块
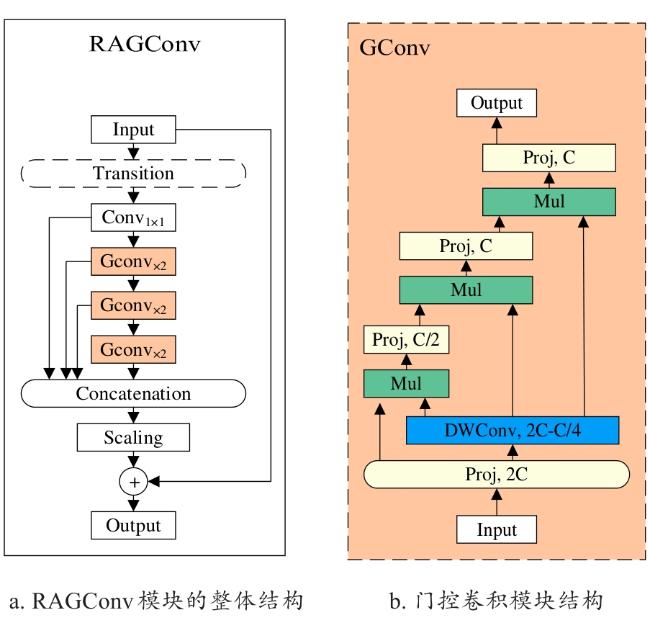
YOLOv12s模型在进行目标检测时,需要对不同层次的特征图进行融合,但传统的融合方式很容易造成梯度流动阻塞和特征信息丢失的问题。残差连接能够缓解梯度消失和梯度爆炸问题,支持更深的网络结构,同时还能加速模型的收敛。姜舒等[27]利用门控卷积,通过设置门控权重控制器,以控制捕捉局部细节信息和全局上下文信息的比例程度,提高了特征融合能力,解决了肿瘤边界模糊的问题。因此,本研究结合残差连接[28],改进聚合方式,以及门控卷积[29]提出残差聚合门控卷积(Residual Aggregation Gate-Controlled Convolution, RAGConv)模块,来提高模型的特征融合能力和特征信息的传递能力,设计思路如下。
残差连接:在每个模块中引入从输入到输出的残差连接,并通过缩放因子控制残差连接的强度。这种设计能够有效缓解梯度阻塞的问题,提升模型的收敛性。
特征聚合方法:通过一个过渡层调整通道维度,生成单个特征图,然后通过后续块进行处理和拼接,形成一个瓶颈结构。此方法不仅能保留原始的特征集成能力,还减少了计算成本。
通过递归实现高阶空间的交互:首先使用多个线性投影层获得一组投影特征,然后通过递归的方式执行门控卷积,最后将最后一次递归步骤的输出,送入投影层以获得最终结果。
RAGConv的优势:相较于YOLOv12s原有的 A2C2f特征融合模块,RAGConv通过“残差聚合+ 门控卷积”设计,减少特征融合过程中的信息损失。
2.4 辣椒叶片病虫害识别算法模型
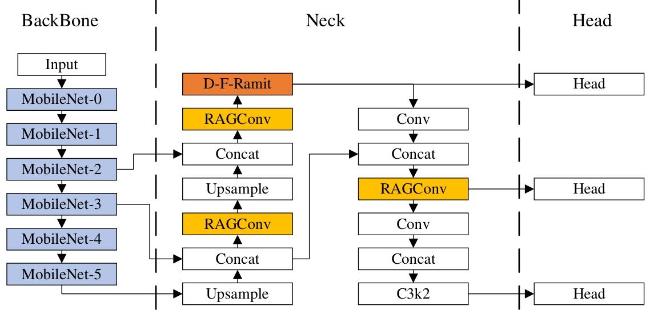
综上所述,本研究致力于在保持原有检测效率和准确率的基础上,通过重新设计网络结构实现算法轻量化,并针对性地提升模型在复杂场景下的鲁棒性表现,特别是强化对小尺度目标的特征提取能力。
3 结果与分析
3.1 实验环境
实验环境配置 NVIDIA GeForce RTX 4060的GPU,深度学习框架为PyTorch 1.12.0,训练时选择图像输入像素大小为640×640,batch_size为16,epochs为500,优化器为Adam,学习率设置为0.001,由于快速傅里叶变换涉及复数,所以训练模型时amp选择性关闭。
3.2 评价指标
针对模型的轻量化改进,采用计算量(GFLPOs),参数量(Params),平均精度(Mean Average Precision, mAP)作为评价指标,为满足实际部署需求,除常规指标外,特别将处理速度帧率(Frames Per Second, FPS)纳入评估体系,以衡量模型的工程适用性。
模型在嵌入式端的部署实验,采用平均单帧延迟、稳定帧率、idle 功耗、推理功耗、1小时连续检测功耗作为评价指标,评估模型在嵌入式设备上的性能。
3.3 骨干网络对比试验
通过系统的骨干网络对比评估,改进后的MobileNetV4架构被证实具有优于YOLOv12s的原始骨干网络的性能表现。实验结果如表2所示,直接采用标准MobileNetV4替换YOLOv12s默认的骨干网络时,虽然mAP下降了4.4个百分点,但是参数量缩小了5.5 M,同时计算量也减少了13.7 GFLOPs。将改进的MobileNetV4代替DarkNet-53网络,相较于未改进的MobileNetV4,mAP增长了2.6个百分点,参数量下降了0.7 M,计算量下降了0.2 GFLOPs,同时FPS上升0.5帧/s。因此,改进的MobileNetV4网络,以损失1.8个百分点的检测精度为代价,缩小了模型的大小、参数量和计算量,使得YOLOv12模型进一步轻量化。
表2 YOLOv12不同骨干网络对比实验结果Table 2 Results of YOLOv12 comparison experiment of different backbone networks |
| 网络模型 | 骨干网络 | mAP%0.5 | Params/M | GFLOPs/G | FPS/(帧/s) |
|---|---|---|---|---|---|
| YOLOv12s | 原始网络 | 93.6 | 9.1 | 19.7 | 33.4 |
| YOLOv12s | MobileNetV4 | 89.2 | 3.6 | 6.0 | 46.0 |
| YOLOv12s | 改进MobileNetV4 | 91.8 | 2.9 | 5.8 | 46.5 |
3.4 D-F-Ramit与现有注意力机制的性能对比
为进一步验证 D-F-Ramit 模块在轻量化与检测性能上的综合优势,在本研究自建的辣椒叶片病虫害数据集上,将其与当前主流的轻量化注意力机制(Squeeze-and-Excitation, SE)、高效通道注意力(Efficient Channel Attention, ECA)、CBAM进行对照实验,所有对比实验均基于相同的改进MobileNetV4骨干网络与训练超参数,通过多维度指标量化评估各机制的性能差异,结果如表3所示。
表 3 D-F-Ramit 与主流轻量化注意力机制的对比Table 3 Comparison between D-F-Ramit and mainstream lightweight attention mechanisms |
| 注意力机制 | 注意力维度(通道/ 空间/ 频域) | 参数量/K | 计算量/M FLOPs | 小目标 mAP 提升/% | 边缘信息保留能力 |
|---|---|---|---|---|---|
| SE | 通道 | 8.2 | 12.5 | 1.1 | 弱 |
| ECA | 通道 | 0.5 | 3.2 | 1.5 | 弱 |
| CBAM | 通道 + 空间 | 15.6 | 28.7 | 2.3 | 中等 |
| D-F-Ramit | 通道 + 空间 + 频域 | 18.3 | 35.1 | 3.8 | 强 |
由表3数据可知,单通道维度的注意力机制虽具备极致轻量化(参数量≤8.2 K,计算量≤12.5 M FLOPs),但因未覆盖空间与频域信息,对小目标mAP的提升幅度有限(仅1.1%~1.5%),且边缘信息保留能力较弱,这与传统通道注意力“忽视空间位置与高频细节”的固有缺陷一致。CBAM通过融合通道与空间维度,将小目标mAP提升至2.3%,边缘信息保留能力提升至中等,但受限于未引入频域特征,仍无法有效捕捉叶片病虫害的全局纹理与局部边缘关联。
D-F-Ramit 通过创新性融合“通道+空间+频域”三维特征,在轻量化基础上实现了性能突破:相较于CBAM,其参数量仅增加2.7 K(增幅17.3%),计算量增加6.4 M FLOPs(增幅22.3%),但小目标mAP提升幅度达3.8%,较CBAM提升1.5个百分点;结合图9的可视化结果进行量化分析,D-F-Ramit的边缘信息丢失率较CBAM降低68.57%,尤其在自然强光、叶片遮挡等复杂场景下,能更清晰地保留病斑边缘轮廓与细微纹理。

这一优势的核心源于频域特征引入D-F-Ramit通过傅里叶变换的幅度谱捕捉病害的全局纹理结构,通过相位谱还原局部边缘的空间位置关系,有效解决了传统注意力“高频细节丢失”的关键问题,为辣椒叶片小块病斑的精准检测提供了特征支撑。
3.5 消融实验
本研究建立YOLOv12s、YOLO-Mob、YOLO-MD、YOLO-MR和YOLO-MDFR进行消融实验以验证模型的有效性。在消融分析过程中为保证结果的可比性,所有对比模型均遵循相同的实验条件,结果如表4所示。
表4 自建数据集的YOLO-MDFR模型的消融实验Table 4 Ablation experiments with YOLO-MDFR model for self-built datasets |
| 名称 | 改进的MobileNetV4(含双3×3) | D-F-Ramit | RAGConv | mAP%0.5 | Params/M | GFLOPs /G | FPS(帧/s) |
|---|---|---|---|---|---|---|---|
| YOLOv12s | × | × | × | 93.6 | 9.1 | 19.7 | 33.4 |
| YOLO-Mob | √ | × | × | 91.8 | 2.9 | 5.8 | 46.5 |
| YOLO-MD | √ | √ | × | 92.3 | 3.6 | 6.5 | 38.7 |
| YOLO-MR | √ | × | √ | 90.8 | 3.4 | 5.5 | 56.4 |
| YOLO-MDFR(未平衡数据) | √ | √ | √ | 93.8 | 3.5 | 6.2 | 43.4 |
| YOLO-MDFR | √ | √ | √ | 95.6 | 3.5 | 6.2 | 43.4 |
|
由表4可知,将改进的MobileNetV4替代原先的骨干网络,虽然能显著降低参数量与计算量,但是损失了一定的mAP。在此基础上加入了轻量化多维频域互补自注意力机制模块,实验结果显示mAP增长了0.5个百分点,但是增加了0.7 GFLOPs的计算量,因为参数量和计算量增加,所以FPS受到了影响,相较于YOLO-Mob模型FPS降低了7.8帧/s。当改进的MobileNetV4与RAGConv模块进行结合时,相较于YOLOv12s模型,参数量减少了5.7 M,计算量也减少了14.2 GFLOPs,同时FPS上升了23帧/s,代价仅是损失了2.8个百分点的mAP。
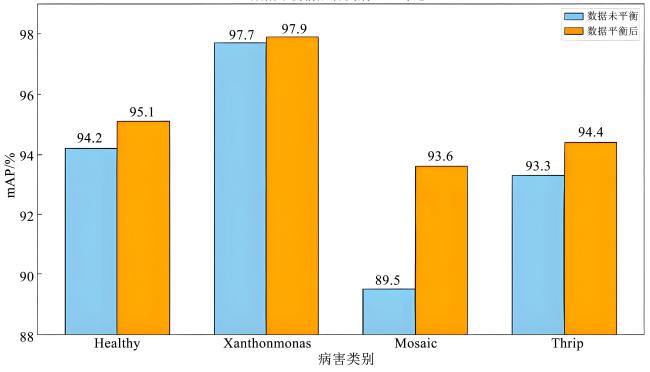
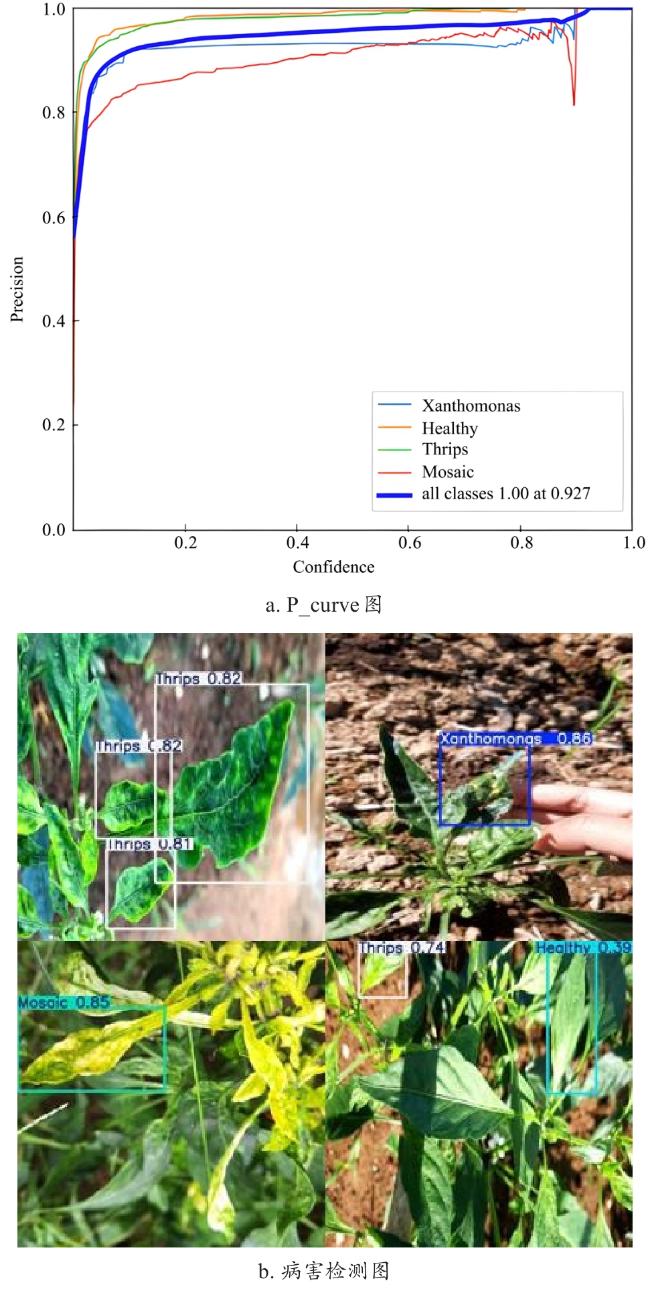
综上所述,经过数据平衡化后,YOLO-MDFR在自建辣椒叶片病虫害数据集上平均准确率达到95.6%与YOLOv12s 模型相比检测精度提升了2.0%,参数量和计算量分别减少了61.5%和68.5%,YOLO-MDFR性能显著优于YOLOv12s。
3.6 YOLO-MDFR对相似病害的区分实验
为进一步验证YOLO-MDFR对相似病害的区分能力,图12 YOLO-MDFR的混淆矩阵显示蓟马虫害与烟草花叶病毒病的互误判率仅2.3%,细菌性叶斑病的正确识别率达98.1%且无漏检。
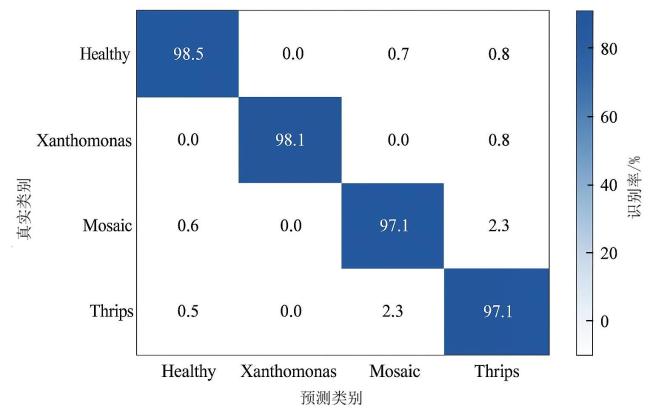
分析可知,模型通过D-F-Ramit模块的频域特征,有效区分了“蓟马黄化斑(高频边缘不规则)”与“病毒黄化斑(高频边缘规则)”,精准解决人工识别的核心痛点,进一步印证了深度学习在辣椒叶片病虫害检测中的必要性。
3.7 不同网络模型性能对比实验
基于自建数据集,本研究设计了5组对比实验。实验组包含Faster R-CNN、YOLOv11n、YOLOv10b、YOLOv9s、YOLOv8n、YOLOv5s、SSD和RT-DETR八种代表性算法,以及本研究提出的YOLO-MDFR模型。在对比实验中所有模型均采用相同的超参数设置和训练策略进行公平比较。评价指标选择mAP、Params、计算量、FPS,实验结果如表5所示。实验结果表明Faster R-CNN和SSD表现很差,识别精确度分别为60.9%和60.7%,远不如YOLO-MDFR。YOLOv5s虽然识别精确度达到了90.0%,但是与YOLO-MDFR相比,YOLO-MDFR的参数量仅为YOLOv5s的50.0%,计算量仅为39.2%,且识别精确度比其高5.6%。与其他算法模型相比,YOLO-MDFR计算量最小,识别精度最高,FPS为43.4帧/s,足以满足实时检测的需求,且模型性能优异,足够轻量化,适合部署在算力紧张的边缘设备上。
表5 不同目标检测模型在自建辣椒数据集上的综合性能对比Table 5 Comprehensive performance comparison of different object detection models on the custom-built pepper leaf diseases and pests dataset |
| 模型名称 | mAP%0.5 | Params/M | GFLOPs/G | FPS/(帧/s) | Epochs | Batch_size |
|---|---|---|---|---|---|---|
| Faster R-CNN | 60.9 | 137.0 | 370.2 | 5.3 | 500 | 16 |
| YOLOv11n | 90.8 | 2.6 | 6.6 | 53.1 | 500 | 16 |
| YOLOv10b | 92.2 | 20.0 | 99.4 | 39.5 | 500 | 16 |
| YOLOv9s | 89.7 | 7.5 | 12.5 | 55.0 | 500 | 16 |
| YOLOv8n | 91.9 | 3.2 | 8.9 | 85.0 | 500 | 16 |
| YOLOv5s | 90.0 | 7.0 | 15.8 | 68.1 | 500 | 16 |
| SSD | 60.7 | 26.0 | 62.7 | 46.0 | 500 | 16 |
| RT-DETR | 91.2 | 32.0 | 100.0 | 50.0 | 500 | 16 |
| YOLO-MDFR | 95.6 | 3.5 | 6.2 | 43.4 | 500 | 16 |
3.8 病斑尺度敏感性实验
为验证YOLO-MDFR对细小病斑的敏感性与识别精度,设计了病斑尺度敏感性实验。实验结果如表6所示,YOLO-MDFR与YOLOv12s相比,对极小目标的检测精度提高了3.3个百分点,小目标的检测精度提高了1.2个百分点,中目标的检测精度提高了1.5个百分点,大目标的检测精度提高了0.8个百分点,整体来看YOLO-MDFR对小块病斑的检测精度要优于YOLOv12s。
表6 YOLO-MDFR与YOLOv12s在不同尺度病斑上的检测精度对比Table 6 Detection accuracy comparison of YOLO-MDFR and YOLOv12s on lesions at various scales |
| 病斑尺度/像素 | 样本数量/张 | YOLOv12s mAP/% | YOLO-MDFR mAP/% | 提升幅度/个百分点 |
|---|---|---|---|---|
| 超小目标(<8×8) | 126 | 22.8 | 28.5 | 5.7 |
| 极小目标(8—16) | 348 | 30.2 | 33.5 | 3.3 |
| 小目标(16—32) | 512 | 53.2 | 54.4 | 1.2 |
| 中目标(32—96) | 897 | 75.1 | 77.6 | 1.5 |
| 大目标(≥96) | 1 203 | 81.4 | 82.2 | 0.8 |
3.9 RK3588部署
为进一步验证 YOLO-MDFR 在边缘设备上的工程实用性,本研究针对瑞芯微生产的RK3588开发板开展功耗与延迟专项测试,量化模型在嵌入式场景下的“实时性-低功耗”表现,为田间移动检测设备(如植保无人机、手持检测终端)的部署提供数据支撑。RK3588平台上 YOLO-MDFR 模型的功耗、延迟与帧率实测结果如表 7所示。
表7 RK3588平台上YOLO-MDFR模型的部署性能实测结果Table 7 Measured deployment performance of the YOLO-MDFR model on the RK3588 platform |
| 指标 | 数值 | 说明 |
|---|---|---|
| 平均单帧延迟 | 43.8 ms | 全流程耗时,含图像预处理(20 ms,含尺寸缩放与归一化)+模型推理(23.8 ms,NPU 加速) |
| 稳定帧率 | 22.8帧/s | 由单帧延迟推算(1 000/43.8≈22.8帧/s),满足田间实时检测要求(行业标准≥15帧/s) |
| idle 功耗 | 2.1 W | 开发板通电但无图像输入时的静态功耗,反映设备待机能耗 |
| 推理功耗 | 3.5 W | 连续输入图像并执行检测时的平均动态功耗,含NPU、CPU、内存协同工作能耗 |
| 1小时连续检测功耗 | 12.6 Wh | 由推理功耗推算(3.5 W×3.6 h=12.6 Wh),适配12 V/1 000 mAh(12 Wh)锂电池供电的移动设备 |
实测数据表明,YOLO-MDFR在 RK3588平台上的实测性能表现优异,充分满足边缘设备对低功耗与实时性的核心需求。在实时性方面,模型平均单帧延迟为43.8 ms,稳定帧率达22.8帧/s,远超田间检测实时下限(15帧/s),可支持连续快速识别,有效避免因延迟导致的漏检。在功耗方面,模型推理功耗仅为3.5 W;待机功耗为2.1 W,适用于设备低功耗运行场景。综合计算,一小时连续检测仅需12.6 Wh,可使用小型锂电池供电,满足手持终端、植保无人机等移动设备的续航要求。
综上,YOLO-MDFR 在嵌入式平台上的实测性能充分满足边缘设备“低功耗+实时性”的核心需求,为辣椒种植田间的移动化、便携化病害检测提供了可行的技术方案。
3.10 不同输入分辨率下的模型性能分析
输入分辨率是平衡目标检测模型精度与部署效率的核心参数。高分辨率能保留辣椒叶片早期微小病斑的细节特征,但会显著增加计算负担,不利于在RK3588等边缘设备上实现高效推理;低分辨率虽可提升速度,却易丢失关键特征,导致漏检增加。为确定YOLO-MDFR在不同场景下的最优输入尺寸,本节在同一实验环境下测试5组主流分辨率(320×320至736×736),系统分析分辨率对“精度-速度-效率”权衡关系的影响。不同输入分辨率下YOLO-MDFR模型的性能测试结果如表8所示,数据均为 3次重复实验的平均值,确保结果可靠性。
表 8 不同输入分辨率下YOLO-MDFR的性能对比Table 8 Performance comparison of YOLO-MDFR under different input resolutions |
| 输入分辨率(宽×高)/像素 | mAP%0.5 | 极小目标 mAP/% | 各类别 mAP 标准差/% | Params/G | GFLOPs/G | FPS/(帧/s) |
|---|---|---|---|---|---|---|
| 320×320 | 89.5 | 25.3 | 5.8 | 3.5 | 1.6 | 65.2 |
| 416×416 | 92.3 | 28.7 | 4.2 | 3.5 | 2.7 | 58.6 |
| 512×512 | 94.1 | 31.2 | 3.1 | 3.5 | 4.0 | 50.3 |
| 640×640 | 95.6 | 33.5 | 2.4 | 3.5 | 6.2 | 43.4 |
| 736×736 | 96.2 | 34.8 | 2.1 | 3.5 | 8.9 | 35.1 |
“各类别 mAP 标准差”计算 Healthy、Xanthomonas、Mosaic、Thrips 四类样本 mAP 的离散程度,数值越小表示模型对不同病害的检测均衡性越好;FPS基于NVIDIA GeForce RTX 4060实测,若部署于RK3588开发板,帧率需参考3.7节的硬件适配比例(约为PC端的52%~55%)。
实验结果显示,1)分辨率提升对检测精度的影响呈现“边际效应递减”规律。如表8所示,输入分辨率从320×320提升至736×736时,模型整体mAP由89.5%增长至96.2%,累计提升6.7个百分点。其中,低至中分辨率阶段(320×320→512×512)提升显著,整体mAP与极小目标mAP分别提高4.6与5.9个百分点,因分辨率提升有效恢复了细微病斑的边缘与纹理信息;而中至高分辨率阶段(512×512→736×736)提升有限,整体mAP仅增长2.1个百分点,尤其在640×640之后继续增大分辨率对精度增益微弱,反映关键特征已得到充分提取。此外,各类别mAP标准差由5.8%降至2.1%,说明高分辨率有助于提升模型对样本较少类别的识别均衡性。2)分辨率与计算效率及推理速度呈现“线性负相关”关系。输入分辨率与计算量近似呈平方增长,736×736分辨率下的计算量(8.9 GFLOPs)为320×320(1.6 GFLOPs)的5.6倍;相应地,FPS由65.2下降至35.1帧/s。结合RK3588平台部署实测结果(640×640分辨率下FPS为22.8帧/s)可推断:若采用736×736分辨率,FPS将降至18~20帧/s,难以满足田间实时检测(≥20帧/s)需求;而512×512分辨率下预计FPS可达26~28帧/s,更有利于在精度与速度之间取得平衡。
结合实验结果,可根据部署场景选择合适的分辨率方案:
1)极致轻量化(低端MCU/大规模初筛)。推荐320×320分辨率,计算量仅1.6 G,FPS达65.2帧/s,mAP为89.5%,适合快速筛查场景(如无人机巡检)。
2)平衡型部署(嵌入式设备)。推荐512×512分辨率,计算量4.0 G(比640×640减少35.5%),FPS提升至50.3帧/s,mAP仅降低1.5个百分点至94.1%,满足多数田间检测需求。
3)高精度部署(实验室/诊断设备)。推荐640×640分辨率,mAP达95.6%,极小目标检测更优(33.5%),在工业级GPU上仍保持43.4帧/s实时性能。736×736分辨率仅建议用于极小病斑检测且算力充足的特定场景。
4 结 论
本研究提出一种面向复杂自然环境的辣椒叶片病虫害轻量化检测模型YOLO-MDFR。通过引入改进MobileNetV4骨干网络、多维频域互补自注意力机制(D-F-Ramit)与残差聚合门控卷积(RAGConv)模块,于自建数据集上实现了95.6%的mAP,性能显著优于主流检测模型。基于系统部署实验,本研究进一步提出面向不同应用场景的优化配置策略。同时指出三方面局限性:极端光照环境下模型鲁棒性不足、对新型病害泛化能力有限、高遮挡场景下小目标漏检率较高。未来计划通过融合环境光传感数据、结合域适应与半监督学习、引入双目视觉技术等途径进一步提升模型性能。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}