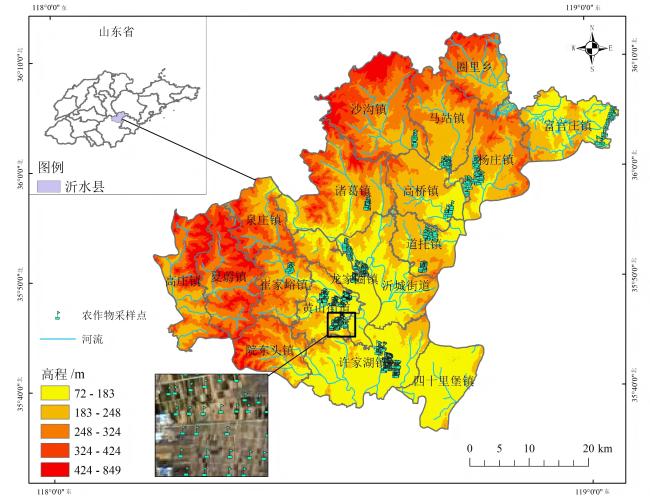
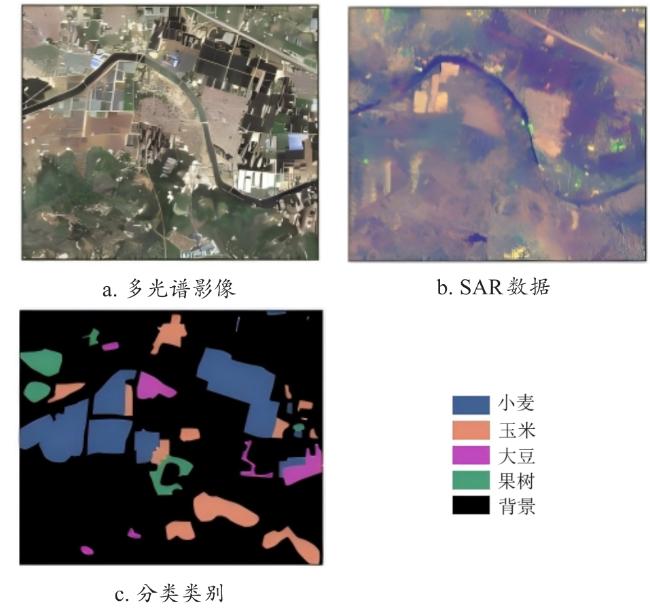
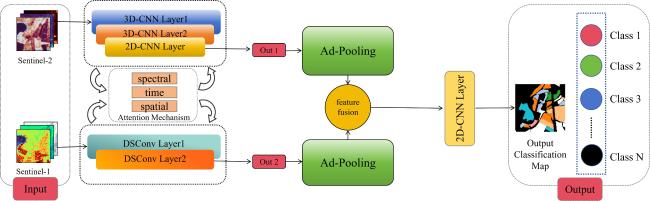
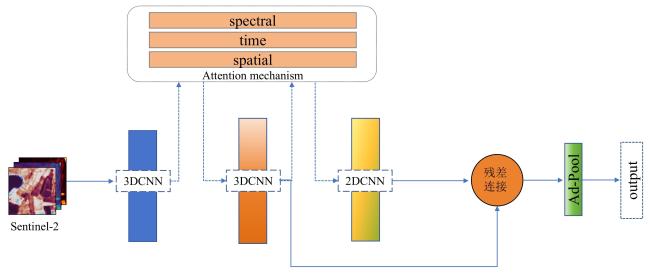
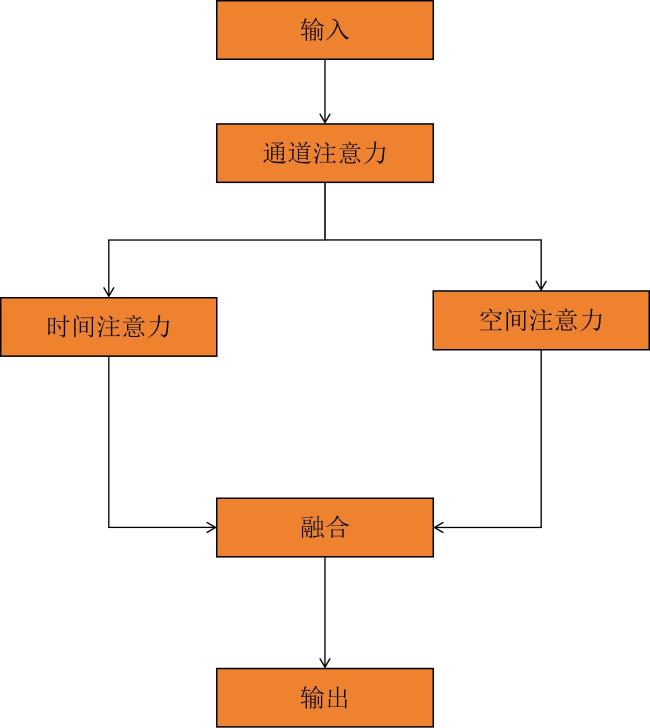
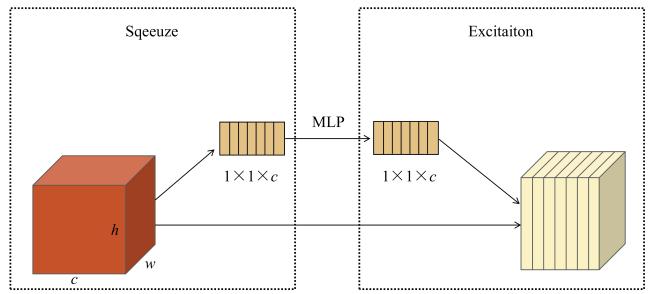
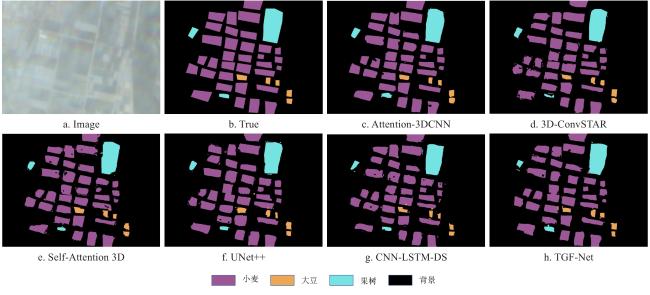
[Objective] Accurate and timely crop mapping is fundamental for agricultural management, yield forecasting, and food security assessment. However, in mountainous and hilly regions characterized by frequent cloud cover and highly fragmented farmland, crop classification methods relying solely on optical remote sensing data are severely constrained. Persistent cloud contamination introduces data gaps and temporal inconsistencies in optical image time series, significantly degrading classification accuracy and robustness. To address these limitations, a robust and adaptive deep learning framework is developed capable of effectively integrating multi-modal remote sensing data. The primary objective is to enhance crop classification accuracy and stability under complex conditions where optical observations are scarce or unreliable, thereby supporting reliable agricultural monitoring in cloudy and fragmented landscapes. [Methods] A novel deep neural network architecture named 3D convolutional neural network based on attention mechanism (Attention-3DCNN) was proposed, designed to jointly exploit multi-temporal optical and synthetic aperture radar (SAR) observations. The model integrated Sentinel-2 multispectral time-series imagery with weather-insensitive Sentinel-1 SAR data through a dedicated cross-modal fusion strategy driven by a triple-attention mechanism. The network adopted a dual-branch feature extraction architecture. For the Sentinel-2 data, a hybrid module combining three-dimensional and two-dimensional convolutional neural networks (3D-CNN and 2D-CNN) was employed to capture discriminative spatiotemporal features and crop phenological dynamics across the growing season. This design enabled effective modeling of the spectral-temporal interactions inherent in crop development. For the Sentinel-1 SAR data, depthwise separable convolutions were utilized to efficiently extract spatial and textural features related to crop structure and surface scattering characteristics while reducing computational complexity. Features extracted from both modalities were subsequently integrated using a custom-designed attention-based fusion module. This module consisted of three complementary attention mechanisms: channel attention, temporal attention, and spatial attention. Residual connections were incorporated throughout the network to facilitate stable training and effective gradient propagation. The proposed model was evaluated on two datasets to assess both its performance and generalizability. The first was the publicly available panoptic agricultural satellite time series (PASTIS) benchmark dataset from France, which contained dense time-series observations and multiple crop classes. The second was a real-world dataset constructed for Yishui county, Shandong province, China, which was characterized by high cloud frequency (approximately 33%), highly fragmented farmland (average parcel size < 0.5 hm2), and a relatively simple crop rotation system. Comparative experiments were conducted against several state-of-the-art models, including 3D-ConvSTAR, UNet++, Self-Attention 3D, CNN-LSTM dual-stream network, and TGF-Net. Ablation studies were also performed to quantify the contribution of each attention component. [Results and Discussions] Experimental results demonstrated that Attention-3DCNN consistently outperformed all baseline methods on both datasets. On the PASTIS benchmark, the model achieved an overall accuracy (OA) of 97.5%, confirming its strong classification capability under favorable observation conditions. On the more challenging Yishui county dataset, Attention-3DCNN attained an OA of 93%, outperforming the other comparison models. Ablation experiments confirmed the effectiveness of the proposed triple-attention mechanism, as removing any attention component resulted in a clear reduction in classification performance. Under heavy cloud coverage, Attention-3DCNN exhibited the smallest accuracy degradation, with an OA drop of only 3.6 percentage points, indicating its ability to adaptively rely on SAR information when optical data quality deteriorated. In regions with highly fragmented farmland, the proposed model also maintained the highest accuracy and the smallest performance decline (2.8 percentage points), benefiting from the spatial attention mechanism. Moreover, attention visualization provided meaningful interpretability. Temporal attention peaks aligned with key crop phenological stages, while channel attention highlighted spectrally and physically informative optical bands and SAR polarizations, which was consistent with established agronomic and remote sensing knowledge. [Conclusions] This study presents the Attention-3DCNN model for accurate and robust crop classification in regions affected by persistent cloud cover and fragmented agricultural landscapes. By fusing Sentinel-2 optical and Sentinel-1 SAR time-series data through a channel-temporal-spatial triple-attention mechanism, the proposed framework enables adaptive integration of complementary multi-modal information. The model achieves outstanding performance on both benchmark and real-world datasets, demonstrates strong robustness under adverse conditions, and offers enhanced interpretability. Overall, the proposed approach provides a reliable and practical solution for crop mapping in complex agricultural environments.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}