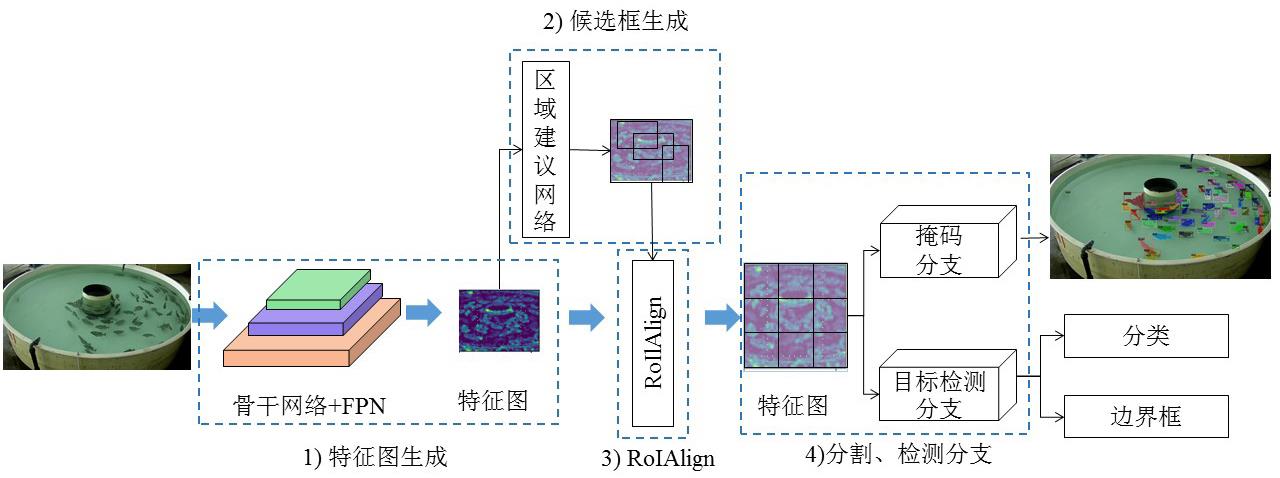
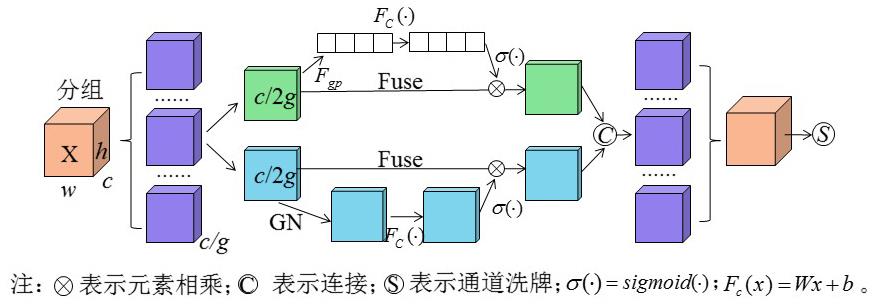
| 1 |
李道亮, 刘畅. 人工智能在水产养殖中研究应用分析与未来展望[J]. 智慧农业(中英文), 2020, 2(3): 1-20.
|
|
LI D L, LIU C. Recent advances and future outlook for artificial intelligence in aquaculture[J]. Smart agriculture, 2020, 2(3): 1-20.
|
| 2 |
杨玲. 基于机器视觉的工厂化鱼群摄食行为智能分析方法研究[D]. 北京: 中国农业大学, 2022.
|
|
YANG L. Computer vision technologies for fish school feeding behavior analysis in industrial aquaculture[D]. Beijing: China Agricultural University, 2022.
|
| 3 |
LIU H Y, LIU T, GU Y Z, et al. A high-density fish school segmentation framework for biomass statistics in a deep-sea cage[J]. Ecological informatics, 2021, 64: ID 101367.
|
| 4 |
ZHANG L, WANG J P, DUAN Q L. Estimation for fish mass using image analysis and neural network[J]. Computers and electronics in agriculture, 2020, 173: ID 105439.
|
| 5 |
KHALID EL MOUTAOUAKIL, NOUREDDINE FALIH. Deep learning-based classification of cattle behavior using accelerometer sensors[J]. IAES international journal of artificial intelligence, 2024, 13(1): 524-5532.
|
| 6 |
ZHANG T W, ZHANG X L. A mask attention interaction and scale enhancement network for SAR ship instance segmentation[J]. IEEE geoscience and remote sensing letters, 2022, 19: 1-5.
|
| 7 |
ALSHDAIFAT N F F, TALIB A Z, OSMAN M A. Improved deep learning framework for fish segmentation in underwater videos[J]. Ecological informatics, 2020, 59: ID 101121.
|
| 8 |
田志新, 廖薇, 茅健, 等. 融合边缘监督的改进Deeplabv3+水下鱼类分割方法[J]. 电子测量与仪器学报, 2022, 36(10): 208-216.
|
|
TIAN Z X, LIAO W, MAO J, et al. Improved Deeplabv3+ underwater fish segmentation method combining with edge supervision[J]. Journal of electronic measurement and instrumentation, 2022, 36(10): 208-216.
|
| 9 |
CHEN L C, ZHU Y K, PAPANDREOU G, et al. Encoder-decoder with atrous separable convolution for semantic image segmentation[C]// Computer Vision-ECCV 2018: 15th European Conference. New York, USA: ACM, 2018: 833-851.
|
| 10 |
WOO S, PARK J, LEE J Y, et al. CBAM: Convolutional block attention module[M]// Computer vision-ECCV 2018. Cham: Springer International Publishing, 2018: 3-19.
|
| 11 |
覃学标, 黄冬梅, 宋巍, 等. 基于目标检测及边缘支持的鱼类图像分割方法[J]. 农业机械学报, 2023, 54(1): 280-286.
|
|
QIN X B, HUANG D M, SONG W, et al. Fish image segmentation method based on object detection and edge support[J]. Transactions of the Chinese society for agricultural machinery, 2023, 54(1): 280-286.
|
| 12 |
YU X N, WANG Y Q, LIU J C, et al. Non-contact weight estimation system for fish based on instance segmentation[J]. Expert systems with applications, 2022, 210: ID 118403.
|
| 13 |
CHANG C C, WANG Y P, CHENG S C. Fish segmentation in sonar images by mask R-CNN on feature maps of conditional random fields[J]. Sensors, 2021, 21(22): ID 7625.
|
| 14 |
HE K M, GKIOXARI G, DOLLAR P, et al. Mask R-CNN[C]// 2017 IEEE International Conference on Computer Vision (ICCV). Piscataway, New Jersey, USA: IEEE, 2017: 2980-2988.
|
| 15 |
郭奕, 黄佳芯, 邓博奇, 等. 改进Mask R-CNN的真实环境下鱼体语义分割[J]. 农业工程学报, 2022, 38(23): 162-169.
|
|
GUO Y, HUANG J X, DENG B Q, et al. Semantic segmentation of the fish bodies in real environment using improved Mask-RCNN model[J]. Transactions of the Chinese society of agricultural engineering, 2022, 38(23): 162-169.
|
| 16 |
YANG L, ZHANG R, LI L, et al. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks[C/OL]// Proceedings of the 38 th International Conference on Machine Learning. New York, USA: PMLR, 2021: 11863-11874.
|
| 17 |
VARKARAKIS V, CORCORAN P. Dataset cleaning: A cross validation methodology for large facial datasets using face recognition[C]// 2020 Twelfth International Conference on Quality of Multimedia Experience (QoMEX). Piscataway, New Jersey, USA: IEEE, 2020: 1-6.
|
| 18 |
姜波. 基于计算机视觉与深度学习的奶牛跛行检测方法研究[D]. 杨凌: 西北农林科技大学, 2020.
|
|
JIANG B. Detection of dairy cow lameness based on computer vision and deep learning[D]. Yangling: Northwest A & F University, 2020.
|
| 19 |
WU S F, CHANG M C, LYU S W, et al. FlagDetSeg: Multi-nation flag detection and segmentation in the wild[C]// 2021 17th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). Piscataway, New Jersey, USA: IEEE, 2021: 1-8.
|
| 20 |
KAMILARIS A, PRENAFETA-BOLDÚ F X. Deep learning in agriculture: A survey[J]. Computers and electronics in agriculture, 2018, 147: 70-90.
|
| 21 |
REN S Q, HE K M, GIRSHICK R, et al. Faster R-CNN: Towards real-time object detection with region proposal networks[J]. IEEE transactions on pattern analysis and machine intelligence, 2017, 39(6): 1137-1149.
|
| 22 |
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2017: 2117-2125.
|
| 23 |
NEUBECK A, VAN GOOL L. Efficient non-maximum suppression[C]//18th International Conference on Pattern Recognition (ICPR'06). Piscataway, New Jersey, USA: IEEE, 2006: 850-855.
|
| 24 |
CHEN Y Y, LIU H H, YANG L, et al. A lightweight detection method for the spatial distribution of underwater fish school quantification in intensive aquaculture[J]. Aquaculture international, 2023, 31(1): 31-52.
|
| 25 |
ZHANG Q L, YANG Y B. SA-net: Shuffle attention for deep convolutional neural networks[C]// ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Piscataway, New Jersey, USA: IEEE, 2021: 2235-2239.
|
| 26 |
HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2016: 770-778.
|
| 27 |
LEE Y, PARK J. CenterMask: Real-time anchor-free instance segmentation[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2020: 13906-13915.
|
| 28 |
LEE Y, HWANG J W, LEE S, et al. An energy and GPU-computation efficient backbone network for real-time object detection[C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Piscataway, New Jersey, USA: IEEE, 2019: 752-760.
|
| 29 |
WANG X L, ZHANG R F, KONG T, et al. SOLOv2: Dynamic and fast instance segmentation[C]// Proceedings of the 34th International Conference on Neural Information Processing Systems. New York, USA: ACM, 2020: 17721-17732.
|
| 30 |
TIAN Z, SHEN C H, CHEN H. Conditional convolutions for instance segmentation[M]// Computer vision-ECCV 2020. Cham: Springer International Publishing, 2020: 282-298.
|
| 31 |
CHEN H, SUN K Y, TIAN Z, et al. BlendMask: Top-down meets bottom-up for instance segmentation[C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway, New Jersey, USA: IEEE, 2020: 8573-8581.
|
 ), CHEN Yingyi1,3,4,5, CHAI Yingqian1,3,4,5, XU Ling1,3,4,5, YU Huihui2,6(
), CHEN Yingyi1,3,4,5, CHAI Yingqian1,3,4,5, XU Ling1,3,4,5, YU Huihui2,6(