



0 引 言
培育优良种猪和控制生猪最佳出栏时间是畜牧业关注的重要问题,特定时间段的猪表型体尺测量是种猪培育和生猪出栏的关键参考点。表型体尺量化地描述了猪体外部特征、表型特征、发育情况等。体尺表型值常可作为育种时的遗传参数,亦可以作为育肥潜力的参考用以控制最佳出栏时间。目前猪表型体尺数据获取的常规方法主要是人工测量法,然而人工测量费时费力、效率低下、同时结果受到测量人员专业素养的主观性影响,且测量过程容易引发牲畜应激反应,并有可能对测量人员造成人身伤害,目前大规模人工测量已经不能满足现代大型养殖场的需求。
随着计算机视觉的发展,牲畜体尺的无接触测量方法越来越引起重视,其技术也经历过了多次改变和发展。最初的研究是使用彩色相机获取猪单视角下的二维彩色图像,通过对二维图像的分析和计算获取牲畜体尺或进行体重估计。江杰等[1]运用基于灰度的背景差分法,结合色度不变性原理,从复杂环境中检测羊体提取轮廓包络线,并获取轮廓包络线最大曲率点作为羊体臀部测点,采用四点法求取羊体其他3个测点计算出羊体的体尺参数。Zhang等[2]在获取羊只顶部和侧面图像后,使用SLIC(Simple Linear Iterative Clustering)Superpixel算法通过分割提取图像中的羊体,再分析轮廓包络线完成羊的体长、体高等体尺信息估算。
二维图像估算牲畜体尺具有成本低、设备安装简易等优势,然而二维图像缺少深度维度信息,且相机在物距、光照条件改变时,测量结果都会受到影响,故通用性较差,难以提升系统整体准确性。
随着消费级深度相机的广泛应用,研究者逐渐转向使用深度相机获取牲畜的三维表面点云进行体尺测量和体重估计。深度相机获取的点云数据包含了X、Y、Z坐标和颜色等信息,拓展了牲畜体尺测量的深度和广度研究。Salau等[5]使用单视角深度相机获取奶牛背部三维点云,分析统计采集点云定位体尺关键点实现对奶牛体尺自动测量,受到单视角的局限,该方法只能对背部和臀部部分体尺进行测量。叶文帅等[6]通过分析肉牛骨架特征和肉牛图像边缘轮廓特征,提出一种多姿态肉牛体尺自动测量方法。Ruchay等[7]使用非刚性配准提高配准精度,并通过在牛体进行物理标记的方法在采集的图像上得到关键点进行测量。Shi等[8]提出了一种基于注意力的特征提取模型对奶牛进行了体况评分,并在体况评分任务中取得了较好的结果;同时构建了一个由512头奶牛构成的数据集。Hu等[9]尝试使用改进的PointNet++网络对点云做分割,平均准确度为标准姿态下96.41%,非标准姿态下94.98%,对分割后的点云进行关键点定位,点云各部分分割后对猪的姿态变化有更高的容忍度,泛化性有所提升,但受限于定位点的精度和定位点数量,仍然有提升空间。
综上所述,采用牲畜表面点云进行体尺计算中,牲畜点云姿态多种多样,会呈现出不同的局部特征,使得体尺测量中关键点定位算法难以泛化应用于全部点云中[10],这也使得如何能更精确地通过点云对牲畜进行体尺测量成为了一个难点。
为进一步提升猪体尺测量的精度,且不采用消耗大量计算资源的点云分割模型,本研究设计了一种猪体点云自注意力机制网络模型Pig Back Transformer进行测量关键点定位,并使用关键点进行体长、体高、体宽、腹围等体尺数据的自动测算。
1 研究方法
本研究猪点云背部关键点定位及体尺测量算法计算流程如图1所示。
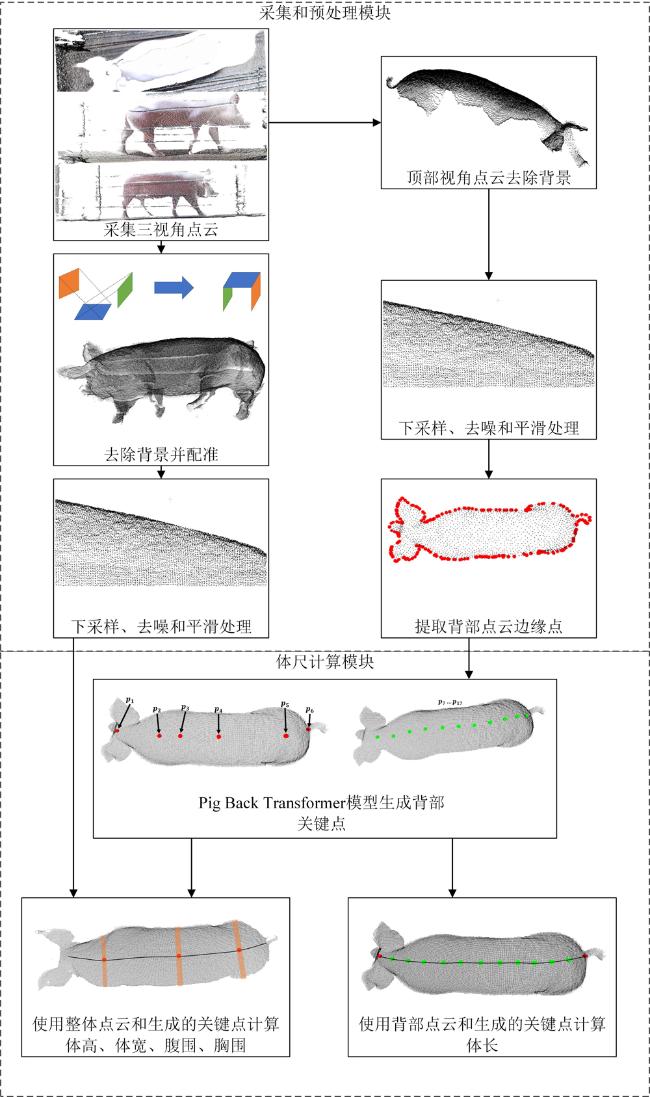
采集和预处理模块:首先使用深度相机采集顶部、左侧、右侧三个视角的局部点云;再分别将各视角点云中的背景去除,并对局部点云配准后得到完整三维点云;之后进行去噪、平滑处理和下采样;最后使用背部点云边缘提取算法获得背部边缘点云。
体尺计算模块:背部边缘点和内部点通过Pig Back Transformer模型生成背部测量关键点,使用背部测量关键点和背脊走向点结合背部点云计算体长,结合整体点云计算体高、体宽、腹围、胸围。
1.1 采集和数据预处理
本研究的数据采集地点位于广东省温氏河源新晶公司,采集猪种包括长白猪、大白猪、杜洛克、皮特兰和蓝塘土猪,猪龄为160~220天。分两次进行数据采集。第一次于2020年7月开始,持续30天;第二次于2022年7月开始,持续45天。
第一次采集,猪只体重为67.79~142.67 kg,平均体重105.28 kg,体长为100~130 cm,平均体长115.79 cm,体高为56~70 cm;第二次采集时,猪只体重为60~150 kg,体长为80~140 cm,体高为50~90 cm。
采集通道由两侧各三根钢制栏杆构成,宽度为0.65 m,长度为2.5 m。
第一次采集时使用三台Kinect V2相机从通道顶部以及两侧进行拍摄,相机参数为:深度图像分辨率像素为512×424,水平视角70°,垂直视角60°,深度范围0.5~3.5 m。通道顶部相机位于中央正上方高度为2.2 m处,两侧相机与地面相对高度为40 cm,水平间距为4.5 m。
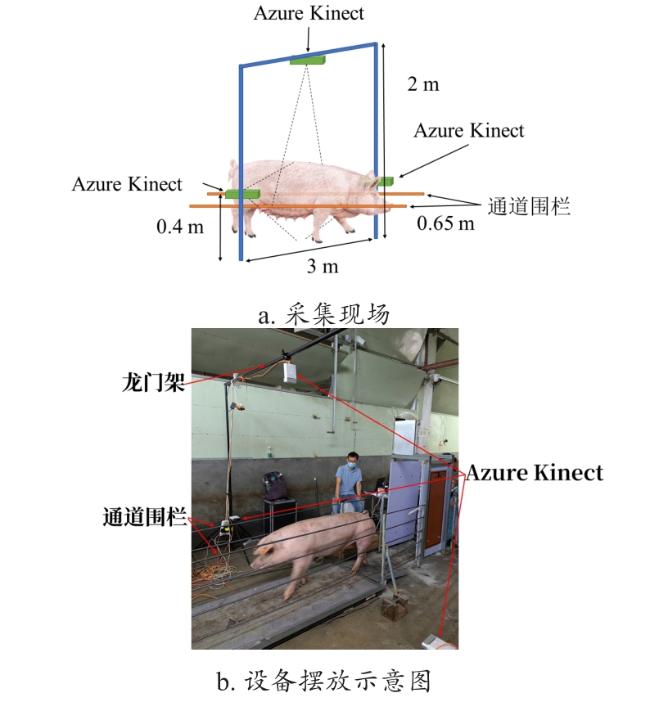
第一次采集得到30头猪的264组点云,去除掉不完整点云以及样本量过少的点云后,得到20头猪,每头猪10组点云,共200组点云,每组都包括了背部、两侧和整体点云,并手工测量了所有受采集猪只的体尺长度数据;第二次采集得到120头猪的1 022组点云,在去除掉不完整点云后,保留了70头猪的610组点云,每组都包括了背部、两侧和整体点云。
研究中进行了边缘提取、神经网络性能和体尺计算三部分实验,边缘提取实验数据集共810个猪体背部点云;关键点生成实验中,人工标记了810组点云作为真值,每组人工标记包括体长测量起始点、前体高和肩宽测量关键点、胸围测量关键点、腹围和腹宽测量关键点、后体高和臀宽测量关键点、体长测量终点以及24~58个根据体长变化的背脊走向点,实验输入的数据集为810个背部点云、各自的边缘点和人工标记的真值经过对称、旋转操作进行数据增强得到的共4 050组数据,每组包括一个背部点云和此背部点云的边缘点,训练时采用随机分割策略,数据分为8∶1∶1的比例分别用作训练集、验证集、测试集;体尺计算实验数据集选取了人工测量过的20头猪,每头10个背部点云、10个完整点云,共400个点云;体长分布实验数据集为从体尺计算实验数据集中根据背脊走向曲线的曲率取姿态变化剧烈的10头,每头10个背部点云,10个完整点云,共200个点云。
1.1.1 配准并提取猪体点云
采集到的点云数据包含有背景,需要提取出猪体目标点云。提取步骤为分别采集通道背景点云集合 ,及含有猪体的点云 ,猪体目标点云为 ,阈值为 ,如公式(1) 所示,根据距离背景点云的距离确定是否为猪体,与背景距离大于阈值的点为猪体点云,时间复杂度为 , 为猪体点数, 为总点数。
1.1.2 噪声点去除
猪体目标点云附着有大量噪声,猪体点云近点噪声由猪体与栏杆之间光线的反复衍射和环境中灰尘等因素产生,噪声点会对边缘提取和关键点生成产生极大的影响。本研究采用统计滤波和半径滤波组合的两级滤波器对猪体点云进行去噪。
统计滤波用于去除离群点,其原理为,设置邻域点数量和标准差,设每个点与邻近点之间的距离服从高斯分布,平均距离为均值,可以根据均值和每一个距离求得标准差,平均距离在标准范围之外的点可以被定义为离群点,并从数据中去除。
半径滤波器则是用于去除小于猪体点云密度的噪声点云。半径滤波器以点云中某一点为中心画一个圆计算落在该圆中点的数量,当数量大于邻域点阈值k,则保留该点,否则剔除该点。
1.1.3 猪体点云平滑
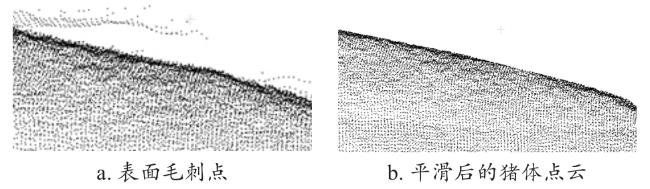
点云经过去噪后,远点噪声和大部分近点噪声基本被去除,但是贴近猪体表面的部分毛刺噪声点(图4a)依旧没有去除。这些毛刺噪声会造成猪体点云表面出现锐利区域,使后续的点云法向量估计出现偏差,造成边缘点提取错误。
1.1.4 猪背部边缘提取
提取猪背部轮廓边缘的目的是获得更加稳定的全局特征,在使用模型提取点云全局几何特征时,三维相机的成像原理导致大量点云集中在背部的平坦区域。平坦区域点在神经网络中提供的特征是相似的,全部输入网络将造成计算资源浪费,故本研究选择采样背部边缘点作为模型第一部分的输入,不仅可以获得稳定的全局特征,而且能极大地减少模型所需的参数量。
背部点云边缘提取算法先根据质点修整点云,再计算每个点的 点法向量并拟合法平面,最后对每个点的 点在其法平面上的投影与其构成的邻边夹角判断是否为边缘点。

计算法平面时,先使用k-d树构建索引并确定每个点的 近邻点,并根据 近邻点使用最小二乘法估计法平面。
在计算得到点云中每一点的法平面后,还需计算点云中每一点和其最近点在法平面上的投影构成的邻边夹角。由于点云具有无序性,在直接计算邻边夹角时需要先进行投影,再经过 级时间复杂度的计算才能确定每个邻边夹角,会额外消耗大量计算资源。
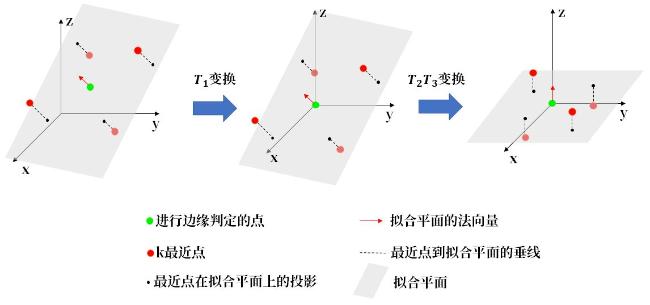
式中: 为将 平移到原点的刚性变换; 为绕 轴的旋转变换; 为法向量在 平面的投影和 轴的夹角; 为绕 轴的旋转变换; 为进行 变换后法向量与 轴的夹角;由于法平面与 重合,此时投影可以直接使用 的 坐标,此方法相比直接投影到法平面再计算极角拥有更低的时间复杂度。
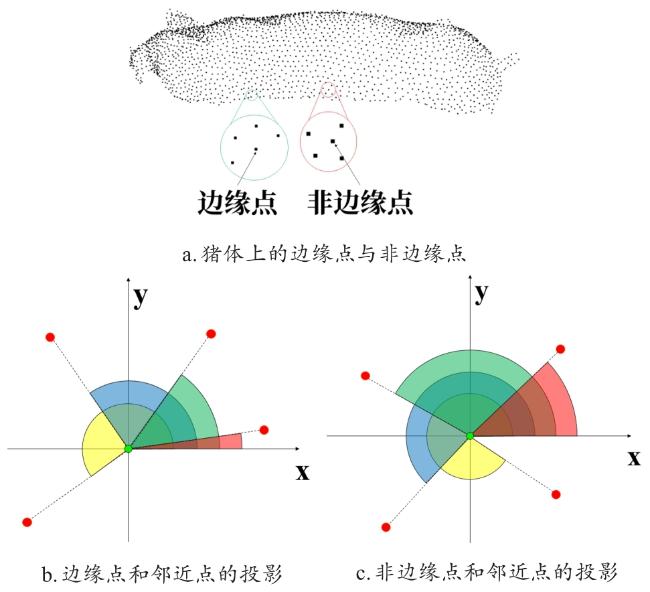
得到极角并从大到小排序后,依次计算极角差得到邻边夹角。
设邻边夹角为 ,则邻边夹角计算如公式(5) 和公式(6) 所示。
式中: 为邻边夹角, 为极角,且 。此时设阈值为 , 时,当前中心点为边缘点。
1.2 体尺计算
本研究设计的体尺算依托于Pig Back Transformer模型获得的体尺关键点和背脊走向点,体尺关键点协助定位各体尺计算区域,背脊走向点曲线拟合可以进行体长计算。
1.2.1 改进的自注意力Pig Back Transformer
猪体背部点云轮廓边缘提取模型是在Transformer网络基础上提出了图 8所示的Pig Back Transformer网络结构。首先进行点云归一化,之后将边缘点云使用最远点采样到32个点作为输入,经Edge Embedding映射,并通过Edge Transformer模块提取特征后由多层感知机得到全局特征点,再输入经过尺寸为0.01的体素降采样和512个点的最远点采样后的完整背部点云,并与全局特征点一起通过Back Embedding完成嵌入,再使用Back Transformer模块提取特征,最后将特征通过多层感知机得到相对偏移,使用偏移和全局特征点求和得到关键点。

下文依次介绍Pig Back Transformer各组件的设计。
1)改进嵌入Edge Embedding 和自注意力 Edge Transformer。
Edge Embedding结构如图9所示,分为两部分。第一部分使用PointNet++[17]中的多层感知机Shared MLP(Multilayer Perceptron)进行映射,Shared MLP使用相同的线性变换将点云中的所有点映射到相同的高维空间中,先经过输入为3个维度,输出为128个维度的卷积,再经过输入为128个维度,输出为128个维度的卷积得到高维点特征 , 将作为edge attention中生成Query( Q )、key( K )、Value( V )矩阵所用的输入;第二部分使用每个点与质心的距离构成向量组作为距离嵌入 , 为edge attention中生成 所用的输入。在Edge Embedding中添加距离嵌入 的原因是相对质心的距离蕴含了点云的几何信息,在获取全局关键点时,自注意力可以根据 为不同的点分配权值,结合使用点云本身的三维位置信息得到的注意力权重,可以使最终得到的注意力权重同时利用到 的全局几何信息和从三维位置信息提取出的局部特征。
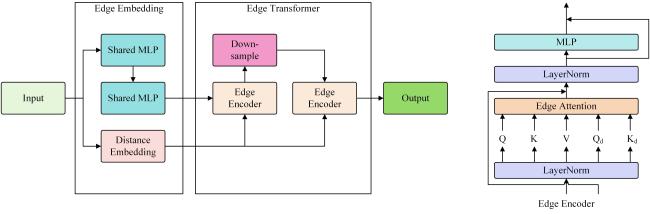
Edge Embedding与Transformer采用了不同的设计。首先没有采用与Transformer中相同的位置编码形式,因为Transformer在Embedding步骤中直接将位置信息添加到了输入的向量中是为了解决self-attention中基于特征提取时会忽略序列顺序导致的词序问题,但是self-attention特征提取的序列无关性却是适合解决点云无序性的关键,所以在进行网络改进的过程中,本文研究选择去除掉位置编码,直接进行特征提取。
其次,Edge Embedding中使用Shared MLP进行提取的设计相对于使用MLP减少了大量的训练参数,Shared MLP为输入点云集合 训练矩阵 进行映射,得到特征 ,此时 的参数量为 , 为特征的维度,若使用MLP进行特征提取,则参数量为 。MLP相对Shared MLP的优点是在进行信息提取时可以将输入进行交叉,而Shared MLP的信息提取是孤立的,只能提取到每个输入自身的高维信息,但是,由于在网络的后续设计中采用了Edge Transformer通过edge attention提取局部和全局信息,所以选择使用Shared MLP作为Embedding步骤的特征提取器。
Edge Transformer使用两层编码器进行一次降采样的结构,编码器中使用了改进的edge attention,其计算如公式(7) 所示。
式中: 分别为使用Shared MLP和距离嵌入得到的特征; 为权值矩阵; 为维度。
改进的自注意力机制添加了与质点之间的距离信息,补充了点的相对位置特征信息。通过叠加点特征和距离特征产生的自注意力权值,能得到更具有代表性的全局特征。
Edge Transformer后使用两层的MLP将得到的特征转化为全局特征点。
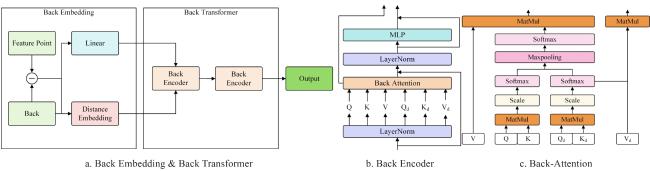
2)改进嵌入Back Embedding 和自注意力 Back Transformer。
Back Embedding如图10所示,分为三部分,第一部分是以背部点与全局特征点作差,得到的向量组作为基于全集特征点的偏移向量组,第二部分是将偏移向量组经过线性映射至64维得到 ,第三部分是使用背部点和偏移向量组构建距离嵌入得到 ,距离嵌入的算法为:
设3行n列的背部点云向量组为 ,3行n列的偏移向量组为 ,质点为 。
的第一维度表示为公式(8) 。
式中: 是每个点到关键点的距离; 为属于 的点。
的第二维度表示为公式(9) 。
式中: 是每个点到质心的距离; 为属于 的点; 为质点。
加入质心和全局特征点偏移的 为神经网络中引入了关于猪体大小和姿态的信息。当猪的大小不同时,两种偏移值的整体都会相应的产生变化。同时, 也蕴含了猪的运动姿态信息。
猪的运动平面在运动解剖学中将分为冠状面、矢状面和横断面,其中冠状面平行于地面,高度位于猪脊柱矢状面垂直于地面、平行于猪脊柱;横断面为同时垂直于地面与猪脊柱的平面,采集过程中发生的主要运动为位于冠状面与矢状面的运动[18]。
当姿态发生冠状面的变化时,如猪左右扭头和左右转身,两侧的质心偏移距离的变化会比较剧烈,若将此时猪背假设为弧形,质心大幅向弧度的中心移动,由于质心的初始位置为接近猪背部中心点,所以猪前侧和后侧与质心的距离减小,中心处与质心的距离增加,同时两侧的减小量比中心的增加量要更大;而全局特征点在学习过程中会发生沿猪的背脊走向移动的整体倾向,此时偏移距离变化较小的部分为移动较少的部分,隐式地表述猪发生运动的关节位置。
当猪姿态发生矢状面变化时,如猪低头、抬头、弓背,由于网络中只使用了猪背部点云,因此对于中心的质心偏移量影响会更大,此时的前后侧偏移距离也是具有前侧和后侧与质心距离减小,中部点与质心距离增加的趋势,同时两侧的减小量比中心的增加量更小;全局特征点在此时会向中心收缩,导致全局偏移量和质心偏移量的相似度提高。
最终, 可以在其张量空间上通过距离隐式含有猪的不同姿势和大小信息。
Back Transformer通过两层连续的编码器组成。编码器结构改进为同时输出提取到点云的特征和距离特征,同时注意力部分使用了改进的back attention结构。back attention的设计如公式(10) 和公式(11) 所示。
式中: 分别为使用线性层和双重距离嵌入得到的特征; 为权值矩阵; 为维度。
相比self attention结构,back attention加入了距离信息作为额外的注意力来源。与edge attention中的叠加自注意权值的做法不同的是,back attention中对 和 的自注意力权值进行了按位max pooling的操作,采用max pooling的原因是 蕴含了足够的信息,使其产生的自注意力具备较强代表性,所以通过max pooling后得到的自注意力权值可以同时兼顾对求解关键点需要的全局信息、相对位置信息和姿态信息。
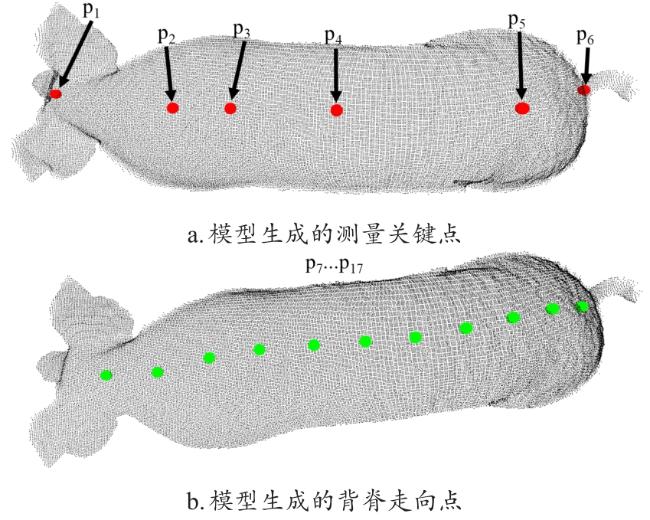
3) 标记与损失函数
本研究中每个猪背部点云标记了6个测量关键点和多个背脊走向点,如图12所示,测量关键点从头至尾依次为:体长测量起点,前体高、肩宽关键点,胸围关键点,腹围、腹宽关键点,后体高、臀宽关键点,以及体长测量终点。
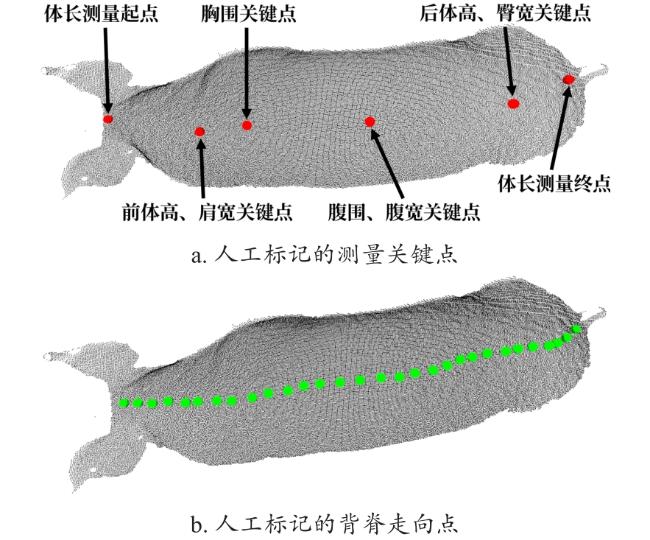
损失函数包含三个目标。第一个目标是最小化生成的点和人工标注的测量关键点的距离;第二个目标是按顺序生成尽可能近的脊背点;第三个目标是降低相邻生成点间距的方差,缩小方差可以使生成点的分布更加均匀,均匀的分布可以使生成点对背脊线的拟合程度更高,提高体尺计算精度。
损失函数如公式(12)~公式(18) 所示。
式中: 表示第 个生成点; 表示第 个人工标记的测量关键点; 为生成的6个测量关键点和人工标记的6个测量关键点对应的距离。
式中: 为 与人工标记背脊走向点集合中的最近点; 为 与人工标记背脊走向点集合中第二近点; 表示每个点与躯干上最近点的距离,用来约束生成点的精度; 表示的是生成的点和躯干的偏差,用来约束生成的点落在Ground Truth走向上的程度; 表示的是生成点间连线的方向是否一致,用来约束生成点的顺序。
式中: 为点 和点 间的距离; 为相邻点之间的平均距离; 为相邻点间距离的方差,用来约束生成点的均匀性,当点越均匀时相邻点之间的平均距离的方差越小,此时脊背线走向点的分布更加均匀。
1.2.2 猪体尺算法
本研究依据Pig Back Transformer产生的体尺关键点和背脊走向点,设计了对应的求体长、前体高、后体高、肩宽、腹宽、臀宽、胸围、臀围的算法。
开始体尺计算前,首先要将地面调整到 平面,计算模型生成点在 的最近点集合 ,并使用RANSAC(Random sample consensus)算法[19]拟合得到地面方程,将 和 根据地面方程旋转,使地面法向量平行于 轴且与 平面距离为0。
1)体长关键点如图13所示,红色为头部和尾部关键点,分别位于两耳中心和尾部末端,绿色为背部曲线拟合点。
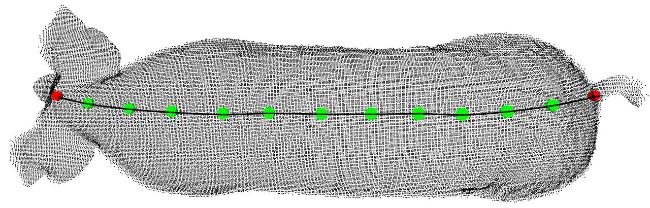
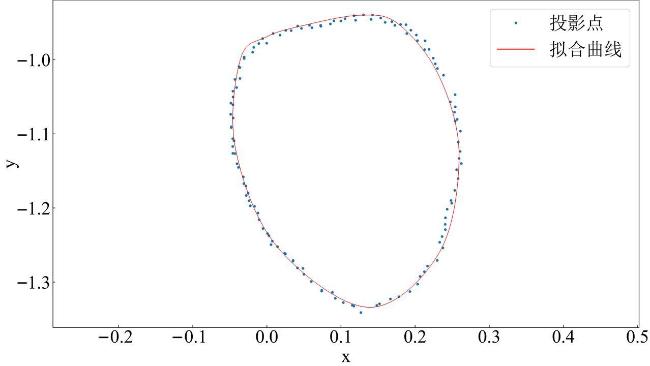
将头尾的测量关键点 ,11个背脊走向点 ~ 和背部点云都投影到 平面上,对头尾关键点和11个背脊走向点的投影进行最小二乘拟合背脊走向曲线,再以2 cm为间隔在曲线上取得曲线和点云投影最近点点集 ,将 映射回背部点云得到 ,体长为 的点间距之和。
2)体高关键点如图14a所示,左侧为前体高测量点,位于肩胛中心,右侧为后体高测量点,位于髋部顶部。
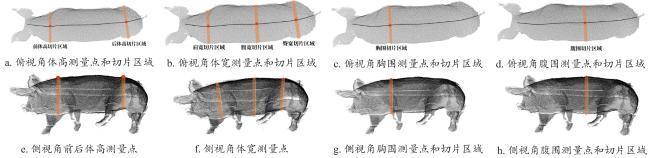
前体高为前体高关键点处沿垂直于走向曲线做切片得到集合 中前10%高点的平均高度:
后体高为后体高关键点处沿垂直于走向曲线做切片得到集合 中前10%高点的平均高度:
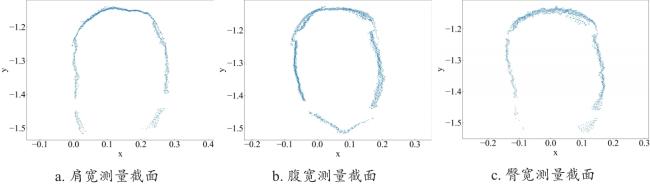
3)体宽关键点如图14b所示,从左到右依次为肩宽、腹宽、臀宽测量点。
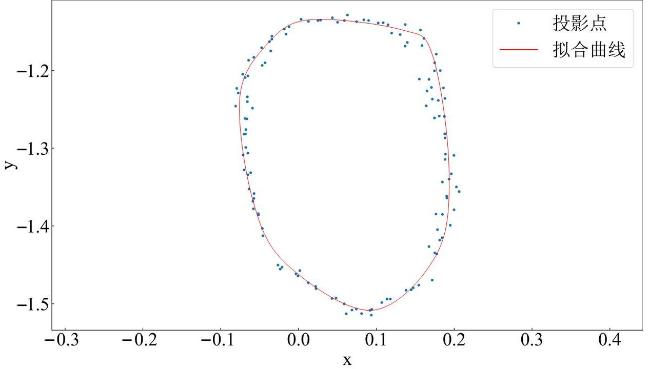
腹宽计算方法为在腹宽关键点处使用与肩宽相同算法得到。测量截面如图15b所示。
臀宽计算方法为在臀宽关键点处使用与肩宽相同算法得到。测量截面如图15c所示。
2 实验结果与分析
实验使用的硬件为AMD Ryzen Threadripper PRO 3995WX CPU和 RTX 3090 GPU,操作系统为Linux,神经网络框架为Pytorch。
2.1 边缘提取
边缘提取实验前先对点云进行体素大小为0.01的体素降采样,再使用最远点降采样将点云降采样至2 048个点提升计算速度。
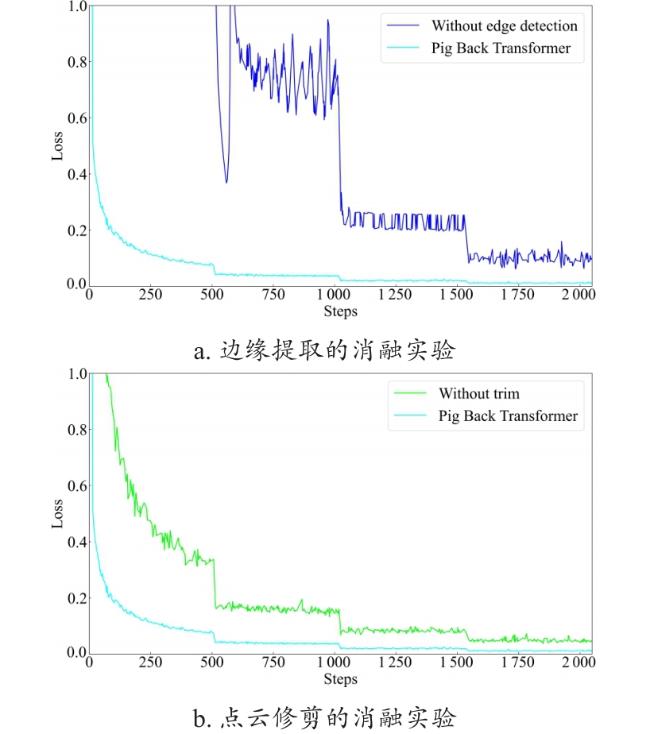
边缘提取效果如图18所示,可以看出本研究提出的边缘提取算法提取出了猪背部点云的边缘,泛化性较强,可以用于不同姿态下的猪背部点云。

但是,从图19所示的侧视角可以看到,点云边缘的曲率变化剧烈、连续性较差,在使用Shared MLP对边缘点云提取特征时,如果不对点云边缘进行预处理,会导致训练过程中边缘点中提取的特征不具有代表性,影响网络的性能和训练时的稳定性,此问题出现的原因是Shared MLP会对输入的点云中的所有点进行相同的线性映射,所以当样本相似度较低时有可能出现欠拟合现象。

而在经过修剪后的边缘提取结果如图20所示,连续性更强,边缘更平整,受猪的姿态影响更小,在神经网络训练时性能更好,稳定性更强。
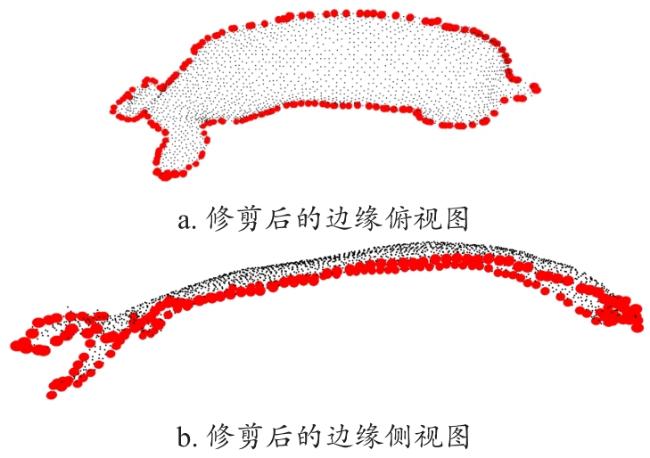
在后续的神经网络训练实验中进一步量化修剪与否的稳定性和性能差异。
2.2 关键点生成
在关键点生成实验中,Pig Back Transformer模型参数量为10 M,数据集为前文介绍的人工标记的810组数据,通过旋转、轴对称操作将数据增强到4 050个点云。
2.2.1 与其他模型的对比
表 1 不同模型的关键点拟合结果Table 1 Key points generated by different models |
| 模型 | Loss | 关键点平均偏差 | 点间距方差 | 参数量/M |
|---|---|---|---|---|
| PointNet++ | 0.061 | 0.009 | 0.001 5 | 8.7 |
| Point Transformer V2[20] | 0.052 | 0.008 | 0.001 5 | 11.0 |
| Point Cloud Transformer[21] | 0.074 | 0.012 | 0.002 1 | 10.5 |
| OctFormer[22] | 0.037 | 0.005 | 0.001 0 | 11.8 |
| PoinTr[23] | 0.082 | 0.013 | 0.001 8 | 10.1 |
| Pig Back Transformer(无边缘提取模块) | 0.091 | 0.015 | 0.001 5 | 9.8 |
| Pig Back Transformer | 0.013 | 0.002 | 0.001 1 | 10.3 |
|
关键点与背脊走向点生成效果如图21所示,PointNet++的生成点均匀度较好,但关键点和走向点的平均偏差较高,OctFormer的关键点和走向点平均偏差都较低,均匀度表现为实验中最好,Pig Back Transformer精度表现最好,均匀度满足测量需求。
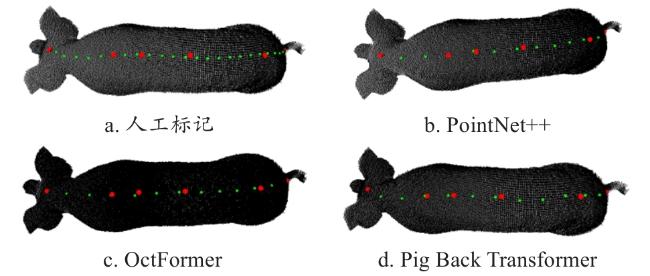
2.2.2 消融实验
2.3 体尺计算
2.3.1 与人工测量结果对比
选取了第一次采集的20头猪体,使用每头猪10个点云计算体尺数据并取平均值作为体尺计算结果并与人工结果进行对比(表2)。
表 2 Pig Back Transformer模型体尺计算结果与人工体尺测量的误差Table 2 Error comparing body size calculated by Pig Back Transformerwith human measured result |
| 体尺类型 | 平均相对 误差/% | 平均误差/cm | 最大误差/cm | 误差标准差 |
|---|---|---|---|---|
| 体长 | 0.63 | 0.729 | 1.982 | 0.079 |
| 前体高 | 1.85 | 1.132 | 2.264 | 2.199 |
| 后体高 | 2.38 | 1.610 | 3.395 | 0.678 |
| 肩宽 | 2.68 | 0.832 | 2.264 | 2.348 |
| 腹宽 | 1.22 | 0.369 | 0.851 | 0.435 |
| 臀宽 | 5.46 | 1.747 | 3.608 | 1.194 |
| 胸围 | 4.02 | 4.200 | 3.170 | 2.910 |
| 腹围 | 3.95 | 4.585 | 2.966 | 2.831 |
结果表明,体长的相对和平均误差结果较好,但由于猪体变化导致的最大误差仍然较高。当猪体发生冠状面变化时,体表皮肤会发生拉伸,对此时采集到的点云进行体长计算会产生较大的误差。
前体高平均误差和最大误差都好于后体高,但标准差比后体高更高,产生这种现象的原因是算法设计过程中未考虑猪在行走过程中后体高测量处出现肌肉隆起,导致整体存在较高的误差。前体高平均误差较低,但是偶有发生在行走过程中低头的现象,导致误差不稳定,故前体高有较高的误差标准差。
腹宽的平均相对误差、平均误差、最大误差和误差标准差结果相对肩宽和臀宽都更好,产生这种现象的原因有两点:一是猪体发生姿态变化时腹宽相对肩宽与臀宽发生的变化会更小;二是肩宽与臀宽的截面截取算法在应对姿态改变时需要优化,由于行走时腿部连线并不垂直于背脊线,所以算法所截平面与实际物理平面存在误差。
胸围与腹围的测量结果都较差,是由于两侧相机视角与地面的相对高度较高,部分点云出现了的较大范围的腹部和胸部空洞,这些空洞导致通过极坐标最小二乘拟合算法得到的胸部、腹部曲线与猪体实际的物理形状相差较大,因此产生了较大的误差。
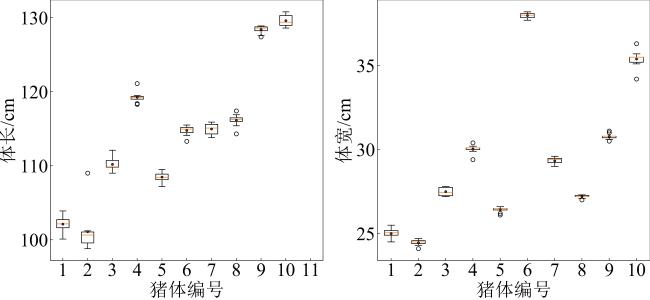
2.3.2 猪体姿态剧烈变化对体尺的影响
表 3 猪姿态剧烈变化时的体长测量结果Table 3 Body length results when pig's posture changed significantly |
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 人工测量结果/cm | 102.0 | 100.0 | 111.0 | 120.0 | 108.0 | 115.0 | 115.0 | 116.0 | 127.0 | 129.0 |
| 结果1/cm | 102.5 | 99.1 | 111.1 | 121.1 | 108.4 | 114.1 | 115.0 | 116.3 | 127.4 | 128.9 |
| 结果2/cm | 102.2 | 100.1 | 112.1 | 119.5 | 108.1 | 114.4 | 114.0 | 116.0 | 128.9 | 130.4 |
| 结果3/cm | 101.1 | 98.8 | 109.8 | 119.0 | 108.9 | 113.3 | 113.8 | 116.5 | 128.8 | 128.6 |
| 结果4/cm | 102.1 | 109.0 | 109.4 | 118.4 | 107.2 | 114.7 | 114.6 | 116.2 | 127.6 | 129.4 |
| 结果5/cm | 101.5 | 101.1 | 109.9 | 118.3 | 109.0 | 115.1 | 114.2 | 116.0 | 128.4 | 128.6 |
| 结果6/cm | 100.1 | 101.2 | 109.8 | 119.2 | 108.0 | 115.5 | 115.8 | 116.4 | 128.6 | 130.7 |
| 结果7/cm | 102.0 | 100.8 | 109.8 | 119.3 | 108.5 | 115.0 | 115.6 | 114.3 | 128.7 | 130.8 |
| 结果8/cm | 103.9 | 100.9 | 109.0 | 119.3 | 109.5 | 115.5 | 115.2 | 115.4 | 128.8 | 129.2 |
| 结果9/cm | 102.9 | 100.5 | 109.9 | 119.0 | 108.2 | 115.2 | 115.6 | 117.4 | 128.2 | 130.0 |
| 结果10/cm | 102.8 | 99.4 | 111.0 | 119.4 | 108.8 | 114.9 | 115.9 | 116.9 | 128.6 | 129.4 |
表 4 猪姿态剧烈变化时的腹宽测量结果Table 4 Abdomen width results when posture changed significantly of pig |
| 编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| 人工测量结果/cm | 25.0 | 25.0 | 27.0 | 30.0 | 27.0 | 38.0 | 29.0 | 27.0 | 30.0 | 35.0 |
| 结果1/cm | 25.1 | 24.5 | 27.8 | 30.1 | 26.5 | 38.1 | 29.5 | 27.2 | 31.0 | 35.5 |
| 结果2/cm | 25.1 | 24.4 | 27.5 | 29.4 | 26.4 | 38.0 | 29.4 | 27.3 | 30.8 | 35.1 |
| 结果3/cm | 25.2 | 24.4 | 27.4 | 30.2 | 26.6 | 38.0 | 29.4 | 27.1 | 30.8 | 35.1 |
| 结果4/cm | 25.3 | 24.3 | 27.6 | 30.1 | 26.5 | 38.0 | 29.4 | 27.2 | 30.7 | 35.5 |
| 结果5/cm | 25.5 | 24.5 | 27.8 | 30.1 | 26.2 | 37.8 | 29.5 | 27.0 | 31.1 | 36.3 |
| 结果6/cm | 24.9 | 24.1 | 27.8 | 29.9 | 26.5 | 37.8 | 29.0 | 27.2 | 30.8 | 35.5 |
| 结果7/cm | 24.9 | 24.5 | 27.4 | 30.0 | 26.1 | 37.7 | 29.0 | 27.2 | 30.5 | 35.7 |
| 结果8/cm | 24.5 | 24.6 | 27.2 | 30.4 | 26.5 | 38.1 | 29.3 | 27.2 | 30.6 | 34.2 |
| 结果9/cm | 25.0 | 24.6 | 27.2 | 30.1 | 26.5 | 38.2 | 29.6 | 27.3 | 30.8 | 35.5 |
| 结果10/cm | 24.5 | 24.7 | 27.2 | 30.0 | 26.4 | 38.1 | 29.2 | 27.3 | 30.7 | 35.5 |
3 讨 论
3.1 Pig Back Transformer实验中的不足
Pig Back Transformer的实验中存在两点不足。第一是未使用公共数据集进行关键点生成实验。公开数据集的多样性能对模型的泛化性进行更充分的测试,同时使用公开数据集进行实验结果会更具有公信力,但两个问题导致了无法使用公开数据集进行实验:首先,目前公开数据集中的关键点均为关键点配对任务,与本研究所需的提取测量关键点任务不同,无法作为本研究的性能指标,也无法进行迁移;其次,本研究采用了点云边缘提取,因为观察到猪背部点云的边缘蕴含的几何信息对整个猪背部点云具有代表性,而公开数据集则不符合此情况。第二是由于边缘提取部分与编码器设计耦合程度太高,导致边缘提取模块和注意力机制的消融实验无法独立进行。
3.2 Pig Back Transformer模型的不足和改进方向
本模型的不足之处有两点。第一是自动化程度仍存在提高空间,由于构建训练集时采用人工剔除掉不完整点云,若直接将本模型应用在生产环境中,便需要人工确定猪体点云是否超出摄像机采集范围。第二是对点云形状的兼容范围不够广,由于采用了边缘提取作为部分输入,算法的适用范围为某一视角的点云存在足够提取出稳定的全局关键点的几何信息。
模型存在四个可改进方向。第一,通过深度图和同时拍摄的二维图像进行关键点检测。深度图在像素上与点云一一对应,并且自身存在结构化信息,可以使用二维计算机视觉方法如YOLO等进行关键点检测,定位到像素点后再映射到点云中的对应点即可进行体尺计算,但是点云作为经过相机内参转换的深度图蕴含了相机内参,而使用深度图和二维图像进行目标检测则缺少这部分信息。第二,利用深度图与点云一一对应的关系,将降噪和去除背景后的点云结构化并利用机构化信息提高特征提取性能。第三,可以通过投影的方法提升模型的适用范围,将完整点云分别投影到不同视角,如投影到 平面,再进行不同视角下的边缘提取,最后通过多视角下的边缘点集输入模型生成关键点。第四,设计算法检测猪体点云是否超出摄像机采集范围,自动构建模型训练所需数据集,同时提高生产环境中的自动化程度。
4 结 论
本研究设计的关键点生成模型Pig Back Transformer有较高的关键点生成精度,相对其他的点云处理网络有较大提升,关键点平均偏差为0.2 cm,解决了猪体尺测量中的关键点定位和背脊走向拟合问题。依托体尺测量关键点构建的体尺算法在体长、体高、体宽测量上获得了较高精度,体长的平均相对误差为0.63%,相对其他研究方法有较大提升。同时,提出的算法能较好地处理动物运动过程中体态的变化,在姿态剧烈变化下体尺的分布较为集中,只有少量异常值产生,具有较好的泛化性,可以改善采集过程中因姿态变化产生的体尺测量误差。
综上所述,本研究设计的种猪体点云关键点生成模型,提高了关键点生成精度。根据关键点和背部走向设计的体尺计算算法,降低了无接触测量的误差。得到的高精度无接触体尺测量结果可以为猪育种工作提供坚实的数据基础。





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}