Smart Agriculture ›› 2025, Vol. 7 ›› Issue (5): 88-100.doi: 10.12133/j.smartag.SA202505007
• Special Issue--Opto-Intelligent Agricultural Innovation Technology and Application • Previous Articles Next Articles
XIE Yuxin, WEI Jiangshu( ), ZHANG Yao, LI Fang
), ZHANG Yao, LI Fang
Received:2025-05-07
Online:2025-09-30
Foundation items:The University Industry Collaborative Education Program of The Ministry of Education(22097077265201); Ya'an Digital Agriculture Engineering Center Construction Project
About author:XIE Yuxin, E-mail: 1958033734@qq.com
corresponding author:
CLC Number:
XIE Yuxin, WEI Jiangshu, ZHANG Yao, LI Fang. Chinese Tea Pest and Disease Named Entity Recognition Method Based on Improved Boundary Offset Prediction Network[J]. Smart Agriculture, 2025, 7(5): 88-100.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.smartag.net.cn/EN/10.12133/j.smartag.SA202505007
Table 1
Information statistics table of Chinese tea pest and disease text named entity recognition dataset
| 标签 | 类别定义 | 示例 | 实体数量/个 |
|---|---|---|---|
| DISEASE | 病害(Disease) | 茶炭疽病病 | 196 |
| PEST | 虫害(Pest) | 茶尺蠖 | 622 |
| PART | 受害茶叶的部位(Part) | 成叶、嫩叶 | 836 |
| LOC | 地区(Location) | 四川、安徽、江苏 | 1 066 |
| COL | 颜色(Color) | 黑褐色、淡黄色 | 1 641 |
| SHA | 形状(Shape) | 椭圆形、灰白色尘末状 | 1 272 |
| OPE | 防控操作(Operator) | 选用抗病品种、加强茶园管理 | 956 |
| MED | 处理受害的药剂(Medicine) | 马拉硫磷乳油、晶体石硫合剂 | 942 |
| FEA | 病虫特征(Feature) | 浅黄色蜡粉、暗褐色波状横纹 | 872 |
| SYM | 受害症状(Symptom) | 水渍状暗绿色病斑、树势衰弱 | 617 |
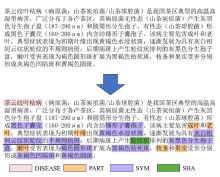
Fig. 1
Example of dataset labeling for Chinese tea pest and disease

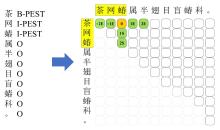
Fig. 2
Schematic diagram of boundary offset
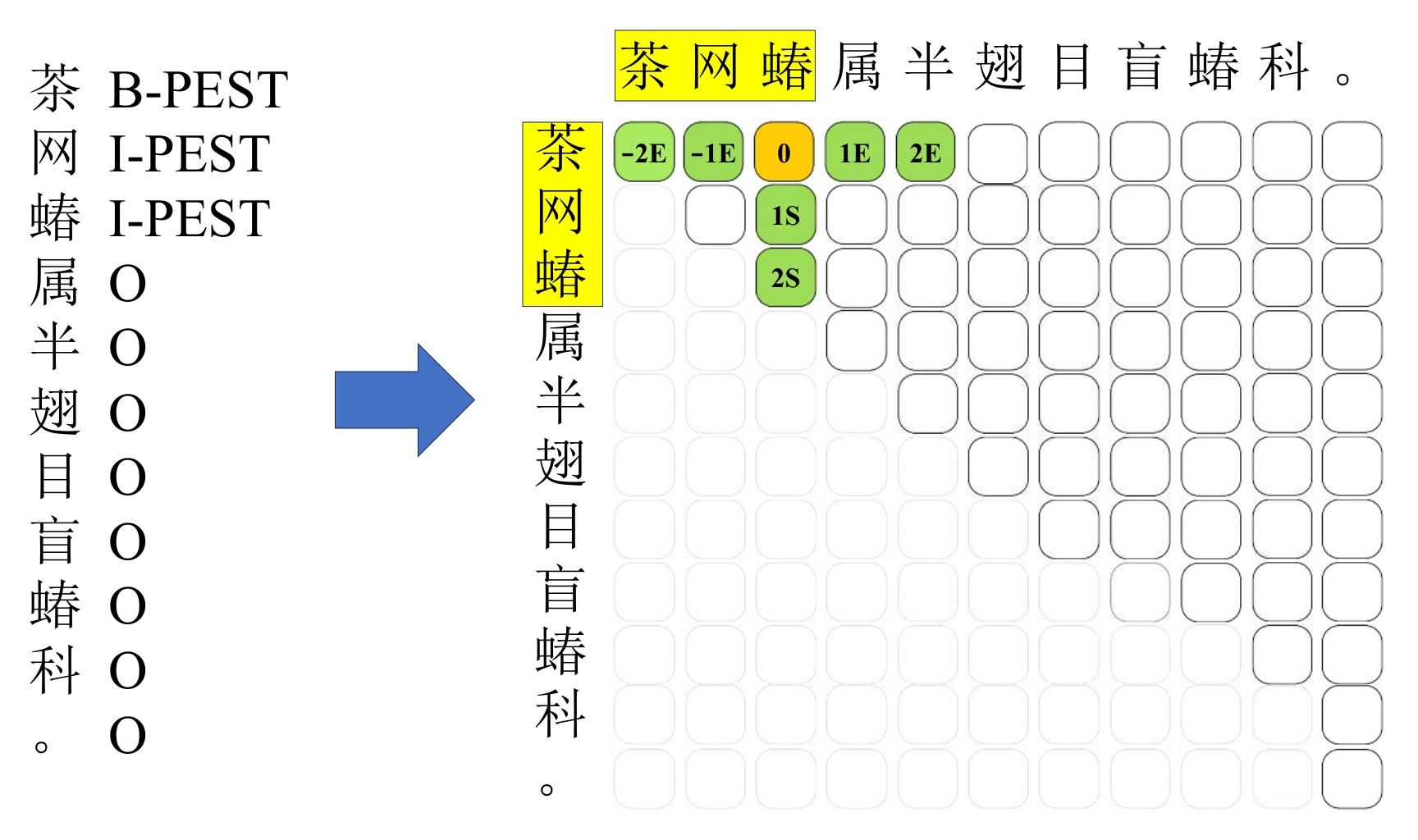

Fig. 3
Overall framework of the Be-BOPN model and the boundary prediction module
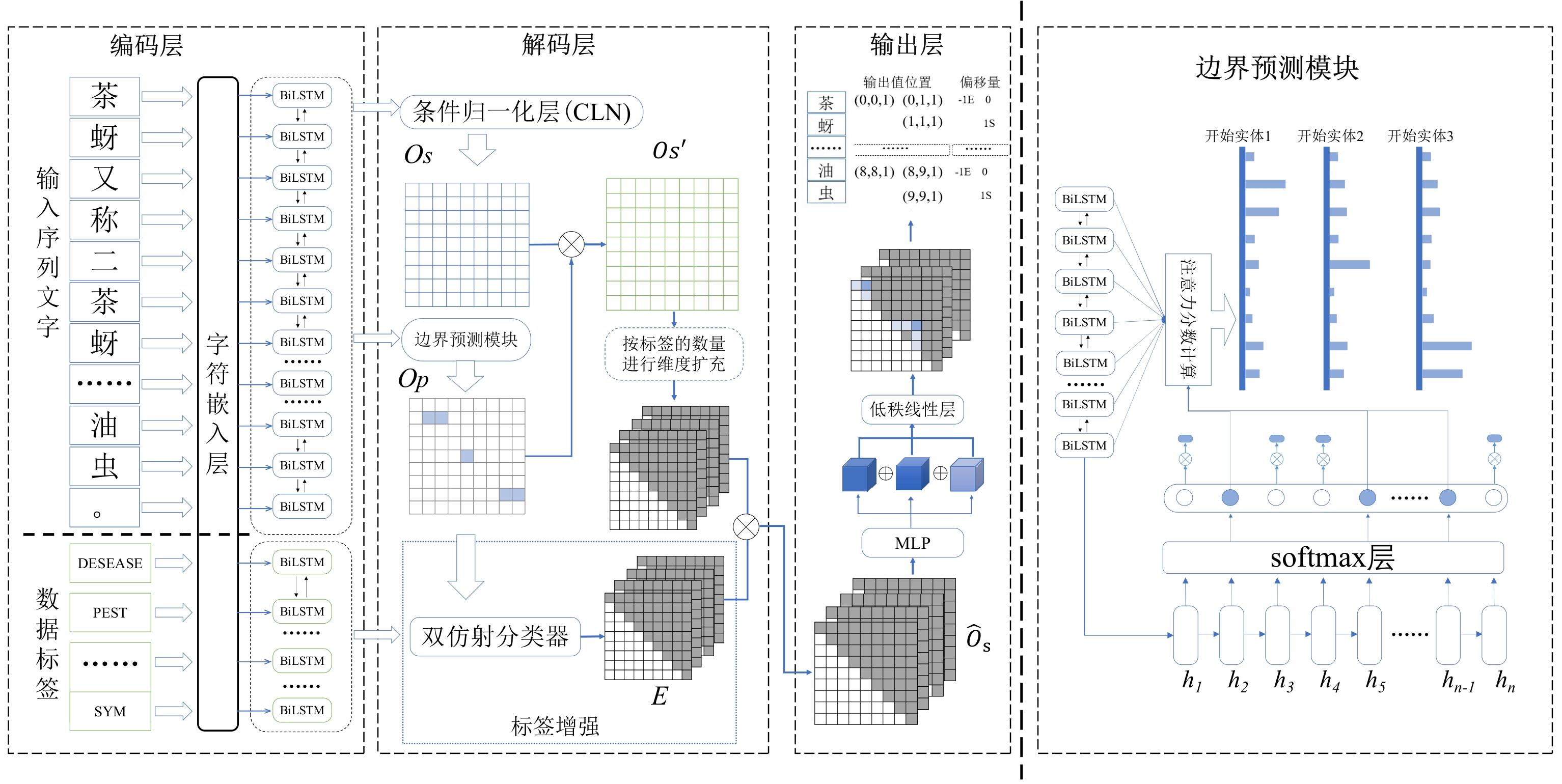
Table 2
Chinese public dataset statistics
| 数据集 | 划分 | 句子数 | 实体数 | 类别 | 数据集 | 划分 | 句子数 | 实体数 | 类别 |
|---|---|---|---|---|---|---|---|---|---|
| ResumeNER[ | 训练集 | 3 821 | 13 343 | 8 | CLUENER(Chinese Language Understanding Evaluation NER)[ | 训练集 | 10 748 | 23 971 | 10 |
| 测试集 | 477 | 1 630 | 测试集 | 1 343 | 3 072 | ||||
| 验证集 | 463 | 1 488 | |||||||
| WeiboNER[ | 训练集 | 1 350 | 1 885 | 4 | Taobao[ | 训练集 | 6 000 | 29 397 | 4 |
| 测试集 | 270 | 414 | 测试集 | 1 000 | 4886 | ||||
| 验证集 | 270 | 389 | 验证集 | 998 | 4941 |
Table 3
Introduction for basic models
| 模型 | 模型特点 |
|---|---|
| BiLSTM-CRF(Bidirectional Long Short-Term Memory- Conditional Random Field)[ | 基于双向LSTM和条件随机场,通过序列标注实现高效的扁平实体识别 |
| Lattice[ | 使用字符-词汇混合编码的方法,避免中文分词错误对NER的影响 |
| Flat[ | 一种基于扁平化结构的方法,通过优化Lattice架构显著提升中文NER效率 |
| SoftLexicon[ | 一种基于字符级词汇融合的方法,简化模型结构同时保持较高准确率 |
| MECT(Multi-Metadata Embedding based Cross-Transformer)[ | 一种基于汉字结构和字根特征的方法,可以通过多源语义融合增强中文NER效果 |
| BOPN | 通过预测候选跨度与实体跨度之间的边界偏移进行分类,有效捕捉实体的边界信息 |
| W2NER | 基于词对关系建模的方法,通过构建二维的词对网格来捕捉相邻词语关系,解决传统NER模型的边界识别问题 |
| Boundary Smooth[ | 使用概率重分配,通过平滑实体边界概率来提升模型泛化能力 |
| DiFiNet[ | 边界感知的嵌套NER模型,通过双仿射跨度表示和自适应语义区分模块解决现有方法边界检测弱、对小变化不敏感的问题,并利用边界过滤模块减轻噪声干扰 |
Table 4
Comparative experimental results of Be-BOPN model on Chinese tea-pad dataset
| 模型 | F 1值/% | P/% | R/% |
|---|---|---|---|
| BiLSTM | 73.43 | 70.83 | 76.23 |
| Lattice | 79.03 | 79.33 | 78.73 |
| Flat | 80.40 | 78.65 | 82.22 |
| SoftLexicon | 77.80 | 78.01 | 77.51 |
| MECT | 80.67 | 80.48 | 80.87 |
| Boundary Smooth | 82.39 | 80.39 | 84.61 |
| W2NER | 81.85 | 79.89 | 83.90 |
| DiFiNET | 82.31 | 80.99 | 83.68 |
| BOPN | 82.08 | 79.18 | 85.20 |
| Be-BOPN | 82.76 | 80.36 | 85.31 |
Table 5
Experimental results of Be-BOPN model on the ResumeNER Chinese dataset
| 模型 | F 1值/% | P/% | R/% |
|---|---|---|---|
| BiLSTM | 91.87 | 92.32 | 91.42 |
| Lattice | 94.46 | 94.81 | 94.11 |
| Flat | 95.86 | — | — |
| SoftLexicon | 96.11 | 96.08 | 96.13 |
| MECT | 95.98 | — | — |
| Boundary Smooth | 95.59 | 95.41 | 95.77 |
| W2NER | 96.21 | 95.97 | 96.44 |
| DiFiNET | 96.41 | 96.50 | 96.32 |
| BOPN | 96.35 | 95.73 | 96.97 |
| Be-BOPN | 96.64 | 96.49 | 96.79 |
Table 6
Experimental results of Be-BOPN model on WeiboNER Chinese dataset
| 模型 | F 1值/% | P/% | R/% |
|---|---|---|---|
| BiLSTM | 48.21 | 51.47 | 45.34 |
| Lattice | 58.79 | 53.04 | 62.25 |
| Flat | 68.55 | — | — |
| SoftLexicon | 70.50 | 70.94 | 67.02 |
| MECT | 70.43 | — | — |
| Boundary Smooth | 72.66 | 70.16 | 75.36 |
| W2NER | 72.32 | 70.84 | 73.87 |
| DiFiNET | 73.21 | 72.51 | 73.91 |
| BOPN | 72.79 | 71.03 | 74.64 |
| Be-BOPN | 73.75 | 71.33 | 76.33 |
Table 7
Experimental results of Be-BOPN model on CLUENER Chinese dataset
| 模型 | F 1值/% | P/% | R/% |
|---|---|---|---|
| BiLSTM | 72.35 | 74.18 | 70.61 |
| Lattice | 75.86 | 77.75 | 74.06 |
| Flat | 79.42 | 78.21 | 80.66 |
| SoftLexicon | 74.17 | 76.57 | 71.91 |
| MECT | 76.84 | 76.19 | 77.51 |
| Boundary Smooth | 79.54 | 79.48 | 79.89 |
| W2NER | 79.79 | 79.35 | 80.23 |
| DiFiNET | 80.02 | 80.12 | 79.92 |
| BOPN | 79.77 | 74.72 | 85.55 |
| Be-BOPN | 80.47 | 80.38 | 80.57 |
Table 8
Experimental results of Be-BOPN model on Taobao Chinese dataset
| 模型 | F 1值/% | P/% | R/% |
|---|---|---|---|
| BiLSTM | 77.20 | 77.81 | 76.59 |
| Lattice | 81.98 | 82.63 | 81.34 |
| Flat | 82.05 | 81.71 | 82.39 |
| SoftLexicon | 79.22 | 78.94 | 79.51 |
| MECT | 84.22 | 83.11 | 85.36 |
| Boundary Smooth | 87.94 | 87.35 | 88.55 |
| W2NER | 88.81 | 87.95 | 89.68 |
| DiFiNET | 88.81 | 88.38 | 89.25 |
| BOPN | 88.47 | 87.31 | 89.66 |
| Be-BOPN | 88.97 | 88.27 | 89.68 |
Table 9
Results of ablation experimental for the Be-BOPN Model
| 试验 | 基础模型 | 边界预测 | 标签增强 | 轻量化卷积 | F 1值/% | P/% | R/% |
|---|---|---|---|---|---|---|---|
| 1 | √ | — | — | — | 82.08 | 79.18 | 85.20 |
| 2 | √ | √ | — | — | 82.17 | 80.78 | 83.60 |
| 3 | √ | — | √ | — | 82.33 | 80.84 | 83.89 |
| 4 | √ | — | — | √ | 82.34 | 79.72 | 85.14 |
| 5 | √ | √ | — | √ | 82.25 | 80.88 | 83.66 |
| 6 | √ | — | √ | √ | 82.21 | 79.47 | 85.14 |
| 7 | √ | √ | √ | — | 82.38 | 79.73 | 85.20 |
| 8 | √ | √ | √ | √ | 82.76 | 80.36 | 85.31 |
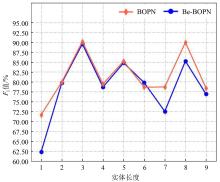
Fig. 4
Performance of entities of different lengths on the Chinese tea pest and disease
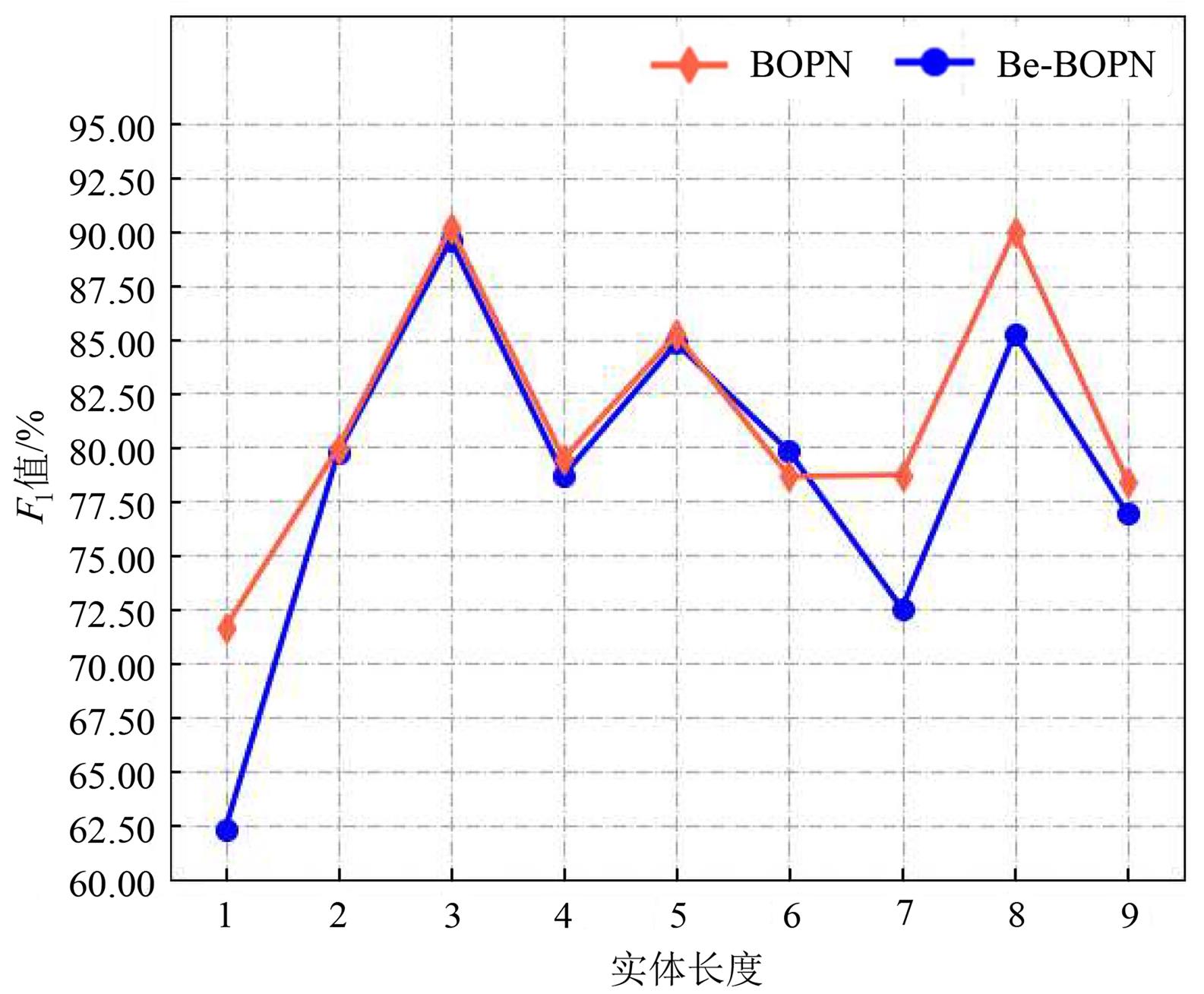
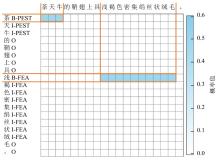
Fig. 5
Visualization of the entity boundary predictionfor boundary prediction module
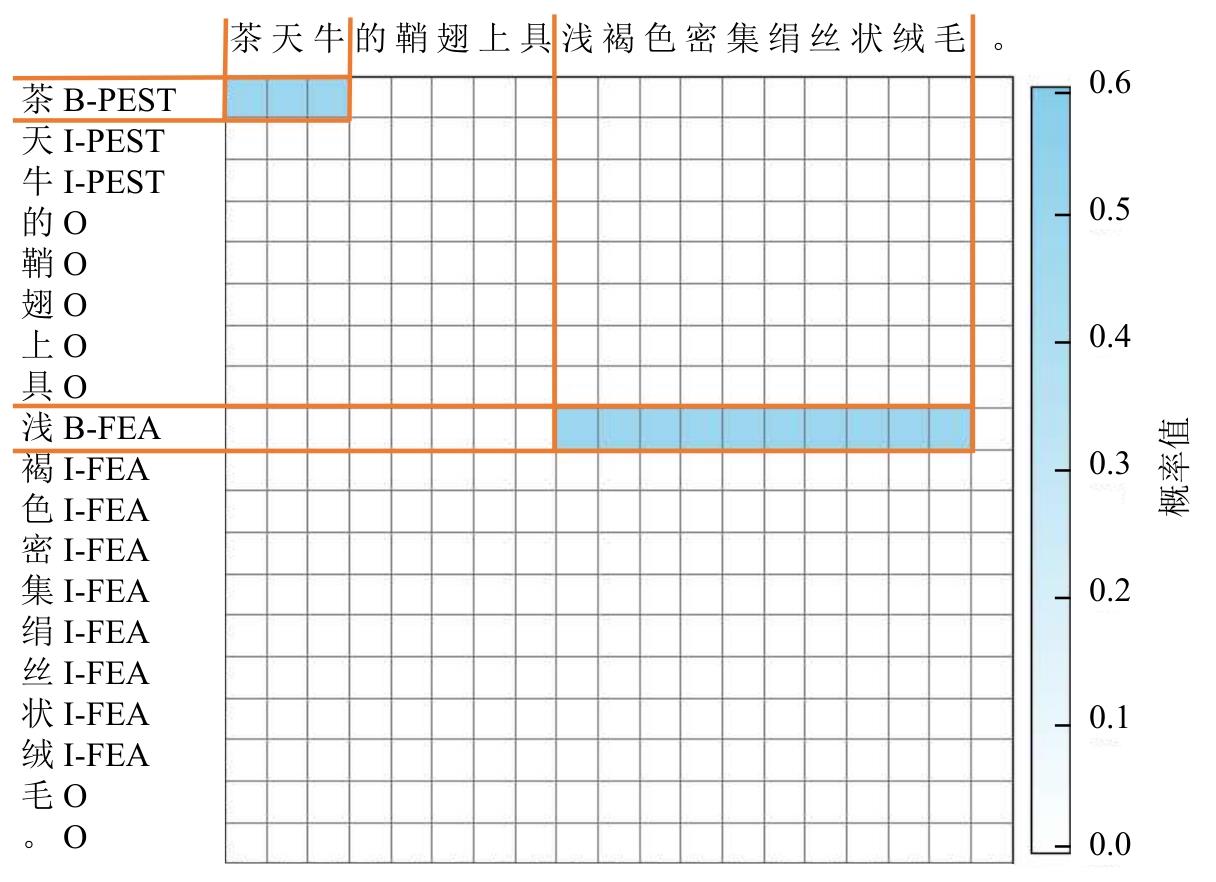
Table 10
Identification effects of different models for different categories of Chinese tea pest and disease
| 标签 | 类别定义 | BiLSTM | SoftLexicon | BOPN | Be-BOPN |
|---|---|---|---|---|---|
| DISEASE | 病害 | 69.15 | 96.69 | 79.46 | 81.18 |
| PEST | 虫害 | 69.15 | 90.58 | 99.98 | 99.99 |
| PART | 茶叶部位 | 62.53 | 65.41 | 79.02 | 81.52 |
| LOC | 地区 | 99.58 | 93.07 | 79.66 | 77.73 |
| COL | 颜色 | 90.96 | 92.67 | 80.49 | 78.71 |
| SHA | 形状 | 78.65 | 84.70 | 80.60 | 89.17 |
| OPE | 防控操作 | 74.04 | 70.58 | 80.10 | 81.30 |
| MED | 药剂 | 92.99 | 91.57 | 82.95 | 83.37 |
| FEA | 病虫特征 | 75.75 | 75.51 | 81.46 | 88.01 |
| SYM | 受害症状 | 76.10 | 66.50 | 82.26 | 83.02 |
| [1] |
聂啸林, 张礼麟, 牛当当, 等. 面向葡萄知识图谱构建的多特征融合命名实体识别[J]. 农业工程学报, 2024, 40(3): 201-210.
|
|
|
|
| [2] |
王彤, 王春山, 李久熙, 等. 基于RoFormer预训练模型的指针网络农业病害命名实体识别[J]. 智慧农业(中英文), 2024, 6(2): 85-94.
|
|
|
|
| [3] |
齐梓均, 牛当当, 吴华瑞, 等. 基于双维信息与剪枝的中文猕猴桃文本命名实体识别方法[J]. 智慧农业(中英文), 2025, 7(1): 44-56.
|
|
|
|
| [4] |
贺子康, 杨勇, 杨国峰, 等. 基于BERT-BiLSTM-CRF的农产品信息文本命名实体识别研究及应用展望[J]. 农业展望, 2022, 18(5): 105-111.
|
|
|
|
| [5] |
陈瑛, 张晓强, 陈昂轩, 等. 基于信息抽取的食品安全事件自动问答系统方法研究[J]. 农业机械学报, 2020, 51(S2): 442-448.
|
|
|
|
| [6] |
韦婷婷, 葛晓月, 熊俊涛. 基于层级多标签的农业病虫害问句分类方法[J]. 农业机械学报, 2024, 55(1): 263-269, 435.
|
|
|
|
| [7] |
朱张莉, 饶元, 吴渊, 等. 注意力机制在深度学习中的研究进展[J]. 中文信息学报, 2019, 33(6): 1-11.
|
|
|
|
| [8] |
李金鹏, 张闯, 陈小军, 等. 自动文本摘要研究综述[J]. 计算机研究与发展, 2021, 58(1): 1-21.
|
|
|
|
| [9] |
|
| [10] |
|
| [11] |
|
| [12] |
|
| [13] |
|
| [14] |
|
| [15] |
|
| [16] |
|
| [17] |
|
| [18] |
|
| [19] |
|
| [20] |
|
| [21] |
|
| [22] |
|
| [23] |
|
| [24] |
|
| [25] |
|
| [26] |
|
| [27] |
|
| [28] |
|
| [29] |
|
| [30] |
|
| [31] |
|
| [32] |
|
| [33] |
|
| [34] |
|
| [35] |
|
| [1] | YANG Chenxue, LI Xian, ZHOU Qingbo. Knowledge Graph Driven Grain Big Data Applications: Overview and Perspective [J]. Smart Agriculture, 2025, 7(2): 26-40. |
| [2] | QI Zijun, NIU Dangdang, WU Huarui, ZHANG Lilin, WANG Lunfeng, ZHANG Hongming. Chinese Kiwifruit Text Named Entity Recognition Method Based on Dual-Dimensional Information and Pruning [J]. Smart Agriculture, 2025, 7(1): 44-56. |
| [3] | WANG Tong, WANG Chunshan, LI Jiuxi, ZHU Huaji, MIAO Yisheng, WU Huarui. Agricultural Disease Named Entity Recognition with Pointer Network Based on RoFormer Pre-trained Model [J]. Smart Agriculture, 2024, 6(2): 85-94. |
| [4] | JI Jie, JIN Zhou, WANG Rujing, LIU Haiyan, LI Zhiyuan. Progressive Convolutional Net Based Method for Agricultural Named Entity Recognition [J]. Smart Agriculture, 2023, 5(1): 122-131. |
| [5] | LI Liangde, WANG Xiujuan, KANG Mengzhen, HUA Jing, FAN Menghan. Agricultural Named Entity Recognition Based on Semantic Aggregation and Model Distillation [J]. Smart Agriculture, 2021, 3(1): 118-128. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||







