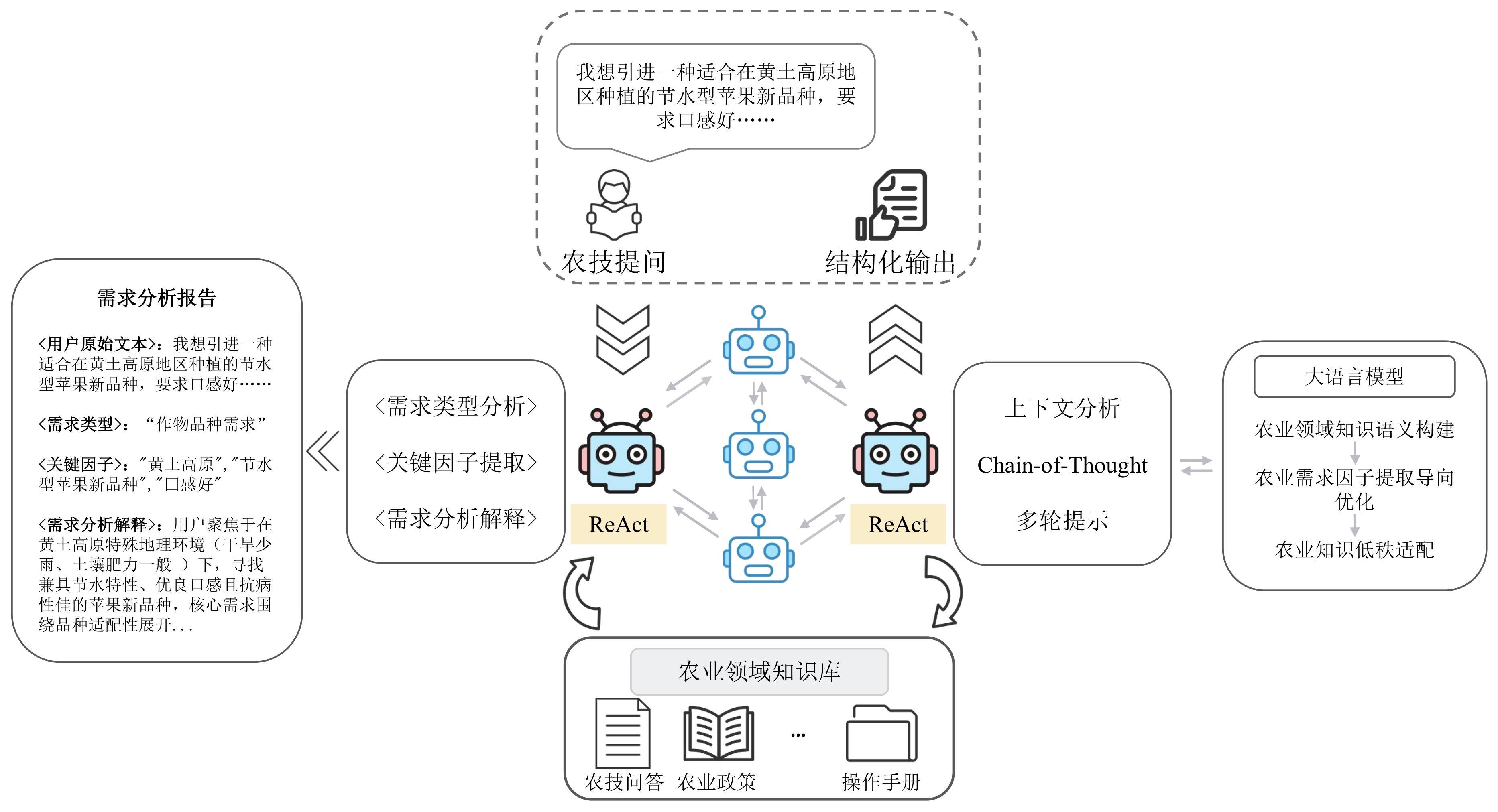
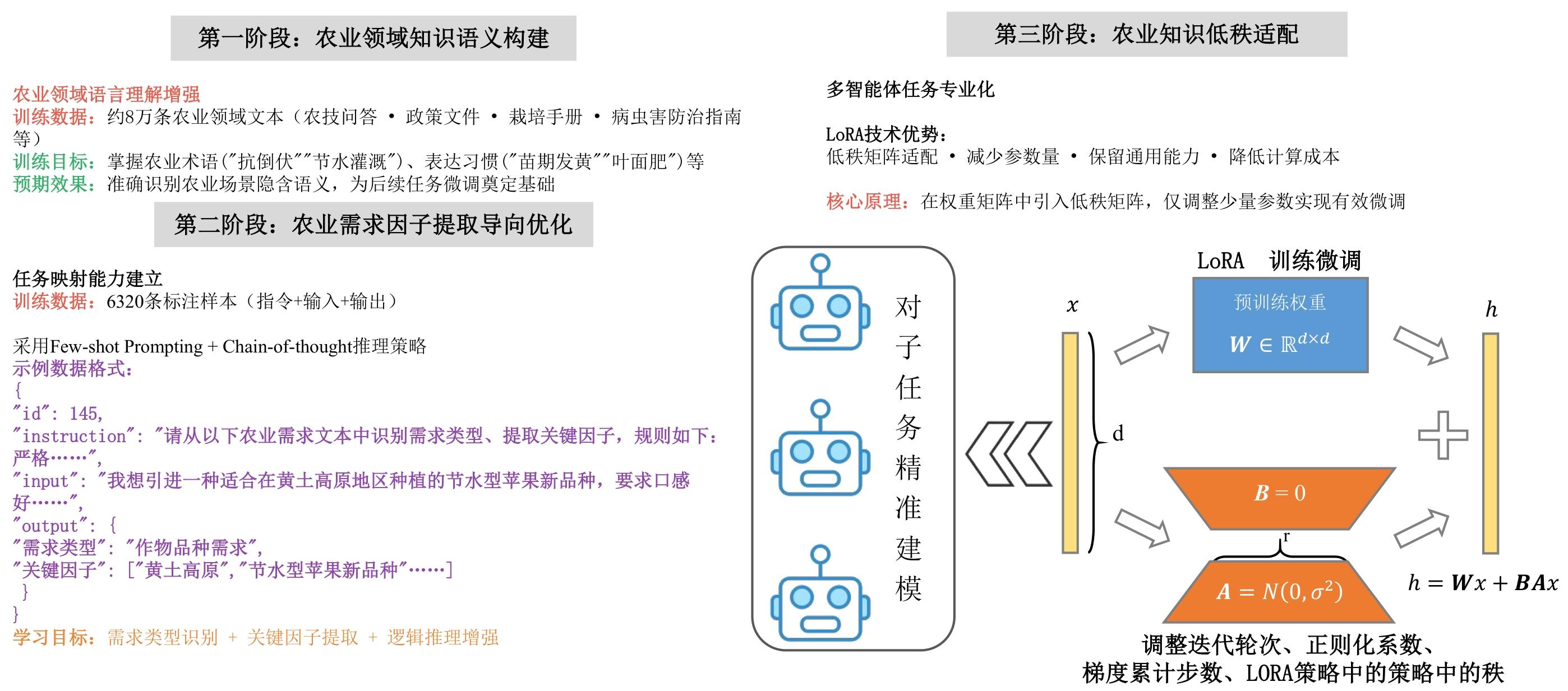
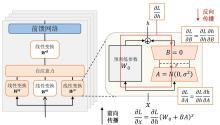
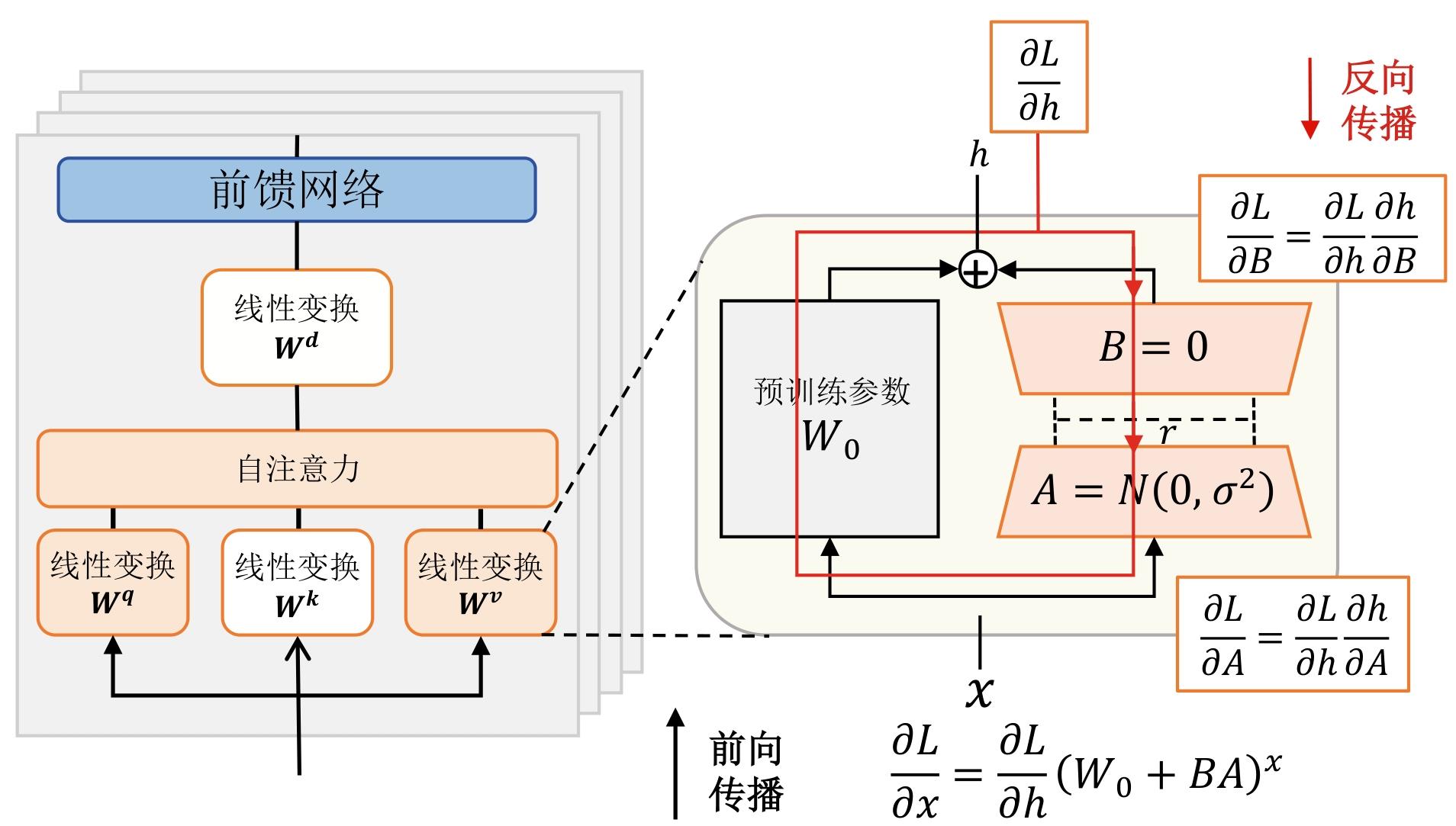
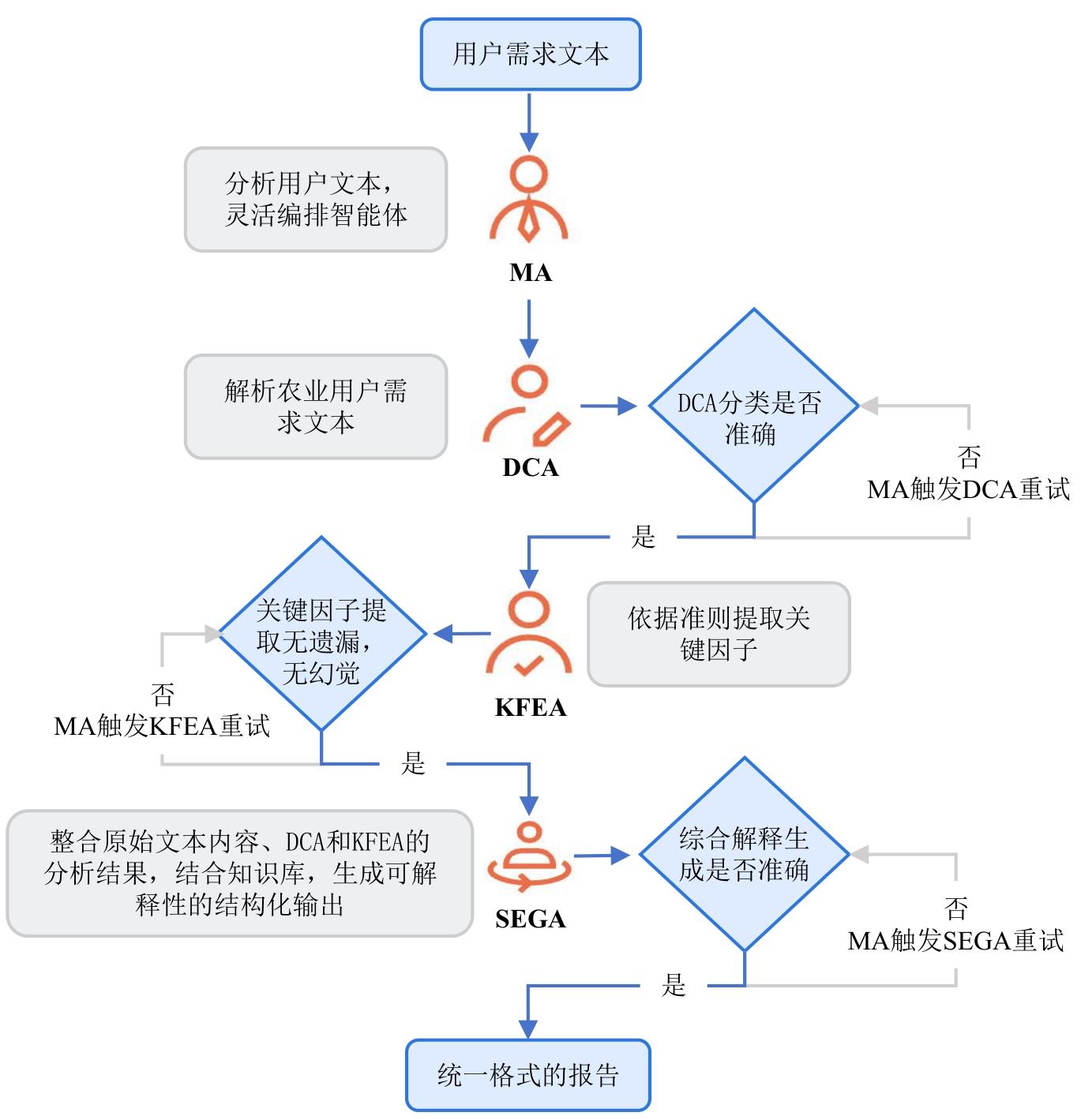
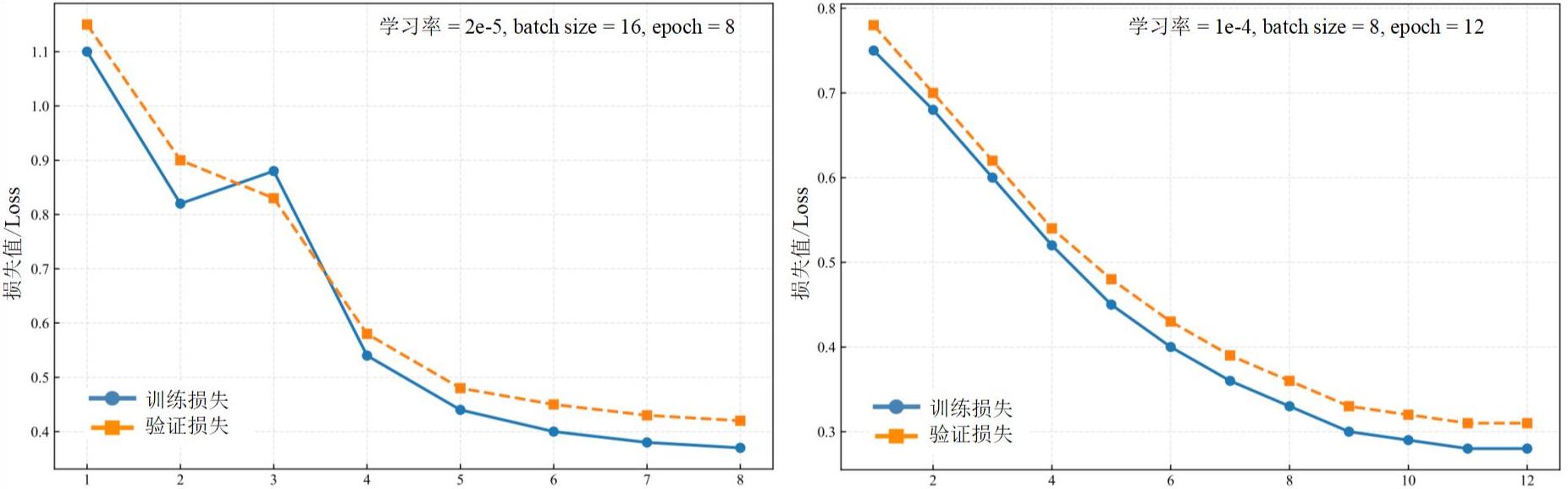
| [1] |
刘文, 王昊, 李啸林. 农业数字化转型: 研究现状、热点与趋势[J]. 技术经济与管理研究, 2025(8): 47-53.
|
|
LIU W, WANG H, LI X L. Digital transformation of agriculture: Research status, hotspots and trends[J]. Journal of Technical Economics & Management, 2025(8): 47-53.
|
| [2] |
DAYIOĞLU MALI, TURKER U. Digital transformation for sustainable future - agriculture 4.0: A review[J]. Tarım Bilimleri Dergisi, 2021, 27(4): 373-399.
|
| [3] |
SARKER I H. Data science and analytics: An overview from data-driven smart computing, decision-making and applications perspective[J]. SN Computer Science, 2021, 2(5): 377.
|
| [4] |
AYED RBEN, HANANA M. Artificial intelligence to improve the food and agriculture sector[J]. Journal of Food Quality, 2021, 2021(1): 5584754.
|
| [5] |
SHARMA S, SHARMA C, ASENSO E, et al. Research constituents and trends in smart farming: An analytical retrospection from the lens of text mining[J]. Journal of Sensors, 2023, 2023(1): 6916213.
|
| [6] |
李孝鹏, 向玉云, 张培君, 等. 农业领域自然语言理解技术应用综述[J]. 农业机械学报, 2025, 56(10): 200-222.
|
|
LI X P, XIANG Y Y, ZHANG P J, et al. Natural language understanding in agriculture: A comprehensive review of technologies and applications[J]. Transactions of the Chinese Society for Agricultural Machinery, 2025, 56(10): 200-222.
|
| [7] |
SHARMA P, DADHEECH P, ANEJA N, et al. Predicting agriculture yields based on machine learning using regression and deep learning[J]. IEEE Access, 2023, 11: 111255-111264.
|
| [8] |
王耀君, 徐国威, 朱建军, 等. 农业领域大语言模型研究进展[J]. 农业机械学报, 2025, 56(9): 240-256.
|
|
WANG Y J, XU G W, ZHU J J, et al. Survey of research on large language models in agriculture[J]. Transactions of the Chinese Society for Agricultural Machinery, 2025, 56(9): 240-256.
|
| [9] |
NISMI MOL E A, SANTOSH KUMAR M B. Review on knowledge extraction from text and scope in agriculture domain[J]. Artificial Intelligence Review, 2023, 56(5): 4403-4445.
|
| [10] |
CHATTERJEE N, KAUSHIK N. Automatic extraction of agriculture terms from domain text: A survey of tools and techniques[EB/OL]. arXiv: 2009.11796, 2020.
|
| [11] |
KOK Z H, MOHAMED SHARIFF A R, ALFATNI M S M, et al. Support vector machine in precision agriculture: A review[J]. Computers and Electronics in Agriculture, 2021, 191: 106546.
|
| [12] |
SHI L, QIN Y Q, ZHANG J J, et al. Multi-class classification of agricultural data based on random forest and feature selection[J]. Journal of Information Technology Research, 2022, 15(1): 1-17.
|
| [13] |
DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]// Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers). Minneapolis, Minnesota, USA: Association for Computational Linguistics, 2019: 4171-4186.
|
| [14] |
LIU Y F, WEI S Q, HUANG H J, et al. Naming entity recognition of citrus pests and diseases based on the BERT-BiLSTM-CRF model[J]. Expert Systems with Applications, 2023, 234: 121103.
|
| [15] |
王婷, 王娜, 崔运鹏, 等. 基于人工智能大模型技术的果蔬农技知识智能问答系统[J]. 智慧农业(中英文), 2023, 5(4): 105-116.
|
|
WANG T, WANG N, CUI Y P, et al. Agricultural technology knowledge intelligent question-answering system based on large language model[J]. Smart Agriculture, 2023, 5(4): 105-116.
|
| [16] |
郭旺, 杨雨森, 吴华瑞, 等. 农业大模型:关键技术、应用分析与发展方向[J]. 智慧农业(中英文), 2024, 6(2): 1-13.
|
|
GUO W, YANG Y S, WU H R, et al. Big models in agriculture: Key technologies, application and future directions[J]. Smart Agriculture, 2024, 6(2): 1-13.
|
| [17] |
李小玲. 智慧农业领域人工智能大模型的应用研究[J]. 中国农机装备, 2025(6): 81-83.
|
|
LI X L. Research on application of large language models in smart agriculture[J]. China Agricultural Machinery Equipment, 2025(6): 81-83.
|
| [18] |
RADFORD A, NARASIMHAN K, SALIMANS T, et al. Improving language understanding by generative pre-training[J/OL]. 2018.[2025-08-26].
|
| [19] |
姜京池, 闫莲, 刘劼. 基于精准知识筛选及知识协同生成的农业大语言模型[J]. 智慧农业(中英文), 2025,7(1): 20-32.
|
|
JIANG J C, YAN L, LIU J. Agricultural large language model based on precise knowledge retrieval and knowledge collaborative generation[J]. Smart Agriculture, 2025,7(1): 20-32.
|
| [20] |
ACHARYA D B, KUPPAN K, DIVYA B. Agentic AI: Autonomous intelligence for complex goals: A comprehensive survey[J]. IEEE Access, 2025, 13: 18912-18936.
|
| [21] |
任荣荣, 胡崇宇, 吴国龙, 等. 农业种植智能体(Agri-agent)的构建与应用展望[J]. 农业展望, 2024, 20(6): 92-106.
|
|
REN R R, HU C Y, WU G L, et al. Construction and application prospect of agricultural planting agent (Agri-agent)[J]. Agricultural Outlook, 2024, 20(6): 92-106.
|
| [22] |
HONG S R, ZHUGE M C, CHEN J Q, et al. MetaGPT: Meta programming for a multi-agent collaborative framework[EB/OL]. arXiv: 2308.00352, 2023.
|
| [23] |
WU Q Y, BANSAL G, ZHANG J Y, et al. AutoGen: Enabling next-gen LLM applications via multi-agent conversation[EB/OL]. arXiv: 2308.08155, 2023.
|
| [24] |
WEI J, WANG X Z, SCHUURMANS D, et al. Chain-of-thought prompting elicits reasoning in large language models[C]// Proceedings of the 36th International Conference on Neural Information Processing Systems. New York, USA: ACM, 2022: 24824-24837.
|
 )
)